Tianchi Data Hero Cup —— 短租数据集分析
数据listings:
id 房源ID
name 房源标题
host_id 主人id
host_name
heighbourhood_group 行政区ID
heighbourhood 行政区
latitude 维度
kongitude 经度
room_type 出租类型(entire home 或者 private room)
price 价格
minimum_nights 最少天数
number_of_reviews 评论数量
last_review 最近的评论时间
reviews_per_month 每月评论数量
calculated_host_listings_count 主人拥有的房子数量
availability_365
分析一:探索性分析
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
pd.set_option('display.max_columns', None)
df = pd.read_csv('listings.csv', index_col=0) # 加载数据,使用第一列为默认索引
print(df.info())
# 描述信息
des_group = ['price', 'number_of_reviews', 'reviews_per_month', 'availability_365']
print(df.describe()[des_group])
# 数据清洗之查看空值信息
print(df.isnull().sum())
# 填充review数量为空的数值填充为均值
df.number_of_reviews.fillna(df.number_of_reviews.mean(), inplace=True)
print(df.isnull().sum())
# 创建子数据集
subsets = ['price', 'minimum_nights', 'number_of_reviews', 'reviews_per_month',
'calculated_host_listings_count', 'availability_365']
# 箱型图,获取数据大致分布情况,查看离群点信息
# 下面这个图好像很难得到有价值的信息,具体的应该缩小范围进一步查看
fig, axes = plt.subplots(len(subsets), 1)
plt.subplots_adjust(hspace=1)
for i, subset in enumerate(subsets):
sns.boxplot(df[subset], ax=axes[i], whis=2, orient='h')
plt.show()
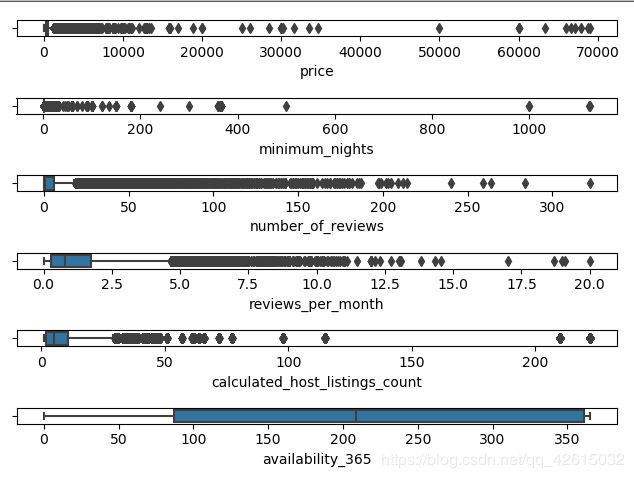
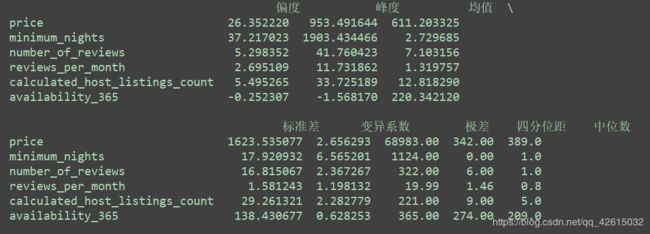
# 探索性数据分析,数据集中性
def get_con(df):
subsets = ['price', 'minimum_nights', 'number_of_reviews',
'reviews_per_month', 'calculated_host_listings_count', 'availability_365']
data = {}
for i in subsets:
data.setdefault(i, [])
data[i].append(df[i].skew())
data[i].append(df[i].kurt())
data[i].append(df[i].mean())
data[i].append(df[i].std())
data[i].append(df[i].std()/df[i].mean())
data[i].append(df[i].max()-df[i].min())
data[i].append(df[i].quantile(0.75)-df[i].quantile(0.25))
data[i].append(df[i].median())
data_df = pd.DataFrame(data, index=['偏度', '峰度', '均值', '标准差',
'变异系数', '极差', '四分位距', '中位数'], columns=subsets)
return data_df.T
df2 = get_con(df)
print(df2)
获取最新的房源消息
# 当评论数为0时,最近评论时间是null
review_data = df[~df['last_review'].isnull()]
print(review_data.isnull().sum())
# 获取各listing上条评论距今的天数
review_data['last_review_to_date'] = pd.datetime.today() - pd.to_datetime(review_data.last_review)
def get_last_review_top10(data): # 获取各区上最新的十条评论
result = []
groups = data.groupby('neighbourhood')
for x, group in groups:
result.append(group.sort_values(by='last_review_to_date')[:10])
result = pd.concat(result)
return result
last_review_top10_by_neighbourhood = get_last_review_top10(review_data)
print(last_review_top10_by_neighbourhood.head())
# 绘制饼图,查看listing分布情况
# 之后我们得到结论:listing分布方面,朝阳,海淀,东城区占比超过60%,其他各区有待开发
lis_dis = df.neighbourhood.value_counts()
labels = lis_dis.index # 注意获取label的问题
plt.rcParams['font.sans-serif'] = 'SimHei' # 这里解决了中文显示的问题
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 8))
plt.title('各区Listing分布占比')
plt.pie(lis_dis, labels=labels, autopct='%.2f%%', explode=[0.1 if i in ['东城区', '朝阳区 / Chaoyang', '海淀区']
else 0 for i in labels])
plt.legend(loc='best', fontsize=8)
plt.show()

plt.figure()
sns.heatmap(df.corr(), vmin=-1, vmax=1, cmap=sns.color_palette('hls', n_colors=8))
plt.title('Correlation among features')
plt.show()
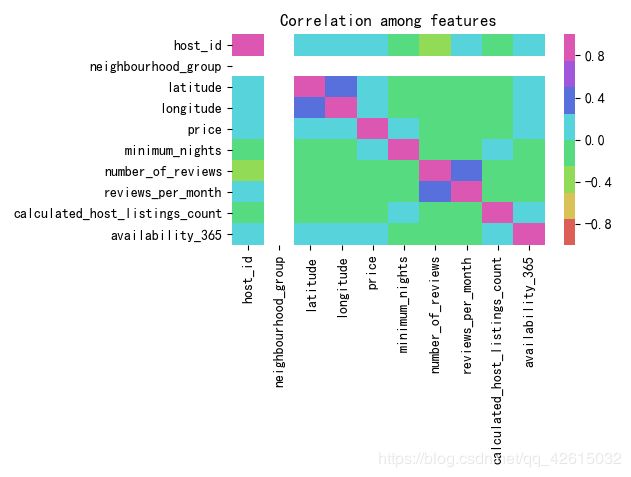
通过某个feature排序,得到top/bottom房源:
# 注意下面这个函数中,concat的方式:把列表内的dataframe组合
feature = ['names', 'minimum_nights', 'price', 'room_type']
label = ['number_of_reviews']
def get_review_tb(data, num): # 获取各区评论数量top/bottom的数量,根据参数
'''获取各区评论数量top/bottom的数量,根据num参数,num为正表示top,为负数表示bottom'''
result = []
groups = data.groupby('neighbourhood')
for x, group in groups:
if num > 0:
result.append(group.sort_values(by='number_of_reviews', ascending=False)[:num])
if num < 0:
result.append(group.sort_values(by='number_of_reviews', ascending=False)[num:])
result = pd.concat(result)
return result
reviews_top10 = get_review_tb(df,10) # 获取各区评论数top10的listing信息
reviews_bottom10 = get_review_tb(df, -10) # 获取各区评论数bottom10的listing信息
这里介绍一个好玩的库:jieba,但是因为缺少数据 没有实际操作
import jieba
def get_words(data): # 利用jieba对房屋名称进行拆词分析,获取高频词汇
s = []
wordsdic = {}
with open('datalab/28951/stopwords.txt', encoding='utf8') as f: # 根据停用词过滤词汇
result = f.read().split()
for i in data:
words = jieba.lcut(i)
word = [x for x in words if x not in result]
s.extend(word)
for word in s:
wordsdic.setdefault(word, 0)
wordsdic[word] += 1
return wordsdic
top_words = get_words(reviews_top10.name.astype('str'))
bottom_words = get_words(reviews_bottom10.name.astype('str'))
top_words_df = pd.Series(top_words).sort_values(ascending=False)[1:21]
bottom_words_df = pd.Series(bottom_words).sort_values(ascending=False)[1:21] # 从1开始是为了过滤空值
print(bottom_words_df.head())
plt.figure(figsize=(10, 5))
plt.title('评论较少listing,name中数量较多的词汇分布')
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
top_words_df.plot(kind='bar', ylim=[0, 400])
plt.figure(figsize=(10, 5))
plt.title('评论较少listing,name中数量较多的词汇分布')
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
bottom_words_df.plot(kind='bar', ylim=[0, 400])
得到结论:
发现描述上面,无论是评论数多的还是评论数少的,
大部分词汇集中在地铁,温馨,北京等一类词汇,评论数与房屋描述相关行不大,
或者房子获得的评论数多少与房屋挂牌时间相关,从描述词汇上面看,没有太多的相关性
# 各区listing价格,评论数平均值对比,分区,房屋类型
pd.options.display.precision = 2
plt.figure()
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
feature_df = pd.pivot_table(df, index='neighbourhood', values=['price', 'number_of_reviews'],
columns='room_type', aggfunc=np.mean)
sns.heatmap(feature_df.price, cmap=sns.color_palette('RdBu_r', n_colors=32), annot=True)
plt.show()
# 通过对比发现,Entire home/apt 类型,密云,平谷,延庆,怀柔,昌平价格较高,
# Shared room中,延庆,怀柔,放上,昌平价格较高

这里介绍一种ML数据传化方法:
from sklearn.preprocessing import LabelEncoder
df['neighbourhood_digit'] = LabelEncoder().fit_transform(df.neighbourhood)
print(df[['neighbourhood', 'neighbourhood_digit']])
分析二:清洗小技巧
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 数据读入与清洗
listings_df = pd.read_csv("listings.csv", index_col=0)
listings_df.drop("neighbourhood_group", axis=1, inplace=True)
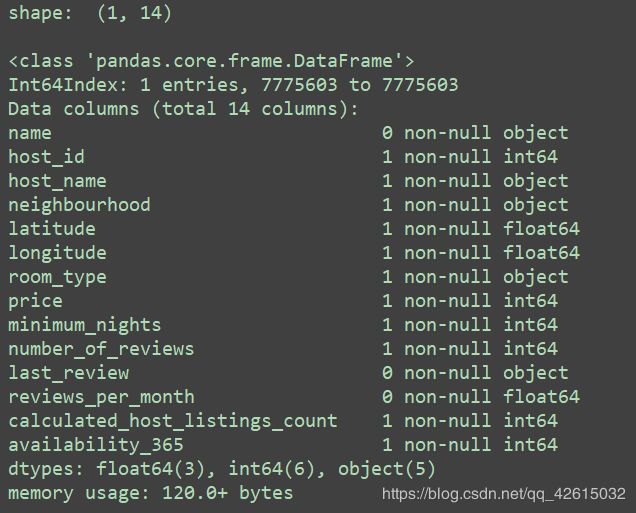
listings_df = listings_df[listings_df["name"].isnull()]
print("shape: ", listings_df.shape, "\n")
listings_df.info()
分析三:Airbnb房东职业化趋势分析
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv("listings.csv")
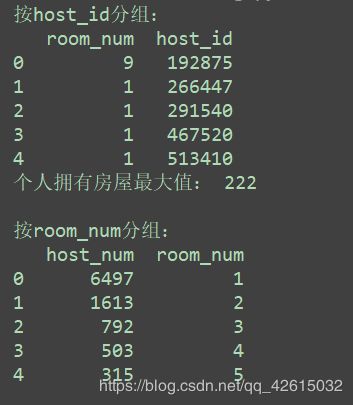
print('按host_id分组:')
ser = df.groupby(['host_id']).count()['id']
dfn = ser.to_frame() # 这个操作挺有意思
dfn['host_id'] = dfn.index # 增加新列
dfn.reset_index(drop=True, inplace=True)
dfn.rename(columns={"id": "room_num"}, inplace=True)
print(dfn.head())
print('个人拥有房屋最大值:', dfn.room_num.max(), '\n')
print('按room_num分组:')
ser1 = dfn.groupby(['room_num']).count()['host_id']
dfp = ser1.to_frame()
dfp['room_num'] = dfp.index
dfp.reset_index(drop=True, inplace=True)
dfp.rename(columns={"host_id": "host_num"}, inplace=True)
print(dfp.head())
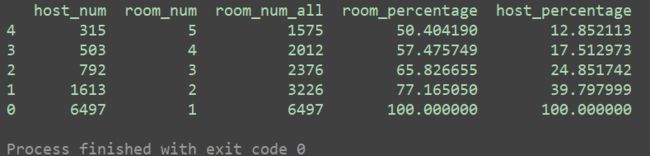
dfp = dfp.sort_values(by='room_num', ascending=False)
dfp['room_num_all'] = dfp['room_num']*dfp['host_num']
dfp["room_percentage"] = dfp["room_num_all"].cumsum()/dfp["room_num_all"].sum()*100
dfp["host_percentage"] = dfp["host_num"].cumsum()/dfp["host_num"].sum()*100
print(dfp.tail())
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['axes.unicode_minus'] = False
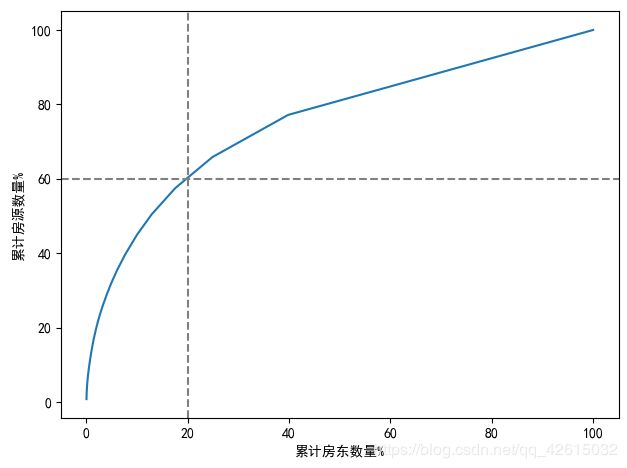
ax.plot(dfp.host_percentage, dfp.room_percentage)
ax.axhline(y=60, color='grey', linestyle='dashed')
ax.axvline(x=20, color='grey', linestyle='dashed')
plt.xlabel("累计房东数量%")
plt.ylabel("累计房源数量%")
plt.show()
通过下图我们可以清楚的看到:0.2的房主占有了0.6的房源
分析四:区域房价分析
import pandas as pd
import warnings
import re
warnings.filterwarnings('ignore')
data = pd.read_csv("listings.csv")
# 可以随机取出地区数据,以检验
# print(data['neighbourhood'].sample(10))
# 只取出neighbourhood中的汉字并且新建一个地区列,重点注意方法
res1 = []
for i in range(len(data)):
res1.append(''.join(re.findall('[\u4e00-\u9fa5]', data['neighbourhood'].iloc[i]))) # 通过Unicode判断中文字符
data['地区'] = res1
# 构造一个dataframe 并且将列明改为中文
data1 = data[['地区', 'price']]
data1.rename(columns={'price': '金额'}, inplace=True)
print(data1.head(10))
import matplotlib.pyplot as plt
import seaborn as sns
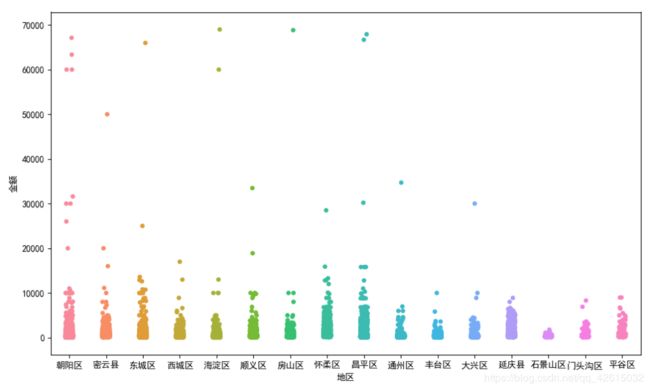
# 绘制 金额和地区散点图分析区域房价的分布情况
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
fig = plt.figure(figsize=(10, 6))
sns.stripplot(x='地区', y='金额', data=data1) # 绘制散点图
plt.show()

分析五:机器学习实战(后期补充)
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv("listings.csv", index_col=0)
data.drop("neighbourhood_group", axis=1, inplace=True)
# 对数据进行一个大致的了解
# data.head()
# data.shape
# data.dtypes
# data.describe()
# 封装函数,使neighbouhood特征列的数据只包含中文名(另一种方法)
def neighbourhood_str(data):
neighbourhoods = []
list = data["neighbourhood"].str.findall("\w+").tolist()
for i in list:
neighbourhoods.append(i[0])
return neighbourhoods
data["neighbourhood"] = neighbourhood_str(data)
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif'] = 'SimHei'
sns.set_style("whitegrid")
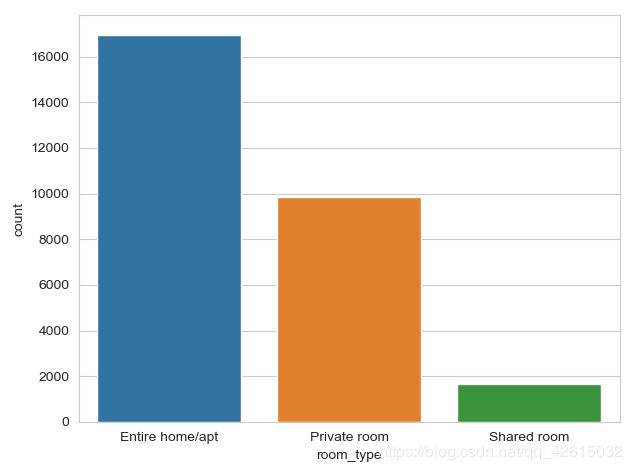
sns.countplot(x="room_type", data=data) # 绘制计数图
plt.show()
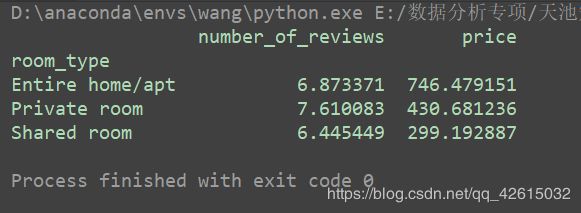
# 建立一个关于room_type的数据透视表
room = pd.pivot_table(data, index="room_type", values=["price", "number_of_reviews"])
print(room)
import seaborn as sns
price = data['price'][data.neighbourhood == '朝阳区']
sns.distplot(price[price < 3000], bins=100, color='k')
plt.show()
