解读Vue3.0的变更之路
第一块:Vue3.0 beta的六大亮点介绍
1:Performance:性能更比Vue 2.0强。
2:Tree shaking support:可以将无用模块“剪辑”,仅打包需要的。
3:Composition API:组合API相对于Vue2.x的option API
4:Fragment, Teleport, Suspense:“碎片”,Teleport即Protal传送门
5:Better TypeScript support:更优秀的Ts支持
6:Custom Renderer API:暴露了自定义渲染API
一:Performance

1:重写了虚拟Dom的实现(且保证了兼容性,脱离模版的渲染需求旺盛)。
2:编译模板的优化。
3:更高效的组件初始化。
4:update性能提高1.3~2倍。
5:SSR速度提高了2~3倍。
1:编译模板的优化
例子一:

根结点div将会被编译成Block
动态绑定msg属性的span,编译后_createVNode会生成PacthFlag(图中有标记),JS runtime在运行的时候,会知道div是一个block,只会对带有PacthFlag的结点进行真正的追踪,且无论层级嵌套多深,它的动态节点都直接与Block根节点绑定,无需再去遍历静态节点,在真正的更新的时候,会直接跳到该结点,比较该结点文字的变化。不需要去关注其他属性和绑定的变化。
再来一个例子:

这个时候我们会发现我们不仅仅有text类型的变化还有props属性的变更,
我们会发现Vue会根据text,props等不同的标记,这样再diff的时候,只需要对比text或者props,不用再做无畏的props遍历
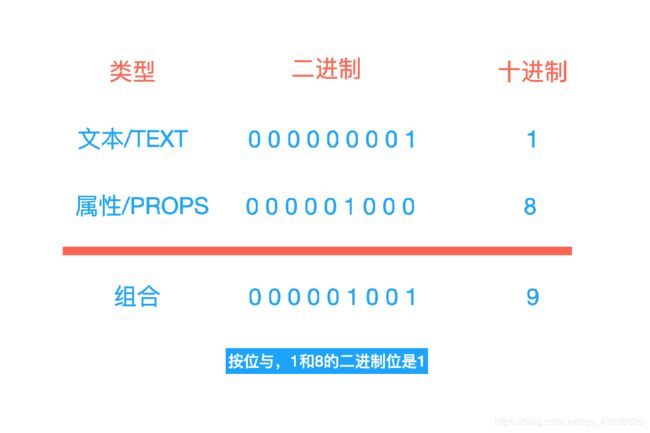
当然小伙伴可能都会有疑问,number–9从何而来,如下图:

我们会发现PatchFlags其实就是一个枚举的映射(位掩码),text是1,props是8,组合在一起就是9,我们可以简单的通过位运算来判定需要做text和props的判断,按位与即可,只要不是0就是需要比较
那什么是位掩码呢?
基本知识介绍
位运算是一种很好的运算思想,它的优点自然是计算快,代码更少。
二进制:
二进制是由1和0两个数字组成的,它可以表示两种状态,即开和关。所有输入电脑的任何信息最终都要转化为二进制。目前通用的是ASCII码。最基本的单位为bit。
位运算:
程序中的所有数在计算机内存中都是以二进制的形式储存的。位运算说穿了,就是直接对整数在内存中的二进制位进行操作。比如,and运算本来是一个逻辑运算符,但整数与整数之间也可以进行and运算。举个例子,6的二进制是110,11的二进制是1011,那么6 and 11的结果就是2,它是二进制对应位进行逻辑运算的结果(0表示False,1表示True,空位都当0处理)。
上一段代码看看:
/**
权限枚举
- 1: permission1,二进制第1位,0表示否,1表示是
- 2: permission2,二进制第2位,0表示否,1表示是
- 4: permission3,二进制第3位,0表示否,1表示是
- 8: permission4,二进制第4位,0表示否,1表示是
*/
typedef NS_OPTIONS(NSUInteger, OptionPermission) {
permission1 = 1 << 0,//0001,1
permission2 = 1 << 1,//0010,2
permission3 = 1 << 2,//0100,4
permission4 = 1 << 3,//1000,8
};
这个时候也就延伸出来了(如下图:)
所以说大家现在应该就知道为何我们的Number是9了吧,那我们总结一下上面分析的编译模板的优化:
总结:通过patchflag实现,patchflag有两个含义:1.用来表达当前节点需要更新,static节点没有这个参数,更新的时候跳过;2.需要更新情况组合,比如:1(只更新显示文本),8(只更新属性),9(更新显示文本和属性)。更新的时候只更新带patchflag的节点,无论节点层级有多深;不同的patchflag调用不同的更新函数,忽略检测其他需要对比和更新的内容。更新只关注变化的内容,也就是让更新更加具体,更加快。通过编译器编译时分析解决了virtual dom最耗性能的Diff算法。既有手写render function的灵活性,又有性能保证。
接下来我们继续看编译模板中的另一块:
优化一:cacheHandlers(事件侦听器缓存)
渲染模板工具地址:https://vue-next-template-explorer.netlify.app/
这个东西我们怎么理解呢?
因为运行时绑定的事件可能会发生改变,通过事件侦听器缓存可以解决事件侦听器中途发生改变,需要刷新节点的情况,特别是父组件传递给子组件的事件,刷新消耗会更大。
来个例子看看:
1:未开启cacheHandlers
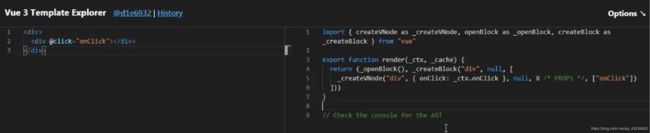
我们可以看到onClick是上下文的一个参数,而且onClick发生改变的时候会触发节点更新,onClick会被视为PROPS动态绑定,后续替换点击事件时需要进行更新。
2:开启cacheHandlers
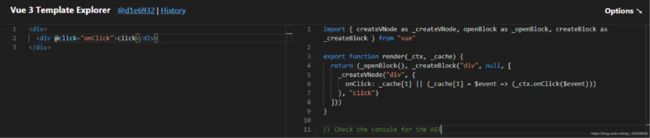
当然如果是手写的内联函数,比如说@click=”()=>onClick()”,vue3.0会将他默认缓存起来,React如果手写内联函数绑定事件,节点每次都会触发更新。当然React可以通过useMemo包裹来优化
总结:cache[1],会自动生成并缓存一个内联函数,“神奇”的变为一个静态节点。
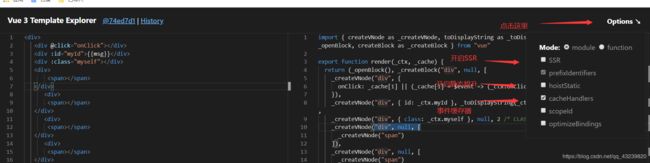
那可能会有小伙伴在打开编译模块地址找不到怎么开启cacheHandlers(下图有指引),这个工具也是非常的好用,同时我们通过这个工具也能看出Vue3.0很大的变化
优化二:静态节点提升
静态节点创建一次,终生使用,节省了对象创建销毁的性能。优化了运行时内存占用。特别是在大型网站上,优化效果更佳,因为大型网站会有大量静态节点。(同样我们可以在上面发布的编译模块链接中试试看~点击Option中的hoistStatic即可查看)

优化三:SSR(服务端渲染)

我们会发现上图,即使存在动态绑定,依然尽可能地做成字符串。,大量的静态节点,甚至是少量变化的节点都会会直接编译为一个字符串,push到一个buffer内部,整个模板只存在剩余动态的节点。对比React服务端基于Virtual Dom渲染出来的字符串会快得多得多。
性能对比图:
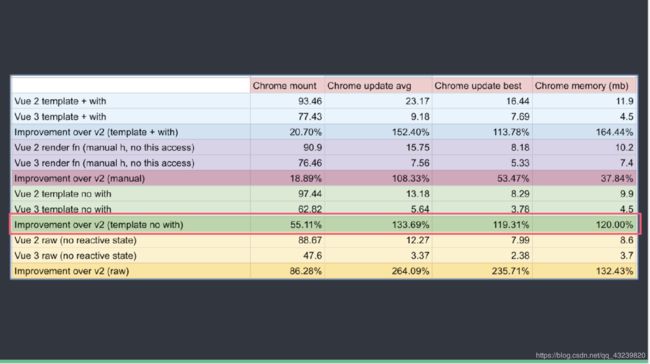
比React做成一个Virtual Dom 再去渲染出来,快上一个量级。服务端渲染的性能,完全不在一个层面上。
整体上,比Vue 2.x 内存占用少一半以上,总体速度快一倍以上。
二:Tree shaking support

1:可以将无用模块“剪辑”,仅打包需要的(比如v-model,,用不到就不会打包)。
2:一个简单“HelloWorld”大小仅为:13.5kb
而有了复合 API (Composition API)的支持,它的文件大小可以低至 11.75kb。
3:含了所有的运行时特性后,一个项目的大小可能只有 22.5 kb。
拥有更多的功能,却比Vue 2更迷你。
很多时候,我们并不需要 vue提供的所有功能,在 vue 2 并没有方式排除掉,但是 3.0 都可能做成了按需引入
三:Composition API
这个是什么意思呢,字面上可以理解为组合式API,它是以函数为载体,将业务相关的逻辑代码抽取到一起,整体打包对外提供相应能力,这就是 Composition API 可以理解它是我们组织代码,解决逻辑复用的一种方案。
Vue 团队引入了一种新的方法来组织代码,最初是在 2.x 版本我们使用了 options。Options 很好,但是在尝试匹配或访问 Vue 逻辑时它有编译器的缺点,还必须处理 JavaScript 的这个问题。因此,composition API 是处理这些问题的更好的解决方案,它还具有在 Vue 组件中使用和重用纯 JS 函数的自由和灵活性,使我们可以写更少的代码。composition API 是这样的:
我们可以想到这个不是和React Hooks越来越像了吗,我们往下看,我们结合一些例子来看看,直接上代码:
第一段逻辑是逻辑鼠标位置监听逻辑
function useMouse() {
const state = reactive({
x: 0,
y: 0
})
const update = e => {
state.x = e.pageX
state.y = e.pageY
}
onMounted(() => {
window.addEventListener('mousemove', update)
})
onUnmounted(() => {
window.removeEventListener('mousemove', update)
})
return toRefs(state)
}
我们还想组合另外一段逻辑 比如随时刷新的时间逻辑
function useOtherLogic() {
const state = reactive({
time: ''
})
onMounted(() => {
setInterval(() => {
state.time = new Date()
}, 1000)
})
return toRefs(state)
}
在实际的工作中我们可以认为这两个逻辑可能被很多组件复用,想想你要是用mixin和hoc你将多么无所是从。但是利用CompositionAPI,我们只需要把他组合并暴露 like this
const MyComponent = {
template: `x:{{ x }} y:{{ y }} z:{{ time }} `,
setup() {
const {
x,
y
} = useMouse()
// 与其它函数配合使用
const {
time
} = useOtherLogic()
return {
x,
y,
time
}
}
}
createApp().mount(MyComponent, '#app')
PS:真的是看到了React Hooks的影子了Em…
当然他还有很多很多的API:
const {
createApp,
reactive, // 创建响应式数据对象
ref, // 创建一个响应式的数据对象
toRefs, // 将响应式数据对象转换为单一响应式对象
isRef, // 判断某值是否是引用类型
computed, // 创建计算属性
watch, // 创建watch监听
// 生命周期钩子
onMounted,
onUpdated,
onUnmounted,
} = Vue
这个具体我们就不细讲了(PS:因为太多了Em… ,大家想看的话链接:点击这里)
大家看到这里可能会疑问,setup是个什么东西?(如下)
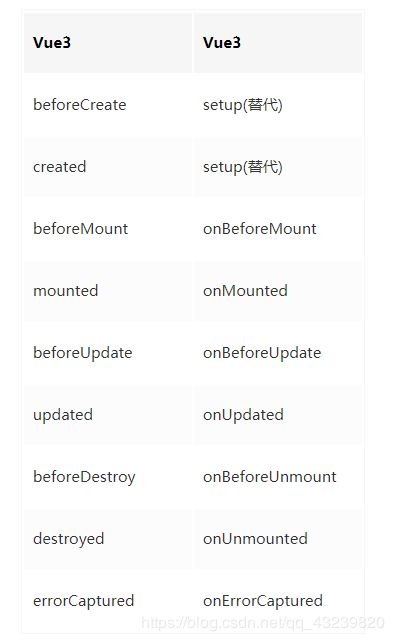
解释–setup功能是新的组件选项,它充当在组件内部使用Composition API(新特性)的入口点;创建组件实例时,在初始道具解析后立即调用。在生命周期方面,它在beforeCreate挂接之前被调用。
然后我们同时也可以看一下和Vue2.0的option API的对比
问题来源:在原来的Vue2.0的option书写方式—比方说之前的一个vue文件2000+js的代码。什么概念呢,就是光computed都是有好几十个,维护起来是非常恐怖的
当然:组件小的时候,用不同的Options比如methods、compute、data、props等这样分类比较清晰。大型组件中,大量的Options聚在一起。同一个组件可能有多个逻辑关注点,当使用Options API时,每一个关注点都有自己的Options,如下图每一个颜色代表不同的逻辑关注点之间的代码。当修改一个逻辑关注点时,就要在一个文件不断地切换和寻找,如果代码逻辑很复杂的,跳来跳去,那看的是真难受啊。
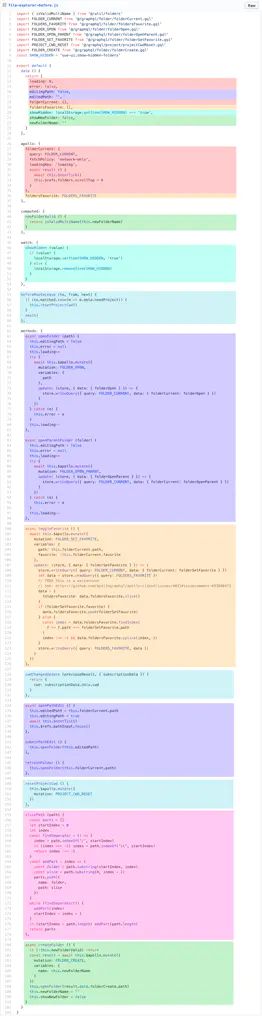
如要用切分这些逻辑点呢?有时候,不好切分,如果用minxin又会导致命名空间冲突。
但是Composition API给了一个很好的机制去解决这样的问题,所有某一个逻辑关注点(功能)相关的代码全都放在一个函数里,当需要去修改一个功能时,就不再需要在一个文件中跳来跳去。

当需要复用的时候,就只需要把这个函数提取出去。然后在另一个组件中引入,这个功能就变得可复用了,Composition API使得组件复用变得更加灵活了。
另一方面,Composition API会有更好的类型的支持,因为都是一些函数,在调用函数时,自然所有的类型就被推导出来了。不像OptionsAPI所有的东西使用this。同时,Composition API的可压缩性会更好一些。
看到这里,屏幕前的你难道真的就觉得这个Composition没有缺点了吗?
我认为在 Vue3.0 的 Composition API 中将来会避免不了出现 “面条代码” 这个问题。
何为“面条代码”?
面条代码:代码的控制结构复杂、混乱,逻辑不清,关系耦合,让人一时难以理解。
面条代码的形象例子:
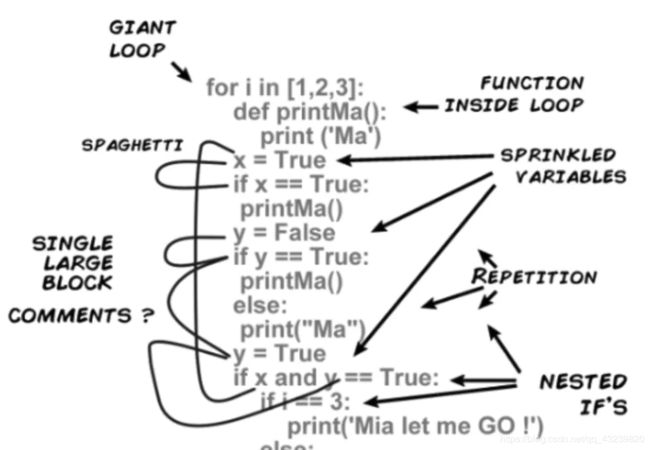
这图让人看了一脸懵逼,如同意大利面条一样,全部混在一起,一时难以确切找到调用出入口和代码之间的关系是如何的。
为啥会担忧出现“面条代码”?
Options API 约定:
- 我们需要在 props 里面设置接收参数
- 我们需要在 data 里面设置变量
- 我们需要在 computed 里面设置计算属性
- 我们需要在 watch 里面设置监听属性
- 我们需要在 methods 里面设置事件方法
你会发现 Options APi 都约定了我们该在哪个位置做什么事,这反倒在一定程度上也强制我们进行了代码分割。
现在用 Composition API,不再这么约定了,于是乎,代码组织非常灵活,我们的控制代码写在 setup 里面即可。
那么在逻辑越来越复杂的情况下,setup 代码量越来越多,同样 setup 里面的 return 越来越复杂,势必会落入“面条代码”的斡旋之中。
就比如说我们在写一个 Composition API 的实践的时候,该应用不大,但是一个 setup 方法整整 350 行代码了……
那我们如何去规避呢?
我们没有了 this 上下文,没有了 Options API 的强制代码分离。Composition API 给了我们更加广阔的天地,那么我们更加需要慎重自约起来。
对于复杂的逻辑代码,我们要更加重视起 Composition API 的初心,不要吝啬使用 Composition API 来分离代码,用来切割成各种模块导出。
就比方说我们期望他是这样的:
import useA from './a';
import useB from './b';
import useC from './c';
export default {
setup (props) {
let { a, methodsA } = useA();
let { b, methodsB } = useA();
let { c, methodsC } = useC();
return {
a,
methodsA,
b,
methodsB,
c,
methodsC
}
}
}
就算 setup 内容代码量越来越大,但是始终围绕着大而不乱,代码结构清晰的路子前进。
setup 是我们的代码控制器,尽量不要写入大量的业务逻辑代码。始终秉承着为 “控制器分忧,为 setup 减负” 的思想来写代码。
三:Fragments(碎片),Teleport,Suspense
Fragments
就像 React 一样,Vue JS 将在 Vue 3.0.0 版本中引入 fragments, fragments 的主要需求之一是 Vue 模板只能有一个标签。所以像这样的代码块在 Vue 模板会返回一个错误:
Hello
World
这个想法是在 React 16 中实现的,fragments 是模板包装标签,用于构造 HTML 代码,但不会改变语义。就像 Div 标签,但是对 DOM 没有任何影响。对于 fragments,手动渲染函数可以返回数组,并且它的工作方式与 React 中的工作方式类似。
Teleport
Teleports 是一种子节点渲染到父组件以外的 DOM 节点的方式,比如用于弹出窗口甚至 modals 。以前,在 CSS 中处理这个问题通常会很麻烦,现在 Vue 允许你在模板部分使用 来处理这个问题。
Suspense
Suspense 是延迟加载期间需要的组件,主要用于包装延迟组件。可以使用 suspense 组件包装多个延迟组件。在 3.0.0 版本中,将引入 Vue JS suspense,以便在嵌套树中等待嵌套的异步依赖项,它可以很好地和异步组件配合使用。
Vue3采用不做调度的情况下,采用粗暴的方法实现Suspense。
也就是:嵌套的组件树渲染之前先在内存中渲染,渲染过程中会记录存在异步以来的组件,当所有嵌套的异步依赖组件被resolve之后才会把整个树渲染到dom里面去,结合composition API采用async setup()定义异步组件。
四:更好的TypeScript支持

- Vue3采用Typescript重写,好处是类型提示,类型检测,自动补全
- Vue3.0 class提案被废弃了,class不是第一推荐的使用方式。灰常喜欢class风格的用户,依然可以支持class写法,vue-class-component 作为单独的库。
- Vue3+TypescriptIDE插件也在开发当中,预计年底大量使用。
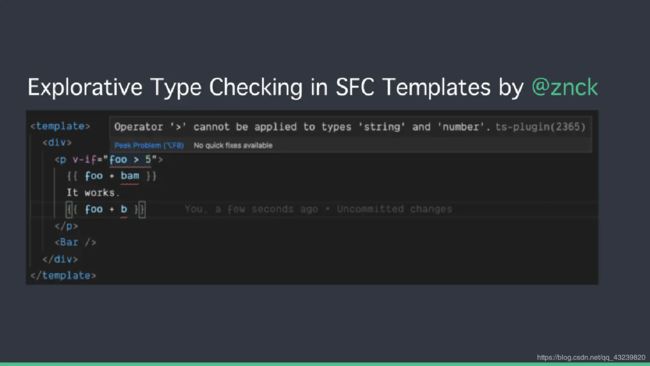
五:Custom Renderer API:自定义渲染器API

- 正在进行NativeScript Vue集成
- 用户可以尝试WebGL自定义渲染器,与普通Vue应用程序一起使用(Vugel:用Vue的语法表达WebGL的渲染逻辑,渲染出来的内容可以嵌入到Vue应用)。
- 意味着以后可以通过 vue, Dom 编程的方式来进行 webgl 编程 。
第二块:Vue3.0 diff算法优化细节+虚拟Dom总结
我们先看一段代码:
hello
{{msg}}
vue2生成的render函数
其中第一个标签是完全静态的,后续的渲染中不会产生任何变化,Vue2中依然使用_c新建成vdom,在diff的时候需要对比,有一些额外的性能损耗
var render = function() {
var _vm = this
var _h = _vm.$createElement
var _c = _vm._self._c || _h
return _c("div", [
_c("span", [_vm._v("hello")]),
_c("span", [_vm._v(_vm._s(_vm.msg))])
])
}
vue3生成的render函数
最后一个_createVNode第四个参数1,只有带这个参数的,才会被真正的追踪,静态节点不需要遍历,这个就是vue3优秀性能的主要来源
import { createVNode as _createVNode, toDisplayString as _toDisplayString, openBlock as _openBlock, createBlock as _createBlock } from "vue"
export function render(_ctx, _cache) {
return (_openBlock(), _createBlock("div", null, [
_createVNode("span", null, "hello"),
_createVNode("span", null, _toDisplayString(_ctx.msg), 1 /* TEXT */)
]))
}
// Check the console for the AST
vue2 生成的 vnode
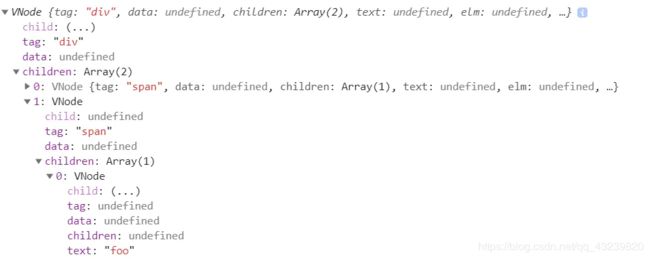
vue3 生成的 vnode
注意标记的,dynamicChildren

很明显,vue3 标记了dynamicChildren 动态节点
接下来patch阶段,只会比较动态节点,静态的直接略过了
而vue2中,还是会patch所有子节点去比对变更
但是Vue2.0其实对于纯静态节点也有优化,但是上面demo中由于只有一层纯文字静态节点,所以未判定为static,套一层div后就会标记为static,之后进入patch阶段会判定是静态节点直接return。vue2其实更多的是同级之间做diff比较,首次遍历损耗比较大,有了很多无用的操作,而 vue3中patch则只会比较dynamicChildren节点,静态节点不能进入patch
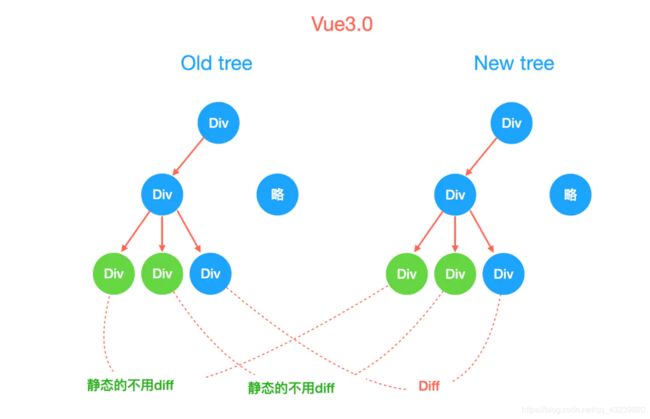
当然我们接着来看diff算法:
下面我们也来用一组数据做例子
// old arr
["a", "b", "c", "d", "e", "f", "g", "h"]
// new arr
["a", "b", "d", "f", "c", "e", "x", "y", "g", "h"]
其实前四步都好理解
第1步:从头到尾开始比较,[a,b]是sameVnode,进入patch,到 [c] 停止;
第2步:从尾到头开始比较,[h,g]是sameVnode,进入patch,到 [f] 停止;
第3步:判断旧数据是否已经比较完毕,多余的说明是新增的,需要mount(本例中没有)
第4步:判断新数据是否已经比较完毕,多余的说明是删除的,需要unmount(本例中没有)
第5步:进入到这里,说明是乱序了,这一步就开始稍显复杂
5.1 首先建一个还未比较的新数据index的Map,keyToNewIndexMap[d:2,f:3,c:4,e:5,x:6,y:7]
5.2
根据未比较完的数据长度,建一个填充 0 的数组 [0,0,0,0,0]
然后循环一遍旧剩余数据,找到未比较的数据的索引newIndexToOldIndexMap[4(d),6(f),3(c ),5(e),0,0]
如果没有在新剩余数据里找到,说明是删除的,unmount掉
找到了,和之前的patch一下
5.3 其实到这一步,已经很好办了,从尾到头循环一下newIndexToOldIndexMap
是 0 的,说明是新增的数据,就 mount 进去
非 0 的,说明在旧数据里,我们只要把它们移动到对应index的前面就行了
如下:
- 把 c 移动到 e 之前
- 把 f 移动到 c 之前
- 把 d 移动到 f 之前
但是我们发现,c 移动到 e 之前是多余的
因为等 f 和 d 都移动之后,c 自然就到 e 之前了
所以,vue3中还做了一件事情,根据newIndexToOldIndexMap找到最长递增子序列
我们的 [4(d),6(f),3(c ),5(e),0,0] 很明显能找到 [3,5] 是数组中的最长递增子序列
于是乎 [3,5] 都不需要移动
做完这步操作之后,我们的diff算法就结束了
对比 vue2.0 的diff算法
但是之前的那组数据
// old arr
["a", "b", "c", "d", "e", "f", "g", "h"]
// new arr
["a", "b", "d", "f", "c", "e", "x", "y", "g", "h"]
vue2整体上也差不多,但是它只有一个双指针的循环
首先比较新旧的头,直到第一个非 sameVNOde
然后从尾开始比较,直到第一个非 sameVNOde
然后会做头尾,尾头的比较,这种是考虑到会左移和右移操作
上面的步骤做完,会发现和vue3一样,只剩下这些没有比较
["d", "f", "c", "e", "x", "y"]
接着会尝试从 “d” 开始去旧数据里找到 index
然后移动到旧数据还未比较数据的头部
于是乎:
- 把 d 移动到 c 之前
- 把 f 移动到 c 之前
- 下轮循环发现新旧都是 c 于是 patch 完之后继续
- 下轮循环发现新旧都是 e 于是 patch 完之后继续
- 发现 x 不在旧数据中,createElm(x)
- 发现 x 不在旧数据中,createElm(y)
可以发现,vue2 在 diff 算法处理无序数据的判断是在最后
每次处理之前,会依次判断之前所有的 if
而vue3中,会找到所有需要移动的节点,直接移动
还有一点 vue3 中 对于首尾替换的额外判断似乎也取消了
第三块:新工具Vite的原理和使用
vite是什么?
Vite,一个基于浏览器原生 ES imports 的开发服务器。利用浏览器去解析 imports,在服务器端按需编译返回,完全跳过了打包这个概念,服务器随起随用。同时不仅有 Vue 文件支持,还搞定了热更新,而且热更新的速度不会随着模块增多而变慢。针对生产环境则可以把同一份代码用 rollup 打包。虽然现在还比较粗糙,但这个方向是有潜力的,做得好可以彻底解决改一行代码等半天热更新的问题。
分为下面两点:
- 一个是 Vite 主要对应的场景是开发模式,原理是拦截浏览器发出的 ES imports 请求并做相应处理。
- 一个是 Vite 在开发模式下不需要打包,只需要编译浏览器发出的 HTTP 请求对应的文件即可,所以热更新速度很快。
因此,要实现上述目标,需要要求项目里只使用原生 ES imports,如果使用了 require 将失效,所以要用它完全替代掉 Webpack 就目前来说还是不太现实的。上面也说了,生产模式下的打包不是 Vite 自身提供的,因此生产模式下如果你想要用 Webpack 打包也依然是可以的。从这个角度来说,Vite 可能更像是替代了 webpack-dev-server 的一个东西。
modules 模块
Vite 的实现离不开现代浏览器原生支持的 模块功能。如下:
当声明一个 script 标签类型为 module 时,浏览器将对其内部的 import 引用发起 HTTP 请求获取模块内容。比如上述,浏览器将发起一个对 HOST/a.js 的 HTTP 请求,获取到内容之后再执行。
Vite 劫持了这些请求,并在后端进行相应的处理(比如将 Vue 文件拆分成 template、style、script 三个部分),然后再返回给浏览器。
由于浏览器只会对用到的模块发起 HTTP 请求,所以 Vite 没必要对项目里所有的文件先打包后返回,而是只编译浏览器发起 HTTP 请求的模块即可。
大家可能会有个疑问,为何Vite的热更新速度不会随着模块的增多而变慢
简单举个例子,有三个文件 a.js、b.js、c.js
// a.js
const a = () => { ... }
export { a }
// b.js
const b = () => { ... }
export { b }
// c.js
import { a } from './a'
import { b } from './b'
const c = () => {
return a() + b()
}
export { c }
如果以 c 文件为入口,那么打包就会变成如下(结果进行了简化处理):(假定打包文件名为 bundle.js)
// bundle.js
const a = () => { ... }
const b = () => { ... }
const c = () => {
return a() + b()
}
export { c }
但是打包也需要有编译的步骤。
Webpack 的热更新原理简单来说就是,一旦发生某个依赖(比如上面的 a.js )改变,就将这个依赖所处的 module 的更新,并将新的 module 发送给浏览器重新执行。由于我们只打了一个 bundle.js,所以热更新的话也会重新打这个 bundle.js。试想如果依赖越来越多,就算只修改一个文件,理论上热更新的速度也会越来越慢。
而如果是像 Vite 这种只编译不打包会是什么情况呢?
只是编译的话,最终产出的依然是 a.js、b.js、c.js 三个文件,只有编译耗时。由于入口是 c.js,浏览器解析到 import { a } from ‘./a’ 时,会发起 HTTP 请求 a.js (b 同理),就算不用打包,也可以加载到所需要的代码,因此省去了合并代码的时间。
在热更新的时候,如果 a 发生了改变,只需要更新 a 以及用到 a 的 c。由于 b 没有发生改变,所以 Vite 无需重新编译 b,可以从缓存中直接拿编译的结果。这样一来,修改一个文件 a,只会重新编译这个文件 a 以及浏览器当前用到这个文件 a 的文件,而其余文件都无需重新编译。所以理论上热更新的速度不会随着文件增加而变慢。
当然这样做有没有不好的地方?
初始化的时候如果浏览器请求的模块过多,也会带来初始化的性能问题。不过如果你能遇到初始化过慢的这个问题,相信热更新的速度会弥补很多。
当然我们可以尝试一下(命令如下):
- mkdir vue-vite 新建文件夹
- npm init -y 初始化项目
- npm i vite -g 全局安装vite
然后新建文件
在项目目录下新建 一下文件index.html
然后新建Comp.vue
然后新建main.js
import { createApp } from 'vue'
import Comp from './Comp.vue'
createApp(Comp).mount('#app')
最后启动:
- cd vue-vite 进入目录
- vite 启动项目
看到这样的页面就代表你启动成功了
然后你可以尝试修改 Comp.vue 看看效果,不用预编译,且支持热更新
本文用于个人学习总结,中间内容有借鉴其他文章的思想,大佬们轻拍,愿景还是想通过这篇文章让大家更好的了解Vue3.0的变更,同时也期待Vue的开源团队能做的更好。