gdb/gcc 调试编译技巧
gdb基本技巧
基础
set args
设置启动参数
next
简写n,单步执行
step
简写s,单步进入
finish
跳出函数
run
简写r,开始执行
continue
简写c,继续执行,直到断点处停止
breakpoint
简写b,设置断点
举例:
case1: b main.c:20 在main.c的第20行设置一个断点
case2: b function1 在function1函数入口处设置一个断点
info breakpoint
简写info b,查看已经设置的断点
enable/disable breakpoint n
简写disable b n,使断点有效/失效,n是用info b查看的断点编号
delete breakpoint n
简写d breakpoint n,删除断点,n是用info b查看的断点编号
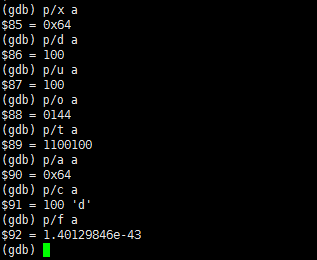
print
简写p,打印变量,还可以格式化打印变量
/x 按十六进制格式显示变量。
/d 按十进制格式显示变量。
/u 按十六进制格式显示无符号整型。
/o 按八进制格式显示变量。
/t 按二进制格式显示变量。
/a 按十六进制格式显示变量。
/c 按字符格式显示变量。
/f 按浮点数格式显示变量。
举例:
case1:p i 打印i变量的值
case2:p $rbp 打印rbp寄存器的值
case3:见下图
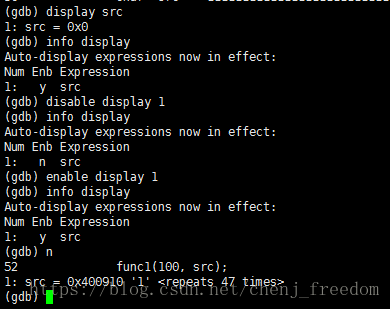
display/undisplay
监视变量,每次程序停止时候,就会展示变量。同样也支持格式化,和print命令格式化类似。
display也可以和info/disable/enable/delete命令联合使用。
举例:见下图
examine
简写x,查看内存。同样也支持格式化。类似print命令。
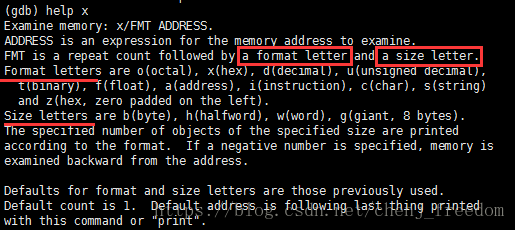
FMT is a repeat count followed by a format letter and a size letter.(中文翻译:格式化(FMT)格式为一个数字(指:后面要显示多少个单元)+格式字符+大小字符)
举例:
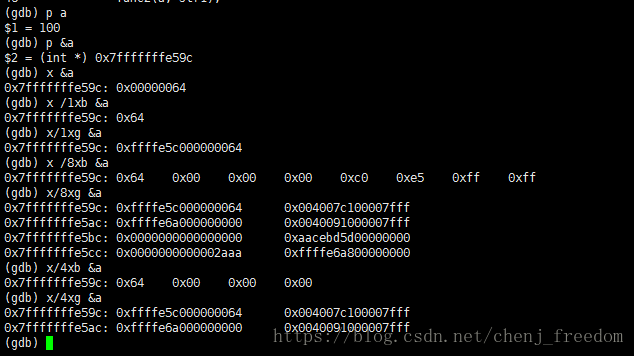
分析:一个数字分别测试1,8,4,所以后面打印了1个数,8个数,4个数;格式字符都用x测试,所以都是十六进制显示;大小字符测试了b和g,b就是一个byte一个byte显示,g就是8个byte显示,但是有点奇怪,这边16个byte显示,不知道是不是32位系统和64位系统的差别。但是反正能看得到内存就OK。
info
通用的展示命令。可以用help info查看下。
info locals :打印当前栈帧的局部变量。
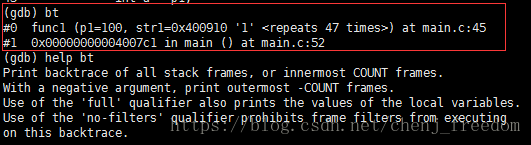
backtrace
简写bt,查看函数堆栈。
frame
简写f,切换到第N个栈帧。
举例:有如下会coredump的程序。
#include "time.h"
#include "stdio.h"
#include "stdint.h"
int func(int par1, int par2)
{
//return par2 / par1;
int a = 10;
a = par2 / par1;
a ++;
return a;
}
int main(void)
{
int a = 0;
int b = 3;
int c = 5;
c = func(a, b);
return 0;
}
// gcc -std=c99 -g test.c -o test
故意core,然后调试。

layout
用于分割窗口,可以一边查看代码,一边测试。
Ctrl + L:刷新窗口
Ctrl + x,再按a:回到传统模式,即退出layout
Ctrl + x,再按1:单窗口模式,显示一个窗口
Ctrl + x,再按2:双窗口模式,显示两个窗口
layout src:显示源代码窗口
layout asm:显示汇编窗口
layout regs:显示源代码/汇编和寄存器窗口
layout split:显示源代码和汇编窗口
layout next:显示下一个layout
layout prev:显示上一个layout
help
查看gdb命令帮助
多进程调试
方法一:attach方式
gdb start后,gdb默认是调试主进程的,那么如果要调试子进程怎么办?
step1:在代码中加入调试代码,如下:
void debug_wait(int flag)
{
while(1)
{
if (flag)
sleep(1);
else
break;
}
}
然后断点设置在该函数中,gdb start后,直接run。
step2:ps -ef | grep ***查找子进程的pid,假设为1000。
step3:在gdb中,attach 1000,就可以进入子进程了,然后p flag=0,修改flag变量,使得跳出debug_wait函数,继续执行子进程。
或者
step1:运行程序。
step2:ps查看子进程pid,假如为1000。
step3:直接gdb attach 1000,就可以进入子进程。然后p flag=0,修改flag变量,使得跳出debug_wait函数,继续执行子进程。
方法二:set follow-fork-mode [parent|child]
1、如果对程序流程熟悉,推荐用方法二,在fork前断点,然后执行到断点,此时设置下set follow-fork-mode,看想调试父进程还是子进程。
2、如果是个多重进程,fork里又嵌套了fork,同样,都是在fork前断点,执行到断点,随后再设置set follow-fork-mode。
多线程调试 todo
info threads 查看线程信息
thread N 指定调试N线程
gdb调试coredump
可以看下另一篇博文。点击我。
coredump堆栈信息丢失,如何处理?
为何堆栈信息会丢失?
缓冲区溢出有可能导致堆栈丢失,如下,我写了个缓冲区溢出的测试程序。
#include
#include
void copyData(char* str) {
char dst[4];
strcpy(dst, str);
}
void func3(char* str3)
{
copyData(str3);
}
void func2(int p2, char* str2)
{
int b = p2;
func3(str2);
}
void func1(int p1, char* str1)
{
int a = p1;
func2(a, str1);
}
void main() {
char* src = "11111111111111111111111111111111111111111111111";
//char* src = "111";
func1(100, src);
}
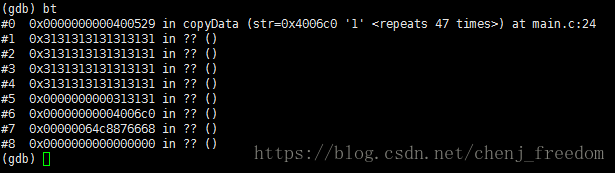
这段代码运行的时候会产生coredump文件,gdb一下看看。如下,显示一堆问号:
如何解决?
网上搜了下有两种方式,一种是手动还原函数调用堆栈;另一种是自己再手动记录另一份函数调用堆栈。这篇文章可以参考下,点击我。
第一种方法比较麻烦,而且也未必奏效。这里着重分析下第二种方法,即:自己再手动记录另一份函数调用堆栈。
手动记录函数调用堆栈使用了gcc的function instrumentation机制(可查看gcc的man page来获取更详细信息),编译时如果为gcc加上“-finstrument-functions”选项,那在每个函数的入口和出口处会各增加一个额外的hook函数的调用,增加的这两个函数分别为:
void __cyg_profile_func_enter (void *this_fn, void *call_site);
void __cyg_profile_func_exit (void *this_fn, void *call_site);
其中第一个参数为当前函数的起始地址,第二个参数为返回地址,即caller函数中的地址。
这是什么意思呢?例如我们写了一个函数func_test(),定义如下:
static void func_test(v)
{
/* your code... */
}
那通过-finstrument-functions选项编译后,这个函数的定义就变成了:
static void func_test(v)
{
__cyg_profile_func_enter(this_fn, call_site);
/* your code... */
__cyg_profile_func_exit(this_fn, call_site);
}
原理分析完毕,现在我们就用这个特性来手动记录函数调用堆栈。在上面的代码中修改一下:
#include
#include
#define DUMP(func, call) printf("%s: func = %p, called by = %p\n", __FUNCTION__, func, call)
void __attribute__((__no_instrument_function__))
__cyg_profile_func_enter(void *this_func, void *call_site)
{
DUMP(this_func, call_site);
}
void __attribute__((__no_instrument_function__))
__cyg_profile_func_exit(void *this_func, void *call_site)
{
DUMP(this_func, call_site);
}
void copyData(char* str) {
char dst[4];
strcpy(dst, str);
}
void func3(char* str3)
{
copyData(str3);
}
void func2(int p2, char* str2)
{
int b = p2;
func3(str2);
}
void func1(int p1, char* str1)
{
int a = p1;
func2(a, str1);
}
void main() {
char* src = "11111111111111111111111111111111111111111111111";
//char* src = "111";
func1(100, src);
}
然后编译的时候要加入-finstrument-functions选项:
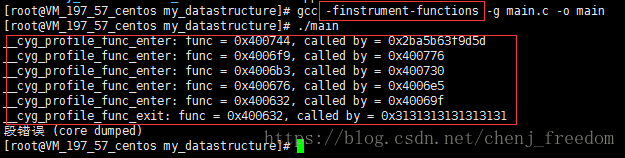
执行后,就可以看到自己的函数调用堆栈了。
但是后面都只是函数地址,那么如何看到函数名呢?可以使用gnu的另一个工具addr2line。
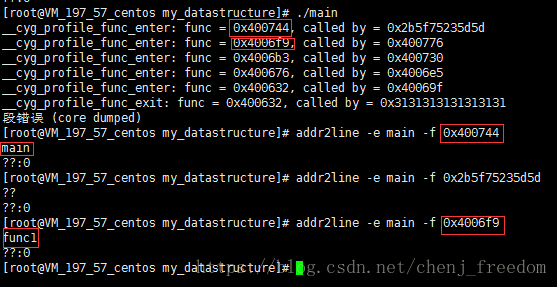
值得注意的是:如果不想跟踪某个函数,可以给该函数指定“no_instrument_function”属性。需要注意的是,__cyg_profile_func_enter()和__cyg_profile_func_exit()这两个hook函数是一定要加上“no_instrument_function”属性的,不然,自己跟踪自己就会无限循环导致程序崩溃,当然,也不能在这两个hook函数中调用其他需要被跟踪的函数。
调试宏
==
C99标准支持一些预定义宏,可以用来方便地调试程序。如下:
参考文档,点击我。
把常用的列出来,如下:
_FILE_ :显示文件 %s
_LINE_ :显示行号 %d
_FUNCTION_ :显示函数名 %s
说明:
1、_FILE_,当编译的时候,gcc是用绝对全路径编译的,那么最终显示的文件名字也是绝对全路径;如果gcc是用相对路径编译的,那么最终显示的文件名字也是相对路径的。如下图
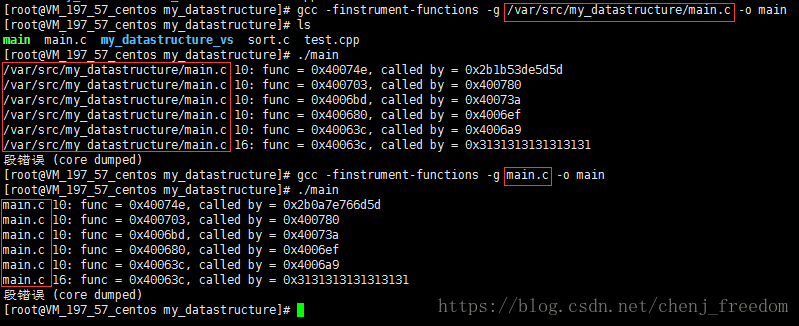
2、更高级地使用_FILE__和_LINE,参考这篇文章。
##一些调试可能遇到的神奇坑
做项目过程中,遇到许多程序设计的bug,有些很莫名其妙,需要灵感和脑洞打开。。这里做一些记录,可能以后会有启发。
1、memcpy后,其他的不相干的值莫名其妙被修改。
比如我给一个长度512的数组赋值,但是我memcpy几万个字节到这个数组,就可能覆盖内存其他值,如果刚好被覆盖的内存有用到,就可能出现不相干的值莫名其妙被修改。
2、有时候要打印一个变量,明明应该可以打印出来一个字符串,但是却显示地址越界的错误,很莫名其妙,可以看看是不是某某debuginfo*.rpm包没有安装。