挑战一轮大厂后的面试总结 (含六个方向) - nodejs 篇
在去年底开始换工作,直到现在算是告了一个段落,断断续续的也面试了不少公司,现在回想起来,那段时间经历了被面试官手撕,被笔试题狂怼,悲伤的时候差点留下没技术的泪水。
这篇文章我打算把我找工作遇到的各种面试题(每次面试完我都会总结)和我自己复习遇到比较有意思的题目,做一份汇总,年后是跳槽高峰期,也许能帮到一些小伙伴。
先说下这些题目难度,大部分都是基础题,因为这段经历给我的感觉就是,不管你面试的是高级还是初级,基础的知识一定会问到,甚至会有一定的深度,所以基础还是非常重要的。
我将根据类型分为几篇文章来写:
面试总结:javascript 面试点汇总(万字长文)(已完成) 强烈大家看看这篇,面试中 js 是大头
面试总结:nodejs 面试点汇总(已完成)
面试总结:浏览器相关 面试点汇总(已完成)
面试总结:css 面试点汇总(已完成)
面试总结:框架 vue 和工程相关的面试点汇总(已完成)
面试总结:面试技巧篇(已完成)
六篇文章都已经更新完啦~
这篇文章是对 nodejs 相关的题目做总结,欢迎朋友们先收藏在看。
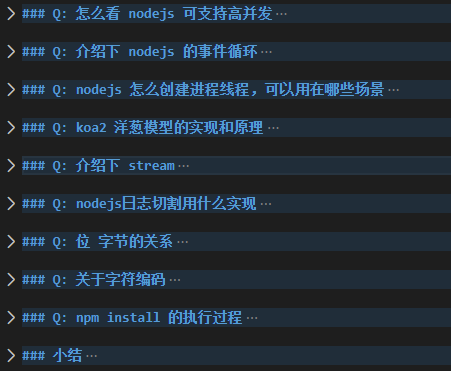
先看看目录
Q: 怎么看 nodejs 可支持高并发
这个问题涉及了好几个方面啊,聊的好,是个很好的加分项。可按照以下步骤给面试官解释
- nodejs 的单线程架构模型
nodejs 其实并不是真正的单线程架构,因为 nodejs 还有I/O线程存在(网络I/O、磁盘I/O),这些I/O线程是由更底层的 libuv 处理,这部分线程对于开发者来说是透明的。 JavaScript 代码永远运行在V8上,是单线程的。
所以从开发者的角度上来看 nodejs 是单线程的。
来张网图:

注意看图的右边有个 Event Loop,接下来要讲的重点
单线程架构的优势和劣势:
优势:
- 单线程就一个线程在玩,省去了线程间切换的开销
- 还有线程同步的问题,线程冲突的问题的也不需要担心
劣势:
- 劣势也很明显,现在起步都是 4 核,单线程没法充分利用 cpu 的资源
- 单线程,一旦崩溃,应用就挂掉了,大家调试脚本也知道一旦执行过程报错了,本次调试就直接结束了
- 因为只能利用一个 cpu ,一旦 cpu 被某个计算一直占用, cpu 得不到释放,后续的请求就会一直被挂起,直接无响应了
当然这些劣势都已经有成熟的解决方案了,使用 PM2 管理进程,或者上 K8S 也可以
- 核心:事件循环机制
那你个单线程怎么支持高并发呢?
核心就要在于 js 引擎的事件循环机制(我觉得这个开场还挺不错)
浏览器和 nodejs 的事件循环是稍有区别的,先给面试官简单说下事件循环的核心,执行栈、宏队列和微队列,具体的介绍可以看我以前写的一篇总结 js 事件循环
然后重点说 nodejs 事件循环的差异点,因不想把两个问题混在一起,所以独立成一个问题,具体讲解大家稍微往下翻看下一个问题的解答。
- 给出个结论 nodejs 是异步非阻塞的,所以能扛住高并发
来个个栗子:
比如有个客户端请求A进来,需要读取文件,读取文件后将内容整合,最后数据返回给客户端。但在读取文件的时候另一个请求进来了,那处理的流程是怎么样的?
灵魂画手,我整了张图,大家理解就好

- 请求A进入服务器,线程开始处理该请求
- A 请求需要读取文件,ok,交给文件 IO 处理,但是处理得比较慢,需要花 3 秒,这时候 A 请求就挂起(这个词可能不太恰当),等待通知,而等待的实现就是由事件循环机制实现的,
- 在A请求等待的时候,cpu 是已经被释放的,这时候B请求进来了, cpu 就去处理B请求
- 两个请求间,并不存在互相竞争的状态。那什么时候会出现请求阻塞呢?涉及到大量计算的时候,因为计算是在 js 引擎上执行的,执行栈一直卡着,别的函数就没法执行,举个栗子,构建一个层级非常深的大对象,反复对这个这个对象
JSON.parse(JSON.stringify(bigObj))
- 有机会的话可以给面试官扩展 同步、异步、阻塞、非阻塞 这个几个概念
同步和异步关注的是消息通信机制。
-
同步:在发起一个调用后,在没有得到结果前,该调用不返回,知道调用返回,才往下执行,也就是说调用者等待被调用方返回结果。
-
异步:在发起一个调用后,调用就直接返回,不等待结果,继续往下执行,而执行的结果是由被调用方通过状态、通知等方式告知调用方,典型的异步编程模型比如 Node.js
阻塞和非阻塞,关注的是在等待结果时,线程的状态。
- 阻塞:在等待调用结果时,线程挂起了,不往下执行
- 非阻塞:与上面相反,当前线程继续往下执行
参考资料:
https://www.zhihu.com/question/19732473
https://zhuanlan.zhihu.com/p/41118827
Q: 介绍下 nodejs 的事件循环
这里假设大家已经对浏览器的事件循环有了解,看下图:

如上图,事件循环中细分为这六个阶段,依次如下:
Timers: 定时器 Interval Timoout 回调事件,将依次执行定时器回调函数Pending: 一些系统级回调将会在此阶段执行Idle,prepare: 此阶段"仅供内部使用"Poll: IO回调函数,这个阶段较为重要也复杂些,Check: 执行 setImmediate() 的回调Close: 执行 socket 的 close 事件回调
开发需要关系的阶段
与我们开发相关的三个阶段分别是 Timers Poll Check
Timers :执行定时器的回调,但注意,在 node 11 前,连续的几个定时器回调会连续的执行,而不是像浏览器那样,执行完一个宏任务立即执行微任务。
Check :这个阶段执行 setImmediate() 的回调,这个事件只在 nodejs 中存在。
Poll :上面两个阶段的触发,其实是在 poll 阶段触发的,poll 阶段的执行顺序是这样的。
- 先查看 check 阶段是否有事件,有的话执行
- 执行完 check 阶段后,检查 poll 阶段的队列是否有事件,若有则执行
- poll 的队列执行完成后,执行 check 阶段的事件
在 nodejs 中也是有宏任务和微任务的, nodejs 中除了多了 process.nextTick ,宏任务、微任务的分类都是一致的。
那么微任务是在什么时候执行呢?
在上图,黄色的几个阶段的旁边挨着个小块 microtask,每个阶段执行后就立即执行微任务队列里的事件。
下面有个栗子说明。
微队列的栗子
如下代码:
const fs = require('fs');
const ITERATIONS_MAX = 3;
let iteration = 0;
const timeout = setInterval(() => {
console.log('START: setInterval', 'TIMERS PHASE');
if (iteration < ITERATIONS_MAX) {
setTimeout(() => {
console.log('setInterval.setTimeout', 'TIMERS PHASE');
});
fs.readdir('./image', (err, files) => {
if (err) throw err;
console.log('fs.readdir() callback: Directory contains: ' + files.length + ' files', 'POLL PHASE');
});
setImmediate(() => {
console.log('setInterval.setImmediate', 'CHECK PHASE');
});
} else {
console.log('Max interval count exceeded. Goodbye.', 'TIMERS PHASE');
clearInterval(timeout);
}
iteration++;
console.log('END: setInterval', 'TIMERS PHASE');
}, 0);
// 第一次执行
// START: setInterval TIMERS PHASE
// END: setInterval TIMERS PHASE
// setInterval.setImmediate CHECK PHASE
// setInterval.setTimeout TIMERS PHASE
// 第二次执行
// START: setInterval TIMERS PHASE
// END: setInterval TIMERS PHASE
// fs.readdir() callback: Directory contains: 9 files POLL PHASE
// fs.readdir() callback: Directory contains: 9 files POLL PHASE
// setInterval.setImmediate CHECK PHASE
// setInterval.setTimeout TIMERS PHASE
// 第三次执行
// START: setInterval TIMERS PHASE
// END: setInterval TIMERS PHASE
// setInterval.setImmediate CHECK PHASE
// fs.readdir() callback: Directory contains: 9 files POLL PHASE
// setInterval.setTimeout TIMERS PHASE
process.nextTick
关于 process.nextTick ,这个事件的优先级要高于其他微队列的事件,所以对于需要立即执行的回调事件可以通过该方法将事件放置到微队列的起始位置。
如下代码:
Promise.resolve().then(function () {
console.log('promise1')
})
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
process.nextTick(() => {
console.log('nextTick')
})
})
})
})
// nextTick=>nextTick=>nextTick=>timer1=>promise1
与浏览器的事件循环执行结果的区别
我们看如下代码分别在浏览器和 nodejs 中的执行结果
setTimeout(() => {
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(() => {
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
对浏览器事件队列熟悉的朋友很快就可得出 浏览器中 timer1->promise1->timer2->promise2,在浏览器中微任务队列是在每个宏任务执行完成后立即执行的。
那么在 nodejs 中呢?
结果是这样的: timer1->timer2->promise1->promise2 ,因为微任务队列是在每个阶段完成后立即执行,所以 Timer 阶段有两个回调事件,将事件依次执行后,在进入下一阶段的之前,先执行微队列中的事件。
注意:这个结果是在 node 10 及以下的版本测试出来的,在 11 及以上的版本做了修改,执行的结果与浏览器的执行结果是一致的
timer1->promise1->timer2->promise2
参考文章:
https://www.ibm.com/developerworks/cn/opensource/os-tutorials-learn-nodejs-the-event-loop/index.html
https://juejin.im/post/5c337ae06fb9a049bc4cd218
Q: nodejs 怎么创建进程线程,可以用在哪些场景
如何开启多个子进程
单线程的一个缺点是不能充分利用多核,所以官方推出了 cluster 模块, cluster 模块可以创建共享服务器端口的子进程
const cluster = require('cluster');
for (let i = 0; i < numCPUs; i++) {
cluster.fork(); // 生成新的工作进程,可以使用 IPC 和父进程通信
}
本质还是通过 child_process.fork() 专门用于衍生新的 Node.js 进程,衍生的 Node.js 子进程独立于父进程,但两者之间建立的 IPC 通信通道除外, 每个进程都有自己的内存,带有自己的 V8 实例
如何在一个进程的前提下开启多个线程
在 nodejs 10.0 及以上的版本,新增了 worker_threads 模块,可开启多个线程
const {
Worker, isMainThread, parentPort, workerData
} = require('worker_threads');
const worker = new Worker(__filename, {
workerData: script
});
- 线程间如何传输数据:
parentPortpostMessageon发送监听消息 - 共享内存:
SharedArrayBuffer通过这个共享内存
使用场景
- 常见的一个场景,在服务中若需要执行 shell 命令,那么就需要开启一个进程
var exec = require('child_process').exec;
exec('ls', function(error, stdout, stderr){
if(error) {
console.error('error: ' + error);
return;
}
console.log('stdout: ' + stdout);
});
- 对于服务中涉及大量计算的,可以开启一个工作线程,由这个线程去执行,执行完毕再把结果通知给服务线程。
参考连接:
https://wolfx.cn/nodejs/node-thread/
Q: koa2 洋葱模型的实现和原理
目前比较火的一个 nodejs 框架 koa2, 这个框架的代码并不多,也非常好理解,推荐大家看一看。
问起 koa2 ,只要把它的核心-洋葱模型说清楚就行。
这是一个段非常简单 koa server
const Koa = require('koa');
const app = new Koa();
app.use(async (ctx, next) => {
ctx.body = 'Hello World';
console.log('firsr before next')
next()
console.log('firsr after next')
});
app.use(async (ctx, next) => {
console.log('sencond before next')
next()
console.log('sencond after next')
ctx.body = 'use next';
});
app.listen(3500, () => {
console.log('run on port 3500')
});
请求 http://127.0.0.1:3500/ 输出
firsr before next
sencond before next
sencond after next
firsr after next
初始化中间件
通过 app.use 方法将中间件函数 push 到数组中,步骤如下:
-
判断是不是中间件函数是不是生成器
generators,目前 koa2 使用的异步方案是async/await,如果是generators函数,会转换成async/await -
使用 middleware 数组存放中间件
use(fn) {
if (typeof fn !== 'function') throw new TypeError('middleware must be a function!');
if (isGeneratorFunction(fn)) {
deprecate('Support for generators will be removed in v3. ' +
'See the documentation for examples of how to convert old middleware ' +
'https://github.com/koajs/koa/blob/master/docs/migration.md');
fn = convert(fn);
}
debug('use %s', fn._name || fn.name || '-');
this.middleware.push(fn);
return this;
}
执行中间件(洋葱模型)
我们通过 use 注册中间件,中间件函数有两个参数第一个是上下文,第二个是 next,在中间件函数执行过程中,若遇到 next() ,那么就会进入到下一个中间件中执行,下一个中间执行完成后,在返回上一个中间件执行 next() 后面的方法,这便是中间件的执行逻辑。
核心函数如下,我加上了注释
// koa-compose/index.js
function compose(middleware) {
// middleware 函数数组
if (!Array.isArray(middleware)) throw new TypeError('Middleware stack must be an array!')
for (const fn of middleware) {
if (typeof fn !== 'function') throw new TypeError('Middleware must be composed of functions!')
}
/*
content:上下文
next:新增一个中间件方法,位于所有中间件末尾,用于内部扩展
*/
return function (context, next) {
// last called middleware #
let index = -1 // 计数器,用于判断中间是否执行到最后一个
return dispatch(0) // 开始执行第一个中间件方法
function dispatch(i) {
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i
let fn = middleware[i] // 获取中间件函数
if (i === middleware.length) fn = next // 如果中间件已经到了最后一个,执行内部扩展的中间件
if (!fn) return Promise.resolve() // 执行完毕,返回 Promise
try {
// 执行 fn ,将下一个中间件函数赋值给 next 参数,在自定义的中间件方法中显示的调用 next 函数,中间件函数就可串联起来了
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err)
}
}
}
}
函数逻辑不难理解,妙在于设计,看官方张图,非常巧妙的利用函数式编程的思想(若是对函数式编程熟悉,可以给面试官来一波)

Q: 介绍下 stream
流在 nodejs 用的很广泛,但对于大部分开发者来说,更多的是使用流,比如说 HTTP 中的 request respond ,标准输入输出,文件读取(createReadStream), gulp 构建工具等等。
流,可以理解成是一个管道,比如读取一个文件,常用的方法是从硬盘读取到内存中,在从内存中读取,这种方式对于小文件没问题,但若是大文件,效率就非常低,还有可能内存不足,采用流的方式,就好像给大文件插上一根吸管,持续的一点点读取文件的内容,管道的另一端收到数据,就可以进行处理,了解 Linux 的朋友应该非常熟悉这个概念。
Node.js 中有四种基本的流类型:
- Writable - 可写入数据的流(例如 fs.createWriteStream())。
- Readable - 可读取数据的流(例如 fs.createReadStream())。
- Duplex - 可读又可写的流(例如 net.Socket)。
- Transform - 在读写过程中可以修改或转换数据的 Duplex 流(例如 zlib.createDeflate())。
接触比较多的还是第一二种
pipe 来消费可读流
const fs = require('fs');
// 直接读取文件
fs.open('./xxx.js', 'r', (err, data) => {
if (err) {
console.log(err)
}
console.log(data)
})
// 流的方式读取、写入
let readStream = fs.createReadStream('./a.js');
let writeStream = fs.createWriteStream('./b.js')
readStream.pipe(writeStream).on('data', (chunk) => { // 可读流被可写流消费
console.log(chunk)
writeStream.write(chunk);
}).on('finish', () => console.log('finish'))
原生提供了 stream 模块,大家可以看官方文档, api 非常强大,若我们需要新建个特定的流,就需要用到这个模块。
推荐文档:
https://javascript.ruanyifeng.com/nodejs/stream.html
http://nodejs.cn/api/stream.html
Q: nodejs日志切割用什么实现
用 winston 和 winston-daily-rotate-file 实现日志管理和切割,日切和根据大小进行切割。
(具体实现没有细看,感兴趣的盆友可以看看源码)
Q: 位 字节的关系
位:bit 代表二进制
字节:1字节 = 8位
Q: 关于字符编码
ASCII:编码的规范标准
Unicode:将全世界所有的字符包含在一个集合里,计算机只要支持这一个字符集,就能显示所有的字符,再也不会有乱码了。Unicode码是ASCII码的一个超集(superset)
UTF-32 UTF-8 UTF-16 都是Unicode码的编码形式
UTF-32:用固定长度的四个字节来表示每个码点
UTF-8:用可变长度的字节来表示每个码点,如果只需要一个字节就能表示的,就用一个字节,一个不够,就用两个…所以,在UTF-8编码下,一个字符有可能由1-4个字节组成.
UTF-16:结合了固定长度和可变长度,它只有两个字节和四个字节两种方式来表示码点
Q: npm install 的执行过程
以下是引用网友的总结,连接见文末
npm 模块安装机制
- 发出npm install命令
- 查询 node_modules 目录之中是否已经存在指定模块
- 若存在,不再重新安装
- 若不存在
- npm 向 registry 查询模块压缩包的网址
- 下载压缩包,存放在根目录下的.npm目录里
- 解压压缩包到当前项目的 node_modules 目录
npm 实现原理
输入 npm install 命令并敲下回车后,会经历如下几个阶段(以 npm 5.5.1 为例):
- 执行工程自身 preinstall,当前 npm 工程如果定义了 preinstall 钩子此时会被执行。
- 确定首层依赖模块,首先需要做的是确定工程中的首层依赖,也就是 dependencies 和 devDependencies 属性中直接指定的模块(假设此时没有添加 npm install 参数)。工程本身是整棵依赖树的根节点,每个首层依赖模块都是根节点下面的一棵子树,npm 会开启多进程从每个首层依赖模块开始逐步寻找更深层级的节点。
- 获取模块,获取模块是一个递归的过程,分为以下几步:
- 获取模块信息。在下载一个模块之前,首先要确定其版本,这是因为 package.json 中往往是 semantic version(semver,语义化版本)。此时如果版本描述文件(npm-shrinkwrap.json 或 package-lock.json)中有该模块信息直接拿即可,如果没有则从仓库获取。如 packaeg.json 中某个包的版本是 ^1.1.0,npm 就会去仓库中获取符合 1.x.x 形式的最新版本。
- 获取模块实体。上一步会获取到模块的压缩包地址(resolved 字段),npm 会用此地址检查本地缓存,缓存中有就直接拿,如果没有则从仓库下载。
- 查找该模块依赖,如果有依赖则回到第1步,没有则停止。
-
安装模块,这一步将会更新工程中的
node_modules,并执行模块中的生命周期函数(按照 preinstall、install、postinstall 的顺序)。 -
执行工程自身生命周期,当前 npm 工程如果定义了钩子此时会被执行(按照 install、postinstall、prepublish、prepare 的顺序)。
最后一步是生成或更新版本描述文件,npm install 过程完成。
模块扁平化(dedupe)
网上有个段子,一个npm快递员:你的 node_modules 到了,一开门,哗啦一大堆的包
上一步获取到的是一棵完整的依赖树,其中可能包含大量重复模块。比如 A 模块依赖于 loadsh,B 模块同样依赖于 lodash。在 npm3 以前会严格按照依赖树的结构进行安装,因此会造成模块冗余。
从 npm3 开始默认加入了一个 dedupe 的过程。它会遍历所有节点,逐个将模块放在根节点下面,也就是 node-modules 的第一层。当发现有重复模块时,则将其丢弃。
这里需要对重复模块进行一个定义,它指的是模块名相同且 semver 兼容。每个 semver 都对应一段版本允许范围,如果两个模块的版本允许范围存在交集,那么就可以得到一个兼容版本,而不必版本号完全一致,这可以使更多冗余模块在 dedupe 过程中被去掉。
比如 node-modules 下 foo 模块依赖 lodash@^1.0.0,bar 模块依赖 lodash@^1.1.0,则 ^1.1.0 为兼容版本。
而当 foo 依赖 lodash@^2.0.0,bar 依赖 lodash@^1.1.0,则依据 semver 的规则,二者不存在兼容版本。会将一个版本放在 node_modules 中,另一个仍保留在依赖树里。
举个例子,假设一个依赖树原本是这样:
node_modules -- foo ---- lodash@version1
-- bar ---- lodash@version2
假设 version1 和 version2 是兼容版本,则经过 dedupe 会成为下面的形式:
node_modules -- foo
-- bar
-- lodash(保留的版本为兼容版本)
假设 version1 和 version2 为非兼容版本,则后面的版本保留在依赖树中:
node_modules -- foo -- lodash@version1
-- bar ---- lodash@version2
引用文章:
https://muyiy.cn/question/tool/20.html
小结
以上是 nodejs 相关的总结,后续遇到有代表性的题目还会继续补充。
文章中如有不对的地方,欢迎小伙伴们多多指正。
谢谢大家~