java源码分析---String、StringBuffer、StringBuilder探索
String、StringBuffer、StringBuilder探索
String源码解析在这片博文中我们解析了String相关的构造方法和常用方法,既然有了String类,为何还要有StringBuffer和StringBuilder类呢?
首先我们先看一段代码:
public class StringTest {
public static void main(String[] args) {
StringBuilder stringBuilder = new StringBuilder();
for(int i=0;i<10000;i++){
stringBuilder.append("hello");
}
}
}这句 string += “hello”;的过程相当于将原有的string变量指向的对象内容取出与”hello”作字符串相加操作再存进另一个新的String对象当中,再让string变量指向新生成的对象。如果大家还有疑问可以反编译其字节码文件便清楚了。反编译后的代码:
public class StringTest {
public StringTest() {
}
public static void main(String[] args) {
StringBuilder stringBuilder = new StringBuilder();
for(int i = 0; i < 10000; ++i) {
stringBuilder.append("hello");
}
}
}并且new操作只进行了一次,也就是说只生成了一个对象,append操作是在原有对象的基础上进行的。因此在循环了10000次之后,这段代码所占的资源要比上面小得多。
那么有人会问既然有了StringBuilder类,为什么还需要StringBuffer类?查看源代码便一目了然,事实上,StringBuilder和StringBuffer类拥有的成员属性以及成员方法基本相同,区别是StringBuffer类的成员方法前面多了一个关键字:synchronized,不用多说,这个关键字是在多线程访问时起到安全保护作用的,也就是说StringBuffer是线程安全的。
下面摘录了一些常见的面试题:
下面是一些常见的关于String、StringBuffer的一些面试笔试题,若有不正之处,请谅解和批评指正。
1. 下面这段代码的输出结果是什么?
String a = “hello2″; String b = “hello” + 2; System.out.println((a == b));输出结果为:true。原因很简单,”hello”+2在编译期间就已经被优化成”hello2″,因此在运行期间,变量a和变量b指向的是同一个对象。
2.下面这段代码的输出结果是什么?
String a = “hello2″; String b = “hello”; String c = b + 2; System.out.println((a == c));输出结果为:false。由于有符号引用的存在,所以 String c = b + 2;不会在编译期间被优化,不会把b+2当做字面常量来处理的,因此这种方式生成的对象事实上是保存在堆上的。因此a和c指向的并不是同一个对象。
3.下面这段代码的输出结果是什么?
String a = “hello2″; final String b = “hello”; String c = b + 2; System.out.println((a == c));输出结果为:true。对于被final修饰的变量,会在class文件常量池中保存一个副本,也就是说不会通过连接而进行访问,对final变量的访问在编译期间都会直接被替代为真实的值。那么String c = b + 2;在编译期间就会被优化成:String c = “hello” + 2;
4.下面这段代码输出结果为:
public class StringTest {
public static void main(String[] args) {
String a = "hello2";
final String b = getHello();
String c = b + 2;
System.out.println((a == c));
}
public static String getHello() {
return "hello";
}
}输出结果为false。这里面虽然将b用final修饰了,但是由于其赋值是通过方法调用返回的,那么它的值只能在运行期间确定,因此a和c指向的不是同一个对象。
5.下面这段代码的输出结果是什么?
public class StringTest {
public static void main(String[] args) {
String a = "hello";
String b = new String("hello");
String c = new String("hello");
String d = b.intern();
System.out.println(a==b);
System.out.println(b==c);
System.out.println(b==d);
System.out.println(a==d);
}
}输出结果为(JDK版本 jdk1.8.0_152):
false
false
false
true
这里面涉及到的是String.intern方法的使用。在String类中,intern方法是一个本地方法,在JAVA SE6之前,intern方法会在运行时常量池中查找是否存在内容相同的字符串,如果存在则返回指向该字符串的引用,如果不存在,则会将该字符串入池,并返回一个指向该字符串的引用。因此,a和d指向的是同一个对象。
6.String str = new String(“abc”)创建了多少个对象?
这个问题在很多书籍上都有说到比如《Java程序员面试宝典》,包括很多国内大公司笔试面试题都会遇到,大部分网上流传的以及一些面试书籍上都说是2个对象,这种说法是片面的。
如果有不懂得地方可以参考这篇帖子:
http://rednaxelafx.iteye.com/blog/774673/
首先必须弄清楚创建对象的含义,创建是什么时候创建的?这段代码在运行期间会创建2个对象么?毫无疑问不可能,用javap -c反编译即可得到JVM执行的字节码内容:
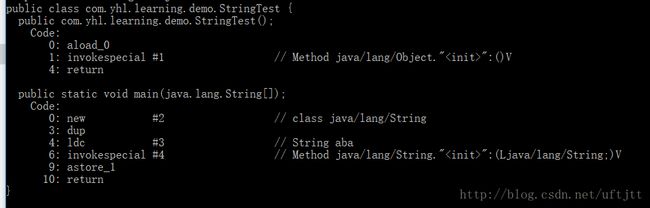
很显然,new只调用了一次,也就是说只创建了一个对象。
而这道题目让人混淆的地方就是这里,这段代码在运行期间确实只创建了一个对象,即在堆上创建了”abc”对象。而为什么大家都在说是2个对象呢,这里面要澄清一个概念 该段代码执行过程和类的加载过程是有区别的。在类加载的过程中,确实在运行时常量池中创建了一个”abc”对象,而在代码执行过程中确实只创建了一个String对象。
因此,这个问题如果换成 String str = new String(“abc”)涉及到几个String对象?合理的解释是2个。
个人觉得在面试的时候如果遇到这个问题,可以向面试官询问清楚”是这段代码执行过程中创建了多少个对象还是涉及到多少个对象“再根据具体的来进行回答。
7.下面这段代码1)和2)的区别是什么?
public class Main {
public static void main(String[] args) {
String str1 = "I";
//str1 += "love"+"java"; 1)
str1 = str1+"love"+"java"; //2)
}
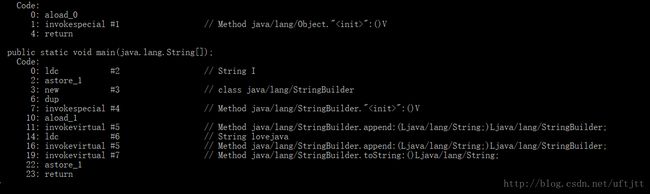
}1)的效率比2)的效率要高,1)中的”love”+”java”在编译期间会被优化成”lovejava”,而2)中的不会被优化。下面是两种方式的字节码:
1)的字节码:
2)的字节码:
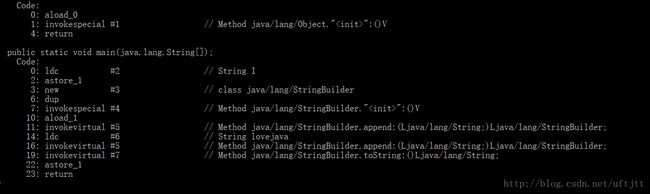
在jdk1.8下查看两个方式的字节码是相同的,看来1.8已经进行了优化