区块链核心技术:拜占庭共识算法之PBFT
区块链核心技术:拜占庭共识算法之PBFT
PBFT是Practical Byzantine Fault Tolerance的缩写,意为实用拜占庭容错算法。该算法是Miguel Castro (卡斯特罗)和Barbara Liskov(利斯科夫)在1999年提出来的,解决了原始拜占庭容错算法效率不高的问题,将算法复杂度由指数级降低到多项式级,使得拜占庭容错算法在实际系统应用中变得可行。该论文发表在1999年的操作系统设计与实现国际会议上(OSDI99)。没错,这个Loskov就是提出著名的里氏替换原则(LSP)的人,2008年图灵奖得主。
摘要部分
OSDI99这篇论文描述了一种副本复制(replication)算法解决拜占庭容错问题。作者认为拜占庭容错算法将会变得更加重要,因为恶意攻击和软件错误的发生将会越来越多,并且导致失效的节点产生任意行为。(拜占庭节点的任意行为有可能误导其他副本节点产生更大的危害,而不仅仅是宕机失去响应。)而早期的拜占庭容错算法或者基于同步系统的假设,或者由于性能太低而不能在实际系统中运作。这篇论文中描述的算法是实用的,因为该算法可以工作在异步环境中,并且通过优化在早期算法的基础上把响应性能提升了一个数量级以上。作者使用这个算法实现了拜占庭容错的网络文件系统(NFS),性能测试证明了该系统仅比无副本复制的标准NFS慢了3%。
1.概要介绍
第一段大片废话就是说明拜占庭算法越来越重要了,然后说这篇论文提出解决拜占庭容错的状态机副本复制(state machine replication)算法。这个算法在保证活性和安全性(liveness & safety)的前提下提供了(n-1)/3的容错性。从Lamport教授在1982年提出拜占庭问题开始,已经有一大堆算法去解决拜占庭容错了。但是一句话概括:这些算法都是狗屎!PBFT算法跟这些妖艳贱货完全不同,在只读操作中只使用1次消息往返(message round trip),在只写操作中只使用2次消息往返,并且在正常操作中使用了消息验证编码(Message Authentication Code,简称MAC),而造成妖艳贱货性能低下的公钥加密(public-key cryptography)只在发生失效的情况下使用。作者不仅提出算法,而且使用这个算法实现了一个牛逼的系统(拜占庭容错的NFS),反正性能杠杠的。
作者先炫耀一下这边论文的贡献亮瞎你们的狗眼:
1)首次提出在异步网络环境下使用状态机副本复制协议
2)使用多种优化使性能显著提升
3)实现了一种拜占庭容错的分布式文件系统
4)为副本复制的性能损耗提供试验数据支持
2.系统模型
这部分主要对节点行为和网络环境进行剧情设定,然后赋予了消息的加密属性,最后对大魔王的能力进行设定。
系统假设为异步分布式的,通过网络传输的消息可能丢失、延迟、重复或者乱序。作者假设节点的失效必须是独立发生的,也就是说代码、操作系统和管理员密码这些东西在各个节点上是不一样的。(那么如果节点失效不独立发生,PBFT算法就失效了吗?)
作者使用了加密技术来防止欺骗攻击和重播攻击,以及检测被破坏的消息。消息包含了公钥签名(其实就是RSA算法)、消息验证编码(MAC)和无碰撞哈希函数生成的消息摘要(message digest)。使用m表示消息,mi表示由节点i签名的消息,D(m)表示消息m的摘要。按照惯例,只对消息的摘要签名,并且附在消息文本的后面。并且假设所有的节点都知道其他节点的公钥以进行签名验证。
系统允许大魔王可以操纵多个失效节点、延迟通讯、甚至延迟正确节点来毁灭世界。但是作者限定大魔王不能无限期地延迟正确的节点,并且大魔王算力有限不能破解加密算法。例如,大魔王不能伪造正确节点的有效签名,不能从摘要数据反向计算出消息内容,或者找到两个有同样摘要的消息。
3.服务属性
这部分描述了副本复制服务的特性
论文算法实现的是一个具有确定性的副本复制服务,这个服务包括了一个状态(state)和多个操作(operations)。这些操作不仅能够进行简单读写,而且能够基于状态和操作参数进行任意确定性的计算。客户端向副本复制服务发起请求来执行操作,并且阻塞以等待回复。副本复制服务由n个节点组成。
针对安全性
算法在失效节点数量不超过(n-1)/3的情况下同时保证安全性和活性(safety & liveness)。安全性是指副本复制服务满足线性一致性(linearizability),就像中心化系统一样原子化执行操作。安全性要求失效副本的数量不超过上限,但是对客户端失效的数量和是否与副本串谋不做限制。系统通过访问控制来限制失效客户端可能造成的破坏,审核客户端并阻止客户端发起无权执行的操作。同时,服务可以提供操作来改变一个客户端的访问权限。因为算法保证了权限撤销操作可以被所有客户端观察到,这种方法可以提供强大的机制从失效的客户端攻击中恢复。
针对活性
算法不依赖同步提供安全性,因此必须依靠同步提供活性。否则,这个算法就可以被用来在异步系统中实现共识,而这是不可能的(由Fischer1985的论文证明)。本文的算法保证活性,即所有客户端最终都会收到针对他们请求的回复,只要失效副本的数量不超过(n-1)/3,并且延迟delay(t)不会无限增长。这个delay(t)表示t时刻发出的消息到它被目标最终接收的时间间隔,假设发送者持续重传直到消息被接收。这时一个相当弱的同步假设,因为在真实系统中网络失效最终都会被修复。但是这就规避了Fischer1985提出的异步系统无法达成共识的问题。
下面这段话是关键
本文的算法弹性是达到最优的:当存在f个失效节点时必须保证存在至少3f+1
个副本数量,这样才能保证在异步系统中提供安全性和活性。这么多数量的副本是需要的,因为在同n-f个节点通讯后系统必须做出正确判断,由于f个副本有可能失效而不发回响应。但是,有可能f个没有失效的副本不发回响应(是因为网络延迟吗?),因此f个发回响应的副本有可能是失效的。尽管如此,系统仍旧需要足够数量非失效节点的响应,并且这些非失效节点的响应数量必须超过失效节点的响应数量,即n-2f>f,因此得到n>3f。
算法不能解决信息保密的问题,失效的副本有可能将信息泄露给攻击者。在一般情况下不可能提供信息保密,因为服务操作需要使用参数和服务状态处理任意的计算,所有的副本都需要这些信息来有效执行操作。当然,还是有可能在存在恶意副本的情况下通过秘密分享模式(secret sharing scheme)来实现私密性,因为参数和部分状态对服务操作来说是不可见的。
4.算法
PBFT是一种状态机副本复制算法,即服务作为状态机进行建模,状态机在分布式系统的不同节点进行副本复制。每个状态机的副本都保存了服务的状态,同时也实现了服务的操作。将所有的副本组成的集合使用大写字母R表示,使用0到|R|-1的整数表示每一个副本。为了描述方便,假设|R|=3f+1,这里f是有可能失效的副本的最大个数。尽管可以存在多于3f+1个副本,但是额外的副本除了降低性能之外不能提高可靠性。
PBFT的剧情缓缓展开,首先介绍舞台(view)、演员(replica)和角色(primary、backups)
所有的副本在一个被称为视图(View)的轮换过程(succession of configuration)中运作。在某个视图中,一个副本作为主节点(primary),其他的副本作为备份(backups)。视图是连续编号的整数。主节点由公式p = v mod |R|计算得到,这里v是视图编号,p是副本编号,|R|是副本集合的个数。当主节点失效的时候就需要启动视图更换(view change)过程。Viewstamped Replication算法和Paxos算法就是使用类似方法解决良性容错的。
PBFT算法的狗血剧情如下:
1.客户端向主节点发送请求调用服务操作
2.主节点通过广播将请求发送给其他副本
3.所有副本都执行请求并将结果发回客户端
4.客户端需要等待f+1个不同副本节点发回相同的结果,作为整个操作的最终结果。
同所有的状态机副本复制技术一样,PBFT对每个副本节点提出了两个限定条件:(1)所有节点必须是确定性的。也就是说,在给定状态和参数相同的情况下,操作执行的结果必须相同;(2)所有节点必须从相同的状态开始执行。在这两个限定条件下,即使失效的副本节点存在,PBFT算法对所有非失效副本节点的请求执行总顺序达成一致,从而保证安全性。
接下去描述简化版本的PBFT算法,忽略磁盘空间不足和消息重传等细节内容。并且,本文假设消息验证过程是通过数字签名方法实现的,而不是更加高效的基于消息验证编码(MAC)的方法。
4.1客户端
客户端c向主节点发送
每个由副本节点发给客户端的消息都包含了当前的视图编号,使得客户端能够跟踪视图编号,从而进一步推算出当前主节点的编号。客户端通过点对点消息向它自己认为的主节点发送请求,然后主节点自动将该请求向所有备份节点进行广播。
副本发给客户端的响应为
客户端等待f+1个从不同副本得到的同样响应,同样响应需要保证签名正确,并且具有同样的时间戳t和执行结果r。这样客户端才能把r作为正确的执行结果,因为失效的副本节点不超过f个,所以f+1个副本的一致响应必定能够保证结果是正确有效的。
如果客户端没有在有限时间内收到回复,请求将向所有副本节点进行广播。如果请求已经在副本节点处理过了,副本就向客户端重发一遍执行结果。如果请求没有在副本节点处理过,该副本节点将把请求转发给主节点。如果主节点没有将该请求进行广播,那么就有认为主节点失效,如果有足够多的副本节点认为主节点失效,则会触发一次视图变更。
本文假设客户端会等待上一个请求完成才会发起下一个请求,但是只要能够保证请求顺序,可以允许请求是异步的。
4.2 PBFT算法主线流程(正常情况)
世界格局
每个副本节点的状态都包含了服务的整体状态,副本节点上的消息日志(message log)包含了该副本节点接受(accepted)的消息,并且使用一个整数表示副本节点的当前视图编号。
事件的导火索
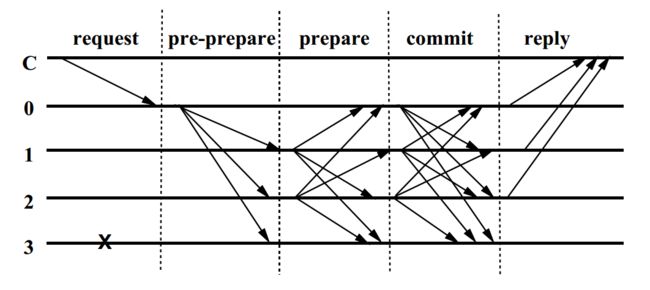
当主节点p收到客户端的请求m,主节点将该请求向所有副本节点进行广播,由此一场轰轰烈烈的三阶段协议(three-phase protocol)拉开了序幕。在这里,至于什么消息过多需要缓存的情况我们就不管了,这不是重点。
三个阶段的任务
我们重点讨论预准备(pre-prepare)、准备(prepare)和确认(commit)这三个历史性阶段。预准备和准备两个阶段用来确保同一个视图中请求发送的时序性(即使对请求进行排序的主节点失效了),准备和确认两个阶段用来确保在不同的视图之间的确认请求是严格排序的。
预准备阶段
在预准备阶段,主节点分配一个序列号n给收到的请求,然后向所有备份节点群发预准备消息,预准备消息的格式为<,这里v是视图编号,m是客户端发送的请求消息,d是请求消息m的摘要。
请求本身是不包含在预准备的消息里面的,这样就能使预准备消息足够小,因为预准备消息的目的是作为一种证明,确定该请求是在视图v中被赋予了序号n,从而在视图变更的过程中可以追索。另外一个层面,将“请求排序协议”和“请求传输协议”进行解耦,有利于对消息传输的效率进行深度优化。
备份节点对预准备消息的态度
只有满足以下条件,各个备份节点才会接受一个预准备消息:
- 请求和预准备消息的签名正确,并且d与m的摘要一致。
- 当前视图编号是v。
- 该备份节点从未在视图v中接受过序号为n但是摘要d不同的消息m。(许仙在这辈子从未见过名字叫白素贞的美貌女子)
- 预准备消息的序号n必须在水线(watermark)上下限h和H之间。
水线存在的意义在于防止一个失效节点使用一个很大的序号消耗序号空间。
进入准备阶段
如果备份节点i接受了预准备消息<,则进入准备阶段。在准备阶段的同时,该节点向所有副本节点发送准备消息
接受准备消息需要满足的条件
包括主节点在内的所有副本节点在收到准备消息之后,对消息的签名是否正确,视图编号是否一致,以及消息序号是否满足水线限制这三个条件进行验证,如果验证通过则把这个准备消息写入消息日志中。
准备阶段完成的标志
我们定义准备阶段完成的标志为副本节点i将(m,v,n,i)记入其消息日志,其中m是请求内容,预准备消息m在视图v中的编号n,以及2f个从不同副本节点收到的与预准备消息一致的准备消息。每个副本节点验证预准备和准备消息的一致性主要检查:视图编号v、消息序号n和摘要d。
预准备阶段和准备阶段确保所有正常节点对同一个视图中的请求序号达成一致。接下去是对这个结论的形式化证明:如果prepared(m,v,n,i)为真,则prepared(m',v,n,j)必不成立,这就意味着至少f+1个正常节点在视图v的预准备或者准备阶段发送了序号为n的消息m。
进入确认阶段
当(m,v,n,i)条件为真的时候,副本i将
接受确认消息需要满足的条件
我们定义确认完成committed(m,v,n)为真得条件为:任意f+1个正常副本节点集合中的所有副本i其prepared(m,v,n,i)为真;本地确认完成committed-local(m,v,n,i)为真的条件为:prepared(m,v,n,i)为真,并且i已经接受了2f+1个确认(包括自身在内)与预准备消息一致。确认与预准备消息一致的条件是具有相同的视图编号、消息序号和消息摘要。
确认被接受的形式化描述
确认阶段保证了以下这个不变式(invariant):对某个正常节点i来说,如果committed-local(m,v,n,i)为真则committed(m,v,n)也为真。这个不变式和视图变更协议保证了所有正常节点对本地确认的请求的序号达成一致,即使这些请求在每个节点的确认处于不同的视图。更进一步地讲,这个不变式保证了任何正常节点的本地确认最终会确认f+1个更多的正常副本。
故事的终结
每个副本节点i在committed-local(m,v,n,i)为真之后执行m的请求,并且i的状态反映了所有编号小于n的请求依次顺序执行。这就确保了所有正常节点以同样的顺序执行所有请求,这样就保证了算法的正确性(safety)。在完成请求的操作之后,每个副本节点都向客户端发送回复。副本节点会把时间戳比已回复时间戳更小的请求丢弃,以保证请求只会被执行一次。
我们不依赖于消息的顺序传递,因此某个副本节点可能乱序确认请求。因为每个副本节点在请求执行之前已经将预准备、准备和确认这三个消息记录到了日志中,这样乱序就不成问题了。(为什么?)
下图展示了在没有发生主节点失效的情况下算法的正常执行流程,其中副本0是主节点,副本3是失效节点,而C是客户端。
4.3 垃圾回收
为了节省内存,系统需要一种将日志中的无异议消息记录删除的机制。为了保证系统的安全性,副本节点在删除自己的消息日志前,需要确保至少f+1个正常副本节点执行了消息对应的请求,并且可以在视图变更时向其他副本节点证明。另外,如果一些副本节点错过部分消息,但是这些消息已经被所有正常副本节点删除了,这就需要通过传输部分或者全部服务状态实现该副本节点的同步。因此,副本节点同样需要证明状态的正确性。
在每一个操作执行后都生成这样的证明是非常消耗资源的。因此,证明过程只有在请求序号可以被某个常数(比如100)整除的时候才会周期性地进行。我们将这些请求执行后得到的状态称作检查点(checkpoint),并且将具有证明的检查点称作稳定检查点(stable checkpoint)。
副本节点保存了服务状态的多个逻辑拷贝,包括最新的稳定检查点,零个或者多个非稳定的检查点,以及一个当前状态。写时复制技术可以被用来减少存储额外状态拷贝的空间开销。
检查点的正确性证明的生成过程如下:当副本节点i生成一个检查点后,向其他副本节点广播检查点消息
个消息就是这个检查点的正确性证明。
具有证明的检查点成为稳定检查点,然后副本节点就可以将所有序号小于等于n的预准备、准备和确认消息从日志中删除。同时也可以将之前的检查点和检查点消息一并删除。
检查点协议可以用来更新水线(watermark)的高低值(h和H),这两个高低值限定了可以被接受的消息。水线的低值h与最近稳定检查点的序列号相同,而水线的高值H=h+k,k需要足够大才能使副本不至于为了等待稳定检查点而停顿。加入检查点每100个请求产生一次,k的取值可以是200。
4.4 视图变更,改朝换代
使用计时器的超时机制触发视图变更事件
视图变更协议在主节点失效的时候仍然保证系统的活性。视图变更可以由超时触发,以防止备份节点无期限地等待请求的执行。备份节点等待一个请求,就是该节点接收到一个有效请求,但是还没有执行它。当备份节点接收到一个请求但是计时器还未运行,那么它就启动计时器;当它不再等待请求的执行就把计时器停止,但是当它等待其他请求执行的时候再次情动计时器。