Kafka实现消息队列——Java
1. Kafka的安装部署可从之前一篇文章看到
Kafka安装部署完整教程——常遇到的各种错误https://blog.csdn.net/qq_37842366/article/details/99966001
2.在本地写Java程序
1)创建Maven项目

点击下一步,写好项目名称,完成,目录结构如下

2)在pom.xml中添加kafka依赖项
org.scala-lang
scala-reflect
2.10.1
项目在自己安装环境时会出现一些依赖包错误情况,这个地方耽误了我好多时间。
Failure to transfer com.yammer.metrics:metrics-annotation:jar:2.2.0
由于已经改好没有报错,之前忘记记录报错信息,只记得这一条。反正就是诸如以上的错误。
重点是解决方法!
项目 - 右键 - Build Path - Configure Build Path
如果有错误,可以在这里看到某一个依赖包错误的前面有红叉,然后每一个依赖包后面都跟着本地路径,找到出错的依赖包的本地路径,将里面的.lastUpdated文件删除。

项目-右键-Maven-Disable Maven Nature
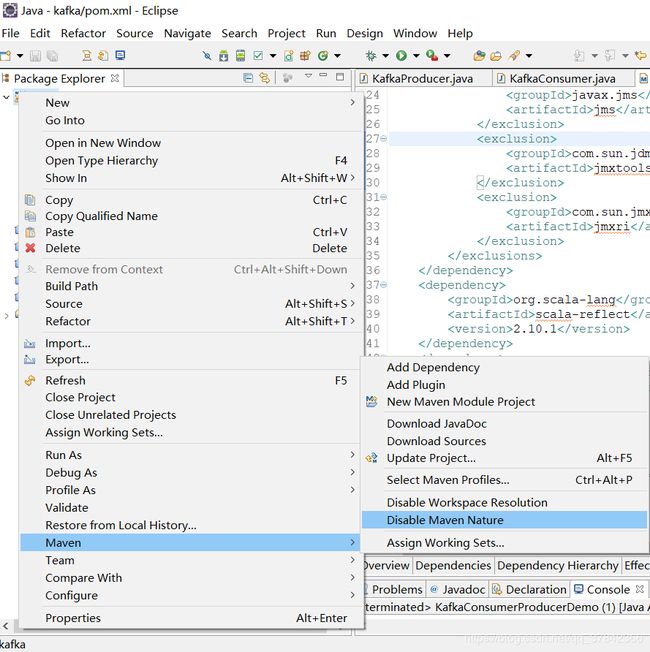
再右击项目中 configure 中的 convert maven 接下来项目会重新下载。等待一会儿就会发现之前报错的一些依赖包重新下载完成了。
这时候我发现,还有俩依赖包有问题:
缺少com.sun.jdmk:jmxtools:jar:1.2.1
还有jmx
解决方法!
修改配置文件
< dependency >
< groupId > log4j
< artifactId > log4j
< version > 1 .2 .15
< scope > compile
原因我也没太理解
最终的pom.xml代码:
4.0.0
kafkaT
kafkaT
0.0.1-SNAPSHOT
jar
kafkaT
http://maven.apache.org
UTF-8
log4j
log4j
1.2.15
javax.jms
jms
com.sun.jdmk
jmxtools
com.sun.jmx
jmxri
org.scala-lang
scala-reflect
2.10.1
com.yammer.metrics
metrics-core
2.2.0
junit
junit
3.8.1
test
org.apache.kafka
kafka_2.10
0.8.0
3)编写kafka配置文件接口
package kafka.kafka;
public interface KafkaProperties {
final static String zkConnect = "172.18.37.14:2181";
final static String groupId = "group1";
final static String topic = "topic1";
final static String kafkaServerURL = "172.18.37.14";
final static int kafkaServerPort = 9092;
final static int kafkaProducerBufferSize = 64 * 1024;
final static int connectionTimeOut = 20000;
final static int reconnectInterval = 10000;
final static String topic2 = "topic2";
final static String topic3 = "topic3";
final static String clientId = "SimpleConsumerDemoClient";
}
4) 编写生产者
package kafka.kafka;
import java.util.Properties;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class KafkaProducer extends Thread
{
private final kafka.javaapi.producer.Producer producer;
private final String topic;
private final Properties props = new Properties();
public KafkaProducer(String topic)
{
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list", "172.18.37.14:9092");
producer = new kafka.javaapi.producer.Producer(new ProducerConfig(props));
this.topic = topic;
}
@Override
public void run() {
int messageNo = 1;
while (true)
{
String messageStr = new String("Message_" + messageNo);
System.out.println("Send:" + messageStr);
producer.send(new KeyedMessage(topic, messageStr));
messageNo++;
try {
sleep(3000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
5) 编写消费者
package kafka.kafka;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class KafkaConsumer extends Thread
{
private final ConsumerConnector consumer;
private final String topic;
public KafkaConsumer(String topic)
{
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
this.topic = topic;
}
private static ConsumerConfig createConsumerConfig()
{
Properties props = new Properties();
props.put("zookeeper.connect", KafkaProperties.zkConnect);
props.put("group.id", KafkaProperties.groupId);
props.put("zookeeper.session.timeout.ms", "40000");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
@Override
public void run() {
Map topicCountMap = new HashMap();
topicCountMap.put(topic, new Integer(1));
Map>> consumerMap = consumer.createMessageStreams(topicCountMap);
KafkaStream stream = consumerMap.get(topic).get(0);
ConsumerIterator it = stream.iterator();
while (it.hasNext()) {
System.out.println("receive:" + new String(it.next().message()));
try {
sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
6) 编写发送和接收main入口
package kafka.kafka;
//路径(在虚拟机中运行会用到):kafka.kafka.KafkaConsumerProducerDemo
public class KafkaConsumerProducerDemo {
public static void main(String[] args)
{
KafkaProducer producerThread = new KafkaProducer(KafkaProperties.topic);
producerThread.start();
KafkaConsumer consumerThread = new KafkaConsumer(KafkaProperties.topic);
consumerThread.start();
}
}
3. 打包本地项目为jar文件
项目-右键-Export-Java-Runnable JAR file

4. 运行jar包
将jar包放在虚拟机上,开启kafka服务,运行jar包
实现了简单的发送和接收消息
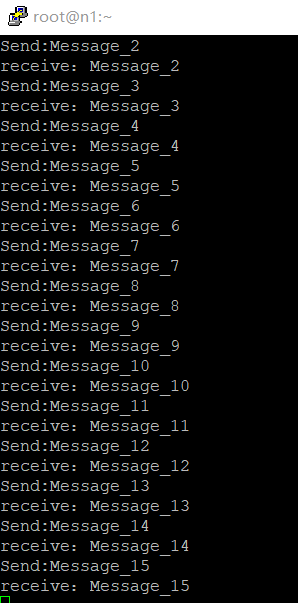
5. 多消费者消息队列
又用了几乎一天的时间才实现,先看结果哈哈~
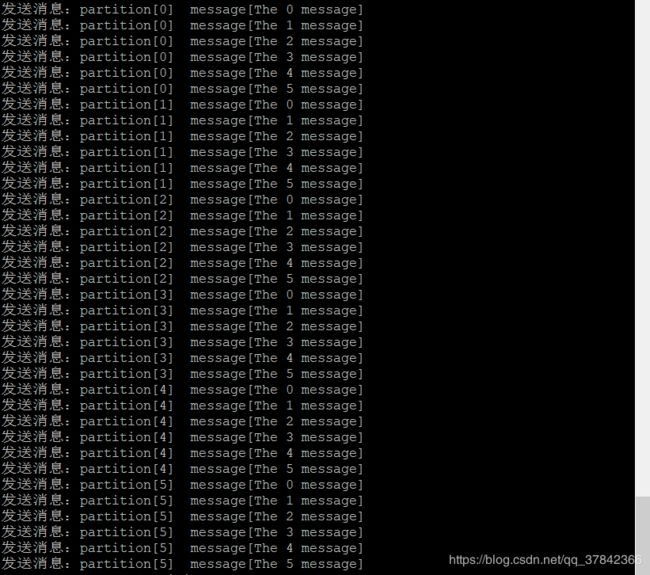
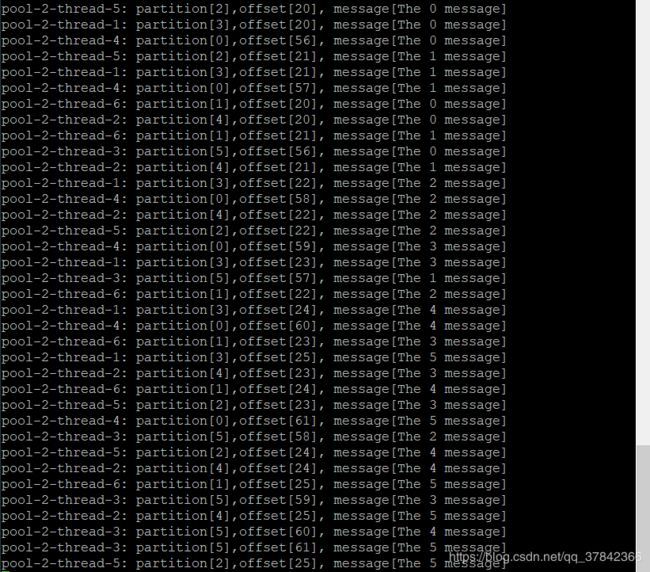
我建立了6个分区,在每一个分区上发送6条消息,由于一个分区只能被具体某一个消费线程消费,就建立了6个消费线程,可以看到他们只消费一个具体分区内的内容,每一条消息只被消费一次,且是先进先出的队列消费形式。
接下来讲实现过程
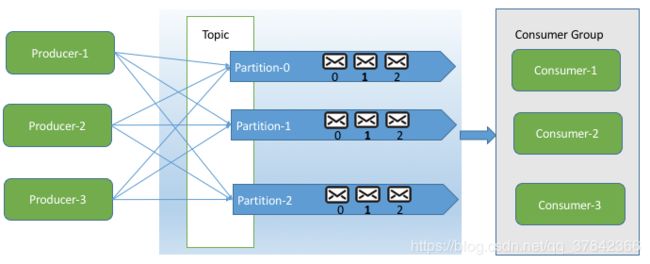
首先看一张图(网上的图,大致都一样,我挑了一张简单易懂的)
1) 生产者代码
package kafkademo;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class KafkaProducer extends Thread {
private Producer producer = null;
private ProducerConfig config = null;
public KafkaProducer() {
Properties props = new Properties();
props.put("zookeeper.connect", "172.18.37.14:2181");
// 指定序列化处理类,默认为kafka.serializer.DefaultEncoder,即byte[]
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 同步还是异步,默认2表同步,1表异步。异步可以提高发送吞吐量,但是也可能导致丢失未发送过去的消息
props.put("producer.type", "sync");
// 是否压缩,默认0表示不压缩,1表示用gzip压缩,2表示用snappy压缩。压缩后消息中会有头来指明消息压缩类型,故在消费者端消息解压是透明的无需指定。
props.put("compression.codec", "1");
// 指定kafka节点列表,用于获取metadata(元数据),不必全部指定
props.put("metadata.broker.list", "172.18.37.14:9092");
config = new ProducerConfig(props);
}
@Override
public void run() {
producer = new Producer(config);
for(int i = 0; i <= 5; i++){ //往6个分区发数据
List> messageList = new ArrayList>();
for(int j = 0; j < 6; j++){ //每个分区6条讯息
messageList.add(new KeyedMessage
//String topic, String partition, String message
("blog", "partition[" + i + "]", "message[The " + j + " message]"));
System.out.println("发送消息:"+"partition[" + i + "]"+" "+"message[The " + j + " message]");
}
producer.send(messageList);
}
}
public static void main(String[] args) {
Thread t = new Thread(new KafkaProducer());
t.start();
}
}
2) 消费者线程代码
package kafkademo;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.message.MessageAndMetadata;
public class KafkaConsumerThread extends Thread {
private KafkaStream stream;
public KafkaConsumerThread(KafkaStream stream) {
this.stream = stream;
}
@Override
public void run() {
ConsumerIterator it = stream.iterator();
while (it.hasNext()) {
MessageAndMetadata mam = it.next();
System.out.println(Thread.currentThread().getName() + ": partition[" + mam.partition() + "],"
+ "offset[" + mam.offset() + "], " + new String(mam.message()));
}
}
}
3)消费者代码
package kafkademo;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class KafkaConsumer extends Thread {
private ConsumerConfig consumerConfig;
private static String topic="blog";
Properties props;
final int a_numThreads = 6;
public KafkaConsumer() {
props = new Properties();
props.put("zookeeper.connect", "172.18.37.14:2181");
props.put("group.id", "blog");
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("auto.offset.reset", "smallest");
consumerConfig = new ConsumerConfig(props);
}
@Override
public void run() {
Map topicCountMap = new HashMap();
topicCountMap.put(topic, new Integer(a_numThreads));
ConsumerConfig consumerConfig = new ConsumerConfig(props);
ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(consumerConfig);
Map>> consumerMap = consumer.createMessageStreams(topicCountMap);
List> streams = consumerMap.get(topic);
ExecutorService executor = Executors.newFixedThreadPool(a_numThreads);
for (final KafkaStream stream : streams) {
executor.submit(new KafkaConsumerThread(stream));
}
}
public static void main(String[] args) {
System.out.println(topic);
Thread t = new Thread(new KafkaConsumer());
t.start();
}
}
4) 程序入口
package kafkademo;
public class KafkaConsumerProducerDemo {
public static void main(String[] args)
{
KafkaProducer producerThread = new KafkaProducer();
producerThread.start();
KafkaConsumer consumerThread = new KafkaConsumer();
consumerThread.start();
}
}