从实际蹲坑中涨姿势之——彻底搞懂Mysql事务隔离级别
一、业务背景
最近在做一个类似于任务分发的平台,分为任务管理平台和作业机,任务管理平台负责接收作业机的请求,并为作业机分配任务,所有的任务都存在表t_task_info,其使用一个字段task_status(0排队中,作业机就是获取这种状态的数据)表示任务的状态;同时系统配备N台执行任务的作业机。
实际发生问题:实际运行过程中发现多台作业机竟然争抢到了同一个任务,换句话说就是一个任务同一时刻被多处运行。
二、上代码
所有代码进行了修改和精简,只留下问题相关的核心代码。
controller
@GetMapping("/api/getTask")
@ResponseBody
public Jo getTask(){
//省略若干代码...
Jo jo = taskRunHistoryService.getLatestTask(...);
return jo;
}
service
public Jo getLatestTask(...) {
...
//准备从数据库查询任务
TaskInfo taskInfo = this.syncGetTask(...);
if (taskRunHistory == null) {
return Jo.failed().setMsg("没有可执行任务!");
}
...
return Jo.success().setData(map);
}
private TaskInfo syncGetTask(...){
...
//加锁,同一时刻只允许一个作业机获取任务,避免并发发生同一个任务被多个作业机抢到。
boolean locked = this.sysLock.lock();
if(!locked) {
//没有获取到锁
return null;
}
TransactionStatus transactionStatus1 = null;
try {
...
//从数据库查询任务状态为0的任务
taskInfo = taskInfoDao.getNeedRun(...);
if(taskRunHistory != null) {
...
//手动开启一个事务
transactionStatus1 = dataSourceTransactionManager.getTransaction(def);
//修改任务状态为1
this.taskInfoDao.updateStatus(...);
//提交事务
dataSourceTransactionManager.commit(transactionStatus1);
}
}catch (Exception e) {
...
}finally {
//释放锁
boolean result = this.sysLock.unlock();
...
}
return taskInfo;
}
三、问题分析
使用spring的事务管理大家都知道,spring和事务相关的有个东西叫做事务传播行为,一般情况下,service的方法调用都会自动开启一个事务,如果是方法嵌套调用,默认就会合并到同一个事务。在上述代码中,除了spring默认为我们开启的事务之外,我们还手动开启了一个事务,用于在锁内更新任务状态。而当数据库的事务隔离级别为RR的时候,其他线程事务发生修改并提交的数据,对当前事务的查询操作是不可见的。
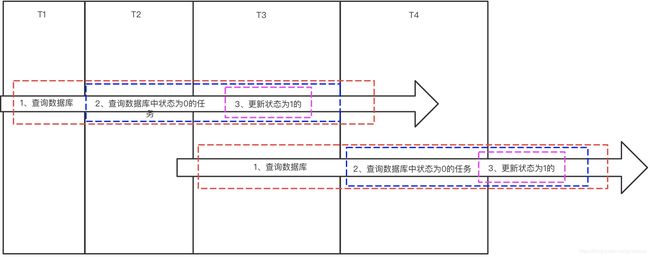
1、在T1时刻,1号作业机启动第一个事务(红虚线框),并且在T2获得锁(锁范围是蓝色框),从数据库查询得到一条状态为0的数据
2、1号作业机在T3手动开启了一个事务(紫色虚线框),而同时2号作业机在T2时刻spring也默认启动事务,1号作业机的紫色框和2号的红色框在时间上有了重合了,因此根据数据库的“可重复读”特性,1号作业机在紫色框中修改的状态实际上对2号作业机红框事务范围内是不可见的。
3、在T4时刻1号作业机的请求被处理完成,释放锁,刚好被2号作业机获取到锁,进行数据库查询。根据上面第2条“可重复读”特性知道,这个时候2号查询的数据实际上发生了重复读现象,因此会将刚刚被1号作业机获取的任务再次返回给2号作业机。
到此,作业机争抢任务的问题被最终定位找到了!!!。
四、解决方案
定位问题后,解决方案基本已经可以确定,只要1号作业机的“更新状态为1”事务和2号机的“查询数据库状态为0”事务之间没有任何时间重叠即可避免此问题产生。而最简单的方案就是将“查询状态为0”的操作放入紫色方框事务中。
因此,修改后的servcie代码如下:
private TaskInfo syncGetTask(...){
...
//加锁,同一时刻只允许一个作业机获取任务,避免并发发生同一个任务被多个作业机抢到。
boolean locked = this.sysLock.lock();
if(!locked) {
//没有获取到锁
return null;
}
TransactionStatus transactionStatus1 = null;
try {
...
//手动开启一个事务
transactionStatus1 = dataSourceTransactionManager.getTransaction(def);
//从数据库查询任务状态为0的任务
taskInfo = taskInfoDao.getNeedRun(...);
if(taskRunHistory != null) {
...
//修改任务状态为1
this.taskInfoDao.updateStatus(...);
}
}catch (Exception e) {
...
}finally {
if(transactionStatus1 != null) {
//提交事务
dataSourceTransactionManager.commit(transactionStatus1);
}
//释放锁
boolean result = this.sysLock.unlock();
...
}
return taskInfo;
}
五、问题延伸
为什么在“可重复读”的隔离下,事务之间的修改是不可见的?
为了搞清楚这个问题,我们需要了解Mysql的“可重复读”实现原理:MVCC
首先回顾下相关知识:
5.1 事务的特性
原子性:指处于同一个事务中的多条语句是不可分割的。
一致性:事务必须使数据库从一个一致性状态变换到另外一个一致性状态。比如转账,转账前两个账户余额之和为2k,转账之后也应该是2K。
隔离性:指多线程环境下,一个线程中的事务不能被其他线程中的事务打扰
持久性:事务一旦提交,就应该被永久保存起来。
5.2 事务隔离性问题
脏读:指一个线程中的事务读取到了另外一个线程中未提交的数据。
不可重复读:指一个线程中的事务读取到了另外一个线程中提交的update的数据。
幻读:指一个线程中的事务读取到了另外一个线程中提交的insert的数据。
5.3 隔离级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
级别越高,数据越安全,但性能越低。
5.4 MySQL的可重复读、幻读及实现原理
本章节内容直接转载自「杨龙飞的博客」文章:https://blog.csdn.net/whoamiyang/article/details/51901888
5.4.1 MVCC简介
1.1 什么是MVCC
MVCC多版本并发控制(Multi-Version Concurrency Control)是MySQL中基于乐观锁理论实现隔离级别的方式,用于实现读已提交和可重复读取隔离级别。
1.2 MVCC是为了解决什么问题?
大多数的MySQL事务型存储引擎,如,InnoDB,Falcon以及PBXT都不使用一种简单的行锁机制.事实上,他们都和MVCC–多版本并发控制来一起使用.
大家都应该知道,锁机制可以控制并发操作,但是其系统开销较大,而MVCC可以在大多数情况下代替行级锁,使用MVCC,能降低其系统开销.
1.3 MVCC实现
MVCC是通过保存数据在某个时间点的快照来实现的. 不同存储引擎的MVCC实现是不同的,典型的有乐观并发控制和悲观并发控制.
5.4.2 MVCC 具体实现分析
下面,我们通过InnoDB的MVCC实现来分析MVCC使怎样进行并发控制的.
InnoDB的MVCC,是通过在每行记录后面保存两个隐藏的列来实现的,这两个列,分别保存了这个行的创建时间,一个保存的是行的删除时间。这里存储的并不是实际的时间值,而是系统版本号(可以理解为事务的ID),每开始一个新的事务,系统版本号就会自动递增,事务开始时刻的系统版本号会作为事务的ID.下面看一下在REPEATABLE READ隔离级别下,MVCC具体是如何操作的.
补充两点
1、开启一个事务并不会立即分配一个事务ID,而是需要执行SQL语句的时候才会分配一个SQLID。(此为实际测验出的结果,MySQL测试版本为5.6,centos 6.5)
2、获得当前会话的TRX_ID 事务ID
SELECT TRX_ID FROM INFORMATION_SCHEMA.INNODB_TRX WHERE TRX_MYSQL_THREAD_ID = CONNECTION_ID();
2.1简单的小例子
create table yang(
id int primary key auto_increment,
name varchar(20));
假设版本号从1开始.
INSERT
InnoDB为新插入的每一行保存当前系统版本号作为版本号.
第一个事务ID为1;
start transaction;
insert into yang values(NULL,'yang') ;
insert into yang values(NULL,'long');
insert into yang values(NULL,'fei');
commit;
对应在数据中的表如下(后面两列是隐藏列,我们通过查询语句并看不到)
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | undefined |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
SELECT
InnoDB会根据以下两个条件检查每行记录:
a.InnoDB只会查找版本早于当前事务版本的数据行(也就是,行的系统版本号小于或等于事务的系统版本号),这样可以确保事务读取的行,要么是在事务开始前已经存在的,要么是事务自身插入或者修改过的.
b.行的删除版本要么未定义,要么大于当前事务版本号,这可以确保事务读取到的行,在事务开始之前未被删除.
只有a,b同时满足的记录,才能返回作为查询结果.
DELETE
InnoDB会为删除的每一行保存当前系统的版本号(事务的ID)作为删除标识.
看下面的具体例子分析:
第二个事务,ID为2;
start transaction;
select * from yang; //(1)
select * from yang; //(2)
commit;
假设1:假设在执行这个事务ID为2的过程中,刚执行到(1),这时,有另一个事务ID为3往这个表里插入了一条数据;
第三个事务ID为3;
start transaction;
insert into yang values(NULL,'tian');
commit;
这时表中的数据如下:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | undefined |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
| 4 | tian | 3 | undefined |
然后接着执行事务2中的(2),由于id=4的数据的创建时间(事务ID为3)大于执行当前事务的ID为2,而InnoDB只会查找事务ID小于等于当前事务ID的数据行,所以id=4的数据行并不会在执行事务2中的(2)被检索出来,在事务2中的两条select 语句检索出来的数据都只会下表:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | undefined |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
假设2:假设在执行这个事务ID为2的过程中,刚执行到(1),假设事务执行完事务3后,接着又执行了事务4;
第四个事务:
start transaction;
delete from yang where id=1;
commit;
此时数据库中的表如下:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
| 4 | tian | 3 | undefined |
接着执行事务ID为2的事务(2),根据SELECT 检索条件可以知道,它会检索创建时间(创建事务的ID)小于当前事务ID的行和删除时间(删除事务的ID)大于当前事务的行,而id=4的行上面已经说过,而id=1的行由于删除时间(删除事务的ID)大于当前事务的ID,所以事务2的(2)select * from yang也会把id=1的数据检索出来.所以,事务2中的两条select 语句检索出来的数据都如下:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | undefined |
| 3 | fei | 1 | undefined |
UPDATE
InnoDB执行UPDATE,实际上是新插入了一行记录,并保存其创建时间为当前事务的ID,同时保存当前事务ID到要UPDATE的行的删除时间.
假设3:假设在执行完事务2的(1)后,其它用户执行了事务3,4,这时,又有一个用户对这张表执行了UPDATE操作:
第5个事务:
start transaction;
update yang set name='Long' where id=2;
commit;
根据update的更新原则:会生成新的一行,并在原来要修改的列的删除时间列上添加本事务ID,得到表如下:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | 5 |
| 3 | fei | 1 | undefined |
| 4 | tian | 3 | undefined |
| 2 | Long | 5 | undefined |
继续执行事务2的(2),根据select 语句的检索条件,得到下表:
| id | name | 创建时间(事务ID) | 删除时间(事务ID) |
|---|---|---|---|
| 1 | yang | 1 | 4 |
| 2 | long | 1 | 5 |
| 3 | fei | 1 | undefined |
还是和事务2中(1)select 得到相同的结果.