(实战总结)我用EggJS开发了一个日增量过亿的数据可视化平台
编者荐语:
这篇文章中的干货蛮多的,用 node 写 BFF 或者后端的小伙伴可以对比一下自己项目,学习下。
以下文章来源于较真的前端 ,作者英俊潇洒你冲哥

较真的前端
前端开发者交流与呵护平台

本文首发于知乎,大家可以通过文章底部的阅读原文来访问原文地址。文末有视频。
项目背景
小编我在国内某知名互联网(非一线)做前端开发,平时做NodeJS比较多,所以负责BFF和服务端的事情也不较多。
前些日子,我所在的Team接到了一个“大活儿”,为我们公司某个服务(出于保密的原因,这里不能直说)做数据可视化及数据分析平台。
与数据生产方(服务维护方)沟通几轮后,我了解到了本次的后端服务有几大挑战:
-
全栈开发:本项目在数据生产完成之后,所有工作都要由我们前端组独立完成,包括前端页面、后端服务、数据加工等等
-
数据量庞大:原始数据的日增量过亿,如果赶上运营活动数据量可能还会翻倍
-
实时展示:我们希望为用户提供实时的数据展示,如此大的数据量要做到实时绝非易事
-
权限认证:该服务的所有数据都是有安全性要求,除了最基础的登录校验,不同业务线也只能查看自身业务线的数据
项目准备
我们对接的服务维护方可以为我们提供的是 将所有实时数据落到clickhouse(一种适合大数据存储分析的数据库)中,除实时数据外,还有小时级别的聚合数据(维度是各业务单元)。
也就是说,每个业务线在该服务上产生的数据会每小时做一个聚合并落到另一张表(包括:小时内的总计、平均值、uv均值、pv总值等等)。
剩下的事情就要靠我们几位前端同学搞定了。
技术选型
后端当然是用NodeJS写,毕竟我们是前端开发,选择NodeJS是理所当然的。
但是基于NodeJS的http server框架该选什么?目前市面上三个比较被大家熟知的有3个。
Express和Koa、EggJS

-
Express本人用了多年,做过两个运行多年的大型项目,但事实上用的很痛苦。每次的请求实例都是通过参数一层层传递的,所有错误也要一层层传递出来。用起来很不爽,急需寻找改变。 -
Koa是Express原班人马打造的, 从根源上做解决了Express的很多痛点,但是我需要一个更适合企业级应用的框架
EggJS——最终选择
EggJS成为了最终的选择,我觉得Egg有如下的优势:
-
多环境配置,作为企业应用,我们会有多个环境——测试环境、stage环境、生产环境,每个环境下的应用所连接底层服务的参数、配置信息都是不一样的。EggJS可以通过启动时注入环境变量来加载不同的配置文件,并且挂在到context上,应用代码根本不用关心环境的差异,多环境问题轻松解决。
-
系统稳定性,使用Express和Koa的话,为了系统稳定性,必须用PM2来做进程管理和监控,而这又加大了运维和部署的复杂度,但是EggJS天然具备进程管理和监控功能
-
定时任务,Egg自身带有schedule模块的,你不需要再引入第三方插件。
-
丰富的生态,由于本次项目使用了很多后端常见,但是前端为所未闻的技术,如状态监控Prometheus、消息队列Kafka等等,但是这些已经在egg生态已经存在插件了,直接使用即可。
-
插件开发简单,如果生态中还没有你想要的Egg插件,自行开发一个也不是难事,我自己在这个项目开发过程中做了4个插件,还有一个已经开源——egg-etcd。
系统设计
本次开发的系统结构图大致如下:
系统中关键的几点:
-
通过中间件来解决对于每个请求进行登录+权限的校验
-
通过Etcd来实现配置信息实时同步
-
“热数据”缓存到Redis中,其他数据实时去Clickhouse和后端接口中取
中间件
介于数据的安全性,对于每个请求都会做登录状态(sso)和资源权限的校验,所以使用中间件是非常合适的。
因为Egg中间件机制是遵循”洋葱圈”模式,每个请求都会经过各个中间件的一层层处理。
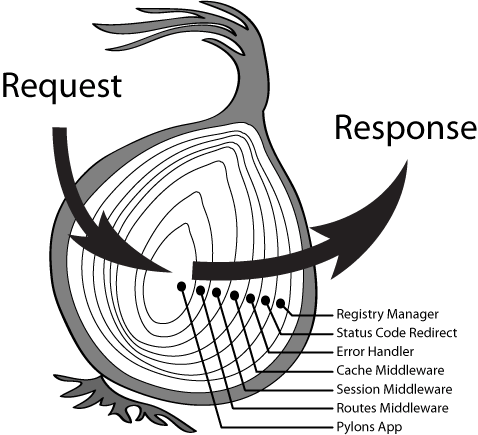
我们公司基建中是有登录校验和资源权限校验的http API,可是在我们着手开发此项目时,并没有针对NodeJS的sdk封装,于是我将这两个校验过程封装成了两个Plugin。
有了这两个Plugin后,今后只需要在不同环境的config文件中配置好appKey、appSecret和其他相关信息就好。(这些是我司对于http API请求的安全校验机制,类似于微信公众平台)。
事实证明,有了这两个
Plugin后,今后Egg项目的开发效率得到了大幅度地提升。
使用Etcd做配置管理

项目中的所有配置都写在了配置中心(本次项目选择用etcd),这样做有几个好处:
-
安全性:把所有机密信息(如数据连接用户名和密码等)通过环境变量来注入到镜像中,而环境变量值写在etcd中,这样这些信息都不会明文暴露在代码中。并且
etcd自带权限管理,所以只有当前项目权限的开发者才会看到关键信息 -
实时性:部分配置信息是可能随时发生变化的,项目需要与最新的配置保持同步,etcd提供事件监听,可以做到配置的“响应式”
-
共享配置:部分配置是多个应用共享的,通过引入etcd上相同的path来省去了维护多份数据的成本
介于Egg生态中并没有Etcd的插件,我自行开发了一个并且开源Egg-Etcd
数据缓存
每次接口请求的数据都会缓存到Redis中,下次请求如果发现Redis中已经存在,则从Redis中取。
为了保证数据的实时性,Redis缓存时间可以设置的短一些
系统稳定性
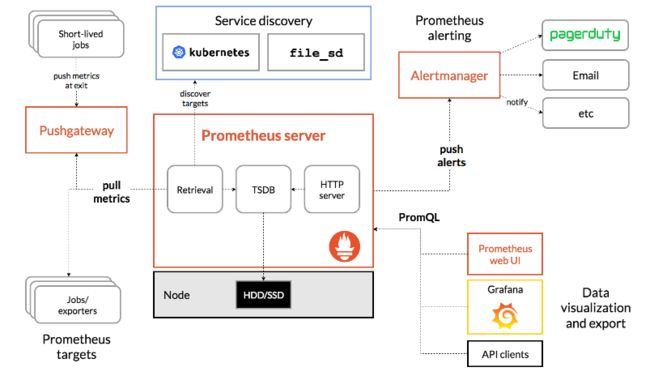
上图和我监控架构很相似,不过有一些不同点:
-
我们的
AlertManager通知的手段会更多。 -
多了异常监控
sentry
系统稳定性需要关注的几点:
-
多实例+多进程:一个进程”倒下”了,立即拉起一个新的进程并关闭异常进程,保证一直有健康正常的进程来响应前端请求。
本次项目是2个实例,每个实例16个进程。
-
平滑重启+自动扩容:应用部署新版本时不应该是让服务变得不可用,哪怕是一秒钟,所以需要通过多实例交替重启来实现”平滑重启”
我们公司云平台的做法是 :先删除一个实例pod,再拉起一个新的pod,等新pod的
存活检查和就绪检查都通过后,再删除一个……这样循环,从而实现平滑重启自动扩容是当你的应用突然迎来一波流量高峰,云平台可以自动为你复制出多个pod,你只需要设置满足扩容的条件即可(如CPU使用率超过85%并持续1分钟)
-
异常监控:代码如果出现
抛出异常,应该第一时间得知,化被动为主动。(代码抛异常,有时并不会让系统崩溃,所以很容易被人忽视)。本次项目使用了
Sentry,如果发生错误,开发者会第一时间收到邮件通知,并且可以在平台中看到各个异常相关的数据和统计。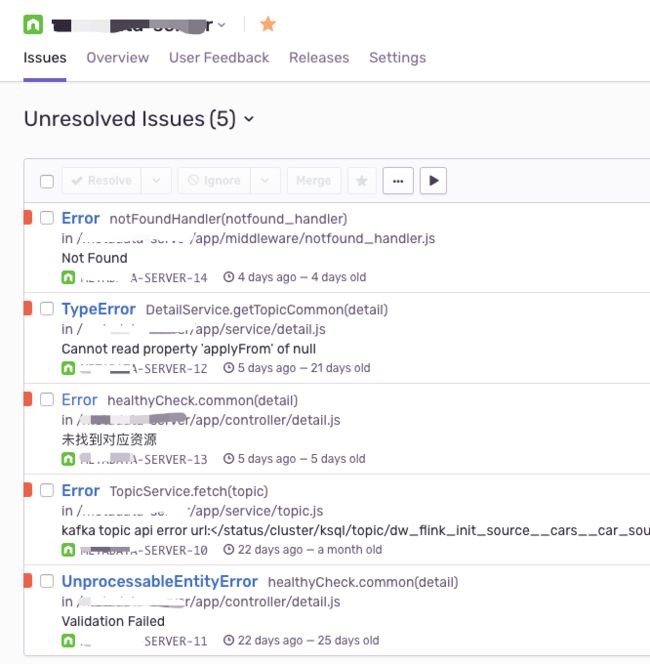
-
指标监控:对于应用运行状态和指标的监控也是十分重要,如CPU使用率、内存使用率、流量等等,可以自定义指标,如QPS、错误累计数、文件句柄数等等。
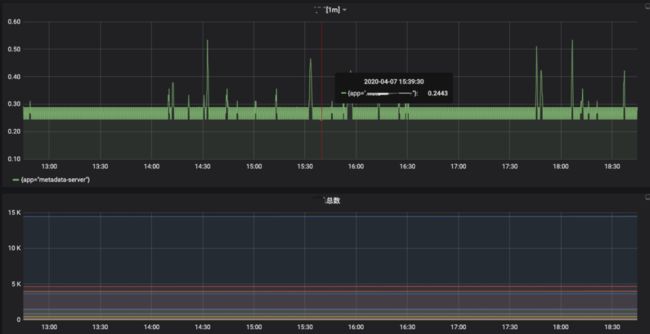
本次项目使用了Prometheus来监控。
在Prometheus的下游,我们公司还提供了Grafana——进行指标可视化,和报警平台——通过PromQL来对关注指标进行报警,报警方式还很多,包括:邮件 => 社交软件 => 发送短信 => 拨打电话(一旦出了异常,报警是躲不掉的)
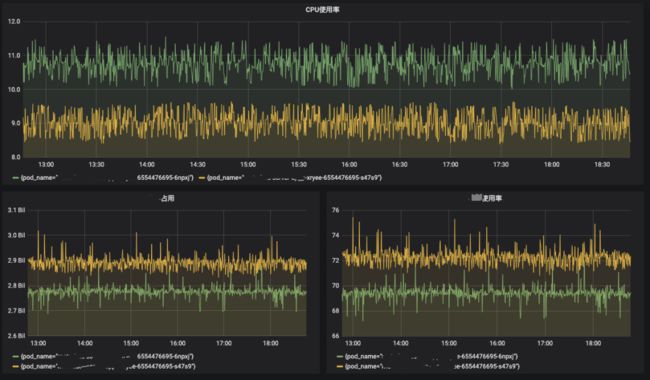
-
日志收集:一旦出了错误,就需要分析日志,我们公司提供了云端日志收集,所以不管你有多少个实例,你的实例是否已经被销毁了,日志文件都是可以保留且可合并分析。
公司云平台为我们提供了Kibana,通过ES语法来检索日志、输出报表、图形化分析,只要确保日志格式是符合规范的,无论你使用哪种语言创建日志,都是可以以相同的方式进行检索查询及分析。
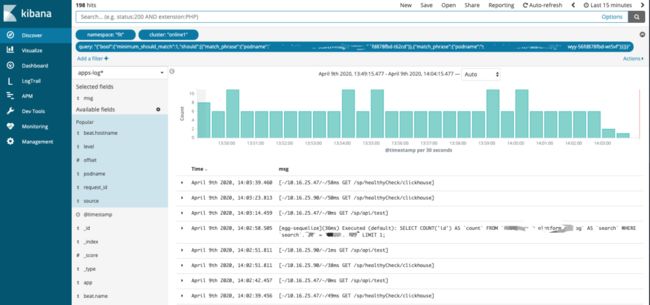
小结
通过上面的总结,我们的系统已经可以稳定运行了,并且形成了像下面一样的完整闭环。下一节的”性能优化”就是基于这个闭环来进行优化的。
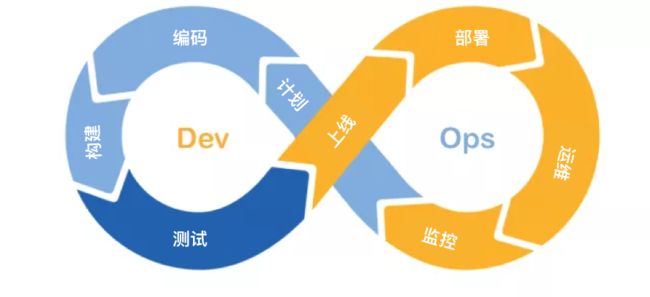
性能优化
在上面的指标监控的加持下,在运行了一段时间后,通过Grafana的指标监控显示,发现了我们的数据可视化系统中,某个业务线的接口返回时间很长,大约要22s以上,这个时长是无法容忍的。
根据日志排查发现,原因是某个业务线的数据量很大,针对于该业务线的所有数据都很慢。
22s到0.1s的优化
通过日志排查,日常消耗在egg-sequelize进行数据查询上,通过其他SQL平台进行查询依然很慢,说明这个查询本身就是慢查询。
如果是MySQL的话,如果出现慢查询,我这里会收到报警,但是clickhouse目前没有这种处理。
首页 - 实时数据优化
首页展示内容是当前业务线的实时内容,包括:
-
各指标今日到当前的实时趋势(粒度:小时)
-
今日关键信息排行榜
-
今日各步骤的转换率
上面三个接口返回时长都在22s以上。
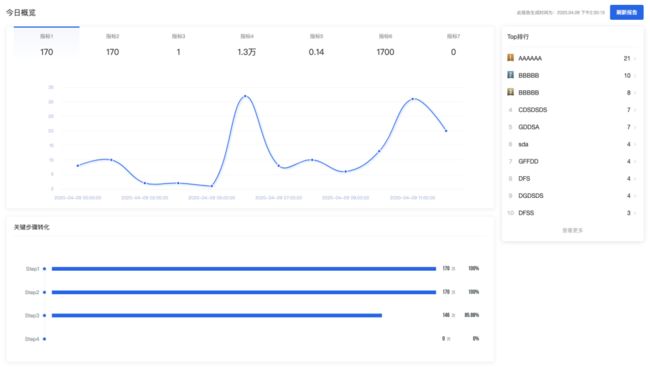
数据均已做过处理
解决方案:
介于用户对于这些数据的实时性要求不是那么那么高,偏差几分钟是在接受范围内的,所以我利用定时任务每5分钟计算一次首页数据,并将这些计算结果缓存到redis中,所以这些接口实际是从Redis读数据,速度大幅提升,最多5分钟的延迟也是用户可以接受的。
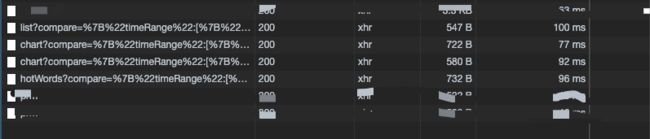
接口返回时长均在100ms之下
用户行为分析页 - 时间范围内聚合
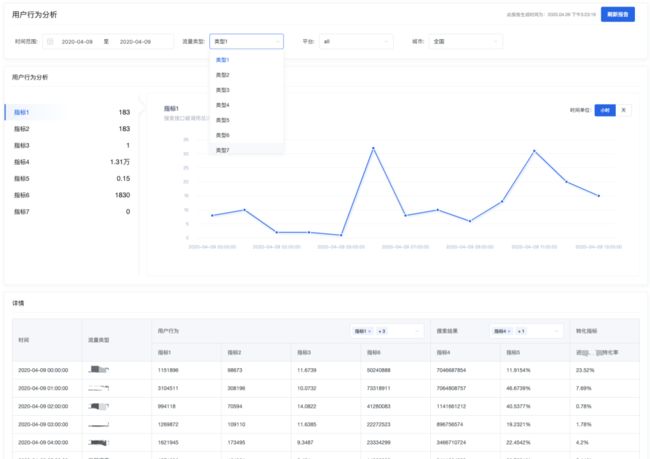
数据均已做处理
用户行为分析页面的特点是用户可能会对长时间范围内的数据进行聚合和分析,所以用户选择的时间跨度越大返回时长越长,clickhouse的查询就越慢(单个业务线的每日数据量在千万以上)。
这个页面查询数据的特点:
-
聚合是按照时间维度(小时、天)
-
查询有多个指标
所以最后的解决方案是,对各个业务线在小时和天两个级别将上面的所有指标数据提前计算出来,并落到clickhouse上,所以此页面的计算会是在中间表上进行查询,效率非常高。定时任务中没有计算到的时间点(如当前小时和上个小时还没有计算和落库),可以再单独去clickhouse中查询,最终将两份数据合并。

接口返回时长也在100ms左右
还能做些什么 What’s the Next?
该项目已经在线上正常运转3个月以上了,在性能上还没有收到用户的负面反馈,总体来说还是符合预期的。
但是我系统中还很多不完美的地方:
-
虽然通过追加中间表来提高了查询速度,但是精细筛选条件下的数据查询依然很慢,原因是中间表是在没有筛选条件下进行聚合在落库的。
-
较大的时间跨度范围内的UV查询依然很慢,原因是在大量数据内做
distinct处理是十分耗时的。
接下来要做的努力:
-
增加埋点收集,分析我们平台的用户行为,发现用户常用的搜索条件是什么,然后提前进行
数据切片并落库。 -
实时性要求变高后,需要引入
Flink+Kafka,进行实时运算再塞到消息队列Kafka中,最后再数据落地,这样数据量会减少很多。
总结
经过这次项目过后,我们在Node应用开发上积累了很多经验,并且沉淀出了多个egg插件,为今后的开发打下了良好基础、效率大大的提升。事实上,在此之后的多个Node项目的开发周期可以控制在一周内,开发人员可以将精力集中在业务逻辑上。
转自https://mp.weixin.qq.com/s/KEwCmlqFzT0XKOUw-ZUT0w