08-Mysql 排序优化
在使用order by时,经常出现Using filesort
索引做为排序时,只用到name和age,salary是作为排序,而不是查找

使用order by排序时, 如果没有按照索引顺序,会出现Using filesort


当使用*时order by即使使用了 全部索引,也会也filesort

当索引字段为常量时 可以当作是存在索引的

使用排序一升一降会造成filesort

使用group by时,出现Using temporary

解决办法和排序一样, 都要按索引顺序进行分组
使用索引的情况
假设建立复合索引(a,b,c),请说出以下条件是否使用到了索引及使用情况
where a = 4 使用到了索引a
where a = 4 and b = 6; 使用到索引a,b
where a = 4 and c = 5 and b = 6 ; 使用到了a,b,c
where a = 4 or b=5; 没有使用到索引
where a = 4 and c = 6; 使用到了索引a
where a = 4 and b > 5 and c=6; 使用到索引a,b
where a = 4 and b like 'test%' and c=4 使用到了a,b kk%相当于范围
where a = 4 order by b,c 使用到了a,不会有filesort
where b = 5 order by a 没用到索引 会有filesort
where b = 5 order by c 没有索引,会有filesort
where a = 5 group by c,b 使用到了索引a, 造成Using temporary;
大批量数据时分页操作如何优化
建立表
DROP TABLE IF EXISTS `testemployee`;
CREATE TABLE `testemployee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`dep_id` int(11) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`salary` decimal(10,2) DEFAULT NULL,
`cus_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=109 DEFAULT CHARSET=utf8;
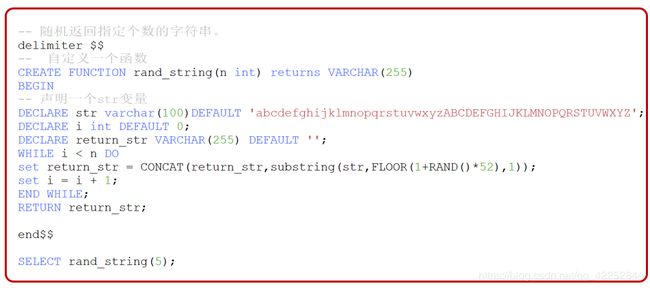
随机生成字符串
#随机生成一个指定个数的字符串
delimiter $$
create function rand_str(n int) RETURNS VARCHAR(255)
BEGIN
#声明一个str 包含52个字母
DECLARE str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';
#记录当前是第几个
DECLARE i int DEFAULT 0;
#生成的结果
DECLARE res_str varchar(255) default '';
while i < n do
set res_str = CONCAT(res_str,substr(str,floor(1+RAND()*52),1));
set i = i + 1;
end while;
RETURN res_str;
end $$
delimiter ;
set global log_bin_trust_function_creators=TRUE;
批量插入数据
delimiter $$
create procedure insert_emp(in max_num int)
BEGIN
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into testemployee (name,dep_id,age,salary,cus_id) values(rand_str(5),floor(1 + rand()*10),floor(20 + rand()*10),floor(2000 + rand()*10),floor(1 + rand()*10));
until i = max_num
end REPEAT;
commit;
end $$
delimiter ;
分页查询:使用limit 随着offset增大, 查询的速度会越来越慢, 因为会把前面的数据都取出,找到对应位置.
优化后分页查询
1、使用子查询优化
select * from employ e inner join (SELECT id from employ limit 500000 ,10 ) et on e.id = et.id;
select * from employee where id >=(SELECT id from employee limit 500000 , 1) limit 10;
2、使用 id 限定优化(记录上一页最大的id号 使用范围查询,只能使用于明确知道id的情况)
select * from employee where id between 1000000 and 1000100 limit 100;
select * from orders_history where id >= 1000001 limit 100;