HashMap深度分析(基于jdk1.8)
HashMap 的简介
- Hashmap是一个散列桶(bucket ),存储的一对一对的数据,形式是:key---value。
- Hashmap采用的是数组和链表的数据结构,能在查询和修改方便继承了数组的线性查找和链表的寻址修改。
- HashMap 线程不安全,所以 HashMap 很快。
- HashMap 可以接受 null 键和值,而 Hashtable 则不能。
HashMap 的工作原理
在使用put(key,value)方法向map中插入值得时候,会优先调用hash()方法,参数为key,意思就是先获取key得hashcode,计算需要将该key放入的位置。这里关键点在于指出,HashMap 是在 bucket 中储存键对象和值对象,作为Map.Node 。下面可以了解一下Hashmap的实现:
static class Node implements Map.Entry {
final int hash;
final K key;
V value;
Node next;
Node(int hash, K key, V value, Node next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry e = (Map.Entry)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
} 解释:Node是Hashmap类的一个静态内部类,实现了Map.Entry
注意:
● HashMap数组:transient Entry[] table
● 数组默认长度:static final int DEFAULT_INITIAL_CAPACITY = 1 << 4=16
● 数组最大长度:static final int MAXIMUM_CAPACITY = 1 << 30=1073741824
● 默认加载因子:static final float DEFAULT_LOAD_FACTOR = 0.75f
● 扩容临界值:private int threshold;(threshold=capcity*loadFactor)
DEFAULT_INITIAL_CAPACITY 是数组默认的长度即16,MAXIMUM_CAPACITY 是数组最大的长度2的30次方,原因是2的31次方就超过Integer.MAX_VALUE(2147483647)了(也就是2^31-1),而数组的长度都必须是2的次方(原因稍后会解释),所以数组最大长度只能是2的30次方。
数组的长度为2的次方原因:比如我们向HashMap中存入了两个键值对entry1(key1=”abc”,value1=”ABC”)、entry2(key2=”def”,value1=”DEF”),假设key1对应的hash值为18,二进制为10010,假设key2对应的hash值为27,二进制为11011。
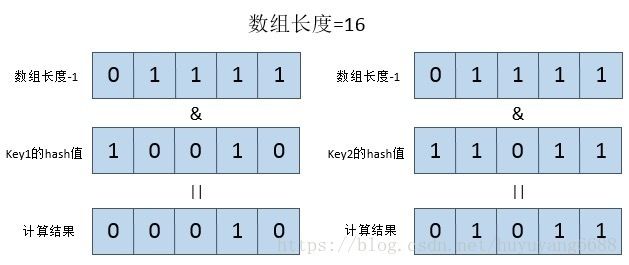
其中会发现一个规律,如果数组长度为2的幂次方,那么数组长度-1的二进制每个位数的值都是1,与key的hash进行&运算之后的结果,除了超过数组长度-1数值的高位部分,低位部分都与key的hash值一致。
如果数组长度不是2的幂次方,比如15,结果会是什么样呢?如下图:
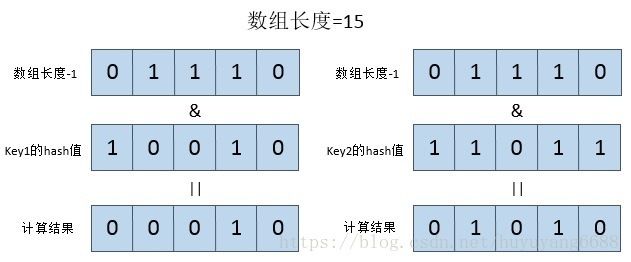
当数组长度是15的时候,其二进制末尾数值为0,计算结果的末尾肯定永远是0,所以永远不会有计算结果为00001、00011、00101、00111、01001、01011、01101、01111这几种末尾是1的情况,也就是数组下标为1、3、5、7、9、11、13、15这几个位置永远都不会存储数据,造成了严重的空间浪费,这就是HashMap中的数组长度必须是2的幂次方的原因。
HashMap 的put方法分析
1、先对key进行hash计算,然后计算存放的位置。如下源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
2、如果位置没有冲突,那么直接放入到bucket之中。
3、如果位置有冲突,那么需要调用equals方法(hashcode一样,key内容不一定相同),如果equals返回的 值为false,那么需要放到这个位置的链表之中。
4、当链表的长度大于8的时候,那么链表会转为红黑树的数据结构。如下源码:
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // TREEIFY_THRESHOLD 默认为8
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;5、当链表的长度小于6的时候,那么红黑树会转为链表的数据结构。如下源码:
if (lc <= UNTREEIFY_THRESHOLD) // UNTREEIFY_THRESHOLD默认为6
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}6、如果hash计算后的值已经存在,那么需要调用equals方法(hashcode一样,key内容不一定相同),如果equals返回的 值为true,那么覆盖原有的value。
7、如果桶满了(容量16*加载因子0.75),就需要 resize(扩容2倍后重排)
注意:在JDK1.8之间,如果是在链表上插入得话,那么是插入到链表得尾部的。这样可以不用移动链表位置(在jdk1.7的时候是插入到链表的头部的,每次都需要去移动链表的位置),还可以防止在jdk1.7中因为扩容出现的循环链表的问题,但是会产生一个新得问题:会存在数据丢失的可能。
HashMap 的get方法分析
1、调用get方法的时候,也会先调用hash()方法,获取bucket 位置。如下源码:
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
} 2、获取bucket位置之后,需要调用equals方法(hashcode一样,key内容不一定相同)去匹配需要查找的key,然后获取对应的value。
HashMap 中 hash 函数分析
前面说过,hashmap 的数据结构是数组和链表的结合,所以我们当然希望这个 hashmap 里面的元素位置尽量的分布均匀些,尽量使得每个位置上的元素数量只有一个。那么当我们用 hash 算法求得这个位置的时候,马上就可以知道对应位置的元素就是我们要的,而不用再去遍历链表。 所以,我们首先想到的就是把 hashcode 对数组长度取模运算。这样一来,元素的分布相对来说是比较均匀的。如下源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}解释:^ :按位异或。>>>:无符号右移,忽略符号位,空位都以0补齐
为什么使用红黑树
之所以选择红黑树,是为了解决二叉树在某一些特殊情况下会变成线性二叉树的时候,那样反而导致查询的层次很深,这样的查询会和直接的链表查询没有区别。而红黑树可以通过左旋、右旋、变色这些操作来保持平衡。引入红黑树就是为了查询数据快,解决链表查询深度的问题。我们知道红黑树属于平衡二叉树,为了保持“平衡”是需要付出代价的,但是该代价所损耗的资源要比遍历线性链表要少。所以当长度大于8的时候,会使用红黑树;如果链表长度很短的话,根本不需要引入红黑树,引入反而会慢。
红黑树的特征
- 节点是红色或者黑色。
- 根节点是黑色。
- 红色节点的子节点是黑色。
- 每个子节点是黑色。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
HashMap的resize分析
HashMap 默认的负载因子大小为0.75。也就是说,当一个 Map 填满了75%的 bucket 时候,和其它集合类一样(如 ArrayList 等),将会创建原来 HashMap 大小的两倍的 bucket 数组来重新调整 Map 大小,并将原来的对象放入新的 bucket 数组中。
重新调整 HashMap 大小存在的问题
在重新调整hashmap的时候,会存在一定的问题
在多个线程都检测到hashmap需要扩容的时候,那么这些线程就会去试着扩容。在扩容的过程中,存储在链表中的元素次序会反过来。因为移动到新的bucket的时候,hashmap并不会将元素放在尾部,而是放在头部。如果竞争发生了,那么就会出现死循环。
CocurrentHashMap浅析
在concurrenhashmap抛弃了原有的segment分段锁,采用了cas+synchronized保证并发安全。最大特点是引入了 CAS.借助 Unsafe 来实现 native code。CAS有3个操作数,内存值 V、旧的预期值 A、要修改的新值 B。当且仅当预期值 A 和内存值 V 相同时,将内存值V修改为 B,否则什么都不做。Unsafe 借助 CPU 指令 cmpxchg 来实现。如下源码:
static class Node implements Map.Entry {
final int hash;
final K key;
volatile V val;
volatile Node next;
Node(int hash, K key, V val, Node next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return val; }
public final int hashCode() { return key.hashCode() ^ val.hashCode(); }
public final String toString(){ return key + "=" + val; }
public final V setValue(V value) {
throw new UnsupportedOperationException();
}
public final boolean equals(Object o) {
Object k, v, u; Map.Entry e;
return ((o instanceof Map.Entry) &&
(k = (e = (Map.Entry)o).getKey()) != null &&
(v = e.getValue()) != null &&
(k == key || k.equals(key)) &&
(v == (u = val) || v.equals(u)));
}
/**
* Virtualized support for map.get(); overridden in subclasses.
*/
Node find(int h, Object k) {
Node e = this;
if (k != null) {
do {
K ek;
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
} while ((e = e.next) != null);
}
return null;
}
} put 过程
- 取出key的hashcode。
- 判断是否需要进行初始化。
- 通过key定位出node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
源码如下:
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node[] tab = table;;) {
Node f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
if ((e = e.next) == null) {
pred.next = new Node(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
} get 过程
- 获取key的hashcode来寻址,如果就在桶上,就直接返回。
- 如果是红黑树,就按照树的方式获取值。
- 不满足就按照链表的方式获取值。
源码如下:
public V get(Object key) {
Node[] tab; Node e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}