Kafka基础入门
前言
Kafka 是一个 Java 开发的 MQ 中间件,依赖于 Zookeper,有高可用,高吞吐量等特点。

一、消息队列
在说 Kafka 之前,首先要理解什么是消息队列(Message Queue,简称 MQ)。消息队列是帮助应用和应用之间进行数据传输的一个队列,而队列相信都不陌生,一种先进先出的数据结构。
 消息队列是解决应用与应用之间数据传输的中间件,注意与
消息队列是解决应用与应用之间数据传输的中间件,注意与 java.util.queue 中的队列进行区分。把数据放到消息队列的叫做生产者,从消息队列里边取数据的叫做消费者。使用消息队列可以实现两个应用之间的数据传输,那么为什么要使用消息队列呢?
两个应用之间进行数据传输完全可以使用 HTTP 请求来实现:A、B两个应用,B应用需要A应用处理的数据,那么B应用可以暴露一个接口,A应用调用B的接口传输数据,比如 spring-cloud 中 feign 请求。那现在除了B需要A的数据之外,又来了一个C,此时就要修改A的代码,新增一步:调用C的接口。但是如果又来了一个D。。。。就类似于广播的形式。
上面的实现方式可以发现,生产者和消费者紧密耦合,但是如果使用消息队列:现在在A、B直接有一个队列,A应用只负责往队列里丢数据,而谁需要取这个数据,应用A一点都不关心,如果再来一个应用D,该应用也只需从队列中取数据即可。这样一来,各个应用直接就相互解耦,只与队列本身产生联系。另一方面,在上面 HTTP 请求方式的实现中,应用A的压力较大,如果有100个消费者,A就要调用100个不同的接口,采用消息队列可以减少A应用的压力。
消费者消费队列中的数据有两种方式:
- 生产者将数据放到消息队列中,然后主动叫消费者去拿(俗称 push ),优点是可以尽可能快地将消息发送给消费者,缺点是如果消费者处理能力跟不上,消费者的缓冲区可能会溢出。
- 消费者不断去轮训消息队列,看看有没有新的数据,如果有就消费(俗称 pull ),优点是消费端可以按处理能力进行拉去,缺点是会增加消息延迟。Kafka 采用的就是该方式。
消息的传递模式主要有两种:点对点传递模式(point to point, queue)、发布-订阅模式(publish/subscribe,topic)。
点对点模式:生产者生产消息发送到队列中,然后消费者从队列中取出并处理。注意:消息被消费者取出消费后,队列中将不再有该消息的存储,所以消息消费者不可能消费到已经被消费过的消息。
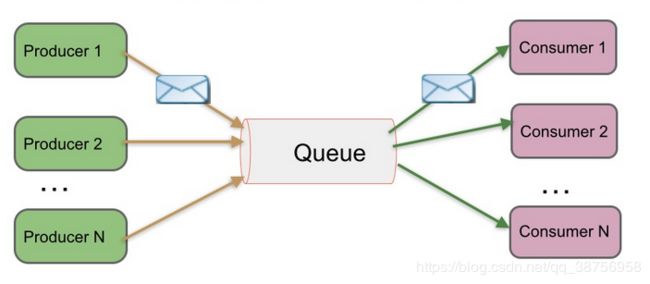
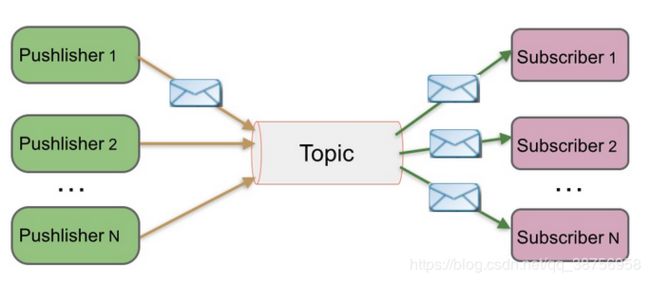
发布-订阅模式:生产者(发布)将消息发布到一个 topic 中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。就像现实生活中多个读者订阅同一个主题栏目,一旦该栏目有新的文章发版,每个订阅的读者都能读到。Kafka 就是发布订阅模式。
二、Kafka简介
Kafka是一个分布式、分区的、多副本的、多订阅者的、基于zookeeper协调的分布式日志系统,也可用做做MQ系统,常用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。客户端和服务端之间通过TCP协议进行通讯。
Topic
Topic 就是数据的类别,每条发布到 Kafka 的消息都有一个类别,这个类别被称为 Topic。就像若干个读者订阅一个栏目主题,这个栏目主题就是 Topic,生产者发布文章要指定该文章的 Topic,以供订阅了这个 Topic 的读者能接受到。因此在 Kafka 中可以存在多个不同 Topic 的数据。
Partition
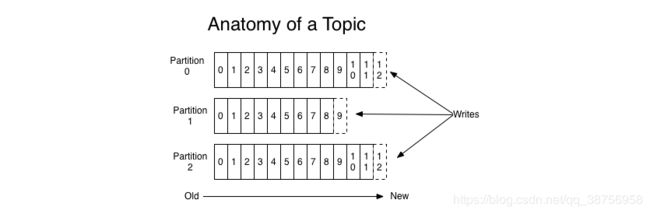
Partition 分区。Topic 中的数据被分割为一个或多个 partition。每个 Topic 至少有一个 partition。每个 partition 中的数据使用多个 segment 文件存储。partition 里的数据是有序的,但是 partition 间是没有顺序的。如果 topic 有多个 partition,那么在消费数据时就不能保证哪个 partition 先被消费,在需要严格保证消息的消费顺序的场景下,需要将 partition 数目设为1。
Topic 就像栏目,比如社科类,文学类,科幻类。出版社就像生产者,读者就像订阅者。一个 partition 就像一本书,segment 就像书中的章节,partition 中的数据是有序的,正如章节是有序的。订阅者在获取数据的时候,只能保证 partition 中的数据按顺序消费,但是 partition 之间是无序的,正如读者订阅了文学类,但是文学类有十本书,书和书直接没有顺序,先发给你哪一本是不确定的。
Broker
Kafka 集群包含一个或多个服务器,服务器节点称为一个 broker,也就是说 Kafka 集群由多个 broker 构成。
broker 存储 topic 的数据,Kafka 会尽可能的将数据平均分配到每个 broker 上。比如一个 topic 有3个 partition,集群有3个 broker,那么每个broker 将存储该 topic 的一个 partition。如果该集群有5个 broker,那么其中有3个broker 存储该 topic 的一个 partition,剩下的2个 broker 不存储该 topic 的 partition 数据。如果集群中 broker 数目少于3个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Producer
Producer 就是生产者,即数据的发布者。Producer 将消息发布到 Kafka 的一个 topic 中。broker 接收到 Producer 发送的消息后,将该消息顺序存储到一个 partition 中,因为是顺序写磁盘,因此效率非常高。生产者也可以指定数据存储的 partition。分区中的每一个记录都会分配一个 id 号来表示顺序,我们称之为 offset,offset 用来唯一的标识分区中每一条记录。
Consumer
Consumer 就是消费者,消费者可以从 broker 中读取数据。一个消费者可以消费多个 topic 中的数据。在每一个消费者中唯一保存的元数据是 offset(偏移量),即消费的位置,因此,Kafka 读取特定消息的时间复杂度为O(1),即与文件大小无关。偏移量由消费者所控制,通常在读取记录后,消费者会以线性的方式增加偏移量,但是实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据。因为 offset 由Consumer 控制,所以 broker 是无状态的,它不需要标记哪些消息被哪些消费过,也不需要通过 broker 去保证同一个Consumer Group 只有一个 Consumer 能消费消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。

Consumer Group
每个 Consumer 都属于一个特定的 Consumer Group(可为每个 Consumer 指定其所属的组 group name,若不指定 group name 则该消费者属于默认的 group)。Kafka 的消费订阅模式是以 Consumer Group 为单位的,对于同一个消息,可以被多个 Consumer Group 所消费,但是 Consumer Group 里只有一个 Consumer 能消费到这条消息。相同的消费者组中不能有比分区更多的消费者,否则多出的消费者一直处于空等待,不会收到消息。
这是 Kafka 用来实现一个 Topic 消息的广播(发给所有的 Consumer)和单播(发给某一个 Consumer)的手段。一个 Topic 可以对应多个 Consumer Group。如果需要实现广播,只要每个 Consumer 有一个独立的 Group 就可以了。要实现单播只要所有的 Consumer 在同一个 Group 里。用 Consumer Group 还可以将 Consumer 进行自由的分组而不需要多次发送消息到不同的Topic。
Leader
如果某一个 broker 宕机,那么里面的数据将不可被消费,导致数据丢失,为了解决这个问题保证数据的安全,每个 partition 都有多个副本 (Replication)存在于其他的 broker 上,在诸多 broker 中,有且仅有一个作为 Leader,只有 Leader 负责数据的读写,Producer 和 Consumer 只与这个 Leader 交互,其它 Replica 作为 Follower 从 Leader 中复制数据。
Follower
Follower 是存放副本 (Replication)的 broker。 Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。如果 Leader 失效,则从 Follower 中选举出一个新的 Leader。当 Follower 挂掉、卡住或者同步太慢,leader 会把这个 follower 从“in sync replicas”(ISR,可以先简单理解为一个维护了 Follower 的列表)列表中删除,然后重新创建一个 Follower。 一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
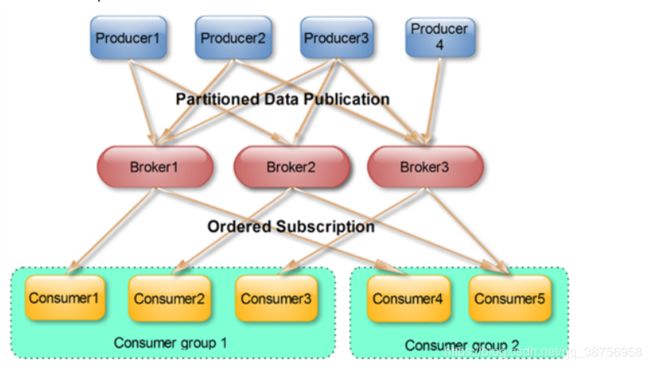
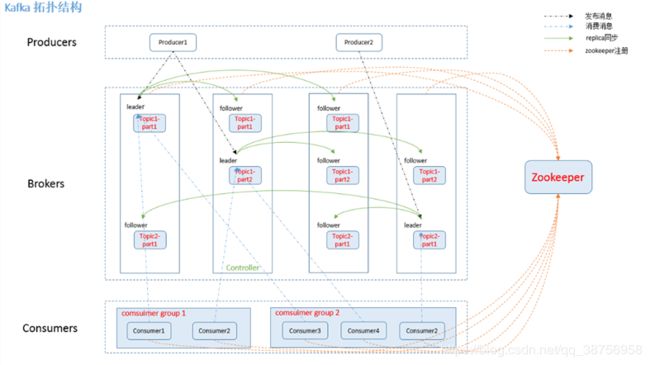
有了以上的介绍,就可以看懂 Kafka 的拓扑图了。如下所示,生产者向 Kafka 集群生产消息,一个消息必须指定其 Topic ,下图有两个 Topic :Topic1 和 Topic2,其中 Topic1 有两个 Partition,分别存储在不同的 broker 上,并存在其副本。Kafka 会尽可能将数据均匀分布到不同的 Partition ,这样就实现了负载均衡。不同的消息可以并行写入不同 broker 的不同 Partition 里,极大的提高了吞吐率。Leader 和 Follower 直接保持同步。每个消费者组都能收到消息,但是该组下只有一个消费者能消费的到这条消息。所有的 broker 和 consumer 都需要注册到 zookeeper 上交给 zookeeper 来管理。
三、Kafka 高可用
Replication
Kafka 在0.8以前的版本中,是没有 Replication 的,一旦某一个 Broker 宕机,则其上所有的 Partition 数据都不可被消费,同时Producer 都不能再将数据存于这些Partition中。
由此可见,在没有 Replication 副本的情况下,一旦某机器宕机或者某个 Broker 停止工作则会造成整个系统的可用性降低。随着集群规模的增加,整个集群中出现该类异常的几率大大增加,因此对于生产系统而言 Replication 机制的引入非常重要。
如果 Producer 使用同步模式,则 Producer 会在尝试重新发送 message.send.max.retries(默认值为3)次后抛出 Exception,用户可以选择停止发送后续数据也可选择继续选择发送。而前者会造成数据的阻塞,后者会造成本应发往该 Broker 的数据的丢失。
如果 Producer 使用异步模式,则 Producer 会尝试重新发送message.send.max.retries(默认值为3)次后记录该异常并继续发送后续数据,这会造成数据丢失并且用户只能通过日志发现该问题。同时,Kafka 的 Producer 并未对异步模式提供 callback 接口。
当集群中的节点出现故障时,能自动进行故障转移,保证数据的可用性。然而自动处理故障需要精确定义节点 “alive” 的概念。Kafka 判断节点是否存活有两种方式。
- 它必须维护与ZooKeeper的session(这个通过ZooKeeper的Heartbeat机制来实现)。
- Follower 必须能及时将 Leader 的消息复制过来,不能“落后太多”。“落后太多”指 Follower 复制的消息落后于 Leader 的条数超过预定值(该值可在
$KAFKA_HOME/config/server.properties中通过replica.lag.max.messages配置,其默认值是4000)或者 Follower 超过一定时间(同样,该值通过replica.lag.time.max.ms来配置,其默认值是10000)未向 Leader 发送 fetch 请求。
满足这两个条件的节点处于 “in sync” 状态。Leader 会通过 ISR(即in-sync Replica)列表追踪所有 “in sync” 的节点。Kafka 的复制机制既不是完全的同步复制,也不是单纯的异步复制。完全同步复制要求所有能工作的 Follower 都复制完,这条消息才会被 commit,这种复制方式极大的影响了吞吐率。异步复制方式下,所有的 Follower 异步的从 Leader 复制数据,数据只要被 Leader 写入 log 就被认为已经 commit,这种情况下如果 Follower 的复制都落后 Leader 很多,此时 Leader 突然宕机,则会丢失数据。而 Kafka 的这种使用 ISR 的方式则很好的均衡了确保数据不丢失以及吞吐率。Follower可以批量的从Leader复制数据,这样极大的提高复制性能。
另外,Kafka 只尝试处理 “fail/recover” 模式的故障,即节点突然停止工作,然后又恢复(节点可能不知道自己曾经挂掉)的状况。Kafka 没有处理所谓的 “Byzantine(拜占庭)” 故障,即一个节点出现了随意响应和恶意响应(可能由于 bug 或 非法操作导致)。
Broker 如何接收生产者的消息
在上一章节中已经讲到,生产者生产的消息实际存放在 Topic 下的 Partition 中,如果不指定 Partition,那么将使用默认的 Partition。所有的 broker 和消费者都会被 Zookeeper 统一管理。
Producer 在发布消息到某个 Partition 时,先通过 ZooKeeper 找到该 Partition 的 Leader,然后无论该 Topic 的 Replication 有多少,Producer 只将该消息发送到 Partition 的 Leader 上。Leader 会将该消息写入其本地 Log。每个 Follower 都从 Leader 上拉取数据,从而保持数据顺序与 Leader 保持一致。Follower 在收到该消息并写入其 Log 后,向 Leader 发送 ACK。一旦 Leader收到了 ISR 列表中的所有 Follower 的ACK,该消息就被认为已经 commit 了,Leader 将增加 HW 并且向 Producer 发送ACK。流程图如下:

Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。
HW(High Watermark):俗称高水位,它标识了一个特定的消息偏移量(offset),消费者只能拉取到这个offset之前的消息。相信下图会让你明白:

Kafka 的消息保障
delivery guarantee,Kafka 是如何进行消息的可靠交付的?
消息交付的可靠性通常有以下三种:
- At most once:最多一次,消息可能会丢,但绝不会重复传输
- At least one:至少一次,消息绝不会丢,但可能会重复传输
- Exactly once :正好一次,每条消息肯定会被传输并且仅传输一次,大部分情况下,这是人们真正想要的。
Kafka 的可靠交付可以分为两个部分:1.生产者生产的消息如何确保被正确接收了。2.如何确保消费者正常消费到了消息
当生产者向 broker 发送消息时,一旦这条消息被 commit,因为副本的存在,它就不会丢。但是如果 Producer 发送数据给broker 后,遇到网络问题而造成通信中断,那 Producer 就无法判断该条消息是否已经 commit。
在 0.11.0.0 之前的版本中, 如果 producer 没有收到表明消息已经被提交的响应, 那么 producer 将重发这条消息, 这其实是 at-least-once 的消息交付语义,因为如果最初的请求事实上执行成功了,那么重传过程中该消息就会被再次写入到 log 当中。
从 0.11.0.0 版本开始,Kafka producer新增了幂等性的传递选项,该选项保证重传不会在 log 中产生重复条目。为实现这个目的, broker 给每个 producer 都分配了一个 ID ,并且 producer 给每条被发送的消息分配了一个序列号来避免产生重复的消息。 同样也是从 0.11.0.0 版本开始,producer 新增了使用类似事务性的语义将消息发送到多个 topic partition 的功能, 也就是说,要么所有的消息都被成功的写入到了 log,要么一个都没写进去。这样就实现了 exactly-once 的数据传递。其实严格意义上来说,这并不是真正的 exactly-once 的数据传递,而是“有效地一次 effectively once”。在分布式系统中要做到 exactly-once 是很困难的。
对于 consumer 来说,因为消息的位置是由消费者来控制的,offset 会被消费者记录到日志中。如果 Consumer 是先读取消息,然后将它的位置保存到 log 中,最后再对消息进行处理的话,消费者进程可能会在保存其位置之后,还没有保存消息处理的输出之前发生崩溃。而在这种情况下,即使在此位置之前的一些消息没有被处理,接管处理的进程将从保存的位置开始。这种情况下,对应于“at-most-once”的语义,可能会有消息得不到处理。如果 Consumer 先读取消息,然后处理消息,最后再保存它的位置。在这种情况下,消费者进程可能会在处理了消息之后,但还没有保存位置之前发生崩溃。而在这种情况下,当新的进程接管后,它最初收到的一部分消息都已经被处理过了。这种情况下,对应于“at-least-once”的语义。
那么对于 exactly once ,Kafka本身是不能保证的,需要借助其他办法实现。
Leader 选举
如果 leader 挂了,就需要从 follower 中选举出一个新的 leader。 但是 followers 自身也有可能落后或者挂掉,所以我们必须确保 leader 的候选者们是一个数据同步最新的 follower 节点。 Kafka 恰恰维护了这样一个候选者列表 ISR。一条消息必须被 ISR 中所有的节点读取并追加到日志中了,这条消息才能视为提交。这个 ISR 集合发生的变化会在 ZooKeeper 中持久化,正因为如此,如果某个分区的 Leader 挂了,Kafka 会从 ISR 列表中选出一个作为新的 Leader。
显然通过 ISR 列表选 Leader 所需的冗余度较低,可以容忍的失败数比较高。而对于常见的“少数服从多数”方法来说,需要较高的冗余度。例如,假设现在有5个 Broker(包含1个 Leader 和4个 Follower),那在 commit 之前必须保证有3个 Replica 都复制完了消息才行,因为如果 Leader 挂了,采用“少数服从多数”方法,Leader 一定是从最新的副本中被选出的,因此至少要有3个最新的副本存在才行,也就是说,此时我们能容忍1个 Follower 延迟较高或者挂掉。同理,如果我们要容忍两个 Follower ,那么就需要5个保持同步的 Replica 才行。
Kafka 的 Leader选举基于 Controller 和 Watcher 机制,Controller 的主要作用是在 ZooKeeper 的帮助下管理和协调整个 Kafka 集群,集群中的每个 broker 都可以称为 controller,但是在 Kafka 集群启动后,只有一个 broker 会成为 Controller 。
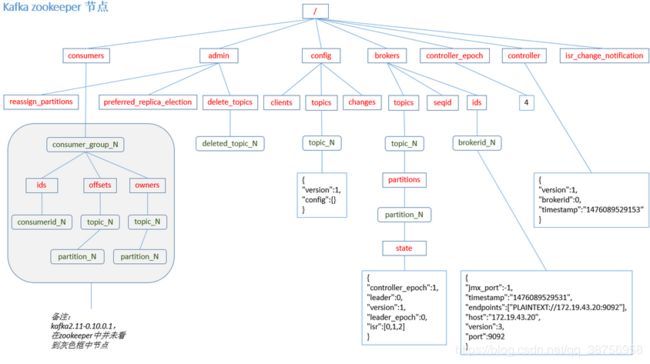
ZooKeeper 的数据是保存在节点上的,每个节点也被称为 znode,znode 节点是一种树形的文件结构,它很像 Linux 操作系统的文件路径,ZooKeeper 的根节点是 /。znode 根据数据的持久化方式可分为临时节点和持久性节点。持久性节点不会因为 ZooKeeper 状态的变化而消失,但是临时节点会随着 ZooKeeper 的重启而自动消失。znode 节点有一个 Watcher 机制:当数据发生变化的时候, ZooKeeper 会产生一个 Watcher 事件,并且会发送到客户端。Watcher 监听机制是 Zookeeper 中非常重要的特性,我们基于 Zookeeper 上创建的节点,可以对这些节点绑定监听事件,比如可以监听节点数据变更、节点删除、子节点状态变更等事件,通过这个事件机制,可以基于 ZooKeeper 实现分布式锁、集群管理等功能。下图为 znode 节点图,详细的说明了 Zookeeper 是如何保存集群信息的,在之前提到生产者发送消息的第一步就是先向 Zookeeper 获取 Leader ,其实就是从/brokers/topic/state 下找到的。
Kafka 当前选举控制器的规则是:Kafka 集群中第一个启动的 broker 通过在 ZooKeeper 里创建一个临时节点 /controller 让自己成为 controller 控制器。其他 broker 在启动时也会尝试创建这个节点,但是由于这个节点已存在,所以后面想要创建 /controller 节点时就会收到一个 节点已存在 的异常。然后其他 broker 会在这个控制器上注册一个 ZooKeeper 的 watch 对象,/controller 节点发生变化时,其他 broker 就会收到节点变更通知。这种方式可以确保只有一个控制器存在。
当控制器发现一个 broker 离开集群(通过观察相关 ZooKeeper 路径),控制器会收到消息:这个 broker 所管理的那些分区需要一个新的 Leader。控制器会依次遍历每个分区,确定谁能够作为新的 Leader,然后将 Leader 的改变直接通过RPC的方式通知需为为此作为响应的 Broker。随后,新的 Leader 开始处理来自生产者和消费者的请求,Follower 用于从新的 Leader 那里进行复制。controller会同时controller也负责增删Topic以及Replica的重新分配。
如果 ISR 节点全挂了?
在上面的选举中有一个前提,那就是:ISR 列表中的 Follower 不能全都挂,至少要有一个存活。假设一旦所有的备份都挂了,怎么去保证数据不会丢失,这里有两种实现的方法
- 等待一个 ISR 的副本重新恢复正常服务,并选择这个副本作为领 leader (它有极大可能拥有全部数据)。
- 选择第一个重新恢复正常服务的副本(不一定是 ISR 中的)作为leader。
这是可用性和一致性之间的简单妥协,如果我只等待 ISR 的备份节点,那么只要 ISR 备份节点都挂了,我们的服务将一直会不可用,如果它们的数据损坏了或者丢失了,那这个 Partition 将永远不可用。另一方面,如果不是 ISR 中的节点恢复服务并且我们允许它成为 leader , 那么即使它不能保证记录了每一个已经提交的消息,在这种策略下也将它的数据作为可信的来源。 kafka 默认选择第二种策略,当所有的 ISR 副本都挂掉时,会选择一个可能不同步的备份作为 leader ,可以配置属性 unclean.leader.election.enable 禁用此策略。
四、安装 Kafka
接下来介绍单机安装 Kafka ,本文以 kafka_2.13-2.4.1 为例。
-
到 kafka 官方网站 下载包。
-
将下载好的 tgz 包上传到服务器中。
[aspire@localhost mms]$ ll -rw-r--r-- 1 aspire aspire 62127579 3月 27 11:36 kafka_2.13-2.4.1.tgz -
将 tgz 包进行解压,注意这个包已经编译好,所以解压即可使用。
[aspire@BJ-FT-VM-136-59 mms]$ tar -xzvf kafka_2.13-2.4.1.tgz [aspire@BJ-FT-VM-136-59 mms]$ ll drwxr-xr-x 6 aspire aspire 83 3月 3 08:35 kafka_2.13-2.4.1 -rw-r--r-- 1 aspire aspire 62127579 3月 27 11:36 kafka_2.13-2.4.1.tgz -
以后台方式启动 zookeeper
[aspire@localhost kafka_2.13-2.4.1]$ ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties -
以后台方式启动 kafka
[aspire@localhost kafka_2.13-2.4.1]$ ./bin/kafka-server-start.sh -daemon ./config/server.properties
kafka 的配置在 /config/server.properties 文件中,zookeeper 的配置文件为 /config/zookeeper.properties 。有关 Kafka 的配置,请参考 Kafka中文文档
五、Kafka 基本操作
所有在本节中看到的 Kafka 操作脚本都在 bin 目录下,接下来介绍一下 Kafka 的基本操作。
启动 Kafka
kafka-server-start.sh,执行该脚本时必须指定启动时的配置文件。为该脚本添加 -daemon 参数将 Kafka 以后台方式启动。如果你使用的是独立的 zookeeper ,那么应该先启动 zookeeper ,这里我使用的是内置的,因此可以直接启动 kafka。
# 这种方式启动,ctrl + c 后即退出kafka
$ ./bin/kafka-server-start.sh ./config/server.properties
# 以后台方式启动
$ ./bin/kafka-server-start.sh -daemon ./config/server.properties
启动脚本的完整内容如下:
if [ $# -lt 1 ];
then
echo "USAGE: $0 [-daemon] server.properties [--override property=value]*"
exit 1
fi
base_dir=$(dirname $0)
if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then
export KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/log4j.properties"
fi
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
EXTRA_ARGS=${EXTRA_ARGS-'-name kafkaServer -loggc'}
COMMAND=$1
case $COMMAND in
-daemon)
EXTRA_ARGS="-daemon "$EXTRA_ARGS
shift
;;
*)
;;
esac
exec $base_dir/kafka-run-class.sh $EXTRA_ARGS kafka.Kafka "$@"
可以看到,启动脚本中指定了 Kafka 的堆内存大小,默认为 1G ,这可能导致启动时因为Java HotSpot 内存不足而报错。你可以根据实际情况修改启动脚本中的内容。
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M"
fi
输入命令 jps 可以看到 kafka 已经启动。
[aspire@BJ-HW-VM-17-150 kafka_2.13-2.4.1]$ jps
18324 Jps
13996 Kafka
优雅的停止
kafka-server-stop.sh ,Kafka 支持更优雅的停止服务器的机制,而不仅仅是杀死它。当一个服务器正常停止时,它将采取两种优化措施:
- 它将所有日志同步到磁盘,以避免在重新启动时需要进行任何日志恢复活动(即验证日志尾部的所有消息的校验和)。由于日志恢复需要时间,所以从侧面加速了重新启动操作。
- 它将在关闭之前将以该服务器为 leader 的任何分区迁移到其他副本。这将使 leader 角色传递更快,并将每个分区不可用的时间缩短到几毫秒。
只要服务器的停止不是通过直接杀死,同步日志就会自动发生,但控制 leader 迁移需要使用特殊的设置:controlled.shutdown.enable=true,而该配置默认值为 true。
$ ./bin/kafka-server-stop.sh
topic 相关操作
kafka-topics.sh 脚本用于操作 topic ,可以新增,修改和删除 topic 。需要注意的是,这个脚本执行需要指定 --zookeeper 参数。
创建 topic
创建 topic 的同时必须指定一些 topic 的相关属性。例如:
$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my_topic --partitions 20 --replication-factor 1
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic my_topic.
--topic 参数指定 topic 名称,--partitions 参数指定 topic 有多少分区。--replication-factor 参数指定复制因子,即有多少服务器将复制写入的消息,需要注意的是,复制因子的数量不能超过 brokers 的数量。例如本人实验的 kafka 是单台,于是不能创建复制因子为3的 topic ,否则会报错如下:
$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my_topic --partitions 1 --replication-factor 3
Error while executing topic command : Replication factor: 3 larger than available brokers: 1.
[2020-04-10 11:35:19,361] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 3 larger than available brokers: 1.
在创建 topic 时,会有一个警告信息,如上例所示。Kafka 在创建 topic 时会检测 . 和 _ 两个字符,并且会将句点号 . 改成下划线 _ 。假设一个 topic 的名称为 “topic.1_2”,还有一个 topic 的名称为“topic_1.2”,那么最后的名称都为“topic_1_2”,就会发生名称冲突。如下所示:
$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic my.topic --partitions 1 --replication-factor 1
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Error while executing topic command : Topic 'my.topic' collides with existing topics: my_topic
[2020-04-10 11:30:37,334] ERROR org.apache.kafka.common.errors.InvalidTopicException: Topic 'my.topic' collides with existing topics: my_topic
查看 topic 列表
$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --list
__consumer_offsets
my_topic
test
查看指定的 topic 属性信息,使用 --discribe 参数。
$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --topic my_topic --describe
Topic: my_topic PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: my_topic Partition: 0 Leader: 0 Replicas: 0 Isr: 0
修改 topic 属性
使用 --alter 参数修改 topic ,例如下面扩大分区,需要注意,添加分区不会更改现有数据的分区。
$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic my_topic --partitions 20
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Adding partitions succeeded!
分区扩容会有一个警告:当 topic 中的消息包含有key时(即key不为null),根据key来计算分区的行为就会有所影响。例如原来 my_topic 的分区数为1时,不管消息的key为何值,消息都会发往这一个分区中。但当分区数增加到20时,那么就会根据消息的 key 来重新计算分区号,原本发往分区 0 的消息现在有可能会发往别的分区中,如此还会影响既定消息的顺序,所以在增加分区数时一定要三思而后行。对于基于 key 计算分区的 topic 而言,建议在一开始就设置好分区数量,避免以后对其进行调整。
另外一方面,Kafka 的分区数量只允许扩充而不允许减少,例如现在重新设置分区数量为1则报错:
$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --alter --topic my_topic --partitions 1
WARNING: If partitions are increased for a topic that has a key, the partition logic or ordering of the messages will be affected
Error while executing topic command : The number of partitions for a topic can only be increased. Topic lx_topic currently has 20 partitions, 1 would not be an increase.
[2020-04-10 11:53:08,257] ERROR org.apache.kafka.common.errors.InvalidPartitionsException: The number of partitions for a topic can only be increased. Topic lx_topic currently has 20 partitions, 1 would not be an increase.
(kafka.admin.TopicCommand$)
按照Kafka现有的代码逻辑而言,此功能完全可以实现,不过也会使得代码的复杂度急剧增大。实现此功能需要考虑的因素很多,比如删除掉的分区中的消息该作何处理?如果随着分区一起消失则消息的可靠性得不到保障;如果需要保留则又需要考虑如何保留。直接存储到现有分区的尾部,消息的时间戳就不会递增,如此对于Spark、Flink这类需要消息时间戳(事件时间)的组件将会受到影响;如果分散插入到现有的分区中,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间,此主题的可用性又如何得到保障?与此同时,顺序性问题、事务性问题、以及分区和副本的状态机切换问题都是不得不面对的。反观这个功能的收益点却是很低,如果真的需要实现此类的功能,完全可以重新创建一个分区数较小的主题,然后将现有主题中的消息按照既定的逻辑复制过去即可。
虽然分区数不可以减少,但是分区对应的副本数是可以减少的,这个其实很好理解,你关闭一个副本时就相当于副本数减少了。不过正规的做法是使用kafka-reassign-partition.sh脚本来实现,具体用法可以自行搜索。
————————————————
版权声明:本文为CSDN博主「RedeLego」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u011078141/article/details/89204319
删除 topic
$ ./bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic my_topic
Topic my_topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
Kafka 删除 topic 的过程实际上是异步的:命令行仅仅是提交一个删除申请给到 controller,并标记该topic 为“删除”状态。如果 delete.topic.enable 的值为 true,那么才会进行删除。由于功能稳定,所以默认启动删除 topic 功能。如果该配置为 false ,那么这个 topic 只是被标记为"deletion",此时再创建同名 topic 时则会提示已存在。
修改配置
如果想保留 topic,只删除 topic 现有数据。可以通过修改数据保留时间实现,对此,我们可以对 topic 增加一个配置为保存消息的时间,对配置的修改使用 kafka-configs.sh
以下配置,修改保留时间为10秒,但不是修改后10秒就马上删掉,kafka 是采用轮训的方式,轮训到这个 topic 发现是10秒前的数据就删掉。
$ ./bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my_topic --alter --add-config retention.ms=10000
该配置与 server.properties 中的 log.retention.check.interval.ms 意义相同,kafka 的默认配置为300秒。需要注意,使用这种方法新增或修改的配置优先级比全局配置 server.properties 中的优先级高。如果想删除一个配置项,如下所示:
$ ./bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my_topic --alter --delete-config retention.ms
查看 topic 的配置信息。
$ ./bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name my_topic --describe
生产者相关操作
使用脚本 kafka-console-producer.sh 进行生产者相关操作。
如下所示,使用 topic “my_topic” 生产消息,broker-list 和 topic 参数均为必传。该命令执行后所输入的内容即为消息的内容。
$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my_topic
> hello world
> this is a message
如果你输入该命令后的返回结果类似于 "WARN Error while fetching metadata with correlation id",那么需要在 server.properties 中加入以下配置:
port = 9092
advertised.host.name = localhost
还可以指定消息的 key 值,如下所示:
$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my_topic --property parse.key=true
> 1 123
> 2 heloworld
key 与消息之间的分隔符,默认为制表符,如果希望修改分隔符,通过 key.separator 指定。
$ ./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my_topic --property parse.key=true --property key.separator=':'
消费者相关操作
查看所有消费者组,使用 kafka-consumer-groups.sh 。需要注意的是,新版本中将使用参数 bootstrap-server,而不是老版本中的 --zookeeper。示例所用 Kafka 版本在本文开始时已经声明。
$ ./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
foo
console-consumer-91397
myGroup
查看指定消费者组的信息。
$ ./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group foo
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
foo test 0 11 11 0 consumer-2-087e22de-1aaf-42f4-9585-c4937101c6a0 /10.2.75.102 consumer-2
删除消费者组,但是如果该消费者组是通过命令创建消费者时自动创建的,使用 ctrl + c 退出消费者后,该消费者所在的组会自动删除。
./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group foo --delete
Deletion of requested consumer groups ('foo') was successful.
启动消费者进行消费,使用 kafka-console-consumer.sh , from-beginning 参数可以显示在这之前生产的消息,未指定消费者组时,Kafka 会自动创建一个新的组,例如下面创建的消费者所在组名为:console-consumer-91397。
$ ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
hello world
六、Kafka 在 zookeeper中的存储
在前文中提到过,ZooKeeper 的数据是保存在节点上的,每个节点也被称为 znode,znode 节点是一种树形的文件结构。接下来详细介绍这一点。

要查看 zookeeper 上存储的信息首先要连接到 zookeeper 上。Kafka 内置的 zookeeper 在 bin 目录中提供了一个 zookeeper-shell.sh 工具。如下所示,连接到 zookeeper 上。
[aspire@localhost bin]$ ./zookeeper-shell.sh localhost:2181
Connecting to localhost:2181
Welcome to ZooKeeper!
JLine support is disabled
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
在 zookeeper 中,最主要的是 ls 和 get 两个命令,ls 命令查看制定路径下的节点,如下所示查看根目录下所有节点。该命令添加 -s 参数,显示属性信息,注意老版本中是 ls2 命令,虽然仍可使用但是已被明确指出已过时。 get 命令获取存储的内容。
Broker 注册信息
ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
ls /brokers
[ids, seqid, topics]
ls /brokers/ids
[0]
get /brokers/ids/0
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://10.8.17.150:9092"],"jmx_port":-1,"port":9092,"host":"10.8.17.150","version":4,"timestamp":"1586487988209"}
topic 注册信息
ls /brokers/topics
[__consumer_offsets, test, zmms-error]
ls2 /brokers/topics
'ls2' has been deprecated. Please use 'ls [-s] path' instead.
ls -s /brokers/topics
[__consumer_offsets, test, zmms-error]cZxid = 0x6
ctime = Fri Mar 27 11:37:37 CST 2020
mZxid = 0x6
mtime = Fri Mar 27 11:37:37 CST 2020
pZxid = 0xb9
cversion = 3
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 3
get /brokers/topics/test
{"version":2,"partitions":{"0":[0]},"adding_replicas":{},"removing_replicas":{}}
partitions 中的 key 指的是 partitionId ,value 是一个 brokerIds 数组,指的是该 partition 在哪些 broker 中存在。如下所示,partitionId 为1的这个分区存在于 brokerId 为0,1,2的 broker 上,其分布情况可以参考本文第二章最后的 Kafka 拓扑结构图。
"partitions": {"1": [0, 1, 2],"0": [1, 2, 0],}
partition 状态信息
ls /brokers/topics/test/partitions
[0]
get /brokers/topics/test/partitions/0/state
{"controller_epoch":1,"leader":0,"version":1,"leader_epoch":0,"isr":[0]}
# "controller_epoch": 表示kafka集群中的中央控制器选举次数,
# "leader": 表示该partition选举leader的brokerId,
# "version": 版本编号默认为1,
# "leader_epoch": 该partition leader选举次数,
# "isr": [同步副本组brokerId列表]
Controller 相关信息
get /controller_epoch
8
# 此值为一个数字,kafka集群中第一个broker第一次启动时为1,每次controller重新选举导致变更,该值就会 + 1;
get /controller
{"version":1,"brokerid":0,"timestamp":"1586487989709"}
七、Springboot 整合 Kafka
以下实例都基于 springboot-2.1.9 版本。
-
添加依赖,如果使用 springboot 整合 Kafka ,则无需特别指定 version ,springboot 将自动的配置一个与你 springboot 版本兼容的包。
<dependency> <groupId>org.springframework.kafkagroupId> <artifactId>spring-kafkaartifactId> dependency> -
Kafka 配置使用
spring.kafka.*的外部配置来进行属性控制。例如,您可以在application.properties中声明以下部分,通过之前的学习相信你一定能理解为什么需要第二行的配置。spring.kafka.bootstrap-servers=localhost:9092 spring.kafka.consumer.group-id=myGroup -
发送消息,springboot 的 KafkaTemplate 是自动配置的,您可以直接在自己的 bean 中装配它,如下所示,send 方法第一个参数指定 Topic ,第二个参数是值。
@Service public class KafkaService { @Autowired private KafkaTemplate<String, String> template; public void send(){ template.send("test", "hello world"); } } -
读取消息,使用
@KafkaListener注解到任何 bean 上以创监听器端点。@Service public class KafkaService { @KafkaListener(topics = "test") public void listen(ConsumerRecord<?, ?> cr) throws Exception { System.out.println(cr.value()); } }
你或许会遇到 java.io.IOException: Can't resolve address: VM_0_15_centos:9092 这种错误,在这里说明一下 Kafka 的连接过程。首先,根据配置的 IP 地址获取 hostname,然后根据返回的 hostname 连接到 Kafka 上。你可以选择修改本地的 hosts 文件将 hostname 与 IP 进行配对。当然你也可以选择修改 Kafka 中 server.properties 文件配置对外暴露的地址,文件注释中有详细的说明。
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://10.8.17.150:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
advertised.listeners=PLAINTEXT://10.8.17.150:9092
参考资料
[1] 知乎:消息队列(mq)是什么?
[2] Kafka学习之路
[3] Kafka中文文档
[4] Kafka中的HW、LEO、LSO等分别代表什么?
[5] 你能说出 Kafka 这些原理吗?
[6] spring-kafka 官方文档
[7] springboot 中文文档
[8] How to Install Apache Kafka on CentOS 7