并发实战——原子类AtomicReference及底层源码CompareAndSwapObject分析
本文内容:
- 分析原子类AtomicReference
- 分析源码
AtomicReference中
public final boolean compareAndSet(V expect, V update) {
return unsafe.compareAndSwapObject(this, valueOffset, expect, update);
}public final V getAndSet(V newValue) {
return (V)unsafe.getAndSetObject(this, valueOffset, newValue);
}
public final Object getAndSetObject(Object var1, long var2, Object var4) {
Object var5;
do {
var5 = this.getObjectVolatile(var1, var2);
} while(!this.compareAndSwapObject(var1, var2, var5, var4));
return var5;
}compareAndSwapObject 源码探析
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);可以看到声明的是native方法,意味着该方法使用更底层的代码(cpp)实现的,需要下载openjdk源码才可以看到。下面开始简要地介绍下寻找源码的过程。
下载好openjdk源码后,将其导入到idea里该project的lib中,方便全局查找。
参照native实现规则,可以猜测javah工具生成的cpp头文件。
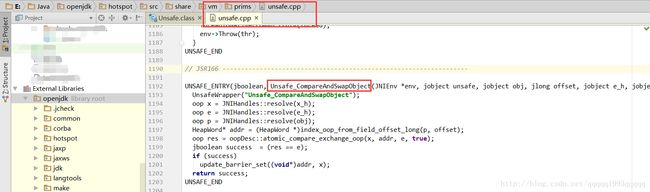
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapObject(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jobject e_h, jobject x_h))
UnsafeWrapper("Unsafe_CompareAndSwapObject");
oop x = JNIHandles::resolve(x_h); // 新值
oop e = JNIHandles::resolve(e_h); // 预期值
oop p = JNIHandles::resolve(obj);
HeapWord* addr = (HeapWord *)index_oop_from_field_offset_long(p, offset);// 在内存中的具体位置
oop res = oopDesc::atomic_compare_exchange_oop(x, addr, e, true);// 调用了另一个方法
jboolean success = (res == e); // 如果返回的res等于e,则判定满足compare条件(说明res应该为内存中的当前值),但实际上会有ABA的问题
if (success) // success为true时,说明此时已经交换成功(调用的是最底层的cmpxchg指令)
update_barrier_set((void*)addr, x); // 每次Reference类型数据写操作时,都会产生一个Write Barrier暂时中断操作,配合垃圾收集器
return success;
UNSAFE_END我们直接全局搜索(搜索范围是openjdk)这个被调用的方法,可以看到该方法的定义和实现
定义:
在opp.hpp文件中
static oop atomic_compare_exchange_oop(oop exchange_value,
volatile HeapWord *dest,
oop compare_value,
bool prebarrier = false);实现:
在opp.inline.hpp中
(http://blog.csdn.net/lqp276/article/details/52231261 指针压缩相关)
inline oop oopDesc::atomic_compare_exchange_oop(oop exchange_value,
volatile HeapWord *dest,
oop compare_value,
bool prebarrier) {
if (UseCompressedOops) { // 如果使用了压缩普通对象指针(CompressedOops),有一个重新编解码的过程
if (prebarrier) {
update_barrier_set_pre((narrowOop*)dest, exchange_value);
}
// encode exchange and compare value from oop to T
narrowOop val = encode_heap_oop(exchange_value); // 新值
narrowOop cmp = encode_heap_oop(compare_value); // 预期值
narrowOop old = (narrowOop) Atomic::cmpxchg(val, (narrowOop*)dest, cmp); // 这里调用的方法见文章最后,因为被压缩到了32位,所以可以用int操作
// decode old from T to oop
return decode_heap_oop(old);
} else {
if (prebarrier) {
update_barrier_set_pre((oop*)dest, exchange_value);
}
return (oop)Atomic::cmpxchg_ptr(exchange_value, (oop*)dest, compare_value); // 可以看到这里继续调用了其他方法
}
}针对64位地址的操作
inline jlong Atomic::cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value) {
int mp = os::is_MP();
jint ex_lo = (jint)exchange_value;
jint ex_hi = *( ((jint*)&exchange_value) + 1 );
jint cmp_lo = (jint)compare_value;
jint cmp_hi = *( ((jint*)&compare_value) + 1 );
__asm {
push ebx
push edi
mov eax, cmp_lo
mov edx, cmp_hi
mov edi, dest
mov ebx, ex_lo
mov ecx, ex_hi
LOCK_IF_MP(mp)
cmpxchg8b qword ptr [edi]
pop edi
pop ebx
}
}/**
CMPXCHG8B - 比较并交换 8 字节
说明
比较 EDX:EAX 中的 64 位值与操作数(目标操作数)。如果这两个值相等,则将 ECX:EBX 中的 64 位值存储到目标操作数。否则,将目标操作数的值加载到 EDX:EAX。目标操作数是 8 字节内存位置。对于一对 EDX:EAX 与 ECX:EBX 寄存器,EDX 与 ECX 包含 64 位值的 32 个高位,EAX 与 EBX 包含 32 个低位。
此指令可以配合 LOCK 前缀使用,此时指令将以原子方式执行。为了简化处理器的总线接口,目标操作数可以不考虑比较结果而接收一个写入周期。如果比较失败,则写回目标操作数;否则,将源操作数写入目标。(处理器永远不会只产生锁定读取而不产生锁定写入)。
*/
CompareAndSwapInt
再来看一个基本类型的CAS源码
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e; // 这里调用的就是上面的CPU指令cmpxchg
UNSAFE_ENDatomic_windows_x86.inline.hpp中:
MP表示multiprocessor,即多处理器。最终根据具体的处理器架构转换成汇编指令来实现CAS。
当多处理器时需要在前面加上lock指令。
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
// alternative for InterlockedCompareExchange
int mp = os::is_MP();
__asm {
mov edx, dest // eax,ecx,edx都是32位寄存器
mov ecx, exchange_value
mov eax, compare_value
LOCK_IF_MP(mp)
cmpxchg dword ptr [edx], ecx
}
}上述是cpu层面的CAS,介绍如下:
Compares the value in the AL, AX, or EAX register (depending on the size of the operand) with the first operand (destination operand). If the two values are equal, the second operand (source operand) is loaded into the destination operand. Otherwise, the destination operand is loaded into the AL, AX, or EAX register.(若期望值等于对象地址存储的值,则用新值来替换对象地址存储的值,否则,把期望值变为当前对象地址存储的值)
This instruction can be used with a LOCK prefix to allow the instruction to be executed atomi-cally. To simplify the interface to the processor’s bus, the destination operand receives a write cycle without regard to the result of the comparison. The destination operand is written back if the comparison fails; otherwise, the source operand is written into the destination. (The processor never produces a locked read without also producing a locked write.)
CAS是所有原子变量的原子性的基础,为什么一个看起来如此不自然的操作却如此重要呢?其原因就在于这个native操作会最终演化为一条CPU指令cmpxchg,而不是多条CPU指令。由于CAS仅仅是一条指令,因此它不会被多线程的调度所打断,所以能够保证CAS操作是一个原子操作。补充一点,当代的很多CPU种类都支持cmpxchg操作,但不是所有CPU都支持,对于不支持的CPU,会自动加锁来保证其操作不会被打断。
由此可知,原子变量提供的原子性来自CAS操作,CAS来自Unsafe,然后由CPU的cmpxchg指令来保证。
(以下应该是针对byte型数据的CAS,但是具体的操作有点奇怪,主要是赋值那一块)
不使用全局搜索,也可以用另一种方式寻找函数。
首先看之前文件中#inclued里出现的文件
找到如下(因为之前调用的方法也是Atomic开头的)
#include "runtime/atomic.inline.hpp"然后进入该hpp文件,找到
#include "runtime/atomic.hpp"这次我们直接定位到atomic.cpp文件
(http://blog.csdn.net/lxf310/article/details/39719445 →出现的jint到底是什么)
jbyte Atomic::cmpxchg(jbyte exchange_value, volatile jbyte* dest, jbyte compare_value) {
assert(sizeof(jbyte) == 1, "assumption.");
uintptr_t dest_addr = (uintptr_t)dest;
uintptr_t offset = dest_addr % sizeof(jint);
volatile jint* dest_int = (volatile jint*)(dest_addr - offset);
jint cur = *dest_int; // 当前值
jbyte* cur_as_bytes = (jbyte*)(&cur); // cur的地址
jint new_val = cur;
jbyte* new_val_as_bytes = (jbyte*)(&new_val); // new_val的地址
// 将新值先写在new_val的地址上(因为最后取值也是从jbyte* dest地址上取值?)
new_val_as_bytes[offset] = exchange_value;
//当前值和期望值进行比较,假设不满足,直接返回cur_as_bytes[offset],因为与compare_value值不同,上层方法会判定交换失败
while (cur_as_bytes[offset] == compare_value) {
// 尝试交换,调用机器指令,返回的是当前该地址上的值
jint res = cmpxchg(new_val, dest_int, cur);
if (res == cur) break;
//否则,修改cur
cur = res;
new_val = cur;
new_val_as_bytes[offset] = exchange_value;
}
return cur_as_bytes[offset];
}