姜健:VP9可适性视频编码(SVC)新特性

与VP8相比,VP9进行了大量的设计改进以尽可能的获得更高的视频编码质量。Google软件工程师 姜健详细介绍了VP9可适性视频编码(SVC)中多种新功能的实现与相应API。本文来自姜健在LiveVideoStack 线上交流分享,并由LiveVideoStack整理而成。
文 / 姜健
整理 / LiveVideoStack
直播回放
https://www2.tutormeetplus.com/v2/render/playback?mode=playback&token=e9d457fedba34b69844f3cba29345704
大家好,我是来自Google的姜健,今天主要想给大家分享一下我们在VP9 SVC里新加的一些功能,以及一些相应API的设置,整体上会比较偏向技术一点。
分享的主要内容包括以下几个方面:
1、 介绍VP9 SVC;
2、 对比SVC和VP8的一些参数;
3、 SVC中去噪功能的实现;
一、SVC (Scalable Video Coding) in VP9
首先向大家提出一个问题,我们为什么要用SVC?常用的视频编码难道不可以吗?当我们进行视频会议时,可能会有多方的参与者。如果其中一方参与者的网络状况不是很好,在不采用SVC编码时,则只有一个分辨率,包括空间和时间分辨率。这时,需要根据网络情况不太好的参与者来进行丢包,或者降低空间分辨率来适应其网络状况。又因为每个参与者收到的包都是一样的,这样其他网络情况好的参与者也就会同时受到影响。但是在采用SVC编码的情况下,我们就可以很好的解决这个问题。SVC可以编码不同的分辨率,服务器在分发的时候,它可以根据不同接收者的网络情况对应分发高分辨率或低分辨率的帧,当有参与者的网络情况不好时,就接受低分辨率的帧。这样一来,其他网络情况好的参与者可以不受影响的接收高分辨率的视频帧。
目前VP9 SVC仍在WebRTC中不断的改进,特别是对于屏幕分享的一些参数。Google正在进行Dogfood,意思就是指大规模的内测。因为Google本身有九万多名员工,我们依靠自己员工的力量来进行内测,员工们如果有什么问题,也可以及时向我们提交一些反馈,以便于进行修改。当内测进行几个月之后,就会把它开放给公众,后面会介绍一下我们在Dogfood中接收到的一些反馈和问题。

今天会主要介绍VP9 SVC的几种Feature。首先会给大家介绍一下SVC的参考帧预测,因为SVC包含空间和时间上的不同分辨率,所以在参考帧的预测上会有很大的区别。我们还添加了一些特殊的Feature,比如帧内编码帧,但是这个帧不是关键帧。另外,SVC的预测模式固定之后是可以更改的,即可以在编码的过程中,随时修改预测模式。还有一个就是我们最近加入的长时间尺度的编码帧预测,最后则是去噪部分。
1、SVC Superframe
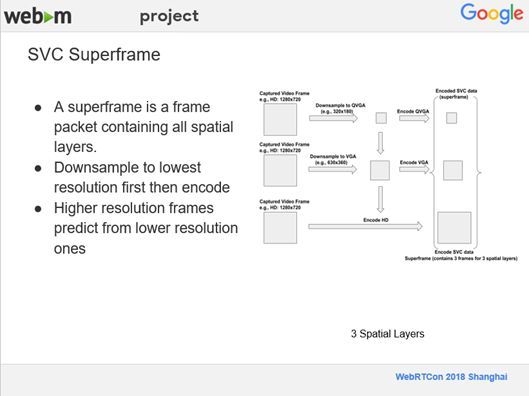
在这里给大家介绍一下SVC中是如何实现将不同分辨率的帧放在一起的。上图的例子中包含三个不同空间分辨率的帧,在SVC里面,不同的层有不同的分辨率,这个例子中有三个不同的层即三个不同的分辨率。假如相机捕捉到的是一个高清720P的帧,首先我们把最上层720P的帧4×4 Scale Down到180P,然后对其进行编码。把中间层720P的帧2×2 Scale Down到VGA 360P,再对它进行编码。最后,我们再编码HD 720P的帧,编码结束之后,再把编码后的三个帧放在一起,我们称之为超级帧(Superframe)。
2、SVC Patterns - 2 Spatial Layers, 3 Temporal Layers
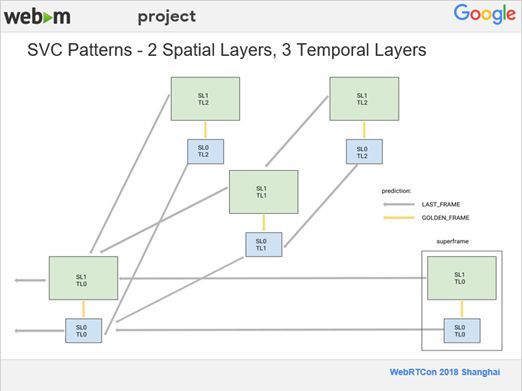
上图是一个预测的例子,模式会稍微复杂一点,它把空间分辨率分为两层(SL0、SL1),时间分辨率分为三层(TL0、TL1、TL2),不同的时间分辨率相当于不同的帧率。在视频流里,编码速率是60帧/秒,时间分辨率TL2占了一半,即30 FPS,时间分辨率TL1占了1/4,即15FPS,最后一层TL0也是15FPS。在这个预测模式中,灰色的箭头代表LAST FRAME,它表示当前编码帧的前一帧;金色的箭头代表GOLDEN FRAME,在非SVC的定义为很早之前的一个帧,可能是第10帧、第20帧、第30帧,然后从它开始预测。但是,在SVC里面,我们改变了它的定义,GOLDEN FRAME表示是从更低分辨率的那一层去预测。在后面的预测过程中,我们会一直重复这样的一个模式。对比非SVC,在整个预测过程中,都是采用的离得最近的帧,包括LAST FRAME为当前编码帧的前一帧,在GOLDEN FRAME我们采用从更低分辨率的那一层去预测,而没有采用长时间的帧来预测,为了解决这一问题,我们后面又引入了一个新的Feature。
3、SVC Reference frame buffer and refresh

由于我们用了LAST FRAME和GOLDEN FRAME这些参考帧,所以在更新参考帧的Buffer时,SVC会比较复杂一些。在前面我们了解到它的Pattern是非常复杂的,在进行帧的预测时,可能会被多个其它的帧用做预测,因此,这一帧会一直放在参考帧的Buffer里面,留着以后才能用到。在Buffer的更新上面,我们还要用到另外一个概念叫ALTREF,ALTREF在非SVC里指的是未来的某一帧,我们会从未来的某一帧来进行预测,这个是在做两遍的压缩时会用到的。但是,实时视频编码是不可能用到未来帧的,所以在SVC中,我们将ALTREF当成一个Marker,用来指定更新哪一个参考帧的哪一个Buffer。在VP9里面一共有8个Buffer可以当成参考帧来用,大家可以看到,在这里我们现在只是用了4个而已。为了解决在SVC里没有从长时间的某一帧来预测的问题,后面我们还会再用到另外一个Buffer。
4、SVC Interlayer Prediction
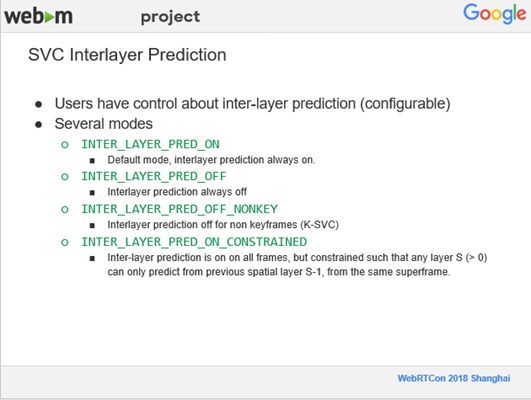
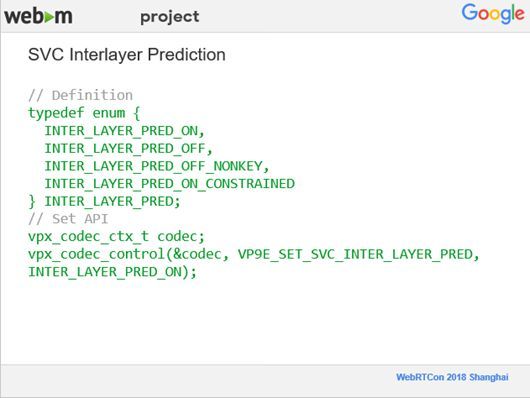
接下来介绍一下我们在不同分辨率帧之间进行预测添加的控制,如果你是用户,就可以通过API来控制不同帧的不同分辨率之间的预测是否开启。还有就是我们可以控制在非关键帧上关闭预测,在关键帧上开启不同分辨率帧之间的预测,这个在WebRTC里是用control prediction来设置的。这个API比较简单,下面这张图就是它的一些定义的类型。
5、SVC Frame Dropping
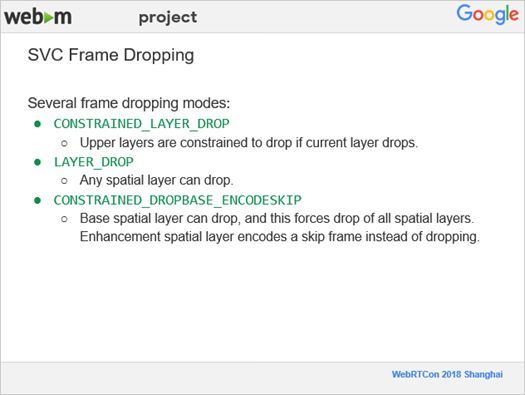
下面我来讲一下SVC的丢帧过程。在非SVC里,某一帧丢掉就丢掉了,但是在SVC里由于一个超级帧里面有三个不同分辨率的帧,在丢帧时,则要考虑是丢整个帧,或者只丢掉其中的某些层。就像在前面第一个Feature讲的一样,我们因为控制不同层之间的预测,如果不同的层之间没有相互依赖的关系,当丢掉最高分辨率的层,也可以进行解码。如果不同帧互相之间是有依赖的,那么在丢最低分辨率层的时候,必须把最高分辨率层一起丢掉,否则就解不出来。我们现在有三个不同的设置,第一个设置就是更低分辨率的帧丢掉之后,更高分辨率的帧也就直接丢掉,这种情况适用于不同空间分辨率的帧之间互相有依赖的情况。第二个设置是任何一个空间分辨率的帧都可以随便丢,这种情况是不同分辨率的帧之间没有相互依赖的关系。第三个设置就是最低分辨率的帧可以丢,在最低分辨率的帧丢掉之后,整个超级帧都一起丢掉。这个跟第一个有点类似,它们有交叉的情况。下面给出的就是一个控制丢帧的API。
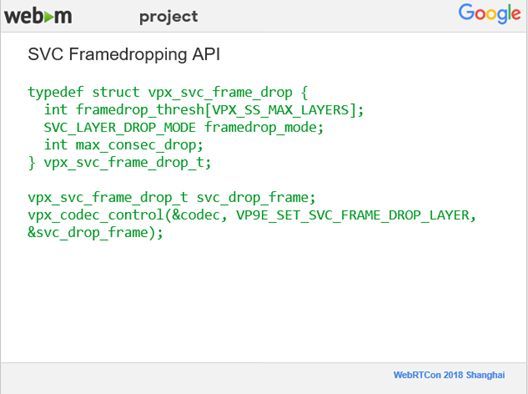
这个API稍微复杂一点,因为丢帧依赖于一些在压缩过程中的参数。第一个是阈值,阈值是针对于每一个空间分辨率的层来定义的。这个阈值是指在编码时,要预测它的大小,然后会有一个Buffer去装它,当这一帧编完之后,可以定义体积比阈值大多少的情况下,我们才把这个帧给丢掉,而且可以根据不同的层去定义不同的阈值。第二个是三种丢帧的模式。第三个是指最多连续可以丢多少帧。比如说,网络情况特别不好的情况下,有可能连续丢好多帧,但是如果已经达到了连续最多丢帧的数目,就会强制把丢帧的Feature关掉,这样就会强制送一帧过去,视频会议的参与者也就不会什么都看不到。
6、Intra-only Frame
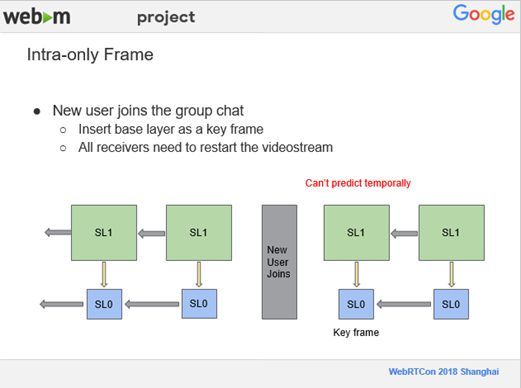
下面一个Feature是帧内编码的帧,但是它是非关键帧。举例说明,如果没有这个Feature,当我们现在有五个人用视频会议开会时,突然有第六个人加入进来,他没有任何关于当前视频的信息。如果想开始的话,所有人的视频帧都必须要插入一个关键帧,他才能看到所有人。但是,插入关键帧会有一个问题,关键帧会更新所有的关键帧的Buffer,这个会导致所有人重新开始,也就是这个视频流会重新开始一遍。然后我们想到,可以用帧内编码的帧,并且它不是关键帧,这样一来就不会去更新所有的参考帧的Buffer。
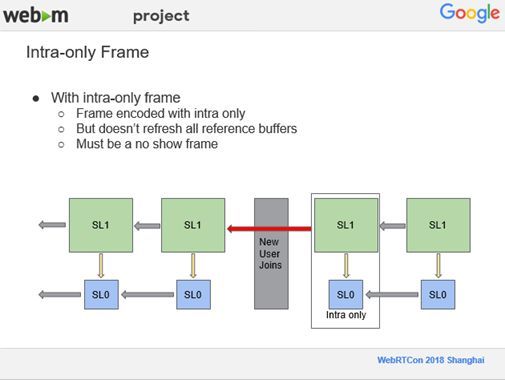
如此当新用户进来之后,其他所有人都只需要插入一个帧内编码的帧即可。对于以前有的用户,会接收更高分辨率的,如上图圈出的SL1,因为帧内编码的帧不会去更新所有的参考帧,它还是可以从以前的视频流里进行预测,它接收高分辨率的用户,然后非常平滑的过渡到新用户进来,如果没有帧内编码,关键帧插入进来,所有的人的视频都中断一下,这样就非常不平滑。但是在VP9里,这应该是比较老的一些设计,必须是no show frame,意思是指不能被显示出来,解码器在解码的时候,是看不到这一帧的。
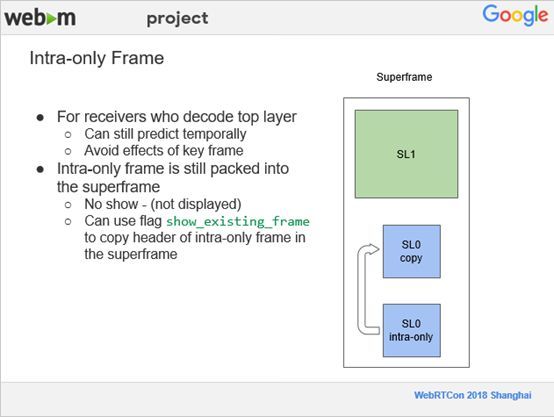
为了解决这个问题,我们在VP9中使用了另外一个Feature,用来显示已经存在的一个帧,称为show existing frame。在一个超级帧中,编码完帧内编码的帧后,把它的帧头部copy到另外一个帧里,然后把copy后的帧加上以前显示帧内编码的帧的标记。但是,因为我们只复制它的头部,它的编码数据还是来自于帧内编码的帧,整个超级帧的大小也基本上不会变化。通过这个我们很好的解决了新用户加入到视频会议后,所有人的视频流都要重启的问题。
7、Long Term Temporal Prediction
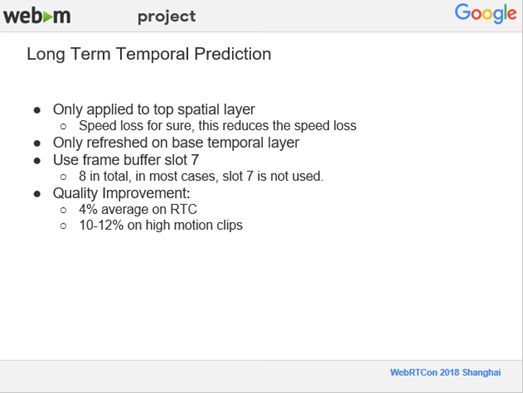
前面曾提到过,SVC中所有的预测模式,有的是低分辨率的预测即同一帧同一幅画面,有的是离它很近的,可能是前一帧或者前两帧预测的情况。VP9支持8个参考帧的Buffer,但我们只用到了4个,那么空闲的一些参考帧的Buffer可以用来做长时间参考帧的预测。但是因为多加入了一个参考帧,编码的时间会增加,且编码速度也要损失一些。目前我们只是把它们用在了最高分辨率那一层,因为在测试中发现,由于网速很快且设备性能较强,所以绝大多数人都是只接收最高分辨率的那一帧。如果要更新参考帧的Buffer,只需更新在最下面的时间分辨率层。此外,为了简单,我们的实现比较暴力一点,只用到了8个参考帧中最后一个参考帧的一个Buffer。由于多了一个参考帧,对压缩效率及质量的提升很大,在我们自己的实时测试编码数据集上,有4%的提高,但是在一些运动范围比较大、运动比较多的视频上测试,有10%到12%的提高,因为在运动比较多的时候,更有可能从长时间的预测上面得到比较有用的信息。下图是一个采用了长时间的参考帧的示意图,它是从很早之前的某一个帧去进行预测的。
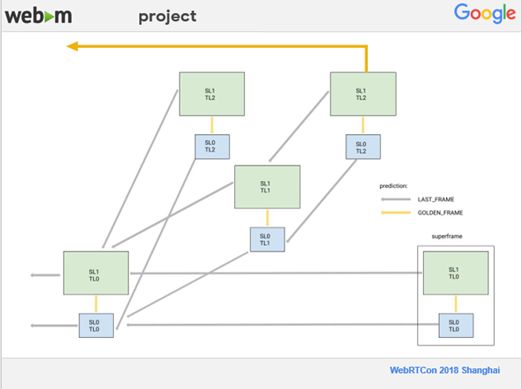
8、Scale partitioning in SVC
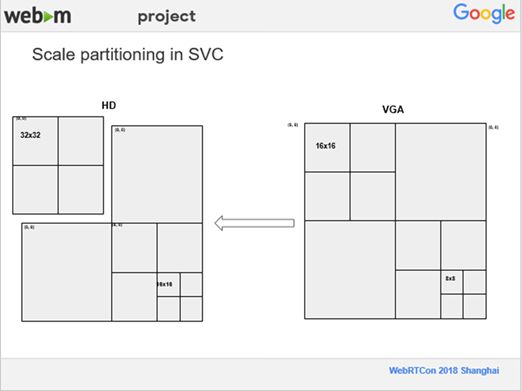
还有一个Feature是用来加速用的,在VP9里支持最大的块是64×64,最小的块在关键帧上是4×4,非关键帧上是8×8,而且这是一个递归结构,非常浪费时间,所以需要优化分块的算法。在优化分块的算法中,由于在SVC里面先编码低分辨率的,再编码高分辨率的,所以我们在编码HD时, VGA这层的编码已经有了,我们就想,在某些特定的情况下如SAD比较低,我们就把VGA里64×64的块直接放大到HD层进行使用,这样我们就完全跳过分块部分的算法。在上图的例子中,VGA是一个64×64的块,最小的是8×8。在把VGA放大到HD层时,由于VGA是64×64的一个大块,在 HD这边就单独拿左上角这块与之对应。这样一来,我们就完全跳过了分块的算法,在我们的RTC测试集上面,平均速度提高5%左右,在有些视频上面,提高10%左右。
9、Motion Vector Reuse
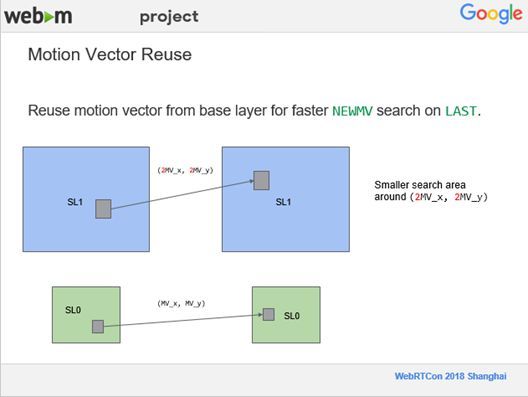
最后是一个很简单的Feature,我们会重复利用低分辨率的运动向量,把低分辨率下计算的运动向量表示成MV的两个方向,在更高分辨率的情况下,我们会利用已有的信息来进行运动向量的搜索。在我们需要寻找到新的运动向量时,就将搜索范围进一步缩小,从而更快的进行运动向量的搜索,这是加速的Feature,没有API可以控制。
二、VP9 SVC v.s. VP8 Simulcast
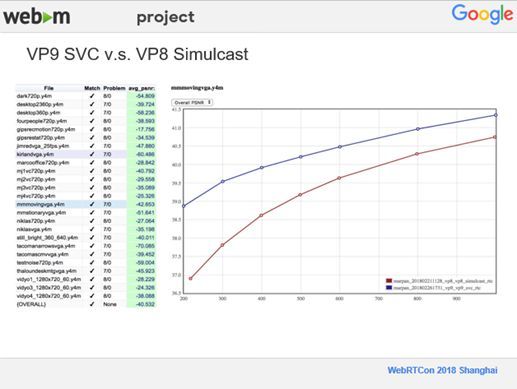
这一部分给大家看一下VP9 SVC与VP8的质量对比,上图中蓝色代表的是VP9,红色代表的是VP8,因为VP9比VP8有30%~40%压缩效率上的提高,出现上图的结果也不奇怪的,相同的码率VP9有更高的PSNR,可以节省更多的码率。左侧是我们用RTC做的一些测试,最后从PSNR来看,相对VP8来讲,还是有很大提高的,大约有40.5%。
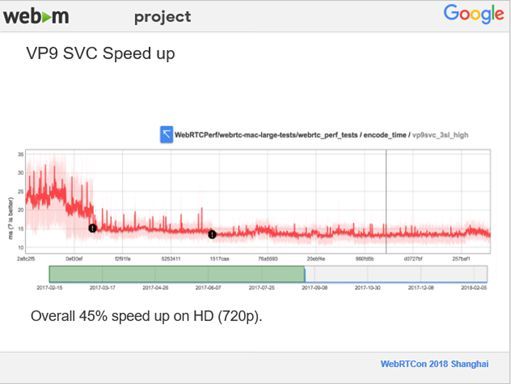
上图展示的是VP9 SVC的编码速度,数据中的最近时间是2018年2月份,已经相对比较老了。现在SVC的编码速度又相对提高了一些,有超过45%的提升,以前每编码一个超级帧大概需要25毫秒,现在大概是10在15毫秒之间。这个测试是在Mac设备上进行的,笔记本电脑也完全可以达到实时性的要求。并且,根据我们在Google内部的预测,没有接收过速度太慢之类的反馈,目前从速度和性能上来说还是不错的。
三、VP9 Temporal Denoiser
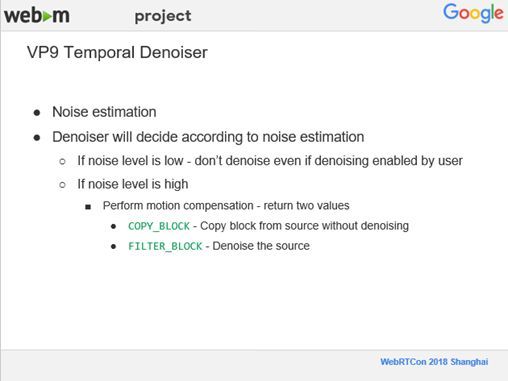
接下来介绍一下去噪的过程,之前我们在测试Denoiser时,录制下来的视频噪音还是比较大,因为噪音都是随机产生的,随机信号是根本无法压缩的,所以我们需要尽量减少噪音。此外,去噪其实是要耗费很多时间的,因此在去噪前我们会做一个噪声的水平估计。大约每20到 30帧做一次估计,如果噪音水平很低,就不再进行去噪了;如果噪音水平很高我们会通过进行运动补偿来决定是否去噪。对当前编码块做运动补偿,从参考帧上做运动补偿过来再进行比较。可能会返回两种结果,一种是从视频源直接将编码块复制过来,则不再进行去噪;另一种就是对当前块去噪。
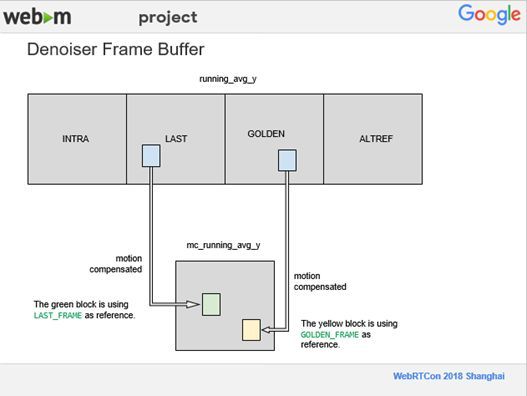
在非SVC情况下,我们可以把INTRA看成Source,就是摄像头直接拍下来的内容,LAST、GOLDEN、ALTREF是参考帧。在去噪的过程中我们会做运动补偿,比如说,上图中绿色的块,它的参考帧是LAST,我们对LAST进行运动补偿,并把它放到一个新的Buffer里面,上图中黄色的块,它的参考帧是GOLDEN,我们对GOLDEN块进行运动补偿并放到新的Buffer里面,然后对运动补偿过的帧进行去噪,并且只针对3个通道Y、U、V 中的Y通道做去噪。
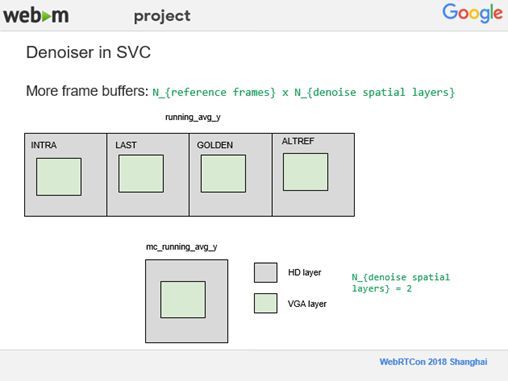
在SVC情况下,去噪相对比较复杂,因为每一个超级帧上都有两个,三个甚至更多不同的分辨率,我们就需要更多的 Buffer在Denoiser里面放置参考帧,所以最后参考帧的数量就是用参考帧的数目乘以需要去噪音的不同分辨率层的数量。比如,上述例子中分辨率有一个HD层,以及VGA层,如果这两层都决定去噪,那么就需要8个Buffer。
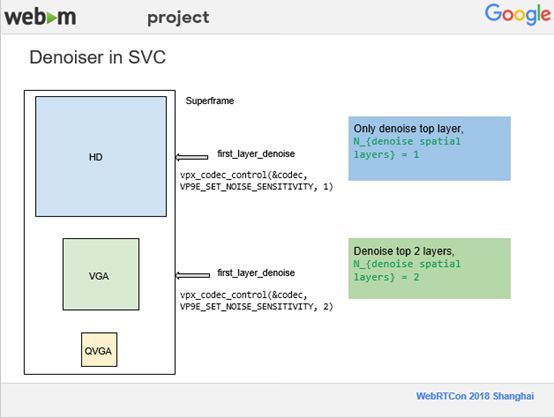
我们将去噪的控制权交给了用户,让用户来决定选择HD层还是VGA层进行去噪。用户可以通过一个Denoiser的API设置,如果将API设成1,去噪就只有最高分辨率的这一层,在这种情况下,当在Denoiser分配Buffer的时候,只用四个Buffer就好了。如果将API设成2,也就是现在要对两个分辨率层进行去噪。它会针对HD和VGA两层进行去噪,在Denoiser上就需要8个Buffer。
四、总结

总结一下,首先VP9已经开始在Google进行内测,我们也正在不停地改进,添加一些新的Feature进去,预计不久之后应该会将VP9 SVC加入到WebRTC中开放给大家。此外,VP9 SVC质量相比VP8来说还是非常好的,并且我们也在不停提高编码速度,这样一来,无论是使用笔记本电脑或台式机,VP9 SVC也完全可以满足实时性要求。
精品文章推荐
技术干货:
Per-Title编码优化
2018:视频标准混战的元年序幕
Demuxed:编解码器和压缩的未来
Netflix:我们是如何评估Codec性能的?
编码压缩新思路:面向QoE的感知视频编码
编解码器之战:AV1、HEVC、VP9和VVC
AV1:下一代视频标准—约束定向增强滤波器
基于QoE的实时视频编码优化:低功耗,低延时,高质量