透彻理解CLH 队列锁原理及其Java实现
CLH 锁队列介绍
之前说到在学习 java 并发框架 AQS 的时候,其中的锁队列是在 CLH 锁队列的基础上改进而来的。本文主要介绍 CLH 队列锁。
SMP 和 NUMA 简要介绍
- SMP (Symmetric MultiProcessing) 对称多处理是一种包括软硬件的多核计算机架构,会有两个或以上的相同的核心共享一块主存,这些核心在操作系统中地位相同,可以访问所有 I/O 设备。它的优点是内存等一些组件在核心之间是共享的,一致性可以保证,但也正因为内存一致性和共享对象在扩展性上就受到限制了 。
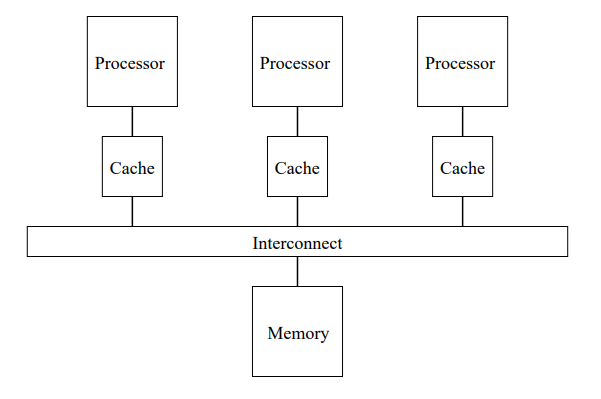 图1 SMP架构
图1 SMP架构
- NUMA (Non-uniform memory access) 非一致存储访问也是一种在多处理任务中使用的计算机存储设计,每个核心有自己对应的本地内存,各核心之间通过互联进行相互访问。在这种架构下,对内存的访问时间取决于内存地址与具体核心之间的相对地址。在 NUMA 中,核心访问自己的本地内存比访问非本地内存(另一个核心的本地内存或者核心之间的共享内存)要快。NUMA 的优势局限于一些特定任务,尤其是对于那些数据经常与特定任务或者用户具有强关联关系的服务器。解决了SMP的扩展问题,但当核心数量很多时,核心访问非本地内存开销很大,性能增长会减慢。
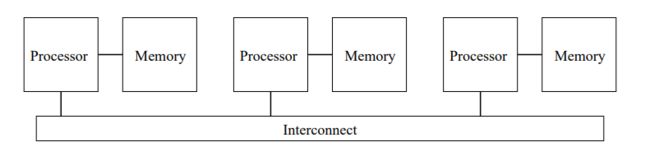 图2 NUMA架构
图2 NUMA架构
CLH 队列锁
简介
在共享内存多处理器环境中,维护共享数据结构的逻辑一致性是一个普遍问题。将这些数据结构用锁保护起来是维持这种一致性的标准技术。需要访问数据的进程(下文中进程,线程,process 都可以看做一个概念,并发运行的程序单位)必须先获取这个数据对应的锁。获取锁之后,进程就独占了对这个数据的访问权知道进行将锁释放。其对锁进行请求的进程都必须进行等待。在持有锁的进程释放锁之后,等待进程的其中一个会获取这把锁,同时其他进程接着等待。
等待进程的等待方式也分两种:被动等待(让出CPU)或者主动等待(自旋)。被动等待就是,进程注册对锁的请求然后阻塞,以便在它等待的时候其他进程可以利用处理器。当锁被释放时,已注册的进程中的其中一个会获取锁。于是被选中的进程就会被解除阻塞在调度就绪时运行。主动等待就是,最典型的就是进程进入一个不断重复检测锁状态并且/或者尝试获取锁对象的紧凑循环(tight loop)。一旦它获取锁对象,就进入受保护数据运行程序。
Anderson[2] 和 Mellor-Crummey 与 Scott[3]提供了对等待方式优缺点的讨论。直观上感觉自旋就是CPU在空转,肯定比阻塞等待浪费性能,但实际上对于小任务,空转时间很短,锁很快就被释放,与阻塞方式在进程状态管理和切换不可忽略的系统开销相比,自旋的代价比阻塞和恢复进程反而小。CLH 锁就是自旋锁的这种被动方式的实践。
队列自旋锁的一个潜在优势就是等待进程不在同一个内存地址上自旋。对于 NUMA 甚至可以达到每个进程都在处理的核心对应的本地内存上自旋,就这降低了各个核心和内存之间互联互通的负载。尤其是在对于某一时间若干等待进程对锁的高争用情况,这点尤其重要。另外队列自旋锁还可以用 FIFO 队列保证对进程的某种公平性和对避免饥饿的保证。
CLH 队列锁中的结构(FIFO 队列)
没有特殊情况我们面对的基本上都是 SMP 架构的系统,这里就只分析最基础的对于 FIFO 队列的锁,优先队列锁和对于 NUMA 系统的锁不做解析。
- Request :对锁的请求,包含一个 state 状态(Granted 表示可以将锁授权给他的监视进程,Pending 表示他的监视进程需挂起等待)
- Lock : 锁对象,包含一个 tail 指针,初始化时指向一个 state = G 的请求
- Process :需要请求锁的进程,包含两个请求指针为 myreq 和 watch ,myreq 指向当前进程对应的锁请求,当进程为获取锁或者获取锁但未释放是,myreq.state = P;当进程释放锁时,myreq.state = G。watch 指向前驱进程的 myreq 请求,监听其状态变化。
结构图如图3(a)所示:
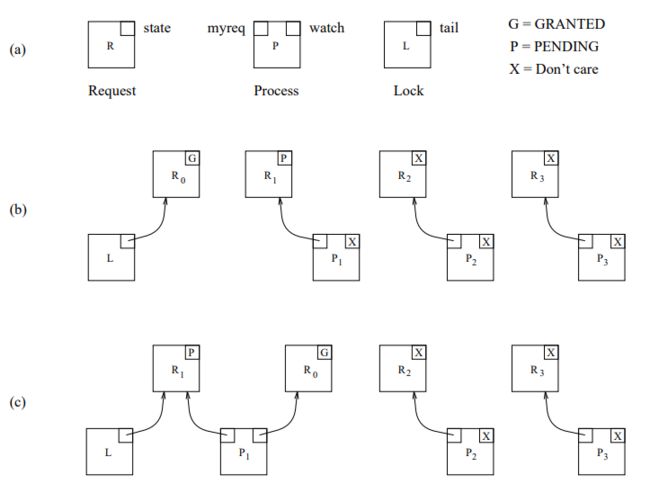 图3 CLH队列锁结构
图3 CLH队列锁结构
队列锁工作步骤如下:
- 初始状态下,锁对象 L.tail 指向一个状态为 G 的 Request R0;
- 接着某进程 P 请求锁,P.myreq 指向一个状态为 P 的 Request,同时 Request tmp = L.tail,L.tail = P.myreq P.watch = tmp,就是将 P 插入到队列的队尾。之后 P 就在其前驱进程的 myreq 请求(也就是 P.watch)上自旋,直到 P.watch 的状态变为 G ,然后获取锁对象,运行程序,最后解锁。
- 当进程 P 运行结束后进行解锁操作,P.myreq 的 state 由 P 置为 G ,并且将 P.myreq = P.watch(原因下文解释)
图3(b) 表示初始状态下,有三个进程 P1,P2,P3,P1 已经将状态置为 P ,准备入队。
图3(c) 表示 进程 P1 已经入队之后的状态,此时 P1 可以获取锁。
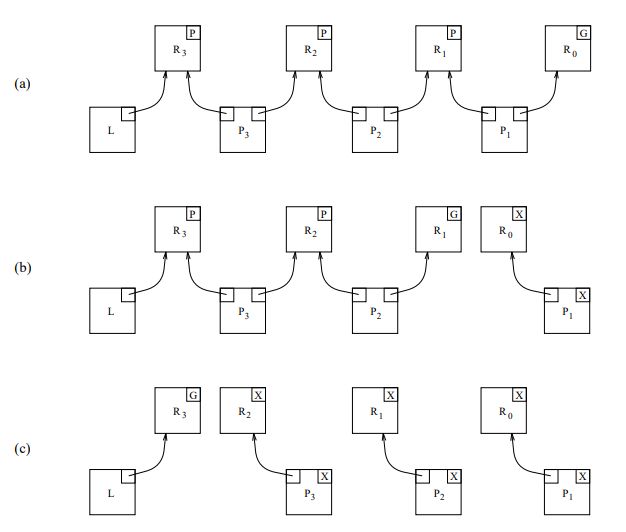 图4 CLH 队列锁结构2
图4 CLH 队列锁结构2
图4(a) 表示进程 P1,P2,P3 都已入队。
图4(b) 表示进程 P1 已经执行完毕并释放锁。P2 可以获取锁。
图4(c) 表示进程 P1,P2,P3 都已运行完毕释放锁。队列中无等待进程。
CLH 队列锁的 java 实现
State 类
/**
* ClassName:State
* Function:request状态.
* Reason:request状态.
* Date:2017/9/12 8:34
*
* @since JDK 1.8
*/
public enum State {
/**
* PENDING: 该状态的request对应的线程等待锁.
*
* @since JDK 1.8
*/
PENDING,
/**
* GRANTED: 该状态的request对应的线程可以获取锁.
*
* @since JDK 1.8
*/
GRANTED
}Lock 类
import java.util.concurrent.atomic.AtomicReference;
/**
* ClassName:Lock
* Function:CLH队列锁的Lock对象.
* Reason:CLH队列锁的Lock对象.
* Date:2017/9/11 16:55
*
* @since JDK 1.8
*/
public class Lock {
/**
* tail: tail指针指向最后一个加入队列的process的myreq.
* 由于入队操作涉及的几个指针赋值逻辑上不可分割,否则会出现问题,
* 所以对request指针都采用原子类。
*
* @since JDK 1.8
*/
private AtomicReference tail;
Lock() {
//初始状态,tail指向一个不属于任何线程,状态为GRANTED的request
tail = new AtomicReference(new Request(State.GRANTED, null));
}
AtomicReference getTail() {
return tail;
}
public void setTail(AtomicReference tail) {
this.tail = tail;
}
} Request 类
/**
* ClassName:Request
* Function:对锁的请求.
* Reason:对锁的请求.
* Date:2017/9/11 16:55
*
* @since JDK 1.8
*/
public class Request {
/**
* myProcess: 发起该请求的线程,myreq对应的myProcess.
*
* @since JDK 1.8
*/
private Process myProcess;
/**
* state: 请求状态,PENDING 表示对应线程等待,GRANTED 表示对应线程可以获取锁.
*
* @since JDK 1.8
*/
private State state;
Request(State state, Process myProcess) {
this.myProcess = myProcess;
this.state = state;
}
public Request(State state) {
this.state = state;
}
State getState() {
return state;
}
void setState(State state) {
this.state = state;
}
Process getMyProcess() {
return myProcess;
}
public void setMyProcess(Process myProcess) {
this.myProcess = myProcess;
}
}Process 类
/**
* ClassName:Process
* Function:请求锁的线程.
* Reason:请求锁的线程.
* Date:2017/9/11 17:01
*
* @since JDK 1.8
*/
public class Process implements Runnable {
/**
* clh: 线程请求的clh锁.
*
* @since JDK 1.8
*/
private CLH clh;
/**
* name: 当前线程名,方便观察,request对象与线程的对应关系.
*
* @since JDK 1.8
*/
private String name;
Process(String name, CLH clh) {
this.clh = clh;
this.name = name;
}
@Override
public void run() {
//1.请求锁
clh.lock(this);
//2.程序性等待,获取锁之后等待2秒钟,释放锁
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//释放锁
clh.unlock();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}CLH 队列锁类
/**
* ClassName:CLH
* Function:CLH 队列锁.
* Reason:CLH 队列锁.
* Date:2017/9/11 16:59
*
* @since JDK 1.8
*/
public class CLH {
/**
* lock: clh队列锁的lock对象.
* @since JDK 1.8
*/
private Lock lock;
/**
* watch: 当前线程自旋监视的目标Request,为前驱process的myreq.
*
* @since JDK 1.8
*/
private ThreadLocal watch;
/**
* myreq: 当前线程持有的Request,当且仅当当前线程释放锁后更新为GRANTED状态,否则为PENDING状态.
*
* @since JDK 1.8
*/
private ThreadLocal myreq;
private CLH() {
this.lock = new Lock();
//初始化myreq对象,状态为PENDING,对应的线程为当前的myProcess
this.myreq = ThreadLocal.withInitial(() -> new Request(State.PENDING));
//watch 初始化为null,加入到队列之后,会指向前驱process的myreq
this.watch = new ThreadLocal();
}
/**
* lock:请求锁.
*/
public void lock(Process process) {
myreq.get().setState(State.PENDING);
myreq.get().setMyProcess(process);
Request tmp = lock.getTail().getAndSet(myreq.get());
watch.set(tmp);
boolean flag = true;
while (watch.get().getState() == State.PENDING) {
try {
if (watch.get().getMyProcess() != null) {
if (flag) {
System.out.println(" " + myreq.get().getMyProcess().getName() + " | is waiting for " + watch.get().getMyProcess().getName()
+ " | " + myreq.get().getState() + " | " + watch.get().getState() + " | " +
"added to queue | ");
} else {
System.out.println(" " + myreq.get().getMyProcess().getName() + " | is waiting for " + watch.get().getMyProcess().getName()
+ " | " + myreq.get().getState() + " | " + watch.get().getState() + " | " +
" |");
}
if (lock.getTail().get().equals(myreq.get())) {
System.out.println("— — — — — — — — — — — — — — — — — — — — — — — — |");
}
}
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = false;
}
if (flag) {
System.out.println(" " + myreq.get().getMyProcess().getName() + " | get lock | " + myreq.get().getState() +
" | " + watch.get().getState() + " | added to queue | ");
} else {
System.out.println(" " + myreq.get().getMyProcess().getName() + " | get lock | " + myreq.get().getState() +
" | " + watch.get().getState() + " | |");
}
if (lock.getTail().get().equals(myreq.get())) {
System.out.println("— — — — — — — — — — — — — — — — — — — — — — — — |");
}
}
/**
* unlock:释放锁.
*/
public void unlock() {
myreq.get().setState(State.GRANTED);
System.out.println(" " + myreq.get().getMyProcess().getName() + " | release lock | " + myreq.get().getState() +
" | X | remove from queue |");
if (lock.getTail().get().equals(myreq.get())) {
System.out.println("— — — — — — — — — — — — — — — — — — — — — — — — |");
}
// threadlocal 类型使用之后强制remove保证没有内存溢出
myreq.remove();
myreq.set(watch.get());
//释放锁之后,watch字段不关心,置空,并且可以保证无内存溢出
watch.remove();
}
public Lock getLock() {
return lock;
}
public void setLock(Lock lock) {
this.lock = lock;
}
public ThreadLocal getWatch() {
return watch;
}
public void setWatch(ThreadLocal watch) {
this.watch = watch;
}
public ThreadLocal getMyreq() {
return myreq;
}
public void setMyreq(ThreadLocal myreq) {
this.myreq = myreq;
}
public static void main(String[] args) throws InterruptedException {
CLH clh = new CLH();
Process process1 = new Process("p1",clh);
Process process2 = new Process("p2",clh);
Process process3 = new Process("p3",clh);
Process process4 = new Process("p4",clh);
System.out.println(" 线程 | action | myreq | watch | queue |");
System.out.println("— — — — — — — — — — — — — — — — — — — — — — — — |");
new Thread(process1).start();
Thread.sleep(100);
new Thread(process2).start();
Thread.sleep(100);
new Thread(process3).start();
}
} CLH 的 myreq 和 watch 采用 ThreadLocal 类型,之前我写的对于ThreadLocal的介绍就是为此服务的,这里对于调用CLH的lock()方法的每个新的线程,由于是 ThreadLocal 类型,所以都会自动为其分配新的 myreq 和 watch 对象,达到线程间数据隔离的目的。
main() 方法中首先创建CLH队列锁实例,之后创建了三个线程p1,p2,p3,每个线程的run()方法都会按序调用 clh.lock()和 clh.unlock(),添加运行状态的日志打印语句之后,执行结果如下:
 图5 CLH 队列锁打印日志
图5 CLH 队列锁打印日志
结果非常清晰:
- 程序启动时 p1 入队,因为 p1.watch 的 request 对象状态为 GRANTED 所以 p1 获取锁;
- p2 入队, p2.watch 指向 p1.myreq 状态为 PENDING ,所以 p2 等待 p1 释放锁;
- p3 入队, p3.watch 指向 p2.myreq 状态为 PENDING ,所以 p3 等待 p2 释放锁;
- p1 释放锁,p1.myreq 状态更新为 GRANTED ,p1.myreq = p1.watch,p1 出队,p2.watch = p1.myreq 发现更新为 GRANTED , p2 获取锁,p3.watch 指向 p2.myreq 状态仍然为 PENDING , p3 继续等待 p2 释放锁;
- p2 释放锁,p2.myreq 状态更新为 GRANTED ,p2.myreq = p2.watch,p2 出队,p3.watch = p2.myreq 发现更新为 GRANTED , p3 获取锁,此时队列中仅剩 p3 一个线程;
- 最后 p3 运行完业务后释放锁,p3 出队,程序结束。
释放锁时候的问题
CLH 队列锁论文原文[1]中关于释放锁时候的具体过程有一句话,很重要:
Then the releaser alters its own Process record to take ownership of the Request that was granted to it by its predecessor.
以图4(a)到图4(b)的 P1 释放锁过程解释,在 P1 释放锁,将锁的控制权传递给 P2 之后,原本 P1.myreq = R1,P1.watch = R0 , 此时 P1.watch 会赋值给 P1.myreq 使得 P1.myreq 指向 R0。
那么究竟为什么要在释放锁时多做这一步呢?如果不这么做又有什么后果呢?请看下图:
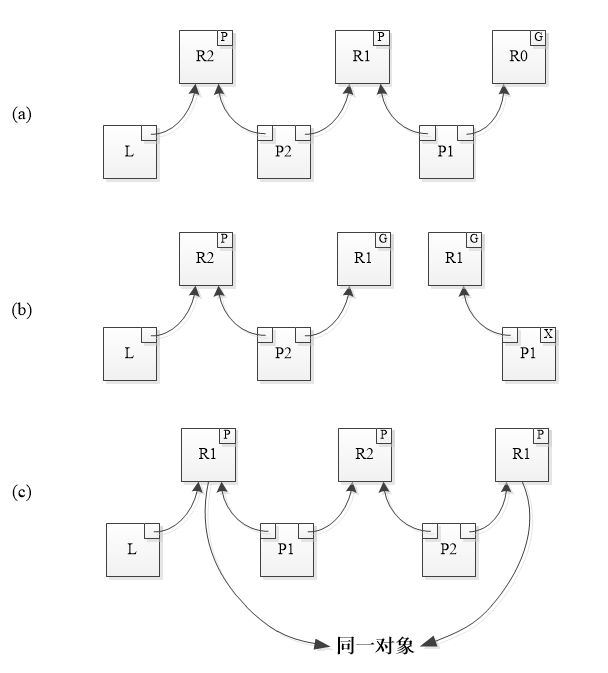 图6 释放锁未更新process.myreq = process.watch 引发问题
图6 释放锁未更新process.myreq = process.watch 引发问题
- 图6(a) 队列中 P1,P2 已经入队,此时 P1 获取锁;
- 图6(b) P1 释放锁,P1.myreq 指向的 R1 状态更新为 GRANTED, 原本 process.myreq 指向 R1 ,释放锁之后 process.myreq 更新之后会指向 R0,但此时未执行 process.myreq = process.watch,所以 P1.myreq 还是指向 R1;
- 由于 P2.watch 指向 R1 状态为 GRANTED,于是 P2 准备获取锁,此时考虑以下情况:在 P1 释放锁之后 P2 获取锁之前,P1 再次调用 lock() ,P1 准备入队,那么 P1.myreq 指向的 R1 状态又会变为 PENDING ,P1 再次入队,在 P1 入队之后 P2 开始获取锁的自旋操作,此时队列情况如图6(c)所示。P1.watch 指向 R2 , P2.watch 指向 R1 状态都为 PENDING ,于是 P1 等待 P2 释放锁,P2 又等待 P1 释放锁,死锁形成!
将上文的代码按这个错误步骤改造之后, 按顺序执行 P1.lock() P2.lock() P1.unlock() 在 P2.lock() 未获取锁再次调用 P1.lock(),结果如下:
 图7 死锁结果
图7 死锁结果
这就是为什么释放锁的时候 process.myreq 一定要更为为 process.watch 的原因。当然你也可以重新创建一个新的 Request 对象赋给 process.myreq , 但有现成的 process.watch 对象可以废物利用,何必要重新去创建一个呢。
CLH 算法的优势
之后原文再次解释:
A key idea in our algorithms, then, is to exchange ownership of Request records each time a process is granted the lock. When a lock is initialized, it is allocated a Request record that is marked as GRANTED. When a process is initialized, it is allocated a Request record, too. A side effect of this change is to remove the requirement for a Request record per lock per process in the Graunke and Thakkar scheme (O(L*P) Requests in a system with L locks and P processes). Our scheme uses just one Request per lock or process in the system (O(L+P) Requests). Besides saving space, it seems easier to manage our structures in a system where the number of locks and/or processes might not be known beforehand.
CLH 算法的核心思想是每次只要某个 process 释放锁(granted the lock)线程就会交换 Request 对象的拥有权。当某个 CLH 锁初始化时,会为其 tail 指针分配一个状态为 GRANTED 的 Request 对象。当一个 process 初始化时,也会为其分配一个 myreq Request 对象。这个设计带来的一个副作用就是此模式消除了 Graunke 和 Thakkar 模式(在此模式中对于一个有 L 把锁和 P 个 process 的系统来说,空间复杂度为O(L*P))对于每锁每 process 都需要分配一个 Request 对象的强制要求。CLH 算法模式中系统只需要为每把锁或者每个 process 分配一个 Request 对象(空间复杂度 O(L+P))。本算法除了更加节省空间,对于那些我们事先不清楚到底有多少锁和/或 process 的系统似乎也更容易对其数据和结构进行管理。
参考文献
- Building FIFO and Priority-Queuing Spin Locks from Atomic Swap
- The Performance of Spin Lock Alternatives for SharedMemory Multiprocessors
- Algorithms for Scalable Synchronization on SharedMemory Multiprocessor
- Why CLH Lock need prev-Node in java