《持续交付》(五)数据管理与版本控制实践
引言
本文是《持续交付》一书学习总结的第五篇。主要内容涉及数据管理以及Git分支管理的实践。

数据管理
软件代码的部署可以简单地用新的版本替换旧的版本,但是数据可不是如此。自从产品上线后,数据就一直在增长,每个版本发布时,数据可能都是全新的。然而,有时我们的确有这样的需求,去改数据的结构或者内容。这就要求我们在做出修改的同时,保证产品运行和部署的可靠性。
首先,数据库的部署也需要脚本化。与代码部署一样,脚本有助于实现自动化,并容易使用版本控制工具来管理。需要注意的是,数据库的部署脚本(建库、建表、插入数据等)需要与最新的代码保持一致。因为只有新的代码可能用到了最新的数据库设计和数据,如果代码版本有误,很可能数据库部署会失败。
版本化你的数据库。我们可以用版本号来标记数据库的状态。这个版本号可以存储在一个独立的表中,每当数据库的设计和内容(元数据)发生变化时,就要更新这个版本号字段。另外,在应用程序的配置中,也要维护一个数据库的版本号,以便于在部署时对应到正确的数据。
除了版本号,每当我们更改数据库时,同时需要编写配套的发布(roll-forward)脚本和回滚(roll-back)脚本。前者用于将此次改动脚本化,让数据库进入新的版本;后者用于回滚这次操作,让数据库回到当前版本。当应用程序中配置的数据库版本号领先于数据库最新的版本时,说明数据库需要更新,这时就可以利用每一次改动对应的发布脚本,依次运行来更新数据库到最新状态。当某一次数据库改动出现问题时,可以利用回滚脚本快速恢复到正确状态。
数据库的脚本和版本可以让数据库的管理与应用程序的管理解耦。数据库管理员可以独立完成更改,只要更新版本号即可。应用程序开发者可以配置自己需要数据库版本号,就可以拿到最新的改动。
生产环境对数据库的回滚操作提出了挑战:
- 回滚操作不能破坏已有的事务操作和丢失数据。
- 回滚不能中断生产环境(热回滚,零宕机发布)。
对于第一点,可以在更新数据库前对事务数据进行缓存,这样在回滚之后,可以恢复丢失的数据。对于第二点,可以利用蓝绿发布中的回滚机制。比如蓝色数据库是生产环境,那么绿色数据库就作为它的备份,并在一定时间内更新到最新。如果蓝色数据库出问题,那么可以立即切换到绿色数据库,并尽快恢复蓝色数据库。修复后,再将这段时间内绿色数据库上的事务数据应用到蓝色环境中。
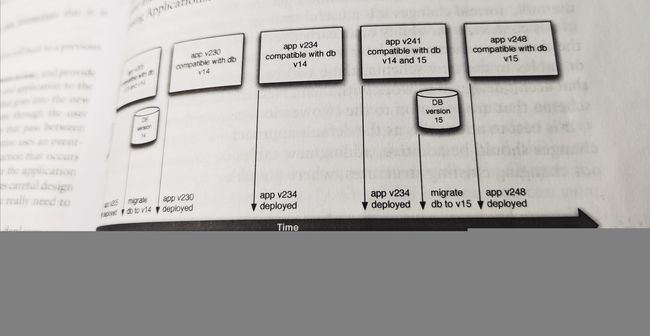
还有一种数据库回滚的方式如下图。数据库的改动不一定要跟随应用程序的发布频率。当数据库有新的改动(v15)时,可以先开发应用程序的特性,以适应这种改动。此时,应用程序的数据库功能是可以兼容新旧(v15和v14)两个版本的。当这个版本的应用程序(v241)发布时,我们可以将数据库迁移到新版本(v15),并观察和测试。如果有问题,则回滚到老版本(v14),也可以无缝衔接。
测试中的数据管理要考虑两个方面:一是性能,二是隔离性。对于第一点,为了提高效率,很多测试case通常是并发执行的,但这就会带来数据同步的问题:很多case可能操作同一套数据。解决这个问题的方法就是让每个case有自己的数据,减少访问的冲突。第二点说的就是case的结果不能互相影响,一个case跑过之后,结果可能被持久化,但它不能对另一个case的结果有影响。
另外要注意的是,测试的设计不能太过依赖实现,否则一个小的改动,就会导致测试代码较大的改动,甚至重构。另外,每个测试case使用的数据量要尽量小,只要满足测试需求就好。
接下来我们看看版本控制的一些话题。
版本控制流程:Git Workflow
下面我打算以Git Workflow为例,介绍Git在软件开发和发布流程中的应用,并简单提及另一种常见流程:Github Flow。这些内容并不来自《持续交付》一书,而是平时的学习实践。
Git WorkFlow是针对传统软件发布的一种常见的Git分支管理流程。在这个流程中要创建一系列的不同用途的分支,经过分支的合并和标签等操作,最终让改动到达可发布的分支上,并开始部署。
值得一提的是,这个流程相对来说比较复杂,因而不适用于目前主流的持续集成/交付(CI/CD)的流程。不过对于传统的软件发布场景,它依然有用武之地,并且可以帮助我们理解Git分支管理的强大之处。GitHub Flow就是针对持续集成和交付的场景设计的,不仅被GitHub官方作为分支管理的流程,也被很多企业级项目广泛采用,我后面会简单介绍。
下图给出了一个典型的Git Workflow的应用。其中,master分支是最终用于部署的分支,所有的需要发布的改动最终都要进到master分支。
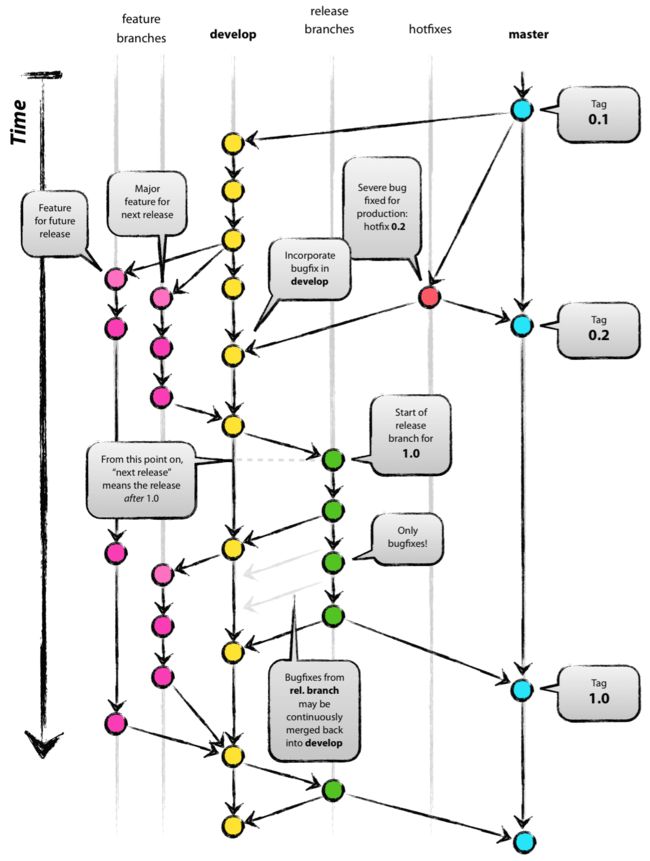
develop分支是稳定的开发分支。开发者合作开发一个项目,会创建自己feature分支,feature分支都是基于develop分支创建。开发结束后,feature分支会在通过代码审核之后合并到develop分支上。develop分支的稳定体现在,合并feature之前,需要通过各种自动化的、人工的测试,保证所有的改动没有错误,并且不破坏已有功能。
当develop分支积累了足够多的feature后,就会准备一个新的发布。首先,从develop分支拉出一个release分支。release分支需要通过各种测试,为发布做准备。如果在这期间发现了比较紧急的问题,可以通过bug-fix分支进行修正。而其他任何改动都不能进入release分支。当然,bug-fix分支需要基于release分支创建。
当release分支稳定后,就可以将其合并入master分支,作为可部署的新版本。在合并的commit上,还需要生成新的tag,代表新的版本。此时,持续部署的流水线就可以基于新版本的master分支,部署生产环境了。发布结束后,最终master分支需要合并回develop分支。
如果在master分支上发现了比较严重的问题,可以基于master分支创建hot-fix分支来修正。这些hot-fix分支最后合并入master分支,也要更新tag,代表一个新的补丁版本。最后,hot-fix分支要合并回develop分支,以保证开发者随时有最新的改动。
以上就是Git Workflow定义的分支管理流程。在实际应用中,依据项目需要,可以进行灵活调整。不过采用这种方式的一个缺点是,不利于持续继承和部署,分支较多不易管理,且很多改动很难及时上线。Github Flow可以解决这个问题。
在Github Flow中,只需要存在master一个稳定分支,该分支必须处于时刻可以部署的状态。开发者直接从master分支上创建feature分支,开发完成后提出Pull Request开启代码审核,并触发CI的流程。如果通过CI的构建和测试,并且通过代码审核,代码就可以进入master分支,用于后续的部署。
从中我们可以看出,Github Flow弱化了“release”的概念,生产环境一天甚至可以部署数次。即使存在严重问题,也是通过小feature的方式修正,然后合并入master。由于整个流程很迅速,改动可以立即上线修正问题。
另外,Github Flow通常依据标签(tag)来部署,每当有新的版本时,只需要标记新的tag,就能触发新的部署。更详细的介绍可以参看官网文档。