k8s (一) --- Kubernetes介绍及部署(v1.18.1)
Kubernetes介绍及部署
- 一、认识Kubernetes -- k8s
- Kubernetes是什么?
- Kubernetes 特点
- 使用Kubernetes能做什么?
- Kubernetes 设计架构
- 二、Kubernetes的一些重要概念
- 三、Kubernetes集群部署
- 实验准备
- 安装 kubelet、kubeadm 和 kubectl
- 用 kubeadm 创建 Cluster
- 添加 node1 和 node2
- 补充:移除NODE节点的方法
- 添加已删除节点
- 忘掉token再次添加进k8s集群
一、认识Kubernetes – k8s
Kubernetes是什么?
Kubernetes是容器集群管理系统,是一个开源的平台,可以实现容器集群的自动化部署、自动扩缩容、维护等功能。
Kubernetes的名字来自希腊语,意思是“舵手” 或 “领航员”。K8s是将8个字母“ubernete”替换为“8”的缩写。
通过Kubernetes你可以:
- 快速部署应用
- 快速扩展应用
- 无缝对接新的应用功能
- 节省资源,优化硬件资源的使用
Kubernetes的目标是促进完善组件和工具的生态系统,以减轻应用程序在公有云或私有云中运行的负担。
Kubernetes 特点
- 可移植: 支持公有云,私有云,混合云,多重云(multi-cloud)
- 可扩展: 模块化, 插件化, 可挂载, 可组合
- 自动化: 自动部署,自动重启,自动复制,自动伸缩/扩展
Kubernetes是Google 2014年创建管理的,是Google 10多年大规模容器管理技术Borg的开源版本。
使用Kubernetes能做什么?
可以在物理或虚拟机的Kubernetes集群上运行容器化应用,Kubernetes能提供一个以“容器为中心的基础架构”,满足在生产环境中运行应用的一些常见需求,如:
-
多个进程(作为容器运行)协同工作。(Pod)
-
存储系统挂载
-
Distributing secrets
-
应用健康检测
-
应用实例的复制
-
Pod自动伸缩/扩展
-
Naming and discovering
-
负载均衡
-
滚动更新
-
资源监控
-
日志访问
-
调试应用程序
-
提供认证和授权
Kubernetes 设计架构
Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc),一切都基于分布式的存储系统。下面这张图是Kubernetes的架构图。
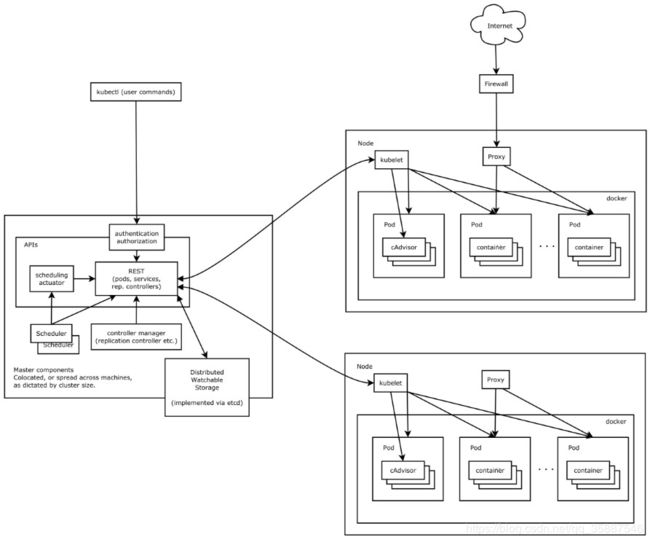
Kubernetes主要由以下几个核心组件组成:
etcd保存了整个集群的状态;
apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的Add-ons:
kube-dns负责为整个集群提供DNS服务
Ingress Controller为服务提供外网入口
Heapster提供资源监控
Dashboard提供GUI
Federation提供跨可用区的集群
Fluentd-elasticsearch提供集群日志采集、存储与查询
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示

核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
接口层:kubectl命令行工具、客户端SDK以及集群联邦
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
二、Kubernetes的一些重要概念
1.cluster
cluster是 计算、存储和网络资源的集合,k8s利用这些资源运行各种基于容器的应用。
2.master
master是cluster的大脑,他的主要职责是调度,即决定将应用放在那里运行。master运行linux操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个master。
3.node
node的职责是运行容器应用。node由master管理,node负责监控并汇报容器的状态,同时根据master的要求管理容器的生命周期。node运行在linux的操作系统上,可以是物理机或者是虚拟机。
4.pod
pod是k8s的最小工作单元。每个pod包含一个或者多个容器。pod中的容器会作为一个整体被master调度到一个node上运行。
5.controller
k8s通常不会直接创建pod,而是通过controller来管理pod的。controller中定义了pod的部署特性,比如有几个剧本,在什么样的node上运行等。为了满足不同的业务场景,k8s提供了多种controller,包括deployment、replicaset、daemonset、statefulset、job等。
6.deployment
是最常用的controller。deployment可以管理pod的多个副本,并确保pod按照期望的状态运行。
7.replicaset
实现了pod的多副本管理。使用deployment时会自动创建replicaset,也就是说deployment是通过replicaset来管理pod的多个副本的,我们通常不需要直接使用replicaset。
8.daemonset
用于每个node最多只运行一个pod副本的场景。正如其名称所示的,daemonset通常用于运行daemon。
9.statefuleset
能够保证pod的每个副本在整个生命周期中名称是不变的,而其他controller不提供这个功能。当某个pod发生故障需要删除并重新启动时,pod的名称会发生变化,同时statefulset会保证副本按照固定的顺序启动、更新或者删除。
10.job
用于运行结束就删除的应用,而其他controller中的pod通常是长期持续运行的。
11.service
deployment可以部署多个副本,每个pod 都有自己的IP,外界如何访问这些副本那?
答案是service
k8s的 service定义了外界访问一组特定pod的方式。service有自己的IP和端口,service为pod提供了负载均衡。
k8s运行容器pod与访问容器这两项任务分别由controller和service执行。
12.namespace
可以将一个物理的cluster逻辑上划分成多个虚拟cluster,每个cluster就是一个namespace。不同的namespace里的资源是完全隔离的。
三、Kubernetes集群部署
实验准备
1.准备三台虚拟机(rhel7.6)
| 主机名 | ip | 作用 |
|---|---|---|
| server1 | 172.25.63.1 | master |
| server2 | 172.25.63.2 | node1 |
| server3 | 172.25.63.3 | node2 |
之前这三个主机做过swarm集群,因此首先将这个集群解散:
[root@server2 ~]# docker swarm leave
[root@server3 ~]# docker swarm leave
[root@server1 ~]# docker swarm leave --force
2.各主机selinux和火墙均为关闭状态。
3.要求集群主机时间同步。
安装 kubelet、kubeadm 和 kubectl
官方安装文档可以参考 https://kubernetes.io/docs/setup/independent/install-kubeadm/
第一步:安装docker
所有节点都需要安装docker
每个节点都需要使docker开机自启
systemctl enable docker
每个节点均部署镜像加速器
docker 的安装可以参考:https://blog.csdn.net/qq_35887546/article/details/105366356
镜像加速器的设置可以参考:https://blog.csdn.net/qq_35887546/article/details/105367592
第二步:配置k8s的yum文件
每台主机都要配置,以下以server1为例。
[root@server1 ~]# cd /etc/yum.repos.d/
[root@server1 yum.repos.d]# vim k8s.repo
[root@server1 yum.repos.d]# cat k8s.repo
[k8s]
name=k8s
enabled=1
gpgcheck=0
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
第三步:安装 kubelet、kubeadm 和 kubectl(所有节点执行)
kubelet 运行在 Cluster 所有节点上,负责启动 Pod 和容器。
kubeadm 用于初始化 Cluster。
kubectl 是 Kubernetes 命令行工具。通过 kubectl 可以部署和管理应用,查看各种资源,创建、删除和更新各种组件。
yum install kubelet kubeadm kubectl -y
第四步:启动kubelet
此时,还不能启动kubelet,因为此时配置还不能,现在仅仅可以设置开机自启动
每个主机执行:
systemctl enable --now kubelet
用 kubeadm 创建 Cluster
第一步:环境准备(各个节点都需要执行下面的操作master,node)
1.CPU数量至少两个否则会报错
2.主机名必须解析
每个主机做解析
[root@server1 ~]# cat /etc/hosts
172.25.63.250 foundation63.ilt.example.com
172.25.63.1 server1 reg.westos.org
172.25.63.2 server2
172.25.63.3 server3
3.要保证打开内置的桥功能,这个是借助于iptables来实现的
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
4.需要禁止各个节点启用swap,如果启用了swap,那么kubelet就无法启动
[root@server1 ~]# swapoff -a && sysctl -w vm.swappiness=0
vm.swappiness = 0
[root@server1 ~]# free -m
total used free shared buff/cache available
Mem: 769 305 104 5 359 312
Swap: 0 0 0
之后更改/etc/fstab文件将swap那一行注释掉即可实现永久关闭。
5.关闭防火墙和selinux
6.删除docker machine添加的认证文件
由于之前server2 和server3 是由docker machine添加的主机因此需要将认证文件删除:
[root@server2 ~]# cd /etc/systemd/system/docker.service.d/
[root@server2 docker.service.d]# ls
10-machine.conf
[root@server2 docker.service.d]# rm -f 10-machine.conf
[root@server3 ~]# cd /etc/systemd/system/docker.service.d/
[root@server3 docker.service.d]# rm -f 10-machine.conf
若没有该文件跳过此步。
7.将docker的cgroup驱动更改为systemd
更改docker的daemon文件
具体内容可以查看:https://kubernetes.io/zh/docs/setup/production-environment/container-runtimes/
[root@server1 ~]# vim /etc/docker/daemon.json
[root@server1 ~]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://ioeo57w5.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
之后重启docker:
systemctl daemon-reload
systemctl restart docker
每个节点都需要设置:
[root@server1 docker]# scp daemon.json server2:/etc/docker/
daemon.json 100% 287 328.6KB/s 00:00
[root@server1 docker]# scp daemon.json server3:/etc/docker/
daemon.json 100% 287 300.0KB/s 00:00
第二步:初始化master
在初始化的时候可以选择更高的版本,例如:1.18.1
[root@server1 ~]# kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.1 --pod-network-cidr=10.244.0.0/16
其中字段含义:
-
--image-repository string:这个用于指定从什么位置来拉取镜像(1.13版本才有的),默认值是k8s.gcr.io,我们将其指定为国内镜像地址:registry.aliyuncs.com/google_containers,也可以先将镜像下载下来放到私有仓库直接从私有仓库拉取。 -
--kubernetes-version string:指定kubenets版本号,默认值是stable-1,会导致从https://dl.k8s.io/release/stable-1.txt下载最新的版本号,我们可以将其指定为固定版本(最新版:v1.18.1)来跳过网络请求。 -
--apiserver-advertise-address指明用 Master 的哪个 interface 与 Cluster
的其他节点通信。如果 Master 有多个 interface,建议明确指定,如果不指定,kubeadm 会自动选择有默认网关的interface。 -
--pod-network-cidr指定 Pod 网络的范围。Kubernetes 支持多种网络方案,而且不同网络方案对--pod-network-cidr有自己的要求,这里设置为10.244.0.0/16 是因为我们将使用 flannel 网络方案,必须设置成这个 CIDR。
看到下面的输出就表示你的集群创建成功了:
......
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 172.25.63.1:6443 --token cmpyar.n4arbbq0i9irhmum \
--discovery-token-ca-cert-hash sha256:542e77bad47c73c3336ce601ad9fe2078381ea8b04b95f377f46520296a79fe2
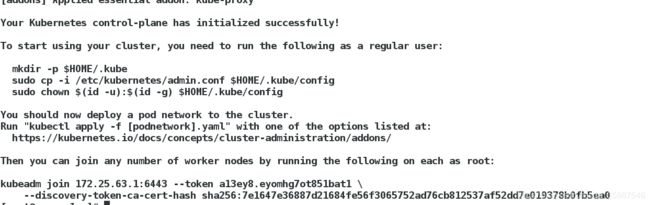 成功后注意最后一个命令,这个join命令可以用来添加节点。
成功后注意最后一个命令,这个join命令可以用来添加节点。
如果初始化失败,请使用如下代码清除后重新初始化
# kubeadm reset
第三步:配置kubectl
kubectl 是管理 Kubernetes Cluster 的命令行工具,前面我们已经在所有的节点安装了 kubectl。Master 初始化完成后需要做一些配置工作,然后 kubectl 就能使用了。
[root@server1 ~]# mkdir -p $HOME/.kube
[root@server1 ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@server1 ~]# chown $(id -u):$(id -g) $HOME/.kube/config
为了使用更便捷,启用 kubectl 命令的自动补全功能。
[root@server1 ~]# echo "source <(kubectl completion bash)" >> ~/.bashrc
现在kubectl可以使用了
[root@server1 ~]# kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
controller-manager Healthy ok
第四步:安装pod网络
要让 Kubernetes Cluster 能够工作,必须安装 Pod 网络,否则 Pod 之间无法通信。
Kubernetes 支持多种网络方案,这里我们先使用 flannel,后面还会讨论 Canal。
[root@server1 ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml

每个节点启动kubelet
systemctl restart kubelet
等镜像下载完成以后,看到node的状态是ready了
[root@server1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
server1 Ready master 18m v1.18.1
此时,就可以看到pod信息了
[root@server1 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7ff77c879f-8gzr5 1/1 Running 0 18m
coredns-7ff77c879f-dxst6 1/1 Running 0 18m
etcd-server1 1/1 Running 1 18m
kube-apiserver-server1 1/1 Running 1 18m
kube-controller-manager-server1 1/1 Running 4 18m
kube-flannel-ds-amd64-wcqrh 1/1 Running 0 8m36s
kube-proxy-lzdn8 1/1 Running 0 18m
kube-scheduler-server1 1/1 Running 4 18m
添加 node1 和 node2
第一步:环境准备
实验的准备之前都完成了
1.node节点关闭防火墙和selinux
2.禁用swap
- 解析主机名
4.启动内核功能
启动kubelet
只需要设置为开机自启动就可以了
systemctl enable kubelet
第二步:添加nodes
这里的–token 来自前面kubeadm init输出提示,如果当时没有记录下来可以通过kubeadm token list 查看。
在需要添加的节点运行:
kubeadm join 172.20.10.2:6443 --token rn816q.zj0crlasganmrzsr --discovery-token-ca-cert-hash sha256:e339e4dbf6bd1323c13e794760fff3cbeb7a3f6f42b71d4cb3cffdde72179903
第三步:查看nodes
根据上面最后一行的输出信息提示查看nodes
[root@server1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
server1 Ready master 38m v1.18.1
server2 NotReady <none> 2m41s v1.18.1
server3 NotReady <none> 2m10s v1.18.1
这里其实需要等一会,这个server2 server3节点才会变成Ready状态,因为node节点需要下载四个镜像flannel coredns kube-proxy pause
过了一会查看节点状态
[root@server1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
server1 Ready master 47m v1.18.1
server2 Ready <none> 11m v1.18.1
server3 Ready <none> 11m v1.18.1
补充:移除NODE节点的方法
第一步:先将节点设置为维护模式(server2是节点名称)
[root@server1 ~]# kubectl drain server2 --delete-local-data --force --ignore-daemonsets
第二步:然后删除节点
[root@server1 ~]# kubectl delete node server2
第三步:查看节点
发现server2节点已经被删除了
[root@server1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
server1 Ready master 47m v1.18.1
server3 Ready <none> 11m v1.18.1
添加已删除节点
如果这个时候再想添加进来这个node,需要执行两步操作
第一步:停掉kubelet(需要添加进来的节点操作)
[root@server2 ~]# systemctl stop kubelet
第二步:删除相关文件
[root@server2 ~]# rm -rf /etc/kubernetes/*
第三步:添加节点
[root@server2 ~]# kubeadm join 172.25.63.1:6443 --token cmpyar.n4arbbq0i9irhmum --discovery-token-ca-cert-hash sha256:542e77bad47c73c3336ce601ad9fe2078381ea8b04b95f377f46520296a79fe2
第四步:查看节点
kubectl get nodes
[root@server1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
server1 Ready master 47m v1.18.1
server2 Ready <none> 11m v1.18.1
server3 Ready <none> 11m v1.18.1
忘掉token再次添加进k8s集群
第一步:主节点执行命令
在主控节点,获取token:
[root@server1 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
cmpyar.n4arbbq0i9irhmum 23h 2020-04-18T20:47:06+08:00 authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token
第二步: 获取ca证书sha256编码hash值
在主控节点
[root@server1 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
542e77bad47c73c3336ce601ad9fe2078381ea8b04b95f377f46520296a79fe2
第三步:从节点执行如下的命令
[root@server2 ~]# systemctl stop kubelet
第四步:删除相关文件
[root@server2 ~]# rm -rf /etc/kubernetes/*
第五步:加入集群
指定主节点IP,端口是6443
在生成的证书前有sha256:
[root@server2 ~]# kubeadm join 172.25.63.1:6443 --token cmpyar.n4arbbq0i9irhmum --discovery-token-ca-cert-hash sha256:542e77bad47c73c3336ce601ad9fe2078381ea8b04b95f377f46520296a79fe2
之后即可查看节点。