Java容器解析之List,Set,Map及HashMap原理
文章目录
- Java容器解析之List,Set,Map及HashMap原理
- List,Set,Map --> Collection
- List
- ArrayList
- LinkedList
- Vector
- CopyOnWriteArrayList
- Set
- HashSet
- LinkedHashSet
- TreeSet
- Map
- HashMap
- LinkedHashMap
- TreeMap
- 其他(Android)
- SparseArray
- ArraySet/ArrayMap
- RandomAccess
- HashMap和HashTable的区别
- HashMap和HashSet的区别
- HashSet如何检查加入的元素重复/HashMap如何检查Key重复?
- HashMap原理
- 1. HashMap结构
- 2. 扰动函数
- 3. 扩容机制
Java容器解析之List,Set,Map及HashMap原理
List,Set,Map --> Collection
List存储一组有序的数据,存储的内容不唯一,可以多个元素引用相同的对象
Set不允许重复的集合,不会有多个元素引用相同的对象
Map通过键值对存储,不同的key可以引用相同的对象,但是key不能重复
List
ArrayList
ArrayList底层结构为Object数组,因此ArrayList的插入和删除元素是通过数组的拷贝进行实现的;数组所需要的内存空间是连续的,因此在进行拷贝的过程中需要寻找合适的大小,每次插入新的元素都需要将之后所有的元素进行后移,删除时将所有元素前移,所以在对数组频繁进行操作的场景下效率比较低;但是在获取元素的时候,是通过数组下标的方式获取,因此查询效率比较高。
LinkedList
LinkedList底层结构为一个双向链表,链表保存前一个元素的位置和后一个元素的位置,因此在进行插入或者删除元素的时候,只需要修改前向指针和后向指针即可,插入和删除元素的效率比较高。但是在进行元素获取的时候,是通过一个for需要移动到需要获取的元素的位置,因此读取的效率比较低。
public void push(E e) {
addFirst(e);
}
public E pop() {
return removeFirst();
}
其中push方法为添加元素到列表头,pop方法为从列表头移除元素。
Vector
Vector和ArrayList的区别为Vector是同步的,意味着Vector是线程安全的,但是因为同步加锁的原因,Vector在性能上是弱于ArrayList的;
Vector和ArrayList底层数组使用完之后,Vector会在当前长度的基础上双倍增加容量(可在构造的时候通过参数限制每次增加的数量),ArrayList则会每次增加一半。
Vector被建议为放弃使用,可以使用Collections.synchronizedList对列表进行同步包装。因为在对Vector进行操作的时候,通常想要同步的为操作序列,对单个操作进行同步是不安全的,依然需要对操作序列进行同步,会影响到性能。
CopyOnWriteArrayList
Vector是在方法上直接通过synchronized进行加锁,相当于对当前对象加锁,而CopyOnWriteArrayList在进行写操作的时候,是在方法内部对方法内容进行加锁。这样在写操作的时候持有的锁不影响读的操作,实现了读写分离。
CopyOnWriteArrayList在写的时候是通过复制一份需要操作的数组的拷贝进行操作,操作完成之后更新数组内容;在写的过程中进行读取则是在原来数组的内容上进行读取。
因为每次写的时候都要拷贝一份原数组进行操作,因此内存占用可能比较大,适用于读多写少的场合。
Set
HashSet
HashSet中添加的元素是唯一的,底层通过HashMap进行实现,HashSet中的元素是无序的,遍历得到元素的顺序和添加的顺序可能不同。
LinkedHashSet
LinkedHashSet是HashSet的子类,LinkedHashSet中按照元素的添加顺序有序存储,因此遍历得到元素的顺序和添加的顺序相同。
TreeSet
TreeSet会对添加的元素进行排序,例如依次添加1,3,2,4,则获取到的顺序为1,2,3,4,我们也可以传入自己的比较器进行排序。
Map
HashMap
同HashSet。
LinkedHashMap
同LinkedHashSet。
TreeMap
同TreeSet。
其他(Android)
SparseArray
SparseArray类似于HashMap,主要在于key均为int值,key和value均通过数组进行存储,在性能上相比HashMap有较大的提升。
如果key值为long,则可以使用LongSparseArray。
根据存储的value不同,可以选择不同的SparseArray,例如存储的long,则可以使用SparseLongArray,boolean类型的可以使用SparseBooleanArray等。
ArraySet/ArrayMap
ArraySet和ArrayMap为底层key和value进行存储,类似于SparseArray,但是对key的类型并没有限制,在内存上进行了优化。
RandomAccess
RandomAccess是一个标志接口,Collections类中通过集合的instanceof方法判断是否实现了RandomAccess接口来判断是否支持快速随机访问,如果支持,则在遍历的时候使用indexedBinarySearch,即通过for循环的方式进行遍历,如果不支持,使用iteratorBinarySearch,即通过迭代器的方式进行遍历。
对于实现了RandomAccess的集合,普通for循环的方式遍历的速度优于使用迭代器的方式遍历;
对于未实现RandomAccess的集合,迭代器的方式遍历的速度优于使用for循环的方式。
为什么实现了RandomAccess使用for循环获取元素快?
因为实现了RandomAccess一般为ArrayList等底层使用数组实现的集合,因此获取元素可直接通过首地址+偏移量(下标)的方式获取元素,而通过迭代器则需要一个一个顺序进行遍历。
为什么未实现RandomAccess使用迭代器获取元素更快?
因为未实现RandomAccess的,例如LinkedList底层使用双向链表进行实现,在地址上不连续,通过for循环然后通过get(i)的方式获取元素,for的时间复杂度为O(n),get的方式也需要通过循环的方式重新从头(二分,或者结尾)查找对应下标位置的元素,总的时间复杂度为O(n^2),而通过迭代器少了get(i)的过程,时间复杂度为O(n),时间的影响主要在get(i)上。
//使用迭代器进行遍历
for (Iterator i=list.iterator(); i.hasNext(); )
i.next();
//使用普通for循环遍历
for (int i=0, n=list.size(); i < n; i++)
list.get(i);
HashMap和HashTable的区别
HashMap是线程不安全的,HashTable是线程安全的,HashTable在性能上弱于HashMap,目前已不建议在代码中使用。
如果使用线程安全的HashMap,建议使用ConcurrentHashMap。
HashMap和HashSet的区别
HashSet的底层使用HashMap进行实现,各种操作均通过操作map进行实现。
HashSet的add方法实际上为在HashMap中添加元素,HashMap的key为HashSet要添加元素,通过HashMap中key不能重复的特性保证HashSet中元素的唯一性 ,value部分为创建了一个Object对象,无实际意义。
public HashSet() {
map = new HashMap<>();
}
//add方法实际上通过
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
HashSet如何检查加入的元素重复/HashMap如何检查Key重复?
HashSet检查元素重复和HashMap检查Key重复调用的都是HashMap的putVal方法。
//其中hash为key的hash值
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)
其中putVal中有这么一段代码,对所有元素进行for循环,判断加入的元素是否重复,其中判断重复如下所示:
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
即当加入的元素和集合中的元素hash值相等的时候,还需要通过==判断对象是否相等或者equals判断对象的值是否相等。
因此我们在自定义自己的数据的时候,如果相同的内容代表同一个对象,则不仅需要重写hashCode方法,同时还要重写equals方法才能保证加入的元素不重复 。
HashMap原理
1. HashMap结构
HashMap由数组+链表+红黑树(1.8新增)组成,如下代码所示:
transient Node<K,V>[] table;
HashMap内部维护了一个Node型数组,Node的结构如下所示:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //保存该节点的hash值(非hashCode,通过hash扰动方法计算的结果),用来进行定位
final K key;
V value;
Node<K,V> next; //指向下一个节点
...
}
2. 扰动函数
HashMap采用数组+链表的方式,在数组的每一个位置都有一个链表结构,当向HashMap中添加元素的时候,首先通过hash方法计算该元素的hash值间接计算元素在数组中的位置,然后将该元素加入到该位置链表的末尾,其中当两个key定位到数组的位置相同时,表明发生了Hash碰撞。HashMap采用链地址法解决Hash碰撞的问题,即发生碰撞时,将元素添加到链表的末尾。
因为当某一位置链表长度较长的时候,当在获取元素的时候,需要对该位置的链表进行遍历进行查找,那么查找数组上该位置链表中的元素的性能就会较差,因此HashMap中需要减少链表的长度以提高性能。
HashMap通过Hash算法计算每个元素在数组中的位置,如果数组的长度比较大,那么可以较为方便的将所有元素映射到HashMap中,例如计算每个元素的hashCode,每个hashCode对应一个下标,则可以保证每个位置只有一个元素,在查找的时候,通过同样的方式计算key对应的下标直接进行获取即可,但是这样会占用比较大的空间,在实际中不可能实现;如果采用较小的数组,那么会增大hash碰撞的概率,即在同一个位置存储多个元素,导致链表长度比较长,查询速度比较慢,因此需要一个较好的hash算法和扩容机制在空间和时间上进行平衡。
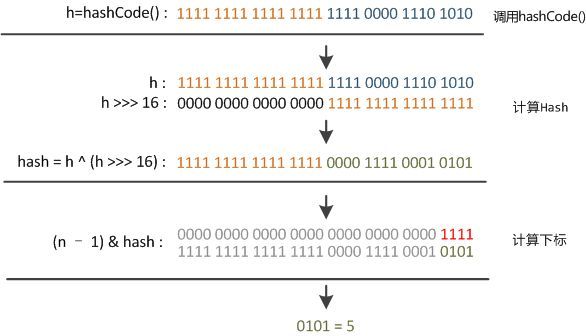
HashMap中通过如下方法计算hash值,该方法又称为“扰动函数”:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//putVal中计算下标
(n - 1) & hash
首先通过key.hashCode()计算key对应的hashCode,计算结果为int型,即32位数字,然后将该数字无符号右移16位,即忽略高位的数字取低16位的值,将该值与原值进行异或操作,这样混合后的数字为通过高位和地位的信息混合得来,增大了随机性。
之后需要将混合值映射到数组中的各个位置,我们首先想到的是可以对数组的长度取余,这样根据余数就可以将元素映射到数组中。取余的操作如果除数是2的整数幂则等价于与除数减1的&操作,即忽略最高位,剩下的值即为余数:
hash % length == hash & (length - 1)
同时,通过&操作相比于%会提高运算效率,因此HashMap中数组的长度均为2的整次幂,通过如下函数进行设置:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
整个计算过程如下图所示:
3. 扩容机制
在了解HashMap的扩容机制之前,首先需要对HashMap中的几个字段做下补充:
final float loadFactor;
int threshold;
transient int size;
transient int modCount;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
其中loadFactor为HashMap的负载因子,默认值为0.75,threshold为HashMap所能容纳的Node,即键值对的个数,其中threshold = length(数组的长度) * loadFactor,例如数组长度为16,loadFactor为0.75,则threshold为12,当HashMap存储的Node的个数大于threshold的值时,数组就开始进行扩容,扩容后的数组的容量为之前的2倍。
size为实际存储的Node的数量。
modCount为HashMap内部结构发生变化的次数,当对HashMap进行的操作会更改内部结构的时候,例如添加Node,删除Node,清空等该值均会+1。该值的主要目的为在多线程过程中,当对HashMap通过迭代器进行操作的过程中,会比对迭代之前该值和迭代过程中该值是否有变化,如果有变化,说明HashMap被其他线程进行了修改,则抛出异常,结束迭代的过程,用于迭代的快速结束,提高性能。
如前所述,当HashMap存储的Node的个数大于threshold的值时,数组就开始进行扩容,扩容后的数组的容量为之前的2倍;在1.7中,会重新计算每个元素的hash值,然后重新放到新的数组中,当发生Hash碰撞的时候,新的元素放置到链表的开头,这样的话在重新进行计算的时候,因为需要对链表进行遍历重新放置,那么之前在链表前边的元素经过遍历和重新放置之后,后边的元素会插入到链表的前边,导致链表数据位置反转。在1.8中,采用尾插法,不会有该现象,同时避免了在多线程中可能出现的环形链表。
在JDK1.8中,计算元素在数组中的位置方式有了调整,因为每次扩容都是原来的2倍,在计算hash值的时候相当于高位多了一位,计算的余数最高位为1或者0,即元素要么不动,要么挪动到之前位置+原数组长度的位置,因此只需要根据查看原hash值对应数组长度位置的值为0或者1即可确定新的位置,不需要重新进行计算。
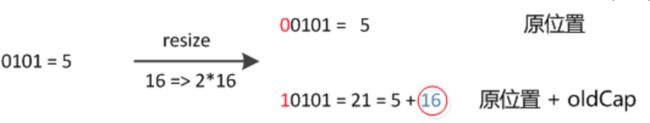
在JDK1.8中,同时引入了红黑树。假定我们插入的key的hashCode值相同,例如重写Key对应的Object的hashCode方法返回同一个值 ,那么插入的所有元素都会在数组相同位置的链表中,这样的话获取元素的时间复杂度就会为O(n),如果采用红黑树的方式,元素被平衡放置在树的两侧,时间复杂度为O(logn),当数据的hashCode值比较差,分布不均匀的时候,可有效提升效率。