java I/O系统(8)-文件压缩
引言
我们对于日志的保存,如果需要存档,那么最好的方式就是对日志文件进行压缩。压缩可以减少资源占用,在需要的时候还能回溯查找。在本篇博文中,详细介绍基于字节流的压缩方式,着重介绍ZipOutputStream、ZipInputStream文件的压缩和解压方式,同时介绍CheckedInputStream、CheckedOutputStream的校验方式,在最后给出相应的demo供大家参考。笔者目前整理的一些blog针对面试都是超高频出现的。大家可以点击链接:http://blog.csdn.net/u012403290
源码在JDK的位置
文件压缩其实本质上也是属于IO操作,但是在JDK中并没有把这部分相关的流操作写入java.io包中。我们需要在java的工具包中:java.util.zip中找到他们:
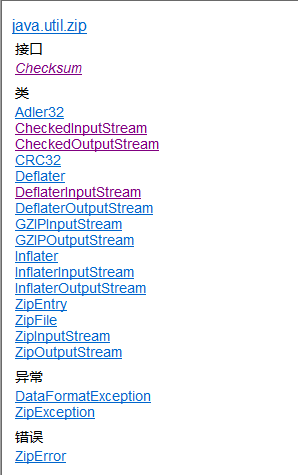
在本篇博文中就是对zip下的一些核心类进行介绍。其中已Stream结尾的就是涉及的IO字节流相关的类。
压缩家族结构
我们在起初介绍IO系统的时候给出了一个IO系统的结构图。就是下面这张:
其实在中间省略了一些流(因为并不常见),在这里补充一下涉及到文件压缩和文件一致性的相关流:
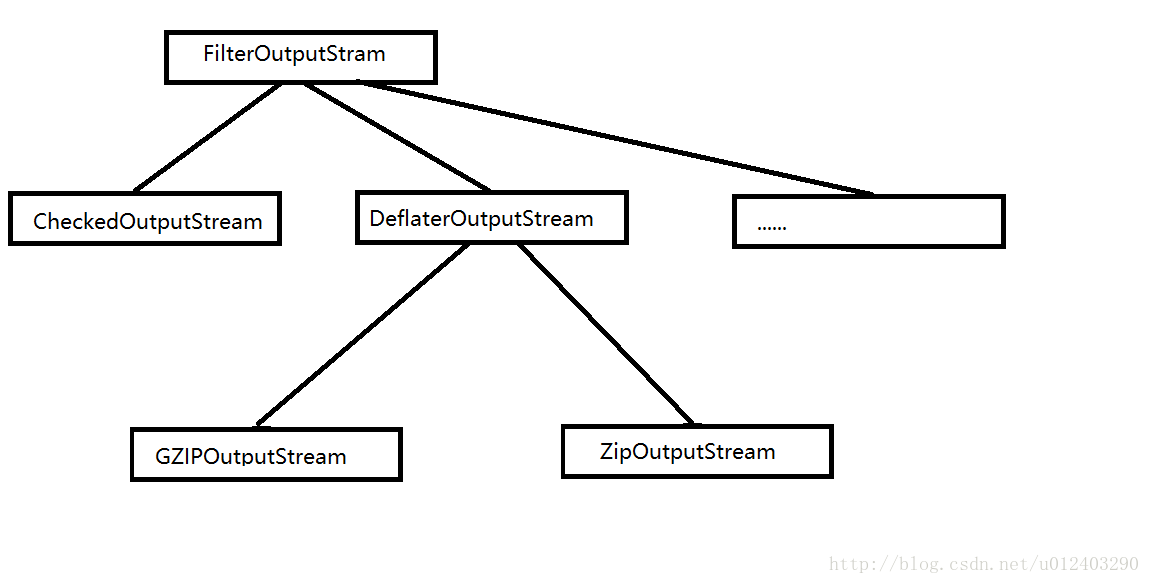
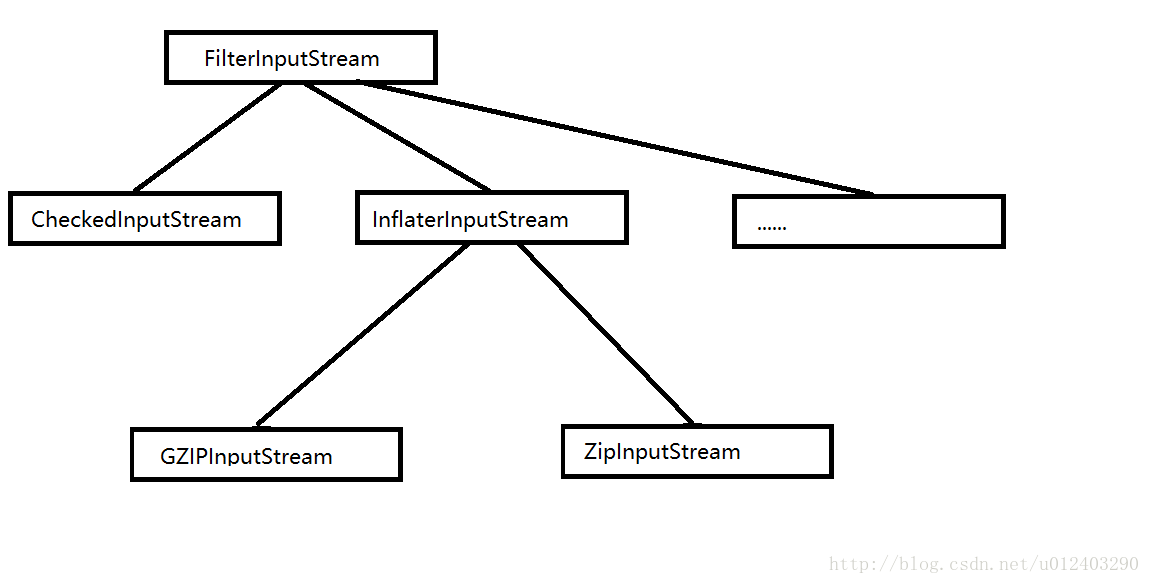
首先,文件压缩都是针对字节流的,所以在FilterInputStream装饰器下还存在相关的两个子类:CheckedInputStream与DeflaterInputStream,前者是用于保证文件在传输过程与存储过程中记录一个校验和(checksum)的值来保证数据的完整性,后者是压缩类的基类。相应的在FilterOutputStream装饰器下还存在两个对应相关的子类:CheckedOutputStream和DeflaterOutputStream类,功能和前面介绍的是一样的。在FileterInputStream和FilterOutputStream下存在着所有压缩的子类:zip压缩方式与Gzip压缩方式。图解它们之间的关系如下:
OutputStream:
InputStream:
值得一提的是,文件压缩是面向字节流的(已Stream结尾的类),但是如果在针对字符流的时候(reader和writer)我们需要用InputStreamReader和OutputStreamWriter进行转化。比如说如下:
BufferedReader reader = new BufferedReader(new InputStreamReader(new GZIPInputStream(new FileInputStream("filePath"))));上面的代码看上去会显得复杂,这也是装饰器模式的劣势,经过层层装饰之后结果会显得非常难理解。其实就是把字节流转换成字符流进行处理。
CheckedInputStream与CheckedOutputStream
校验字节流的核心功能是对文件能生产一个校验和,在我们进行远程数据传输和文件拷贝存储的时候,可以通过这种方式进行校验,比较两者的校验和(checkSum)是否一致,从而保证数据的一致性与完整性。
从上面的JDKapi中,我们可以看出校验方式有两种:Adler32和CRC32。其中Adler32运算效率要比CRC32要高一些,但是数据精准却不如CRC32。可以根据实际情况使用,一般来说可使用Adler32。
假如说,我们要对一个文件进行拷贝,那么我们先对拷贝之前计算它的校验和:
package com.brickworkers.io;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.zip.Adler32;
import java.util.zip.CheckedInputStream;
/**
*
* @author Brickworker
* Date:2017年5月23日下午4:02:00
* 关于类CheckSumTest.java的描述:获取文件的校验和
* Copyright (c) 2017, brcikworker All Rights Reserved.
*/
public class CheckSumTest {
public static void main(String[] args) throws IOException {
// 生成一个校验流
try (CheckedInputStream cs = new CheckedInputStream(new FileInputStream("F:/java/io/bw.txt"), new Adler32())) {
byte[] b = new byte[4096];
while ((cs.read(b)) != -1) {
}
System.out.println(cs.getChecksum().getValue());
}
}
}
//输出结果:
//3652824222
//
然后我们把文件拷贝的别的地方,并对它进行改名,不修改文件内部任何数据:
package com.brickworkers.io;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.zip.Adler32;
import java.util.zip.CheckedInputStream;
/**
*
* @author Brickworker
* Date:2017年5月23日下午4:02:00
* 关于类CheckSumTest.java的描述:获取文件的校验和
* Copyright (c) 2017, brcikworker All Rights Reserved.
*/
public class CheckSumTest {
public static void main(String[] args) throws IOException {
// 生成一个校验流
try (CheckedInputStream cs = new CheckedInputStream(new FileInputStream("F:/python/bw1.txt"), new Adler32())) {
byte[] b = new byte[4096];
while ((cs.read(b)) != -1) {
}
System.out.println(cs.getChecksum().getValue());
}
}
}
//输出结果:
//3652824222
//
只要文件内部数据没有被修改,那么它的校验和是一样的,同时说明文件命名被不在校验和的计算之中。
有些小伙伴就有疑问了,你这样做显得好没有意义啊。为了计算一个文件的校验和还需要把文件从头到尾读取一遍?
如果有这样的疑问,说明IO系统已经学到了有一定的基础了。check流其实是在装饰器基类Filter流之下,那么我们可以给任何一种流赋予这种计算校验和的能力。这也是装饰器模式可以层层装饰的厉害之处。比如说我在对文件进行压缩的时候顺带计算校验和,其实并不需要独立的让check流主动去读取一遍数据,你只需要这样写:
CheckedInputStream cs = new CheckedInputStream(new FileInputStream("F:/python/bw1.txt"), new Adler32());
ZipInputStream zs = new ZipInputStream(cs);那么你的核心对象就变成了ZipInputStream,在zs读取的过程中其实也就在计算校验和了。
ZipInputStream与ZipOutputStream文件压缩解压
接下来说一说核心的文章压缩,首先我们介绍文件压缩过程:
①文件压缩
// 文件压缩方法
public static void compress(String fromFilePath, String toFilePath) throws IOException {
File file = new File(fromFilePath);
try (
// 指定文件压缩输出流
ZipOutputStream zs = new ZipOutputStream(new FileOutputStream(new File(toFilePath)))) {
checkFile(file, zs, file.getName());
} catch (Exception e) {
e.printStackTrace();
}
}
private static void checkFile(File file, ZipOutputStream zs, String filename) throws FileNotFoundException, IOException {
FileInputStream fs;
if(file.isDirectory()){
//如果是文件夹需要遍历压缩
//获得文件集合
File[] files = file.listFiles();
//遍历
for(int i = 0; i < files.length; i++){
//对命名进一步叠加
checkFile(files[i], zs, filename + File.separator + files[i].getName());
}
}else{
fs = new FileInputStream(file);
// 把压缩文件的档案传递给ZipEntry对象.
// ZipEntry可以管理所有压缩文件,在解压的时候可以根据ZipEntry的值进行解压
zs.putNextEntry(new ZipEntry(filename));
// 开始压缩
// 从输入流读取,逐个字节写入输出流
int c = 0;
while ((c = fs.read()) != -1) {
zs.write(c);
}
}
}
上面这段代码就是对文件进行压缩,基本上所有的操作都是基本流的操作。在压缩前先判断要压缩的文件是文件夹还是单个文件,如果是文件夹,那么需要遍历文件夹下的所有文件,如果是单个文件,那么直接开始压缩。但是压缩的过程中核心要记得的是ZipOutputStream.putNextEntry这个方法,在ZipEntry对象中存在着许多重要的方法,同时ZipEntry在我们解压的时候有着至关重要的作用,它将直接导致压缩后的文件层次的正确性。
迭代方法已经脱离出来了,通常的,在eclipse中我都是用refactor->Extract Method直接自动把局部代码生成为一个独立的方法。在这个递归方法中,我们核心要注意两点:判断文件是否为目录;文件目录层次剖析,也就是前面描述的filename。
②解压文件
解压文件操作相对于压缩文件操作来说会显得简单很多。因为压缩文件中不存在是否文件夹的判断,每一个都是指定了的具体文件:
public static void deCompress(String fromFilePath, String toFilePath) throws FileNotFoundException, IOException{
//压缩文件中详细层次文件
ZipEntry entry;
//输出流
FileOutputStream fs;
//用Zip流获取压缩文件
try(ZipInputStream zs = new ZipInputStream(new FileInputStream(new File(fromFilePath)))){
//直接遍历zip输入流中的ZipEntry
while((entry = zs.getNextEntry()) != null){
//指定这个压缩文件中的文件的准确输出路径
//需要先修复文件的父级目录
File currentFile = new File(toFilePath + File.separator + entry.getName());
if(!currentFile.getParentFile().exists()){
//mkdirs可以保证父级文件夹不存在一并创建
currentFile.getParentFile().mkdirs();
}
//然后处理当前文件
if(!currentFile.exists()){
currentFile.createNewFile();
}
fs = new FileOutputStream(currentFile);
int c;
while((c = zs.read()) != -1){
fs.write(c);
}
}
}
}以上就是对文件的压缩处理方式。不过这里有一个缺陷必须和大家说明,和git的submit方式一样,当文件夹中的数据为空的时候,压缩结果会导致解压后数据不存在。不过这个也是可以解决的。
希望对你有所帮助