企业级mysql数据库集群实战(2)—— MySQL主从复制之异步复制(传统复制Postion与Gtid)
目录
一. 主从复制简介
- 1、概念
- 2、原理
- 3、优点
二、异步复制
- 1、优缺点简介
- 2、理解pos复制与GTID复制方式
- 3、pos复制与GTID复制区别
三、搭建基于position异步复制
(一).master节点上:
- 步骤一:下载mysql服务器安装包
- 步骤二:修改初始化文件并开启数据库,进行安全初始化
- 步骤三:安全初始化
- 步骤四:登录验证 创建用户 授权
- 步骤五:在真机测试master节点是否配置好
(二).在salve节点上也部署mysql服务
- 步骤一:从server1上拷贝安装包
- 步骤二:安装软件
- 步骤三:修改初始化文件并开启数据库,进行安全初始化
- 步骤四:安全初始化
- 步骤五:配置主从复制的信息
(三).测试主从同步是否生效
- 步骤一:在master创建新数据:
- 步骤二:在slave上读取信息,看是否同步
四.搭建基于GTID的异步复制
- 步骤一:修改配置文件加入开启gtid的信息
- 步骤二:在slave节点上完成上边相同的步骤
- 步骤三:登陆数据库启用gtid
- 步骤四 :在master节点上添加插入数据
- 步骤五:在slave节点上查看数据是否已经同步
- 步骤六:查看数据是否已经复制
一. 主从复制简介
1、概念
1.MYSQL的主从复制(异步复制)的基本信息
特别提醒:在数据库中进行操作时,事实上大小写都是通用的,但是作为一个专业人士 ,尽量还是使用大写
异步复制(主从复制)master节点不会关心slave节点的状态,只需要写自己的数据即可
能不能完成复制看slave节点的io线程和sql线程是否开启
- 主从复制的要求:
(1)主库开启binlog日志(设置log-bin参数)
(2)主从server-id不同
(3)从库服务器能连同主库
- 主从复制的原理:
mysql的主从配置又叫replication,AB复制,基于binlog二进制日志,主数据库必须开启binlog二进制日志才能进行复制
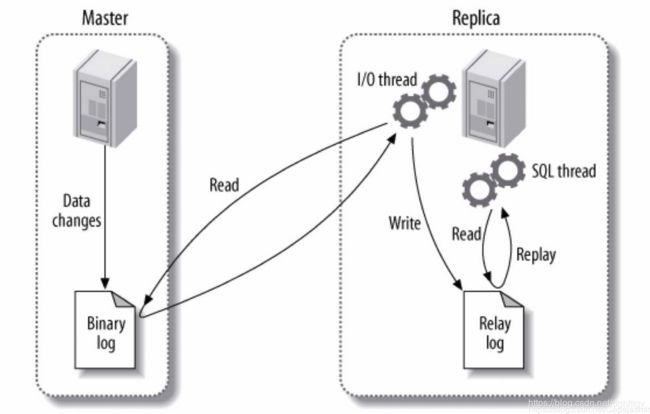
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2)从库生成两个线程,一个i/o线程,一个SQL线程,i/o线程去请求主库的binlog,sql线程进行日志回放来复制
(3) slave将master的binary log events拷贝到它的中继日志(relay log);
(4)slave重做中继日志中的事件,将更改应用到自己的数据上。
- mysql的主从复制(异步复制)(基于position)把一个事件拆开来复制,并不是以一个完整的事件为单位来进行复制
- 一开始两个mysql必须一模一样,否则会报错
- master自己做自己的,写在自己的日志里
- slave能否同步成功取决于IO线程,和SQL线程回放日志
- IO通过联系master拿到master的二进制日志,SQL回放日志
- slave节点的数据总比master节点的数据慢
异步复制:在主节点写入日志即返回成功,默认情况下MySQL5.5/5.6/5.7和mariaDB10.0/10.1的复制功能是异步的
异步复制可以实现最佳的性能,主库把binlog日志发送给从库,这一动作就结束了,并不验证从库,会造成主从库数据不一致
- 主从复制(也称 AB 复制)允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
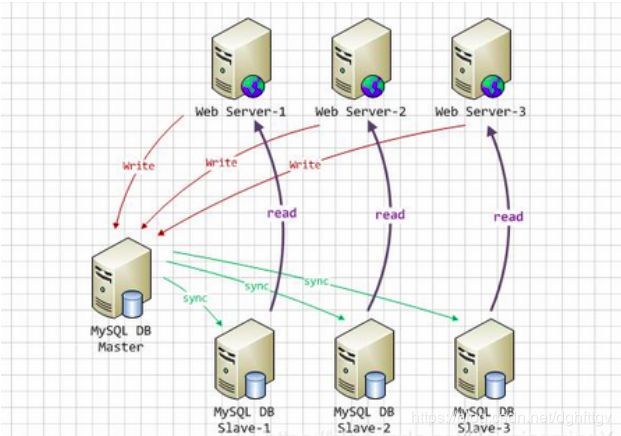
2、原理
MySQL之间数据复制的基础是二进制日志文件(binary log file)。一台MySQL数据库一旦启用二进制日志后,其作为master,它的数据库中所有操作都会以“事件”的方式记录在二进制日志中,其他数据库作为slave通过一个I/O线程与主服务器保持通信,并监控master的二进制日志文件的变化,如果发现master二进制日志文件发生变化,则会把变化复制到自己的中继日志中,然后slave的一个SQL线程会把相关的“事件”执行到自己的数据库中,以此实现从数据库和主数据库的一致性,也就实现了主从复制。
3、优点
mysql的主从复制,是用来建立一个和主数据库完全一样的数据库环境,称为从数据库,主数据库一般是实时的业务数据操作,从数据库常用的读取为主。
优点主要有
1,可以作为备用数据库进行操作,当主数据库出现故障之后,从数据库可以替代主数据库继续工作,不影响业务流程
- 1、概念
- 2、原理
- 3、优点
2,读写分离,将读和写应用在不同的数据库与服务器上。一般读写的数据库环境配置为,一个写入的数据库,一个或多个读的数据库,各个数据库分别位于不同的服务器上,充分利用服务器性能和数据库性能;当然,其中会涉及到如何保证读写数据库的数据一致,这个就可以利用主从复制技术来完成。
3,吞吐量较大,业务的查询较多,并发与负载较大。
二、异步复制
1、优缺点简介
异步复制是MySQL默认的复制方式,原理是在主库写入binlog日志后,就可以直接成功返回客户端,不用等待binlog日志传递给从库的过程。相对来说会更快,但是一旦主库发生宕机,就有可能发生数据丢失。
2、理解pos复制与GTID复制方式
主从复制,默认是通过pos复制(postion),就是说在日志文档里,将用户进行的每一项操作都进行编号(pos),每一个event都有一个起始编号,一个终止编号,我们在配置主从复制时从节点时,要输入master的log_pos值就是这个原因,要求它从哪个pos开始同步数据库里的数据,这也是传统复制技术,以后就自己去读取上一次同步到哪一块,接着同步.
MySQL5.6增加了GTID复制,GTID就是类似于pos的一个作用,不过它是整个mysql复制架构全局通用的,就是说在这整个mysql冗余架构中,它们的日志文件里事件的GTID值是一致的。
3、pos复制与GTID复制区别
两者都是日志文件里事件的一个标志,如果将整个mysql集群看作一个整体,pos就是局部的,GTID就是全局的。

上图就是一个mysql节点的集群,一主两从,在master,slave1,slave2日志文件里的pos,都各不相同,就是一个event,在master的日志里,pos可能是700,而在slave1,slave2里,pos可能就是300,400了,因为众多slave也可能不是同时加入集群的,不是从同一个位置进行同步
而GTID,在master,slave1,slave2各自的日志文件里,同一个event的GTID值都是一样的.
为什么要有这个区分呢?
大家都知道,这整个集群架构的节点,通常情况下是master在工作,其他两个结点做备份。而且各个节点的机器性能不可能完全一致。所以,在做备份时,备份的速度就不一样,当master突然crash掉之后,马上会启用从节点机器接管master的工作,当有多个从节点时,选择备份日志文件最接近master的那个节点。
现在就出现情况了,当salve1变成主节点,那slave2就应该从slave1去获取日志文件,进行同步.。
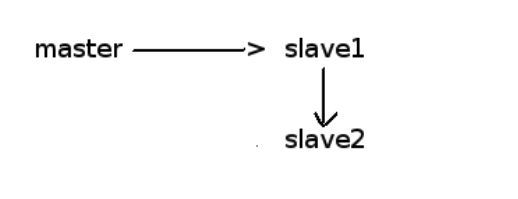
如果使用的是pos,三者的pos不一致,slave2怎么去获取它当前要同步的事件在slave1里的pos呢,很难.
所以就有了GTID,全局的,将所有节点对于同一个event的标记完全一致,当master crash掉之后,slave2根据同一个GTID直接去读取slave1的日志文件,继续同步。
三、搭建基于position异步复制
实验环境
| 主机名 | ip | 服务 |
|---|---|---|
| server1 | 172.25.6.1 | 数据库master |
| server2 | 172.25.6.2 | 数据库slave |
| foundation6.ilt.example.com | 172.25.6.250 | 客户端 |
实验
(一) . master节点上:
步骤一:
下载mysql服务器安装包
下载地址:https://github.com/mysqljs/mysql/releases/tag/ (也可以到mysql官网去下,但是官网(www.mysql.com)有时比较慢)
1.查看节点的实验环境是否干净(查看master节点)

slave端同理

2.提前下好的是mysql软件压缩包
[root@server1 ~]# du -sh mysql-5.7.24-1.el7.x86_64.rpm-bundle.tar ##查看压缩包容量的大小
[root@server1 ~]# tar xf mysql-5.7.24-1.el7.x86_64.rpm-bundle.tar ##解压

删除没有用的:rm -rf devel、embe、mini、server-minimal、test
最终只有5个rpm包

安装软件
[root@server1 ~]# yum install -y *.rpm ##安装此路径下所有带有rpm的软件包

步骤二:
修改初始化文件并开启数据库,进行安全初始化
[root@server1 ~]# vim /etc/my.cnf ##进入数据库的配置文件中
...
log-bin=mysql-bin
server-id=1 ##(每个节点的序号是唯一的,这里master=1 slave=2)
...
[root@server1 ~]# systemctl start mysqld ##重启mysql服务

![]()
开启服务之后会生成一个临时密码,使用临时密码进行数据库安全初始化
[root@server1 ~]# cat /var/log/mysqld.log | grep password ##查看mysql初始密码
[root@server1 ~]# mysql -uroot -plsFtyBkYp7-G ##登录数据库查看
...
mysql> show databases;
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.
...
##可以登录但是有报错,没有进行数据库初始化
步骤三:
安全初始化
安全初始化登陆的时候使用的是临时密码,接下来要自己设置数据库的密码,这个密码必须有特殊字符,英文字母的大小写还有数字
[root@server1 ~]# mysql_secure_installation ##安全初始化数据库
Securing the MySQL server deployment.
Enter password for user root: ##输入安全初始化数据库的密码
The existing password for the user account root has expired. Please set a new password.
New password: ##输入新的密码
Re-enter new password:


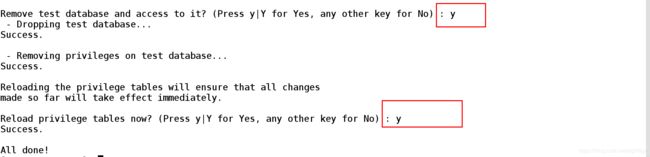
(注:都选择y)
步骤四:
登录验证 创建用户 授权
master节点的数据库初始化结束,使用设置的密码登录数据库数据库验证是否设置成功!!
1.登录验证

2.创建用户 授权
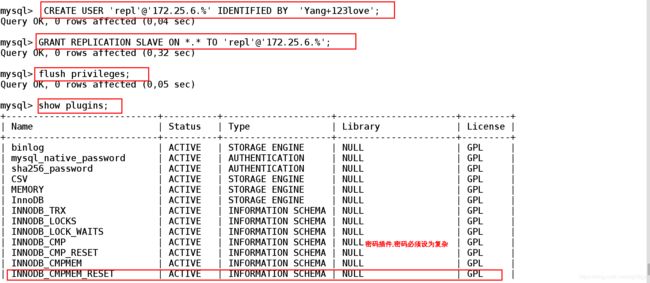
[root@server1 ~]# mysql -uroot -pYang+123love ##登录数据库
mysql> show databases;
mysql> CREATE USER 'repl'@'172.25.6.%' IDENTIFIED BY 'Yang+123love'; ##;创建用户,可以使用此用户远程登录数据库
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'172.25.6.%'; ##授权为可以复制master节点数据的slave节点
mysql> flush privileges; ##刷新
mysql> show plugins; ##查看master插件
mysql> show master status; ##查看master节点的状态| 参数 | 解释 |
|---|---|
| REPLICATION | 表示复制的权限 |
| * .* | 表示对所有库的所有表都授权 |
| repl | 用户名 |
| ‘172.25.6.%’ | 授权172.25.6网段的所有数据库节点都可以同步(复制) |

步骤五:
在真机测试master节点是否配置好
[root@foundation6 ~]# mysql -h 172.25.6.1 -urepl -pYang+123love ##可以登录成功但是看不到master数据库中的重要信息
(二). 在salve节点上也部署mysql服务
步骤一:
从server1上拷贝安装包
[root@server1 ~]# scp mysql-community-* server2:/root ##拷贝安装包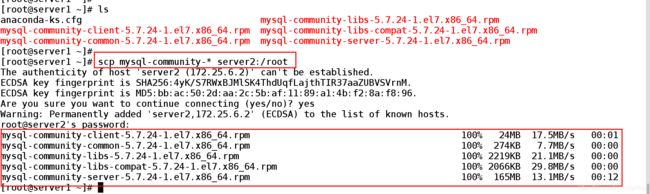

步骤二:
安装软件
[root@server2 ~]# yum install -y *.rpm ##安装此路径下所有带有rpm的软件包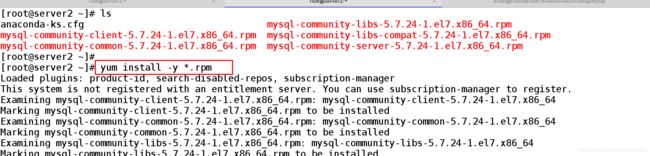

步骤三:
修改初始化文件并开启数据库,进行安全初始化
[root@server1 ~]# vim /etc/my.cnf ##进入数据库的配置文件中
...
server-id=1 ##(每个节点的序号是唯一的,这里master=1 slave=2)
...
[root@server1 ~]# systemctl start mysqld ##重启mysql服务


步骤四:
1.安全初始化(同上边master进行的操作)
[root@server2 ~]# cat /var/log/mysqld.log | grep password
[root@server2 ~]# mysql_secure_installation 

2. 登录验证查看是否成功

步骤五:
配置主从复制的信息(配置salve链接的master信息)
mysql> change master to master_host='172.25.6.1', ##在这个slave节点上面设置管理它的master节点主机信息
-> master_user='repl', ##用户
-> master_password='Yang+123love', ##密码
-> master_log_file='mysql-bin.000002', ##复制日志中的内容
-> master_log_pos=1565; ##复制的认证信息
mysql> start slave; ##开启slave
mysql> show slave status/G
...
Slave_IO_Running: Yes ##看到都为Yes就说明设置成功
Slave_SQL_Running: Yes
...

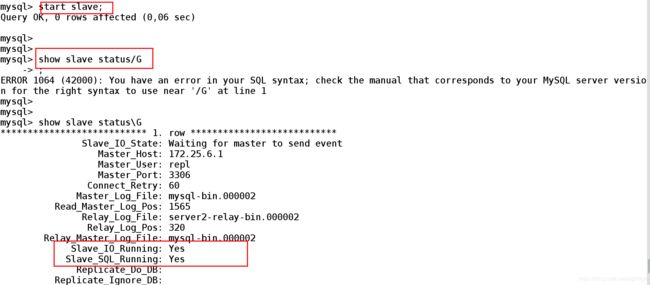
Slave_IO_Running: Yes Slave_SQL_Running: Yes 这两个参数是Yes,表示成功。
因为对于slave节点来说,io线程和sql线程是最重要的两个线程。只有当io线程和sql线程都开启的时候,slave节点才可以正常复制master节点的数据
(三). 测试主从同步是否生效
注意:写操作只能在master结点上,读操作在slave节点上
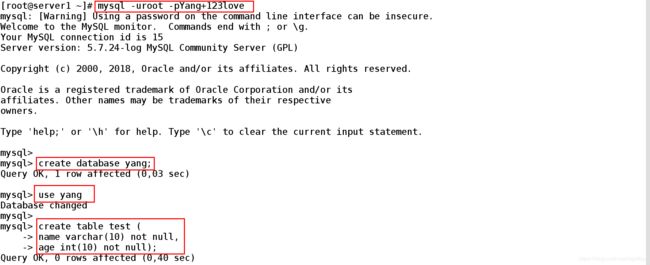
步骤一:
在master创建新数据:非关系型数据库
mysql> create database yang; ##创建库
mysql> use yang ##进入库中
Database changed
mysql> create table test ( ##创建表
-> name varchar(10) not null,
-> age int(10) not null);
mysql> desc test; ##查看表的属性
mysql> insert into test values ('user1','18'); ##插入数据
mysql> select * from test; ##查表
- 1、概念
- 2、原理
- 3、优点

步骤二:
在slave上读取信息,看是否同步
mysql> show databases; ##查看库信息,看是否同步了刚才创建的库
mysql> use yang
mysql> select * from test; ##查表


(数据同步成功!!!!)
四.搭建基于GTID的异步复制
此实验是基于position的主从复制的基础上进行的
在master(server1)上:
步骤一:
修改配置文件加入开启gtid的信息
[root@server1 ~]# vim /etc/my.cnf
...
gtid_mode=ON
enforce-gtid-consistency=true ##在文件中写入gtid相关的配置信息
...
[root@server1 ~]# systemctl restart mysqld ##重启动mysql服务



步骤二:
在slave节点上完成上边相同的步骤



步骤三:
登陆数据库启用gtid
[root@server2 ~]# mysql -uroot -pYang+123love ##登录数据库
mysql> stop slave; ##关闭salve服务
mysql> CHANGE MASTER TO
-> MASTER_HOST = '172.25.6.1',
-> MASTER_USER = 'repl',
-> MASTER_PASSWORD = 'Yang+123love',
-> MASTER_AUTO_POSITION = 1;
mysql> start slave; ##配置完成后开启slave
mysql> show slave status\G ##查看slave链接的状态信息
...
此时能查看到这两项
Retrieved_Gtid_Set:
Executed_Gtid_Set:
...
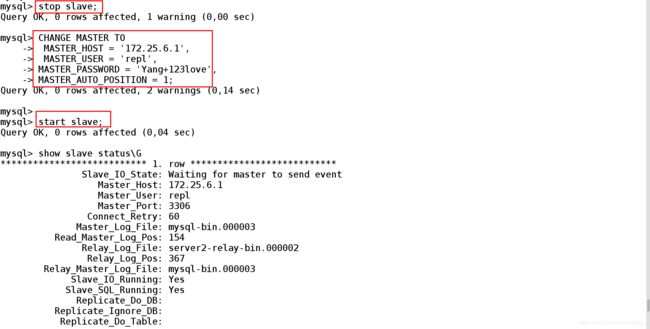
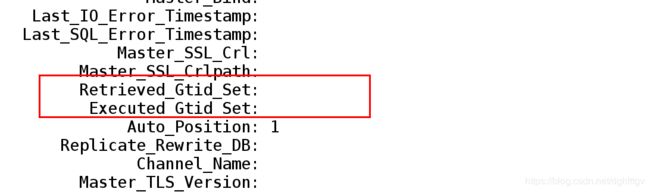
(查看到的是Gtid中的内容是空的)
步骤四 :
在master节点上
添加插入数据
[root@server1 mysql]# mysql -uroot -pYang+123love ##登录数据库
mysql> use yang ##进入到上一个实验创建的库中
mysql> insert into test values ('user2','23'); ##插入数据



步骤五:
在slave节点上查看数据是否已经同步
[root@server2 ~]# mysql -uroot -pYang+123love
mysql> show slave status\G ##查看slave的状态信息
...
Retrieved_Gtid_Set: d3e68614-6e96-11ea-9348-52540064d254:1 ##查看到的是uuid的地址和slave中的地址一致,1表示更新了一组数据
Executed_Gtid_Set: d3e68614-6e96-11ea-9348-52540064d254:1
...
mysql> use mysql
mysql> select * from gtid_executed; ##查看gtid复文件的个数
+--------------------------------------+----------------+--------------+
| source_uuid | interval_start | interval_end |
+--------------------------------------+----------------+--------------+
| d3e68614-6e96-11ea-9348-52540064d254 | 1 | 1 |
+--------------------------------------+----------------+--------------+



步骤六:
查看数据是否已经复制
mysql> use yang
mysql> select * from test; ##查表 
总结:
MySQL主从复制涉及到3个线程,一个运行在主节点(log dump thread),其余两个(I/O thread,SQL thread)运行在从节点,
当从节点上执行 “ start slave ” 命令之后从节点会创建一个I/O线程 用来链接节点主节点,请求主库更新的bin-log,I/O线程在收到主节点binlog dump 进程发来的更新之后,保存在本地的relay -log中。
SQL线程负责读取 relay log中的内容,更新程具体的操作并执行,最终保持数据的一致性,
异步复制主节点不会主动push bin log 的到从节点,这样可能导致failover的情况下,也许从节点没有及时的将最新的bin log 同步到本地。
GTID复制模式:
1.在传统的复制里面,当发生故障,需要主从切换,需要找到binlog和pos点,然后将主节点指向新的主节点,相对来说比较麻烦,也容易出错。在MySQL 5.6里面,不用再找binlog和pos点,我们只需要知道主节点的ip,端口,以及账号密码就行,因为复制是自动的,MySQL会通过内部机制GTID自动找点同步。2. 多线程复制(基于库),在MySQL 5.6以前的版本,slave的复制是单线程的。一个事件一个事件的读取应用。而master是并发写入的,所以延时是避免不了的。唯一有效的方法是把多个库放在多台slave,这样又有点浪费服务器。在MySQL 5.6里面,我们可以把多个表放在多个库,这样就可以使用多线程复制。3.2.6基于GTID复制实现的工作原理主节点更新数据时,会在事务前产生GTID,一起记录到binlog日志中。从节点的I/O线程将变更的bin log,写入到本地的relay log中。SQL线程从relay log中获取GTID,然后对比本地binlog是否有记录(所以MySQL从节点必须要开启binary log)。如果有记录,说明该GTID的事务已经执行,从节点会忽略。如果没有记录,从节点就会从relay log中执行该GTID的事务,并记录到bin log。在解析过程中会判断是否有主键,如果没有就用二级索引,如果有就用全部扫描。