GAN生成对抗网络合集(三):InfoGAN和ACGAN-指定类别生成模拟样本的GAN(附代码)
1 InfoGAN-带有隐含信息的GAN
InfoGAN是一种把信息论与GAN相融合的神经网络,能够使网络具有信息解读功能。
GAN的生成器在构建样本时使用了任意的噪声向量x’,并从低维的噪声数据x’中还原出来高维的样本数据。这说明数据x’中含有具有与样本相同的特征。
由于随意使用的噪声都能还原出高维样本数据,表明噪声中的特征数据部分是与无用的数据部分高度地纠缠在一起的,即我们能够知道噪声中含有有用特征,但无法知道哪些是有用特征。
InfoGAN是GAN模型的一种改进,是一种能够学习样本中的关键维度信息的GAN,即对生成样本的噪音进行了细化。先来看它的结构,相比对抗自编码,InfoGAN的思路正好相反,InfoGAN是先固定标准高斯分布作为网络输入,再慢慢调整网络输出去匹配复杂样本分布。
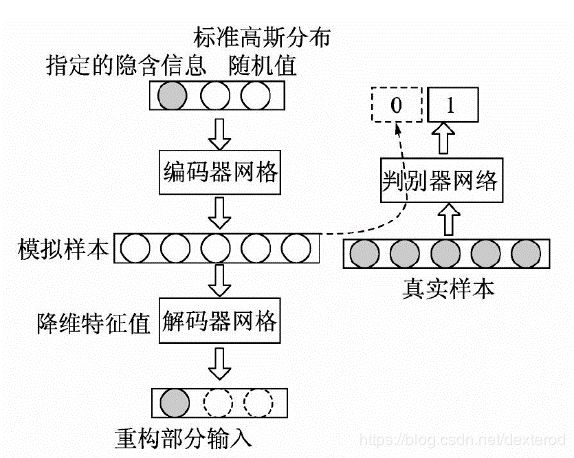
图3.1 InfoGAN模型
如图3.1所示,InfoGAN生成器是从标准高斯分布中随机采样来作为输入,生成模拟样本,解码器是将生成器输出的模拟样本还原回生成器输入的随机数中的一部分,判别器是将样本作为输入来区分真假样本。
InfoGAN的理论思想是将输入的随机标准高斯分布当成噪音数据,并将噪音分为两类,第一类是不可压缩的噪音Z,第二类是可解释性的信息C。假设在一个样本中,决定其本身的只有少量重要的维度,那么大多数的维度是可以忽略的。而这里的解码器可以更形象地叫成重构器,即通过重构一部分输入的特征来确定与样本互信息的那些维度。最终被找到的维度可以代替原始样本的特征(类似PCA算法中的主成份),实现降维、解耦的效果。
2 AC-GAN-带有辅助分类信息的GAN
AC-GAN(Auxiliary Classifier GAN),即在判别器discriminator中再输出相应的分类概率,然后增加输出的分类与真实分类的损失计算,使生成的模拟数据与其所属的class一一对应。一般来讲,AC-GAN可以属于InfoGAN的一部分,class信息可以作为InfoGAN中的潜在信息,只不过这部分信息可以使用半监督方式来学习。


3 代码
首先明确,GAN的代码没有目标检测的复杂,以一个目标检测程序demo的篇幅就涵盖了GAN的数据输入、训练、定义网络结构和参数、loss函数和优化器以及可视化部分。
还可以学习到的是,GAN基本除开两个大的网络框架G和D以外,就是加各种约束(分类信息、隐含信息等)用以生成想要的数据。
下面是代码实现学习MINST数据特征,生成以假乱真的MNIST模拟样本,并发现内部潜在的特征信息。

代码总纲:
- 加载数据集;
- 定义G和D;
- 定义网络模型的参数、输入输出、中间过程(经过G/D)的输入输出;
- 定义loss函数和优化器;
- 训练和测试(套循环);
- 可视化
3.1 加载数据集、引入头文件
MNIST数据集下载到相应的地址,其加载方式是固定的。
# -*- coding: utf-8 -*-
##################################################################
# 1.引入头文件并加载mnist数据
##################################################################
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from scipy.stats import norm
import tensorflow.contrib.slim as slim
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/media/S318080208/py_pictures/minist/") # ,one_hot=True)
tf.reset_default_graph() # 用于清除默认图形堆栈并重置全局默认图形
3.2 定义G和D
- 生成器G
通过“两个全连接+两个反卷积(转置卷积slim.conv2d_transpose)”模拟样本的生成,每一层都有BN(批量归一化)处理。 - 判别器D
判别器中有使用leaky_relu函数,其余的在slim库里有,不用重新定义;
判别器也是由“两次卷积+两次全连接”组成。生成的数据可以分别连接不同的输出层产生不同的结果,其中1维的输出层产生判别结果1或0,10维的输出层产生分类结果,2维输出层产生隐含维度信息。
##################################################################
# 2.定义生成器与判别器
##################################################################
def generator(x): # 生成器函数 : 两个全连接+两个反卷积模拟样本的生成,每一层都有BN(批量归一化)处理
reuse = len([t for t in tf.global_variables() if t.name.startswith('generator')]) > 0 # 确认该变量作用域没有变量
# print (x.get_shape())
with tf.variable_scope('generator', reuse=reuse):
x = slim.fully_connected(x, 1024)
# print(x)
x = slim.batch_norm(x, activation_fn=tf.nn.relu)
x = slim.fully_connected(x, 7*7*128)
x = slim.batch_norm(x, activation_fn=tf.nn.relu)
x = tf.reshape(x, [-1, 7, 7, 128])
# print ('22', tf.tensor.get_shape())
x = slim.conv2d_transpose(x, 64, kernel_size=[4, 4], stride=2, activation_fn = None)
# print ('gen',x.get_shape())
x = slim.batch_norm(x, activation_fn=tf.nn.relu)
z = slim.conv2d_transpose(x, 1, kernel_size=[4, 4], stride=2, activation_fn=tf.nn.sigmoid)
# print ('genz',z.get_shape())
return z
def leaky_relu(x):
return tf.where(tf.greater(x, 0), x, 0.01 * x)
def discriminator(x, num_classes=10, num_cont=2): # 判别器函数 : 两次卷积,再接两次全连接
reuse = len([t for t in tf.global_variables() if t.name.startswith('discriminator')]) > 0
# print (reuse)
# print (x.get_shape())
with tf.variable_scope('discriminator', reuse=reuse):
x = tf.reshape(x, shape=[-1, 28, 28, 1])
x = slim.conv2d(x, num_outputs=64, kernel_size=[4, 4], stride=2, activation_fn=leaky_relu)
x = slim.conv2d(x, num_outputs=128, kernel_size=[4, 4], stride=2, activation_fn=leaky_relu)
# print ("conv2d",x.get_shape())
x = slim.flatten(x) # 输入扁平化
shared_tensor = slim.fully_connected(x, num_outputs=1024, activation_fn=leaky_relu)
recog_shared = slim.fully_connected(shared_tensor, num_outputs=128, activation_fn=leaky_relu)
# 生成的数据可以分别连接不同的输出层产生不同的结果
# 1维的输出层产生判别结果1或是0
disc = slim.fully_connected(shared_tensor, num_outputs=1, activation_fn=None)
disc = tf.squeeze(disc, -1)
# print ("disc",disc.get_shape()) # 0 or 1
# 10维的输出层产生分类结果 (样本标签)
recog_cat = slim.fully_connected(recog_shared, num_outputs=num_classes, activation_fn=None)
# 2维输出层产生重构造的隐含维度信息
recog_cont = slim.fully_connected(recog_shared, num_outputs=num_cont, activation_fn=tf.nn.sigmoid)
return disc, recog_cat, recog_cont
3.3 定义网络模型 输入/输出/中间参数
输入进生成器的是两个噪声数据(一般噪声随机向量z_rand 38列 / 隐含信息约束z_con 2列)和分类标签labels的one_hot编码 10 列。生成模拟样本,然后将模拟样本gen和真实样本x分别输入到判别器中,生成判别结果dis_fake/样本标签class_fake/重构造的隐含信息con_fake 以及 dis_real/class_real/ _ 。
注:隐含信息在这里是指字体的粗细和倾斜信息。它不由我们控制,比如我想让字体拥有这两个信息的特征生成,就给他们两个隐含信息;如果没有这种特征生成,就多加几个隐含信息,假如加10个隐含信息,看里面有没有能控制的,多余的就当是随机变量。如果再都没有,就说明这个太复杂了,学习不了(个人理解)。
##################################################################
# 3.定义网络模型 : 定义 参数/输入/输出/中间过程(经过G/D)的输入输出
##################################################################
batch_size = 10 # 获取样本的批次大小32
classes_dim = 10 # 10 classes
con_dim = 2 # 隐含信息变量的维度, 应节点为z_con
rand_dim = 38 # 一般噪声的维度, 应节点为z_rand, 二者都是符合标准高斯分布的随机数。
n_input = 784 # 28 * 28
x = tf.placeholder(tf.float32, [None, n_input]) # x为输入真实图片images
y = tf.placeholder(tf.int32, [None]) # y为真实标签labels
z_con = tf.random_normal((batch_size, con_dim)) # 2列
z_rand = tf.random_normal((batch_size, rand_dim)) # 38列
z = tf.concat(axis=1, values=[tf.one_hot(y, depth=classes_dim), z_con, z_rand]) # 50列 shape = (10, 50)
gen = generator(z) # shape = (10, 28, 28, 1)
genout= tf.squeeze(gen, -1) # shape = (10, 28, 28)
# labels for discriminator
y_real = tf.ones(batch_size) # 真
y_fake = tf.zeros(batch_size) # 假
# 判别器
disc_real, class_real, _ = discriminator(x)
disc_fake, class_fake, con_fake = discriminator(gen)
pred_class = tf.argmax(class_fake, dimension=1)
3.4 定义损失函数和优化器
判别器D的损失函数有两个:真实输入的结果loss_d_r和模拟输入的结果loss_d_f。二者结合为loss_d;(输入真实样本,判别为真/输入模拟样本,判别为假)
生成器G的损失函数是想要“以假乱真”,自己输出的模拟数据,让它在D中判别为真,loss值为loss_g;
还要定义网络中共有的loss值:真实的标签与输入模拟样本判别出的标签loss_cf、真实的标签与输入真实样本判别的标签loss_cr、隐含信息的重构误差loss_con。
之后用AdamOptimizer分别优化G和D。其中用了一个技巧,将D的学习率设小0.0001,将G的学习率设大0.001,可以让G有更快的进化速度来模拟真实数据。
##################################################################
# 4.定义损失函数和优化器
##################################################################
# 判别器 loss
loss_d_r = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_real, labels=y_real))
loss_d_f = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_fake, labels=y_fake))
loss_d = (loss_d_r + loss_d_f) / 2
# print ('loss_d', loss_d.get_shape())
# 生成器 loss
loss_g = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=disc_fake, labels=y_real))
# categorical factor loss 分类因素损失
loss_cf = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=class_fake, labels=y))
loss_cr = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=class_real, labels=y))
loss_c = (loss_cf + loss_cr) / 2
# continuous factor loss 隐含信息变量的损失
loss_con = tf.reduce_mean(tf.square(con_fake-z_con))
# 获得各个网络中各自的训练参数列表
t_vars = tf.trainable_variables()
d_vars = [var for var in t_vars if 'discriminator' in var.name]
g_vars = [var for var in t_vars if 'generator' in var.name]
# 优化器
disc_global_step = tf.Variable(0, trainable=False)
gen_global_step = tf.Variable(0, trainable=False)
train_disc = tf.train.AdamOptimizer(0.0001).minimize(loss_d + loss_c + loss_con, var_list=d_vars, global_step=disc_global_step)
train_gen = tf.train.AdamOptimizer(0.001).minimize(loss_g + loss_c + loss_con, var_list=g_vars, global_step=gen_global_step)
所谓的AC-GAN就是将 loss_cr 加入到 loss_c 中。如果没有 loss_cr,令 loss_c = loss_c,对于网络生成模拟数据是不影响的,但是会损失真实分类与模拟数据间的对应关系(未告知分类信息)(影响后果见可视化部分)。
3.5 训练与测试
建立 session,在循环里使用 run 来运行前面构建的两个优化器。测试部分分别使用 loss_d 和 loss_g 的 eval 完成。
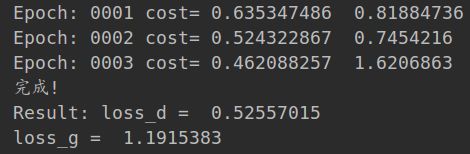
整个数据集运行3次后,判别误差在0.5左右,基本可以认为是对真假数据无法分辨。
##################################################################
# 5.训练与测试
# 建立session,循环中使用run来运行两个优化器
##################################################################
training_epochs = 3
display_step = 1
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.4
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size) # 5500
# 遍历全部数据集
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size) # 取数据x:images, y:labels
feeds = {x: batch_xs, y: batch_ys}
# Fit training using batch data
# 输入数据,运行优化器
l_disc, _, l_d_step = sess.run([loss_d, train_disc, disc_global_step], feeds)
l_gen, _, l_g_step = sess.run([loss_g, train_gen, gen_global_step], feeds)
# 显示训练中的详细信息
if epoch % display_step == 0:
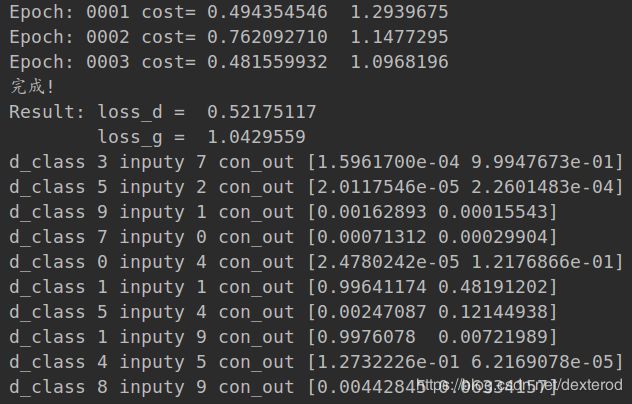
print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f} ".format(l_disc), l_gen)
print("完成!")
# 测试
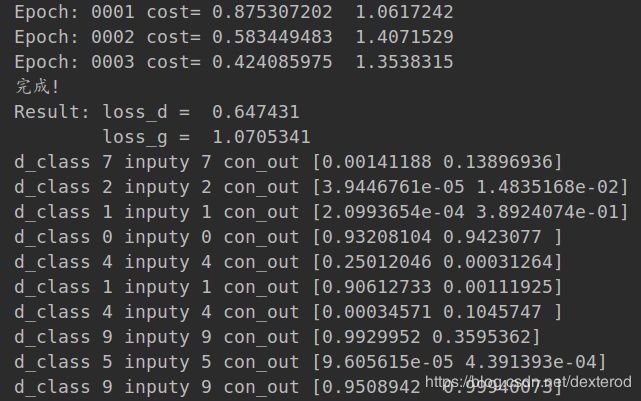
print("Result: loss_d = ", loss_d.eval({x: mnist.test.images[:batch_size], y: mnist.test.labels[:batch_size]}),
"\n loss_g = ", loss_g.eval({x: mnist.test.images[:batch_size], y: mnist.test.labels[:batch_size]}))
测试结果如下:
3.6 可视化
可视化部分分为两部分,一部分是对原图片和对应的模拟数据图片进行plt。另一部分是利用隐含信息生成的模拟样本图片。
- 第一部分
##################################################################
# 6.可视化
##################################################################
# 根据图片模拟生成图片
show_num = 10
gensimple, d_class, inputx, inputy, con_out = sess.run(
[genout, pred_class, x, y, con_fake], feed_dict={x: mnist.test.images[:batch_size], y: mnist.test.labels[:batch_size]})
f, a = plt.subplots(2, 10, figsize=(10, 2)) # figure 1000*20 , 分为10张子图
for i in range(show_num):
a[0][i].imshow(np.reshape(inputx[i], (28, 28)))
a[1][i].imshow(np.reshape(gensimple[i], (28, 28)))
print("d_class", d_class[i], "inputy", inputy[i], "con_out", con_out[i]) # 输出 判决预测种类/真实输入种类/隐藏信息
plt.draw()
plt.show()
# 将隐含信息分布对应的图片打印出来
my_con = tf.placeholder(tf.float32, [batch_size, 2])
myz = tf.concat(axis=1, values=[tf.one_hot(y, depth=classes_dim), my_con, z_rand])
mygen = generator(myz)
mygenout= tf.squeeze(mygen, -1)
my_con1 = np.ones([10, 2])
a = np.linspace(0.0001, 0.99999, 10)
y_input = np.ones([10])
figure = np.zeros((28 * 10, 28 * 10))
my_rand = tf.random_normal((10, rand_dim))
for i in range(10):
for j in range(10):
my_con1[j][0] = a[i]
my_con1[j][1] = a[j]
y_input[j] = j
mygenoutv = sess.run(mygenout, feed_dict={y: y_input, my_con: my_con1})
for jj in range(10):
digit = mygenoutv[jj].reshape(28, 28)
figure[i * 28: (i + 1) * 28,
jj * 28: (jj + 1) * 28] = digit
plt.figure(figsize=(10, 10))
plt.imshow(figure, cmap='Greys_r')
plt.show()
得到的结果如下:
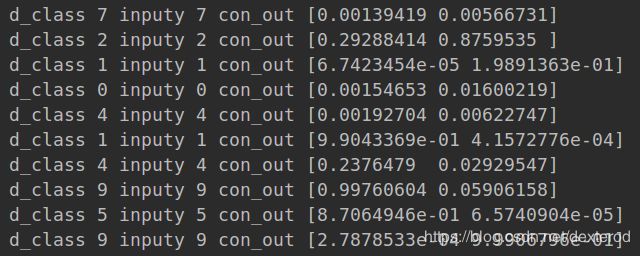


可以看到前两个结果是第一部分生成的,将原样本与对应的模拟数据图片的分类、预测分类、隐含信息打印出来;
而最后一个结果是利用隐含信息生成的模拟样本图片,在整个【0,1】空间里均匀抽样,与样本的标签混合在一起,生成模拟数据。
若去掉 loss_cf,只保留 loss_cr 约束:(直接不优化模拟数据的分类信息了,即我不努力了还不行么)


若去掉loss_cr,只保留loss_cf约束(没告诉什么是对的。即分类分对了,但与本身生成的模拟数据没啥关系)