MVCC原理探究及MySQL源码实现分析
文章目录
- 数据库多版本读场景
- MVCC实现原理
- MVCC解决了什么问题
- MySQL代码分析
数据库多版本读场景
| session 1 | session 2 |
|---|---|
| select a from test; return a = 10 | |
| start transaction; | |
| update test set a = 20; | |
| start transaction; | |
| select a from test; return ? | |
| commit; | |
| select a from test; return ? |
我们看下上面这个数据库日常操作的例子。
- session 1修改了一条记录,没有提交;与此同时,session 2 来查询这条记录,这时候返回记录应该是多少呢?
- session 1 提交之后 session 2 查询出来的又应该是多少呢?
由于MySQL支持多种隔离级别,这个问题是需要看session2的事务隔离级别的,情况如下
- 隔离级别为 READ-UNCOMMITTED 情况下:
无论session 1 是否commit,session 2 去查看都会看到的是修改后的结果,即 a = 20 - 隔离级别为 READ-COMMITTED 情况下:
session 1 在 commit 前,session 2查看到的还是 a =10 , commit之后看到的则是 a = 20 - 隔离级别为 REPEATABLE-READ 及 SERIALIZABLE 情况下:
无论 session 1 是否commit,session 2 去查看都会看到的是修改前的结果,即 a = 10
其实不管隔离级别,我们也抛开数据库中的ACID,我们思考一个问题:众所周知,InnoDB的数据都是存储在B-tree里面的,修改后的数据到底要不要存储在实际的B-tree叶子节点,session2是怎么做到查询出来的结果还是10,而不是20呢?
MVCC实现原理
上述现象在数据库中大家经常看到,但是数据库到底是怎么实现的,深究的人就不多了。
其实原理很简单,InnoDB数据库就是通过UNDO和MVCC来实现的。
1.旧数据存储在UNDO中,再通过DB_ROLL_PTR 回溯查找历史版本
- 首先InnoDB每一行数据还有一个DB_ROLL_PTR(回滚指针),用于指向该行修改前的上一个历史版本(InnoDB里,会将 row data修改前的旧数据存储在UNDO中)


更新记录时,原记录将被放入到undo表空间中,并通过DB_ROLL_PTR指向该记录。session2查询返回的未修改数据就是从这个UNDO中返回的。MySQL就是根据记录上的回滚段指针及事务ID判断记录是否可见,如果不可见继续按照DB_ROLL_PTR继续回溯查找。
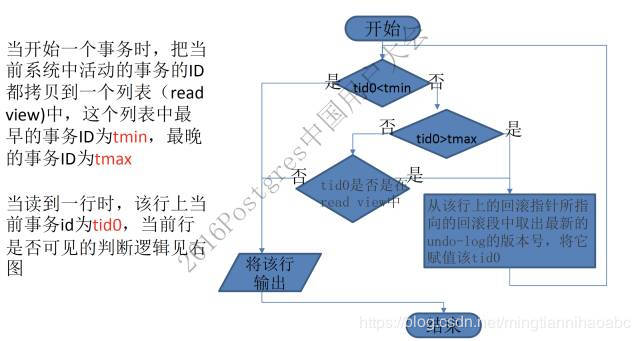
2.通过read view判断行记录是否可见
具体的判断流程如下: - RR隔离级别下,在每个事务开始的时候,会将当前系统中的所有的活跃事务拷贝到一个列表中(read view)。
- RC隔离级别下,在事务中的每个语句开始时,会将当前系统中的所有的活跃事务拷贝到一个列表中(read view) 。
- 然后按照以下逻辑判断事务的可见性
MVCC解决了什么问题
-
MVCC使得数据库读不会对数据加锁,普通的SELECT请求不会加锁,提高了数据库的并发处理能力;
-
借助MVCC,数据库可以实现RC,RR等隔离级别,用户可以查看当前数据的前一个或者前几个历史版本。保证了ACID中的I特性(隔离性)。
MySQL代码分析
前面我们介绍了什么是MVCC,以及它解决了什么问题。
下面我们来看一下在MySQL源码中,到底是怎么实现这个逻辑的。
1、InnoDB隐藏字段源码分析
InnoDB表中会存有三个隐藏字段,这三个字段是mysql默认添加的。可以通过代码中查看到:
dict_table_add_system_columns(
/*==========================*/
dict_table_t* table, /*!< in/out: table */
mem_heap_t* heap) /*!< in: temporary heap */
{
ut_ad(table);
ut_ad(table->n_def == (table->n_cols - table->get_n_sys_cols()));
ut_ad(table->magic_n == DICT_TABLE_MAGIC_N);
ut_ad(!table->cached);
/* NOTE: the system columns MUST be added in the following order
(so that they can be indexed by the numerical value of DATA_ROW_ID,
etc.) and as the last columns of the table memory object.
The clustered index will not always physically contain all system
columns.
Intrinsic table don't need DB_ROLL_PTR as UNDO logging is turned off
for these tables. */
dict_mem_table_add_col(table, heap, "DB_ROW_ID", DATA_SYS,
DATA_ROW_ID | DATA_NOT_NULL,
DATA_ROW_ID_LEN);
#if (DATA_ITT_N_SYS_COLS != 2)
#error "DATA_ITT_N_SYS_COLS != 2"
#endif
#if DATA_ROW_ID != 0
#error "DATA_ROW_ID != 0"
#endif
dict_mem_table_add_col(table, heap, "DB_TRX_ID", DATA_SYS,
DATA_TRX_ID | DATA_NOT_NULL,
DATA_TRX_ID_LEN);
#if DATA_TRX_ID != 1
#error "DATA_TRX_ID != 1"
#endif
if (!table->is_intrinsic()) {
dict_mem_table_add_col(table, heap, "DB_ROLL_PTR", DATA_SYS,
DATA_ROLL_PTR | DATA_NOT_NULL,
DATA_ROLL_PTR_LEN);
#if DATA_ROLL_PTR != 2
#error "DATA_ROLL_PTR != 2"
#endif
/* This check reminds that if a new system column is added to
the program, it should be dealt with here */
#if DATA_N_SYS_COLS != 3
#error "DATA_N_SYS_COLS != 3"
#endif
}
}
- DB_ROW_ID,如果表中没有显示定义主键或者没有唯一索引则MySQL会自动创建一个6字节的row id存在记录中
- DB_TRX_ID,事务ID
- DB_ROLL_PTR,回滚段指针
2、InnoDB判断事务可见性源码分析
mysql中并不是根据事务的事务ID进行比较判断记录是否可见,而是根据每一行记录上的事务ID进行比较来判断记录是否可见。
我们可以通过实验验证 , 创建一张表里面插入一条记录
dhy@10.16.70.190:3306 12:25:47 [dhy]>select * from dhytest;
+------+
| id |
+------+
| 10 |
+------+
1 row in set (7.99 sec)
手工开启一个事务 更新一条记录 但是并不提交:
dhy@10.10.80.199:3306 15:28:24 [dhy]>update dhytest set id = 20;
Query OK, 3 rows affected (40.71 sec)
Rows matched: 3 Changed: 3 Warnings: 0
在另外一个会话执行查询
dhy@10.16.70.190:3306 12:38:33 [dhy]>select * from dhytest;
这时我们可以跟踪调试mysql 查看他是怎么判断记录的看见性,中间函数调用太多列举最重要部分
这里需要介绍一个重要的类 ReadView,Read View是事务开启时当前所有事务的一个集合,这个类中存储了当前Read View中最大事务ID及最小事务ID
/** The read should not see any transaction with trx id >= this
value. In other words, this is the "high water mark". */
trx_id_t m_low_limit_id;
/** The read should see all trx ids which are strictly
smaller (<) than this value. In other words, this is the
low water mark". */
trx_id_t m_up_limit_id;
/** trx id of creating transaction, set to TRX_ID_MAX for free
views. */
trx_id_t m_creator_trx_id;
当我们执行上面的查询语句时,跟踪到主要函数如下:
函数row_search_mvcc->lock_clust_rec_cons_read_sees
bool
lock_clust_rec_cons_read_sees(
/*==========================*/
const rec_t* rec, /*!< in: user record which should be read or
passed over by a read cursor */
dict_index_t* index, /*!< in: clustered index */
const ulint* offsets,/*!< in: rec_get_offsets(rec, index) */
ReadView* view) /*!< in: consistent read view */
{
ut_ad(index->is_clustered());
ut_ad(page_rec_is_user_rec(rec));
ut_ad(rec_offs_validate(rec, index, offsets));
/* Temp-tables are not shared across connections and multiple
transactions from different connections cannot simultaneously
operate on same temp-table and so read of temp-table is
always consistent read. */
//只读事务或者临时表是不需要一致性读的判断
if (srv_read_only_mode || index->table->is_temporary()) {
ut_ad(view == 0 || index->table->is_temporary());
return(true);
}
/* NOTE that we call this function while holding the search
system latch. */
trx_id_t trx_id = row_get_rec_trx_id(rec, index, offsets); //获取记录上的TRX_ID这里需要解释下,我们一个查询可能满足的记录数有多个。那我们每读取一条记录的时候就要根据这条记录上的TRX_ID判断这条记录是否可见
return(view->changes_visible(trx_id, index->table->name)); //判断记录可见性
}
下面是真正判断记录的看见性代码逻辑:
bool changes_visible(
trx_id_t id,
const table_name_t& name) const
MY_ATTRIBUTE((warn_unused_result))
{
ut_ad(id > 0);
//如果TRX_ID小于Read View中最小的, 则这条记录是可以看到。说明这条记录是在select这个事务开始之前就结束的
if (id < m_up_limit_id || id == m_creator_trx_id) {
return(true);
}
check_trx_id_sanity(id, name);
//如果比Read View中最大的还要大,则说明这条记录是在事务开始之后进行修改的,所以此条记录不应查看到
if (id >= m_low_limit_id) {
return(false);
} else if (m_ids.empty()) {
return(true);
}
const ids_t::value_type* p = m_ids.data();
return(!std::binary_search(p, p + m_ids.size(), id)); //判断是否在Read View中, 如果在说明在创建Read View时,此条记录还处于活跃状态则不应该查询到,否则说明创建Read View是此条记录已经是不活跃状态则可以查询到
}
对于不可见的记录都是通过row_vers_build_for_consistent_read函数查询UNDO构建老版本记录,直到记录可见。
这里需要说明一点 不同的事务隔离级别,可见性的实现也不一样:
-
READ-COMMITTED
事务内的每个查询语句都会重新创建Read View,这样就会产生不可重复读现象发生 -
REPEATABLE-READ
事务内开始时创建Read View , 在事务结束这段时间内 每一次查询都不会重新重建Read View , 从而实现了可重复读。
唐成-2016PG大会-数据库多版本实现内幕.pdf,提取码: 5ap5