使用libtorch读取预训练权重,完成语义分割
首先说一下我的电脑配置,ubuntu16.04;opencv3.4.3;在anaconda里面安装了torch1.3.1(不同版本的torch使用的c++的代码也是不同的,如果超过v1.0.1,那么需要使用新的API,否则需要使用旧的);cuda10.0;cudnn7.6.5;
这里使用的语义分割的网络是:dspnet V2;基于pytorch开发,支持PyTorch 1.0,我的1.3也可以。可以实现实时的语义分割(这个网络同样可以实现目标检测和目标分类),在我电脑上将图片resize成384*384大小,处理一帧只需要15ms,可以说非常快了,我的电脑运行segnet都需要60ms/帧,而且两者的精度类似。我的电脑显卡为GTX1650。
接下来讲一下如何在c++的环境下如何使用预训练的模型实现语义分割的。
1.将.pth文件转化为.pt文件
在github上将代码下载之后,里面自带一个segmentation_demo.py,这个demo可以将 sample_images目录下的图片完成语义分割,保存到segmentation_results目录下,看源代码里面,生成model的时候需要原始的网络定义,并且还需要传入一个参数args,有的网络是不需要传入参数的,具体需要看实现的源码。
首先吧代码贴上来(只贴了一部分,完整的可以在这里下载):
model = ESPNetv2Segmentation(args).to(device='cuda')#将模型加载到相应的设备中。有的可能不需要传递参数
#model = espnetv2_seg(args)
model.load_state_dict(torch.load('./model/segmentation/model_zoo/espnetv2/espnetv2_s_2.0_pascal_384x384.pth', map_location='cuda'))
model.eval()
example = torch.Tensor(1, 3, 384, 384).cuda()
out = model(example)
print_info_message(out.size())
traced_script_module = torch.jit.trace(model, example)#这句话执行时会有warning,没有事
traced_script_module.save("espnetv2_s_2.0_pascal_384x384.pt")
print_info_message('Done')上面的args的具体含义在完整的代码里面,太长了就不贴上来了,运行上面的程序时可能出现下面的warning:
这个warning我google了半天也不知道怎么解决,但是他不影响生成的.pt文件的效果。因为这个模型是在GPU上训练的,所以传入的tensor要放到GPU上,也就是.cuda(),另外,生成的model也要放到GPU上。其他的网络的做法应该也大同小异,无非就是找到原本的网络的实现代码,看看需不需要传入参数,然后将预训练模型传入,再给一个随机的tensor,然后生成.pt文件。
2.c++(libtorch)加载模型,完成语义分割
这一块我研究了很久,因为网上的资料并不多,大家的网络都不一样,实现可能也有些不同,所以首先要看懂给的demo里面是如何用python实现语义分割的。
大体的步骤是:首先根据读入的参数创建一个模型
model = espnetv2_seg(args)#将各种参数传入然后加载预训练的参数:
weight_dict = torch.load(args.weights_test, map_location=torch.device('cuda'))
model.load_state_dict(weight_dict)然后读入图像,并对图像进行一系列的处理,包括,resize大小,从BGR转化为RGB,将图像转化成tensor,归一化,然后传入模型,得到输出的tensor,并转化为numpy,在转化成图片,回复大小,给图片上色,转化成RGB,保存,因此,我们的c++程序得按照类似的步骤进行,首先贴上cmakelists
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(example-app)
SET(CMAKE_BUILD_TYPE Release)
MESSAGE("Build type: " ${CMAKE_BUILD_TYPE})
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Wall -O3 -march=native ")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -O3 -march=native")
#set( CMAKE_CXX_FLAGS "-std=c++11 -O3" )
#Check C++11 or C++0x support
include(CheckCXXCompilerFlag)
CHECK_CXX_COMPILER_FLAG("-std=c++11" COMPILER_SUPPORTS_CXX11)
CHECK_CXX_COMPILER_FLAG("-std=c++0x" COMPILER_SUPPORTS_CXX0X)
if(COMPILER_SUPPORTS_CXX11)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
add_definitions(-DCOMPILEDWITHC11)
message(STATUS "Using flag -std=c++11.")
elseif(COMPILER_SUPPORTS_CXX0X)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++0x")
add_definitions(-DCOMPILEDWITHC0X)
message(STATUS "Using flag -std=c++0x.")
else()
message(FATAL_ERROR "The compiler ${CMAKE_CXX_COMPILER} has no C++11 support. Please use a different C++ compiler.")
endif()
if( TORCH_PATH )
message("TORCH_PATH set to: ${TORCH_PATH}")
set(Torch_DIR ${TORCH_PATH})
else()
message(FATAL_ERROR "Need to specify Torch path, e.g., pytorch/torch/share/cmake/Torch ")
endif()
find_package(OpenCV 3.4.3 REQUIRED)
find_package(Torch REQUIRED)
message(STATUS "Torch version is: ${Torch_VERSION}")
if(Torch_VERSION GREATER 1.0.1)
message(STATUS "Torch version is newer than v1.0.1, will use new api")
add_definitions(-DTORCH_NEW_API) #TORCH_NEW_API这个变量在代码中被检测是否定义,因为不同版本的一些功能的使用方法不一样
endif()
add_executable(example-app example-app.cpp)
target_link_libraries(example-app ${TORCH_LIBRARIES} ${OpenCV_LIBS})
set_property(TARGET example-app PROPERTY CXX_STANDARD 11)
add_executable(example-c example-c.cpp)
target_link_libraries(example-c ${TORCH_LIBRARIES} ${OpenCV_LIBS})
set_property(TARGET example-c PROPERTY CXX_STANDARD 11)build.sh
mkdir build
cd build
cmake .. -DCMAKE_BUILD_TYPE=Release -DTORCH_PATH=/home/azs/anaconda3/lib/python3.6/site-packages/torch/share/cmake/Torch #使用anaconda里面的pytorch
make -j8创建时,根据设置的环境变量TORCH_PATH找到torch的cmake文件。
这里我写了两个程序,example-app.cpp是可以读取TUM数据集里面的一个文件夹下的图片,从而实现对多张图片连续进行语义分割,example-c.cpp是对单张图片实现语义分割。以单张的代码为例:
#include
#include
#include "torch/script.h"
#include "torch/torch.h"
#include "opencv2/core.hpp"
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/imgcodecs.hpp"
#include
#include
#include
#include
using namespace std;
//上色
void Visualization(cv::Mat prediction_map, std::string LUT_file) {
cv::cvtColor(prediction_map.clone(), prediction_map, CV_GRAY2BGR);
cv::Mat label_colours = cv::imread(LUT_file,1);
cv::cvtColor(label_colours, label_colours, CV_RGB2BGR);
cv::Mat output_image;
LUT(prediction_map, label_colours, output_image);
cv::imshow( "Display window", output_image);
}
//对图片首先进行处理,返回张量
torch::Tensor process( cv::Mat& image,torch::Device device,int img_size)
{
cv::imshow("test1",image);
//首先对输入的图片进行处理
cv::cvtColor(image, image, CV_BGR2RGB);// bgr -> rgb
cv::Mat img_float;
// image.convertTo(img_float, CV_32F, 1.0 / 255);//归一化到[0,1]区间,
cv::resize(image, img_float, cv::Size(img_size, img_size));
std::vector dims = {1, img_size, img_size, 3};
#if defined(TORCH_NEW_API) //根据编译结果选择执行哪一段
torch::Tensor img_var = torch::from_blob(img_float.data, dims, torch::kByte).to(device);//将图像转化成张量
#else
//下面这两句只有使用老版本的时候才用
torch::Tensor img_tensor = torch::CPU(torch::kFloat32).tensorFromBlob(img_float.data, dims);
torch::Tensor img_var = torch::autograd::make_variable(img_tensor, false).to(device);//创建图像变量
#endif
img_var = img_var.permute({0,3,1,2});//将张量的参数顺序转化为 torch输入的格式 1,3,384,384
img_var = img_var.toType(torch::kFloat);
img_var = img_var.div(255);
return img_var;
}
int main() {
char path[] = "../h2.png";
int img_size = 384;
std::string LUT_file="../pascal.png";
//设置device类型
torch::DeviceType device_type;
device_type = torch::kCUDA;
torch::Device device(device_type);
std::cout<<"cudu support:"<< (torch::cuda::is_available()?"ture":"false")<,新版本是对象,使用.
//std::shared_ptr module = torch::jit::load("../espnetv2_s_2.0_pascal_384x384.pt");
module.to(device);
// 读取图片
cv::Mat image = cv::imread(path,cv::ImreadModes::IMREAD_COLOR);
//对图片进行处理,得到张量
torch::Tensor img_var=process(image,device,img_size);
std::chrono::steady_clock::time_point t1 = std::chrono::steady_clock::now();
torch::Tensor result = module.forward({img_var}).toTensor(); //前向传播获取结果,还是tensor类型
std::chrono::steady_clock::time_point t2 = std::chrono::steady_clock::now();
std::cout << "Processing time = " << (std::chrono::duration_cast(t2 - t1).count())/1000000.0 << " sec" < 注释都写在里面了,最后的运行结果:
原图:

结果:

如果运行example-app.cpp这个程序,时间结果如下:
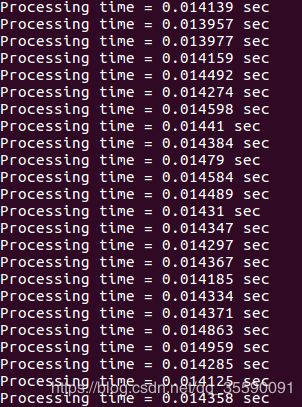
可以看到,处理时间大都是14ms左右。但是有一点需要注意,预测单张照片时间和连续预测多张照片平均下来的每张照片的处理时间差距很大,单纯的处理一张照片可能需要300ms,但是连续的话就只需要14ms。
我的代码下载地址
参考目录:
https://blog.csdn.net/cp562090732/article/details/100172372?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task#4__142
https://blog.csdn.net/pplxlee/article/details/90445316
https://blog.csdn.net/u010397980/article/details/89437628
https://blog.csdn.net/IAMoldpan/article/details/85057238
https://www.cnblogs.com/geoffreyone/p/10827010.html
https://www.jianshu.com/p/aee6a3d72014
https://www.jianshu.com/p/7cddc09ca7a4
编译遇到的一些问题参考:
https://www.jianshu.com/p/186bcdfe9492