从 leveldb 到分布式 kv 存储系统
目录
- LevelDB
- RocksDB : enhanced LevelDB
- Features
- RocksDB Features that are not in LevelDB
- 一些基于 LevelDB/RocksDB 的 kv 存储系统
- Pika - 360
- 整体架构
- 线程模型
- pika blackwidow引擎数据存储格式
- Hash结构的存储
- Tair - 阿里巴巴
- 存储引擎
- Version支持
- 分布式策略
- config server
- 容灾
- 扩容
- 迁移
- Abase - 头条
LevelDB
详细原理见 leveldb 原理解析
RocksDB : enhanced LevelDB
https://rocksdb.org.cn/doc.html
RocksDB是从 levelDB 的某个 commit checkout 出来的,进化版
RocksDB is a C++ library providing an embedded key-value store, where keys and values are arbitrary byte streams. It was developed at Facebook based on LevelDB and provides backwards-compatible support for LevelDB APIs.
RocksDB is optimized for Flash with extremely low latencies. RocksDB uses a Log Structured Database Engine for storage, written entirely in C++. A Java version called RocksJava is currently in development. See RocksJava Basics.
RocksDB features highly flexible configuration settings that may be tuned to run on a variety of production environments, including pure memory, Flash, hard disks or HDFS. It supports various compression algorithms and good tools for production support and debugging.
Features
- Designed for application servers wanting to store up to a few terabytes of data on locally attached Flash drives or in RAM
- Optimized for storing small to medium size key-values on fast storage – flash devices or in-memory
- Scales linearly with number of CPUs so that it works well on processors with many cores
RocksDB Features that are not in LevelDB
Performance
- Multithread compaction
- Multithread memtable inserts
- Reduced DB mutex holding
- Optimized level-based compaction style and universal compaction style
- Prefix bloom filter
- Memtable bloom filter
- Single bloom filter covering the whole SST file
- Write lock optimization
- Improved Iter::Prev() performance
- Fewer comparator calls during SkipList searches
- Allocate memtable memory using huge page.
Features
12. Column Families
13. Transactions and WriteBatchWithIndex
14. Backup and Checkpoints
15. Merge Operators
16. Compaction Filters
17. RocksDB Java
18. Manual Compactions Run in Parallel with Automatic Compactions
19. Persistent Cache
20. Bulk loading
21. Forward Iterators/ Tailing iterator
22. Single delete
23. Delete files in range
24. Pin iterator key/value
一些基于 LevelDB/RocksDB 的 kv 存储系统
Pika - 360
https://github.com/Qihoo360/pika
基于 RocksDB
完全支持 Redis 协议,用户不需要修改任何代码,就可以将服务迁移至 Pika。Pika是一个可持久化的大容量Redis存储服务,兼容string、hash、list、zset、set的绝大接口兼容详情,解决Redis由于存储数据量巨大而导致内存不够用的容量瓶颈,并且可以像Redis一样,通过slaveof命令进行主从备份,支持全同步和部分同步。同时DBA团队还提供了迁移工具, 所以用户不会感知这个迁移的过程,迁移是平滑的。
整体架构
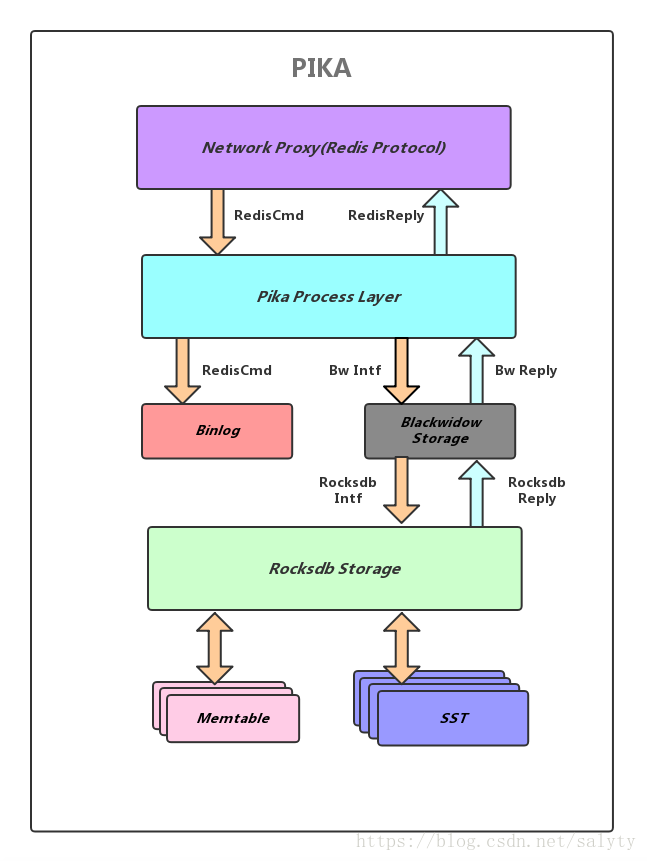
线程模型
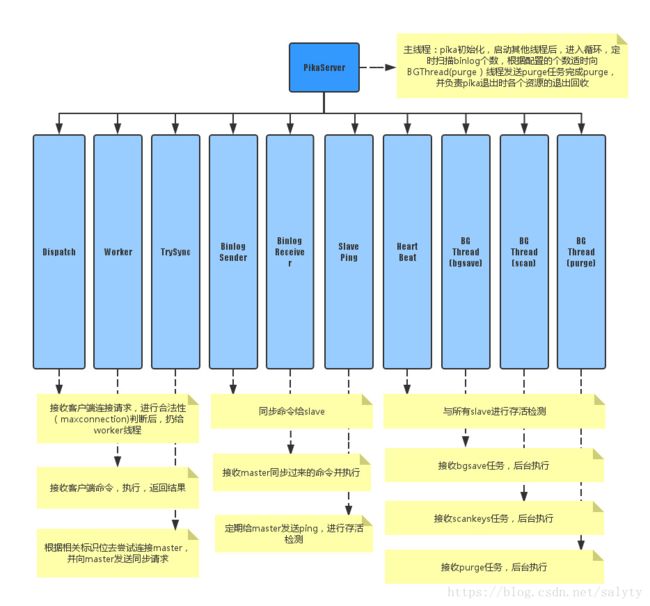
pika使用的是多线程模型,使用多个工作线程来进行读写操作,由底层blackwidow引擎来保证线程安全,线程分为11种。
- PikaServer:主线程
- DispatchThread:监听端口1个端口,接收用户连接请求
- WorkerThread:存在多个(用户配置),每个线程里有若干个用户客户端的连接,负责接收处理用户命令并返回结果,每个线程执行写命令后,追加到binlog中
- Trysync:尝试与master建立首次连接,并在以后出现故障后发起重连
- BinlogSender:存在多个(动态创建销毁,本master节点挂多少个slave节点就有多少个),每个线程根据slave节点发来的同步偏移量,从binlog指定的偏移开始实时同步命令给slave节点
- BinlogReceiver:存在1个(动态创建销毁,一个slave节点同时只能有一个master),将用户指定或当前的偏移量发送给master节点并开始接收执行master实时发来的同步命令,在本地使用和master完全一致的偏移量来追加binlog
- SlavePing:slave用来向master发送心跳进行存活检测
- bgsave:后台dump线程
- HeartBeat:master用来接收所有slave发送来的心跳并回复进行存活检测
- scan:后台扫描keyspace线程
- purge:后台删除binlog线程
- Monitor: 实时打印出Pika服务器接收到的命令
- Pub/Sub: 用来支持Pika的订阅功能
pika blackwidow引擎数据存储格式
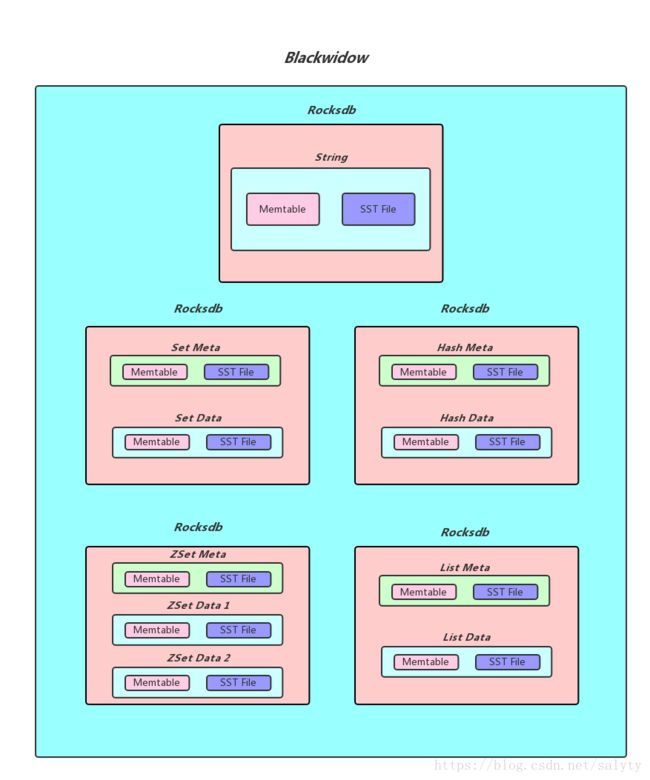
Hash结构的存储
blackwidow中的hash表由两部分构成,元数据(meta_key, meta_value), 和普通数据(data_key, data_value), 元数据中存储的主要是hash表的一些信息, 比如说当前hash表的域的数量以及当前hash表的版本号和过期时间(用做秒删功能), 而普通数据主要就是指的同一个hash表中一一对应的field和value,作为具体最后Rocksdb落盘的kv格式,下面是具体的实现方式:
每个hash表的meta_key和meta_value的落盘方式

meta_key实际上就是hash表的key, 而meta_value由三个部分构成: 4Bytes的Hash size(用于存储当前hash表的大小) + 4Bytes的Version(用于秒删功能) + 4Bytes的Timestamp(用于记录我们给这个Hash表设置的超时时间的时间戳, 默认为0)
hash表中data_key和data_value的落盘方式

data_key由四个部分构成: 4Bytes的Key size(用于记录后面追加的key的长度,便与解析) + key的内容 + 4Bytes的Version + Field的内容, 而data_value就是hash表某个field对应的value。
如果我们需要查找一个hash表中的某一个field对应的value, 我们首先会获取到meta_value解析出其中的timestamp判断这个hash表是否过期, 如果没有过期, 我们可以拿到其中的version, 然后我们使用key, version,和field拼出data_key, 进而找到对应的data_value(如果存在的话)
Tair - 阿里巴巴
http://tair.taobao.org/

作为一个分布式系统,Tair由一个中心控制节点(config server)和一系列的服务节点(data server)组成,
- config server 负责管理所有的data server,并维护data server的状态信息;为了保证高可用(High Available),config server以一主一备形式提供服务;
- data server 对外提供各种数据服务,并以心跳的形式将自身状况汇报给config server;所有的 data server 地位都是等价的。
存储引擎
Tair的存储引擎有一个抽象层,只要满足存储引擎需要的接口,便可以很方便的替换Tair底层的存储引擎。比如你可以很方便的将bdb、tc、redis、leveldb甚至MySQL作为Tair的存储引擎,而同时使用Tair的分布方式、同步等特性。
Tair主要有下面几种存储引擎:
- mdb,定位于cache缓存,类似于memcache。支持k/v存取和prefix操作;
- rdb,定位于cache缓存,采用了redis的内存存储结构。支持k/v,list,hash,set,sortedset等数据结构;
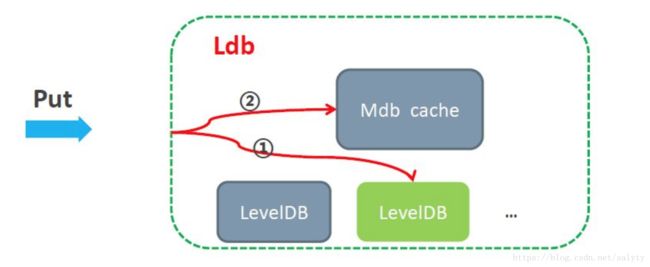
- ldb,定位于高性能存储,采用了levelDB作为引擎,并可选择内嵌mdb cache加速,这种情况下cache与持久化存储的数据一致性由tair进行维护。支持k/v,prefix等数据结构。今后将支持list,hash,set,sortedset等redis支持的数据结构。
- kdb,Kyoto Cabinet
LDB流程

Version支持
Tair中的每个数据都包含版本号,版本号在每次更新后都会递增。这个特性有助于防止由于数据的并发更新导致的问题。
Version改变的逻辑如下:
- 如果put新数据且没有设置版本号,会自动将版本设置成1;
- 如果put是更新老数据且没有版本号,或者put传来的参数版本与当前版本一致,版本号自增1;
- 如果put是更新老数据且传来的参数版本与当前版本不一致,更新失败,返回VersionError;
- put时传入的version参数为0,则强制更新成功,版本号自增1。
比如,系统有一个value为“a,b,c”,A和B同时get到这个value。A执行操作,在后面添加一个d,value为 “a,b,c,d”。B执行操作添加一个e,value为”a,b,c,e”。如果不加控制,无论A和B谁先更新成功,它的更新都会被后到的更新覆盖。
Tair无法解决这个问题,但是引入了version机制避免这样的问题。还是拿刚才的例子,A和B取到数据,假设版本号为10,A先更新,更新成功 后,value为”a,b,c,d”,与此同时,版本号会变为11。当B更新时,由于其基于的版本号是10,服务器会拒绝更新,从而避免A的更新被覆盖。 B可以选择get新版本的value,然后在其基础上修改,也可以选择强行更新。
分布式策略
tair 的分布采用的是一致性哈希算法,对于所有的key,分到Q个桶中,桶是负载均衡和数据迁移的基本单位。config server 根据一定的策略把每个桶指派到不同的data server上,因为数据按照key做hash算法,所以可以认为每个桶中的数据基本是平衡的,保证了桶分布的均衡性, 就保证了数据分布的均衡性。
具体说,首先计算Hash(key),得到key所对应的bucket,然后再去config server查找该bucket对应的data server,再与相应的data server进行通信。也就是说,config server维护了一张由bucket映射到data server的对照表,比如:
bucket data server
192.168.10.1
192.168.10.2
192.168.10.1
192.168.10.2
192.168.10.1
192.168.10.2
这里共6个bucket,由两台机器负责,每台机器负责3个bucket。客户端将key hash后,对6取模,找到负责的数据节点,然后和其直接通信。表的大小(行数)通常会远大于集群的节点数,这和consistent hash中的虚拟节点很相似。
当有新节点加入或者有节点不可用时,config server会根据当前可用的节点,重新build一张对照表。数据节点同步到新的对照表时,会自动将在新表中不由自己负责的数据迁移到新的目标节点。迁移完成后,客户端可以从config server同步到新的对照表,完成扩容或者容灾过程。整个过程对用户是透明的,服务不中断。
config server
client 和 config server的交互主要是为了获取数据分布的对照表,当client启动时获取到对照表后,会cache这张表,然后通过查这张表决定数据存储的节点,所以请求不需要和config server交互,这使得Tair对外的服务不依赖configserver,所以它不是传统意义上的中心节点,也并不会成为集群的瓶颈。
config server维护的对照表有一个版本号,每次新生成表,该版本号都会增加。当有data server状态发生变化(比如新增节点或者有节点不可用了)时,configserver会根据当前可用的节点重新生成对照表,并通过数据节点的心跳,将新表同步给data server。当client请求data server时,后者每次都会将自己的对照表的版本号放入response中返回给客client,client接收到response后,会将data server返回的版本号和自己的版本号比较,如果不相同,则主动和config server通信,请求新的对照表。
这使得在正常的情况下,client不需要和configserver通信,即使config server不可用了,也不会对整个集群的服务造成大的影响。有了config server,client不需要配置data server列表,也不需要处理节点的的状态变化,这使得Tair对最终用户来说使用和配置都很简单。
容灾
当有某台data server故障不可用的时候,config server会发现这个情况,config server负责重新计算一张新的桶在data server上的分布表,将原来由故障机器服务的桶的访问重新指派到其它有备份的data server中。这个时候,可能会发生数据的迁移,比如原来由data server A负责的桶,在新表中需要由 B负责,而B上并没有该桶的数据,那么就将数据迁移到B上来。同时,config server会发现哪些桶的备份数目减少了,然后根据负载情况在负载较低的data server上增加这些桶的备份。
扩容
当系统增加data server的时候,config server根据负载,协调data server将他们控制的部分桶迁移到新的data server上,迁移完成后调整路由。
注意:
不管是发生故障还是扩容,每次路由的变更,config server都会将新的配置信息推给data server。在client访问data server的时候,会发送client缓存的路由表的版本号,如果data server发现client的版本号过旧,则会通知client去config server取一次新的路由表。如果client访问某台data server 发生了不可达的情况(该 data server可能宕机了),客户端会主动去config server取新的路由表。
迁移
当发生迁移的时候,假设data server A 要把 桶 3,4,5 迁移给data server B。因为迁移完成前,client的路由表没有变化,因此对 3, 4, 5 的访问请求都会路由到A。现在假设 3还没迁移,4 正在迁移中,5已经迁移完成,那么:
- 如果是对3的访问,则没什么特别,跟以前一样;
- 如果是对5的访问,则A会把该请求转发给B,并且将B的返回结果返回给client;
- 如果是对4的访问,在A处理,同时如果是对4的修改操作,会记录修改log,桶4迁移完成的时候,还要把log发送到B,在B上应用这些log,最终A B上对于桶4来说,数据完全一致才是真正的迁移完成;
Abase - 头条
基于 RocksDB