python大数据基础知识点(Hadoop+HDFS+MapReduce+Hive+Hbase)
python大数据基础知识点
***概述
起源:Google 3篇论文 GFS ,MapReduce ,BigTable
Doug Cutting 写 Hadoop
HDFS - GFS,
MapReduce -- MapReduce,
HBase--- BigTable
hadoop主要分类:
1. apache组织的 开源版 互联网
2. cloudera CDH
雇佣 Doug Cutting 4000美金
3,Hortonworks 最初apache组织 hadoop的开发人员 创立12000美元 (10个)
一,大数据基础:
1,4v特点:大量的;多样性(结构化-数据库,半结构化json,非结构化-音视频)
快速的-处理数据快;价值-在海量没有价值的低价值的数据中获取有价值的
2,数据怎么存?
HDFS,hadoop分布式文件存储系统hadoop distributed file system
主从式架构:nameNode,dataNode
nameNode:维护目录结构;记录文件相关信息-权限大小所属组;DataNode与文件块对应关系 副本集。
DataNode:以块的形式128M存储数据;存储副本集保证数据的安全;校验和,检验文件是否损坏。
3,怎么运算,处理数据?
移动代码,以MapReduce方式移动
yarn集群机制来监控Map和Reduce处理数据,并调度计算机cpu内存网络等资源
二,搭建hadoop集群单节点:(伪分布式集群)
1,设置网络、主机名和主机映射,关闭防火墙和selinux
2,安装JDK
3,上传并解压hadoop安装版:一般放置在/etc/opt/install/hadoop
tar -zxvf hadoopxxx.tar.gz -C /opt/install
4,配置文件:hadoop环境jdk,hadoop四大模块配置
hadoop-env.sh :export JAVA_HOME =/usr/java/jdk1.8xxx
hadoop_home/etc/hadoop/core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
5,启动单集群单节点:
先初始化hadoop_home:bin/hdfs namenode -format
启动nameNone,dataNode,yarn-resourcemanager-nodemanager
jps查看进程
通过网络访问:
HDFS http://hadoop.jun.com:50070
yarn http://hadoop.jun.com:8088
三,HDFS系统的访问和操作:
主从式架构,namenode对外client提供访问;
访问和操作:存储、读取数据、删除数据、创建目录;
客户端通过shell命令行和python代码来访问HDFS.
1,常用shell命令:在hadoop_home下:
bin/hdfs dfs -ls /
bin/hdfs dfs -mkdir -p /xiaoming/daming
bin/hdfs dfs -put 本地目录 /jun远程目录
bin/hdfs dfs -text/-cat /jun 查看文本文件
bin/hdfs dfs -get hdfs目录 本地目录:下载
bin/hdfs dfs -rm -r /jun/text :删除
bin/hdfs dfs -cp 原始位置 目标位置 复制
bin/hdfs dfs -mv 原始位置 目标位置 移动
2,垃圾箱保存时间:
core-site.xml:
3,HDFS权限问题:客户端要上传文件需要
hdfs-site.xml:
4,python访问:
pip install hdfs
from hdfs import Client
client = Client("http://192.xxx:50070")
files = client.list('/')
upload('/',‘text’); download('/jun','ce')
delete('/jun',True);makedirs('jun');
rename('')改名
5,ssh免密登录:
生成公私秘钥:ssh-keygen -t rsa
(生成在~/.ssh目录下id_rsa是私,id_rsa.pub公)
发送到远端主机:ssh-copy-id root@ip
(会添加到远端主机的authorized_keys文件中)
四,HDFS集群搭建:
1,设置网络、主机名和主机映射,关闭防火墙和selinux
2,安装JDK
3,所有节点安装相同版本hadoop安装版:一般放置在/etc/opt/install/hadoop
tar -zxvf hadoopxxx.tar.gz -C /opt/install
4,进行ssh免密登录
5,修改4大配置文件与hadoop-env.sh
6,修改hadoop-home/etc/hadoop/slaves文件为集群所有节点机器名称:
hadoop1.com hadoop2.com
7,删除data/temp目录
8,启动集群:
先格式化:bin/hdfs namenode -format
sbin/star-dfs.sh
sbin/stop-dfs.sh
五,HDFS高级理论:
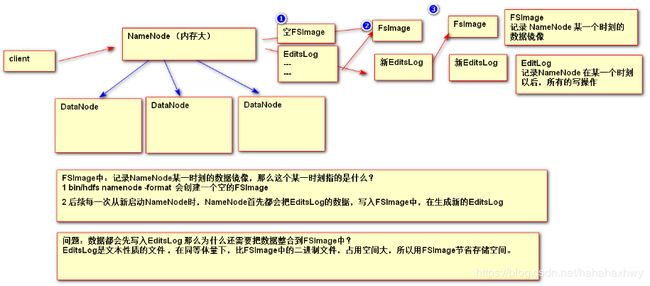
1,NameNode的持久化:由于NameNode所使用的数据,存储在内存,那么如果进程出现问题,内存中的重要数据就会丢失,
为了解决上述问题,HDFS通过FSImage和EditsLog 一起配合进行 NameNode数据的持久化。
FSImage记录NameNode格式化时和重启namenode时的数据镜像(格式化时是新建空的FSImage,重启时namenode把Editlog数据写入FSimage, 再重新生成新的EditsLog)
*FSImage是二进制文件,占用空间少。
FSImage和EditsLog默认存储位置?
/opt/install/hadoop-2.5.2/data/tmp/dfs/name/current,可在hdfs-site.xml配置修改路径
2,安全模式,safemode
重启Namenode时hdfs要合并EditsLog与FSImage,此时禁止写操作,会进入安全模式。手动进入安全模式:#进入安全模式
bin/hdfs dfsadmin -safemode enter
#获得安全模式状态
bin/hdfs dfsadmin -safemode get
#关闭安全模式
bin/hdfs dfsadmin -safemode leave
3,SecondaryNameNode
SecondaryNameNode会定期的获取NameNode的FSImage和EditsLog,并生成一个新的EditsLog为NameNode对外提供服务,后续SecondaryNameNode会合并之前的FSImage和EditsLog,并把合并后新的FSImage还给NameNode. 定期:
时间 默认 1小时;事务数 默认 1万
可以部分还原数据;NameNode与SecondaryNameNode尽量不放在同一节点,避免同时损坏数据不可还原。
4,热添加热删除:
增加:
1. 保证新加的机器 (hosts配置 域名设置 iptables selinux关闭 配置主机到从机 SSH免密码登陆 hadoop安装(core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves))
# clone 删除新机器中的 data/tmp 内容
2. 启动新机器的datanode
sbin/hadoop-daemon.sh start datanode
# namenode
3. 平衡处理sbin/start-balancer.sh
# 为了日后重启集群 不要丢了新加入的节点
4. 修改集群中所有的slave配置文件 把新加入的节点配置进去
热删除:
1. 在namenode主机器中,创建一个新的文件 位置 名字 随便
host.exclusion
hadoop3.baizhiedu.com
2. 配置 hdfs-site.xml
dfs.hosts.exclude 文件的位置 (不加 file://)
3. 通过命令刷新集群,在namenode节点:执行:
bin/hdfs dfsadmin -refreshNodes
4. 把删除的节点 从slaves 删除
5. 把hdfs-site.xml
dfs.hosts.exclude 的信息删除
6. kill 掉 被删除的DataNode
5,HA高可用集群:
HA架构的NameNode,由一个主节点对外提供服务,同时通过Zookeeper把主节点中的内容,自动的同步到备机中,保证主,备数据的一致。如果主机出现问题,备机会通过zookeeper自动升级主节点。
首先,搭建zookeeper集群,为了保证集群裂变后尽量保证节点数多的一方继续对外服务,要求奇数节点;
然后,Hadoop基本环境 还原:删除 hadoop_home/data/tmp 内容
再然后,各配置文件,保证各主从节点都做了ssh免密登录;
最后依次启动:各节点服务
启动服务后,日程启动停止:sbin/start-dfs.sh
sbin/stop-dfs.sh
六,MapReduce:hadoop分布式计算模型

移动代码到数据所在位置进行计算的机制,需要yarn集群来监控作业,调度资源
Map中的NodeManager进程做具体分配与调度工作
Reduce中的ResourceManager进程做全局资源和作业的监控
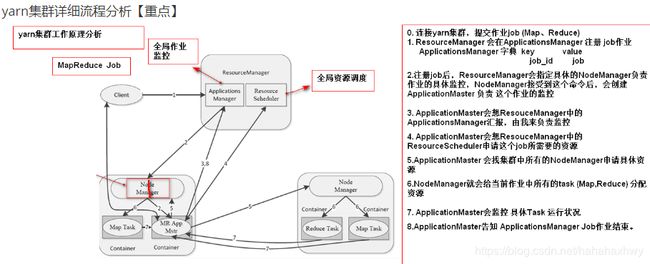
1,yarn集群启动:
单机版:sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
集群版:sbin/start-yarn.sh
sbin/stop-yarn.sh
2,MapReduce的5个核心编程步骤:
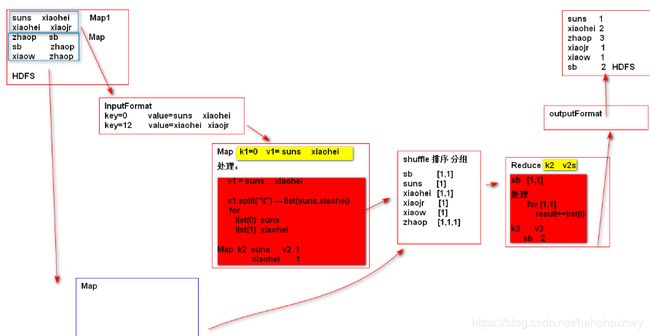
(1)inputFormat获取数据;(2)Map局部处理数据;(3)shuffle排序分组;
(4)Reduce汇总,默认一个,不涉及数据合并就可以没有reduce,数据清洗可没有;(5)outputFormat结果输出。
Map对文本文件有几块数据就有几个Map,对数据库一行数据一个map,可优化。
3,mapReduce存在问题:(1)一个功能就要写一个job麻烦;(2)每个job有大量代码冗余。
七,Hive FaceBook开源的基于hadoop的数据仓库
HIVE可以让程序员像书写SQL语句一样完成对大数据内容的增删改查,数据清洗,去重。
HIVE解决MapReduce两个问题:一个功能要写一个job麻烦;大量代码冗余。
hive最终会根据MetaStore上的对应信息,把sql语句翻译成MapReduce来运行。
MetaStore存储映射关系(默认derby数据库只支持一个连接客户端,要修改为mysql库):关系表user---文件user.txt; id,name ----> 文件中列对应。
1,hive环境搭建过程:
安装hadoop;安装hive的tar包;配置hive-env.sh文件hadoop内置地址;
在hdfs创建/tmp ;启动bin/hive;jps显示runjar进程则启动。
2,Hive中MetaStore的配置:derby该为mysql。
安装mysql:yum install -y mysql-server;
启动:service mysqld start; chkconfig mysqld on;
设置密码:/usr/bin/mysqladmin -u root -password 'xxxx'
登录:mysql -uroot -pxxxx
打开远端访问权限:use mysql
grant all privileges on *.* to root@'%' identified by "123456";
flush privileges;
**修改hive_home/conf/hive-site.xml中mysql相关设置。
**上传mysql驱动jar包到hive的lib目录:
mysql-connector-java-5.1.39-bin.jar
重启service mysqld restart
3,hive语法:sql语句中 * 不启动mr 反之就会启动 mr
show databases
create database [if not exists] db_name #创建数据库
default数据库 位置 /user/hive/warehouse
所谓数据库 对应的就是hdfs 上的一个目录
create table if not exists t_user(
id int,
name string
)row format delimited fields terminated by '\t';
load data local inpath '本地文件的路径' into table t_user;
select * from t_user; #不启动mr
select id,name from t_user where id between 1 and 5;
select id,name from t_user limit 3;
select id from t_user group by id having id >3 ;
select id,name from t_user order by id asc;
select e.id,e.name,d.name from emp as e inner join dept as d
on e.dept_id = d.id;
drop database db_name; #必须保证当前库是空的
drop database db_name cascade #删除非空数据库
#表删除 数据删除
drop table table_name
#表保留 数据删除 TRUNCATE TABLE table_name
管理表:#hive 可以现有数据 在有表的 【重点】
create table if not exists t_test2(
id int,
name string
)row format delimited fields terminated by '\t' location '/t2'。
4,管理表;外部表;分区表;桶表;临时表。
管理表与外部表区别:
hive删除管理表,同时删除管理表在hdfs上所对应的路径,及其文件
hive删除外部表,不会删除hdfs上对应的路径及其文件,删除的是metastroe
#/user/hive/warehouse/db_name.db/table_name
create table if not exists t_test(
id int,
name string
)row format delimited fields terminated by '\t'
#指定表定义的目录
create table if not exists t_test(
id int,
name string
)row format delimited fields terminated by '\t' location '/t1'
#hive 可以先有数据再有表的 【重点】
create table if not exists t_test2(
id int,
name string
)row format delimited fields terminated by '\t' location '/t2'
***Python链接hive:
pip install PyHive
from pyhive import hive
conn = hive.Connection(host='ip地址', port=10000, username='用户名', database='default', auth='NOSASL')
cursor = conn.cursor()
cursor.execute('select * from testhive limit 10')
for result in cursor.fetchall():
print( result)
PV******实例:
#求pv(page view),uv(unique visitor):
1,创建数据库one_source;
2,创建hdfs目录:t_one_source,并上传两个log文件;
3,创建原始表,location定位到已上传文件的hdfs 目录;
#创建管理表,作为原始表:
create table t_one_source
(id string,url string,referer string,keyword string,
type string,guid string,pageId string,moduleId string,
linkId string,attachedInfo string,sessionId string,
trackerU string,trackerType string,ip string,
trackerSrc string,cookie string,orderCode string,
trackTime string,endUserId string,firstLink string,
sessionViewNo string,productId string,
curMerchantId string,provinceId string,cityId string,
fee string,edmActivity string,edmEmail string,
admJobId string,ieVersion string,platform string,
internalKeyword string,resultSum string,
currentPage string,linkPosition string,
buttonPosition string
) row format delimited fields terminated by '\t'
location '/t_one_source/';
4,创建分区表:清洗表t_one_clear(day/hour两级子分区目录)
字段:id, url,guid,day,hour
create table t_one_clear(
id string,
url string,
guid string,
day string,
hour string
)partitioned by(days string,hours string)
row format delimited fields terminated by '\t';
5,从原始表清洗需要的字段,并插入到清洗表中:
insert into table t_one_clear partition(days='28',hours='18') select id,url,guid,substring(trackTime,9,2) day,
substring(trackTime,12,2) hour from t_one_source where substring(trackTime,12,2)=18;
insert into table t_one_clear partition(days='28',hours='19') select id,url,guid,substring(trackTime,9,2) day,
substring(trackTime,12,2) hour from t_one_source where substring(trackTime,12,2)=19;
6,创建结果表t_one_result,导入清洗表的pv,uv汇总结果:
create table t_one_result(
day string, hour string,
pv string, uv string
)row format delimited fields terminated by '\t';
7,向结果表中插入数据:
insert into table t_one_result select max(day),min(hour), count(url),count(distinct guid) from t_one_clear
where days='28' and hours = '18';
insert into table t_one_result select max(day),min(hour), count(url),count(distinct guid) from t_one_clear
where days='28' and hours = '19';
8,从hive的结果表t_one_result导出数据到mysql表:
创建mysql表:t_one_pvuv:
create table t_one_pvuv(
day varchar(12),hour varchar(12),
pv varchar(12),uv varchar(12)
);
从hive表导出结果到mysql表:
bin/sqoop export \
--connect \
jdbc:mysql://hadoop4.com:3306/sqoop \
--username root \
--password 666666 \
--table t_one_pvuv \
--columns day,hour,pv,uv \
--export-dir /user/hive/warehouse/one_source.db/t_one_result \
--num-mappers 1 \
--input-fields-terminated-by '\t'
八,HBase,hadoop的NOSQL数据库
hadoop的Nosql数据库,是Google bigdata开源实现.
Nosql数据库特点:
1. 大多数NoSQL产品 是内存型
2. Schema Less 弱格式化 弱结构化
3. 没有表连接
4. 弱化事物 redis事务 mongoDB没有事务
5. 搭建集群方便
1. kv类型
redis
2. 文档类型 (JSON BSON)
mongoDB
3. 列类型类型 (Column)
HBase、Cassandra
4. 图形类型
NEO4j
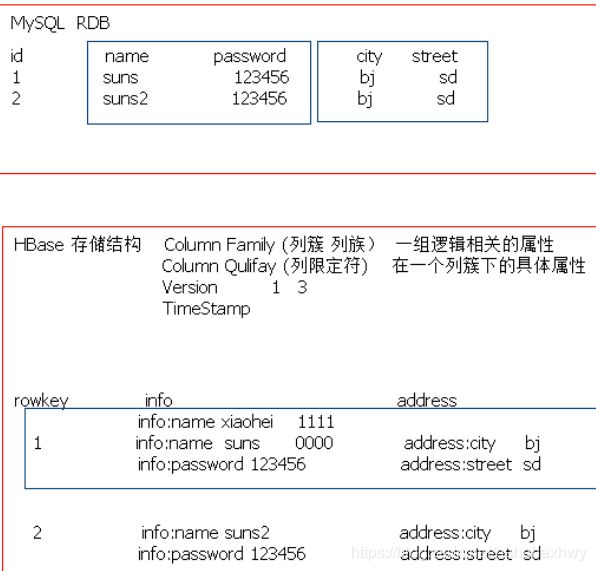
Hbase结构:
- Hbase数据库安装:
- 正确安装hadoop;
- 安装zookeeper集群环境:配置文件conf/zoo.cfg:
dataDir=/opt/install/zookeeper-3.4.5/data
启动zk:bin/zkServer.sh start
bin/zkCli.sh
-
- 安装HBase,下载-上传服务器目录-解压-配置文件:
- Hbase-env.sh; hbase-site.xml;建目录hbase_home/data/tmp
- 安装HBase,下载-上传服务器目录-解压-配置文件:
替换hbase相关hadoop的jar包文件
D) 启动hbase:bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserver
- hbase常用命令:
# 登录HBase
bin/hbase shell
# 数据库 namespace相关命令
list_namespace #查看当前数据库
create_namespace # 创建数据库
create_namespace xxx
drop_namespace # 删除数据库
drop_namespace xxx
describe_namespace # 描述数据库
describe_namespace xxx
list_namespace_tables # 查看数据库下的表
list_namespace_tables xxx
create 'myhbase:t1','f1' //创建库myhbase,表t1,列簇f1
删除表,先让表失效后,再删除
disable 'my:t1'
drop ‘my:t1'
# 删除数据
delete ‘myhb:user','001‘,’info:name‘
#查询:
get ‘myhb:user','001','info:name'
scan 'ns1:tb1'
3,python操作hbase:
# python3版本 happybase
pip install thrift
pip install thrift-sasl
pip install happybase
# 启动 thirt服务
bin/hbase-daemon.sh start thrift
D:\virtual_env\virtual125\Lib\site-packages\thriftpy\parser\parser.py
修改其中的488行为如下情况:
#if url_scheme == '':
if url_scheme in ('e', ''): #报哪个 写哪个
#代码
import happybase
#建议与HBase连接
connection = happybase.Connection(host="192.168.184.16", port=9090)
connection = happybase.Connection(host="hadoop6.com", port=9090)
connection.open()
#建表测试
hbase create ‘myhb:user','f1','f2'
hbase create ‘myhb:user',{NAME=>'cf',VERSIONS=>1},{NAME=>'df'}
families = {
"base":dict(),
"address":dict()
}
connection.create_table(‘myhb:user',families)
#删除表
connection.delete_table(‘myhb:user',disable=True)
#插入一个数据
# 1获取表对象
table = connection.table(‘myhb:user')
hbase put ‘myhb:user',"rowkey","base:name","suns"
table.put("001",{"base:name":"suns"})
table.put("001",{"base:sex":"male"})
table.put("002",{"base:name":"huxz"})
table.put("002",{"address:city":"bj"})
#删除数据
table.delete("001", columns=None, timestamp=None, wal=True)
#查询
info = table.row('001', columns=None, timestamp=None, include_timestamp=False)
print(info)
scanner = table.scan(columns=('address',),limit=2,reverse=True)
print(list(scanner))
#前缀查询 scanner = table.scan(columns=('address',),limit=2,reverse=True,row_prefix = '用户ID')
4,hbase结构:
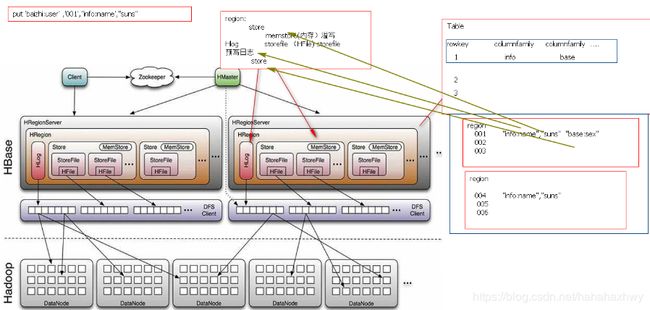
1. HMaster
管理用户对Table的CRUD
管理RegionServer中Region分布
在Region分裂后,负责新Region的分配
RegionServer死机后,迁移Region
2. HRegionServer
管理region
负责响应用户的IO请求,从HDFS系统中读写数据
3. Zookeeper
保证 HMaster 高可用
实时监控RegionServer