linux内存管理--缺页异常处理
1 缺页异常在linux内核处理中占有非常重要的位置,很多linux特性,如写时复制,页框延迟分配,内存回收中的磁盘和内存交换,都需要借助缺页异常来进行,缺页异常处理程序主要处理以下四种情形:
1请求调页: 当进程调用malloc()之类的函数调用时,并未实际上分配物理内存,而是仅仅分配了一段线性地址空间,在实际访问该页框时才实际去分配物理页框,这样可以节省物理内存的开销,还有一种情况是在内存回收时,该物理页面的内容被写到了磁盘上,被系统回收了,这时候需要再分配页框,并且读取其保存的内容。
2写时复制:当fork()一个进程时,子进程并未完整的复制父进程的地址空间,而是共享相关的资源,父进程的页表被设为只读的,当子进程进行写操作时,会触发缺页异常,从而为子进程分配页框。
3地址范围外的错误:内核访问无效地址,用户态进程访问无效地址等。
4内核访问非连续性地址:用于内核的高端内存映射,高端内存映射仅仅修改了主内核页表的内容,当进程访问内核态时需要将该部分的页表内容复制到自己的进程页表里面。
2 缺页异常处理程序有可能发生在用户态或者内核态的代码中,在这两种形态下,有可能访问的是内核空间或者用户态空间的内存地址,因此,按照排列组合,需要考虑下列的四种情形,如图所示:
1缺页异常发生在内核态
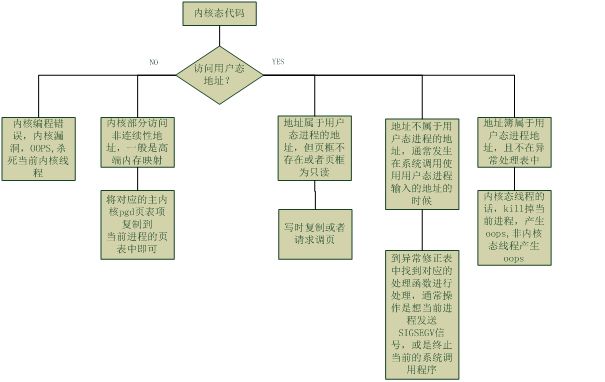
2缺页异常发生在用户态
3源代码分析(选自2.6.10内核)
- 3.1 do_page_fault()
- fastcall void do_page_fault(struct pt_regs *regs, unsigned long error_code)
- {
- struct task_struct *tsk;
- struct mm_struct *mm;
- struct vm_area_struct * vma;
- unsigned long address;
- unsigned long page;
- int write;
- siginfo_t info;
- //将引发缺页异常的线性地址保存在address变量里面
- __asm__("movl %%cr2,%0":"=r" (address));
- if (notify_die(DIE_PAGE_FAULT, "page fault", regs, error_code, 14,
- SIGSEGV) == NOTIFY_STOP)
- return;
- tsk = current;
- //info是内核发送信号使用的信息结构体
- info.si_code = SEGV_MAPERR;
- //该分支表明发生缺页时是发生在访问内核空间时
- if (unlikely(address >= TASK_SIZE)) {
- //该分支表示发生缺页异常时,代码是在内核态访问内核态不存在
- //的地址,转到vmalloc_fault处理分支,可能是访问了不连续的内核页面
- if (!(error_code & 5))
- goto vmalloc_fault;
- //做相应出错处理
- goto bad_area_nosemaphore;
- }
- mm = tsk->mm;
- //在中断或者软中断中访问用户态空间,发生问题,是不可以的,因为中断或者
- //软中断不代表任何的进程,mm为NULL代表着该进程是内核线程,内核线程
- //继承了上一个普通进程页表,不能对其进行修改
- if (in_atomic() || !mm)
- goto bad_area_nosemaphore;
- //尝试获取到读锁,若获得读锁失败时
- if (!down_read_trylock(&mm->mmap_sem)) {
- //在内核态访问用户态的地址,这种情况发生在在
- //进程的系统调用中去访问用户态的地址,在访问
- //地址前,内核是不会去写对应的读锁的,所以可能是
- //别的进程写了,相应的锁,所以需要等待,其它情况
- //属于错误情况
- if ((error_code & 4) == 0 &&
- !search_exception_tables(regs->eip))
- goto bad_area_nosemaphore;
- down_read(&mm->mmap_sem);
- }
- //下面这几句话是来判断出错地址是否在进程的线性区内
- vma = find_vma(mm, address);
- //不在线性区内,地址错误
- if (!vma)
- goto bad_area;
- //在线性区内,跳到正常处理部分
- if (vma->vm_start <= address)
- goto good_area;
- //下面这些代码属于扩展进程栈的相关处理,该地址可能由push或者pusha指令引起
- //向低地址扩展的栈其线性区的标志位会置上VM_GROWSDOWN
- if (!(vma->vm_flags & VM_GROWSDOWN))
- goto bad_area;
- if (error_code & 4) {//异常发生在用户态
- //对于栈操作,发生错误的内存地址不应该比esp小太多,不该小32
- //个字节以上
- if (address + 32 < regs->esp)
- goto bad_area;
- }
- //扩展进程的用户态堆栈
- if (expand_stack(vma, address))
- goto bad_area;
- good_area:
- info.si_code = SEGV_ACCERR;
- write = 0;
- switch (error_code & 3) {
- default://写,存在该页框,写时复制的情况
- case 2: //写但不存在该页框
- //该线性区不让写,发生错误
- if (!(vma->vm_flags & VM_WRITE))
- goto bad_area;
- write++;
- break;
- case 1: //读,存在该页框
- goto bad_area;
- case 0: //读但是不存在该页框,缺页,需要进行调页
- if (!(vma->vm_flags & (VM_READ | VM_EXEC)))
- goto bad_area;
- }
- survive:
- //在handle_mm_fault()函数里面处理缺页的情况
- switch (handle_mm_fault(mm, vma, address, write)) {
- case VM_FAULT_MINOR:
- //在没有阻塞的情况下,完成了调页
- tsk->min_flt++;
- break;
- case VM_FAULT_MAJOR:
- //在阻塞的情况下,完成了调页操作
- tsk->maj_flt++;
- break;
- case VM_FAULT_SIGBUS:
- //发生其他错误
- goto do_sigbus;
- case VM_FAULT_OOM:
- //内存不足
- goto out_of_memory;
- default:
- BUG();
- }
- /*
- * Did it hit the DOS screen memory VA from vm86 mode?
- */
- if (regs->eflags & VM_MASK) {
- unsigned long bit = (address - 0xA0000) >> PAGE_SHIFT;
- if (bit < 32)
- tsk->thread.screen_bitmap |= 1 << bit;
- }
- up_read(&mm->mmap_sem);
- return;
- /*
- * Something tried to access memory that isn't in our memory map..
- * Fix it, but check if it's kernel or user first..
- */
- bad_area:
- up_read(&mm->mmap_sem);
- bad_area_nosemaphore:
- //该错误发生在用户态代码访问时
- if (error_code & 4) {
- if (is_prefetch(regs, address, error_code))
- return;
- tsk->thread.cr2 = address;
- tsk->thread.error_code = error_code | (address >= TASK_SIZE);
- tsk->thread.trap_no = 14;
- info.si_signo = SIGSEGV;
- info.si_errno = 0;
- info.si_addr = (void __user *)address;
- //发送sigsegv信号给当前的进程
- force_sig_info(SIGSEGV, &info, tsk);
- return;
- }
- //剩下的错误,发生在内核态
- no_context:
- //是否有动态修正代码,该异常通常发生在将用户态线性地址
- //作为参数传递给了系统调用,该错误发生在内核态访问一个
- //用户态地址,但用户态地址不属于进程的地址空间
- if (fixup_exception(regs))
- return;
- if (is_prefetch(regs, address, error_code))
- return;
- bust_spinlocks(1);
- //发生了真正的内核错误,往输出上打印相关错误信息
- if (address < PAGE_SIZE)
- printk(KERN_ALERT "Unable to handle kernel NULL pointer dereference");
- else
- printk(KERN_ALERT "Unable to handle kernel paging request");
- printk(" at virtual address %08lx\n",address);
- printk(KERN_ALERT " printing eip:\n");
- printk("%08lx\n", regs->eip);
- asm("movl %%cr3,%0":"=r" (page));
- page = ((unsigned long *) __va(page))[address >> 22];
- printk(KERN_ALERT "*pde = %08lx\n", page);
- #ifndef CONFIG_HIGHPTE
- if (page & 1) {
- page &= PAGE_MASK;
- address &= 0x003ff000;
- page = ((unsigned long *) __va(page))[address >> PAGE_SHIFT];
- printk(KERN_ALERT "*pte = %08lx\n", page);
- }
- #endif
- //产生Oops的消息
- die("Oops", regs, error_code);
- bust_spinlocks(0);
- //退出相关进程
- do_exit(SIGKILL);
- out_of_memory:
- //内存不足,删除当前进程
- up_read(&mm->mmap_sem);
- if (tsk->pid == 1) {
- yield();
- down_read(&mm->mmap_sem);
- goto survive;
- }
- printk("VM: killing process %s\n", tsk->comm);
- if (error_code & 4)//用户态进程,杀死用户态进程
- do_exit(SIGKILL);
- goto no_context;
- do_sigbus:
- //发送SIGBUS信号给当前进程
- up_read(&mm->mmap_sem);
- //内核态进程,生成oops等
- if (!(error_code & 4))
- goto no_context;
- if (is_prefetch(regs, address, error_code))
- return;
- //用户态进程的话,发送SIGBUS给当前用户态进程
- tsk->thread.cr2 = address;
- tsk->thread.error_code = error_code;
- tsk->thread.trap_no = 14;
- info.si_signo = SIGBUS;
- info.si_errno = 0;
- info.si_code = BUS_ADRERR;
- info.si_addr = (void __user *)address;
- force_sig_info(SIGBUS, &info, tsk);
- return;
- vmalloc_fault:
- {
- //在内核态访问内核空间内存,访问非连续性内存
- int index = pgd_index(address);
- unsigned long pgd_paddr;
- pgd_t *pgd, *pgd_k;
- pmd_t *pmd, *pmd_k;
- pte_t *pte_k;
- asm("movl %%cr3,%0":"=r" (pgd_paddr));
- pgd = index + (pgd_t *)__va(pgd_paddr);
- pgd_k = init_mm.pgd + index;
- if (!pgd_present(*pgd_k))
- goto no_context;
- pmd = pmd_offset(pgd, address);
- pmd_k = pmd_offset(pgd_k, address);
- if (!pmd_present(*pmd_k))
- goto no_context;
- //主要操作就是把主内核页表上对应的表项复制到当前进程的页表中
- set_pmd(pmd, *pmd_k);
- pte_k = pte_offset_kernel(pmd_k, address);
- if (!pte_present(*pte_k))
- goto no_context;
- return;
- }
- }
- 3.2 handle_mm_fault()
- int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct * vma,
- unsigned long address, int write_access)
- {
- pgd_t *pgd;
- pmd_t *pmd;
- __set_current_state(TASK_RUNNING);
- pgd = pgd_offset(mm, address);
- inc_page_state(pgfault);
- if (is_vm_hugetlb_page(vma))
- return VM_FAULT_SIGBUS;
- spin_lock(&mm->page_table_lock);
- //找到相应的pmd表的地址,没有的话,分配一个
- pmd = pmd_alloc(mm, pgd, address);
- if (pmd) {
- //找到对应的pte表的地址,即页表的地址,找不到
- //的话,分配一个
- pte_t * pte = pte_alloc_map(mm, pmd, address);
- //进行相应的缺页处理:
- //1请求调页,2写时复制
- if (pte)
- return handle_pte_fault(mm, vma, address, write_access, pte, pmd);
- }
- spin_unlock(&mm->page_table_lock);
- return VM_FAULT_OOM;
- }
- 3.3 handle_pte_fault()
- static inline int handle_pte_fault(struct mm_struct *mm,
- struct vm_area_struct * vma, unsigned long address,
- int write_access, pte_t *pte, pmd_t *pmd)
- {
- pte_t entry;
- entry = *pte;
- if (!pte_present(entry)) {
- //页面从未被访问过,需要申请页面进行调页,匿名映射
- //或者是磁盘文件映射都有可能
- if (pte_none(entry))
- return do_no_page(mm, vma, address, write_access, pte, pmd);
- //非线性磁盘文件映射
- if (pte_file(entry))
- return do_file_page(mm, vma, address, write_access, pte, pmd);
- //相关页框被作为交换页写到了磁盘上
- return do_swap_page(mm, vma, address, pte, pmd, entry, write_access);
- }
- //写时复制
- if (write_access) {
- if (!pte_write(entry))
- return do_wp_page(mm, vma, address, pte, pmd, entry);
- entry = pte_mkdirty(entry);
- }
- entry = pte_mkyoung(entry);
- ptep_set_access_flags(vma, address, pte, entry, write_access);
- update_mmu_cache(vma, address, entry);
- pte_unmap(pte);
- spin_unlock(&mm->page_table_lock);
- return VM_FAULT_MINOR;
- }
利用异常表处理 Linux 内核态缺页异常
前言
在程序的执行过程中,因为遇到某种障碍而使 CPU 无法最终访问到相应的物理内存单元,即无法完成从虚拟地址到物理地址映射的时候,CPU 会产生一次缺页异常,从而进行相应的缺页异常处理。基于 CPU 的这一特性,Linux 采用了请求调页(Demand Paging)和写时复制(Copy On Write)的技术
1. 请求调页是一种动态内存分配技术,它把页框的分配推迟到不能再推迟为止。这种技术的动机是:进程开始运行的时候并不访问地址空间中的全部内容。事实上,有一部分地址也许永远也不会被进程所使用。程序的局部性原理也保证了在程序执行的每个阶段,真正使用的进程页只有一小部分,对于临时用不到的页,其所在的页框可以由其它进程使用。因此,请求分页技术增加了系统中的空闲页框的平均数,使内存得到了很好的利用。从另外一个角度来看,在不改变内存大小的情况下,请求分页能够提高系统的吞吐量。当进程要访问的页不在内存中的时候,就通过缺页异常处理将所需页调入内存中。
2. 写时复制主要应用于系统调用fork,父子进程以只读方式共享页框,当其中之一要修改页框时,内核才通过缺页异常处理程序分配一个新的页框,并将页框标记为可写。这种处理方式能够较大的提高系统的性能,这和Linux创建进程的操作过程有一定的关系。在一般情况下,子进程被创建以后会马上通过系统调用execve将一个可执行程序的映象装载进内存中,此时会重新分配子进程的页框。那么,如果fork的时候就对页框进行复制的话,显然是很不合适的。
在上述的两种情况下出现缺页异常,进程运行于用户态,异常处理程序可以让进程从出现异常的指令处恢复执行,使用户感觉不到异常的发生。当然,也会有异常无法正常恢复的情况,这时,异常处理程序会进行一些善后的工作,并结束该进程。也就是说,运行在用户态的进程如果出现缺页异常,不会对操作系统核心的稳定性造成影响。 那么对于运行在核心态的进程如果发生了无法正常恢复的缺页异常,应该如何处理呢?是否会导致系统的崩溃呢?是否能够解决好内核态缺页异常对于操作系统核心的稳定性来说会产生很大的影响,如果一个误操作就会造成系统的Oops,这对于用户来说显然是不能容忍的。本文正是针对这个问题,介绍了一种Linux内核中所采取的解决方法。
在读者继续往下阅读之前,有一点需要先说明一下,本文示例中所选的代码取自于Linux-2.4.0,编译环境是gcc-2.96,objdump的版本是2.11.93.0.2,具体的版本信息可以通过以下的命令进行查询:
$ gcc -v
Reading specs from /usr/lib/gcc-lib/i386-redhat-linux/2.96/specs
gcc version 2.96 20000731 (Red Hat Linux 7.3 2.96-110)
$ objdump -v
GNU objdump 2.11.93.0.2 20020207
Copyright 2002 Free Software Foundation, Inc.
GCC的扩展功能
由于本文中会用到GCC的扩展功能,即汇编器as中提供的.section伪操作,在文章开始之前我再作一个简要的介绍。此伪操作对于不同的可执行文件格式有不同的解释,我也不一一列举,仅对我们所感兴趣的Linux中常用的ELF格式的用法加以描述,其指令格式如下:
.section NAME[, "FLAGS"]
大家所熟知的C程序一般由以下的几个部分组成:代码段(text section)、初始化数据段(data section)、非初始化数据段(bss section)、栈(heap)以及堆(stack),具体的地址空间布局可以参考《UNIX环境高级编程》一书。
在Linux内核中,通过使用.section的伪操作,可以把随后的代码汇编到一个由NAME指定的段中。而FLAGS字段则说明了该段的属性,它可以用下面介绍的单个字符来表示,也可以是多个字符的组合。
- 'a' 可重定位的段
- 'w' 可写段
- 'x' 可执行段
- 'W' 可合并的段
- 's' 共享段
举个例子来说明,读者在后面会看到的:.section .fixup, "ax"
这样的一条指令定义了一个名为.fixup的段,随后的指令会被加入到这个段中,该段的属性是可重定位并可执行。
内核缺页异常处理
运行在核心态的进程经常需要访问用户地址空间的内容,但是谁都无法保证内核所得到的这些从用户空间传入的地址信息是"合法"的。为了保护内核不受错误信息的攻击,需要验证这些从用户空间传入的地址信息的正确性。
在老版本的Linux中,这个工作是通过函数verify_area来完成的:
extern inline int verify_area(int type, const void * addr, unsigned long size)
该函数验证了是否可以以type中说明的访问类型(read or write)访问从地址addr开始、大小为size的一块虚拟存储区域。为了做到这一点,verify_read首先需要找到包含地址addr的虚拟存储区域(vma)。一般的情况下(正确运行的程序)这个测试都会成功返回,在少数情况下才会出现失败的情况。也就是说,大部分的情况下内核在一些无用的验证操作上花费了不算短的时间,这从操作系统运行效率的角度来说是不可接受的。
为了解决这个问题,现在的Linux设计中将验证的工作交给虚存中的硬件设备来完成。当系统启动分页机制以后,如果一条指令的虚拟地址所对应的页框(page frame)不在内存中或者访问的类型有错误,就会发生缺页异常。处理器把引起缺页异常的虚拟地址装到寄存器CR2中,并提供一个出错码,指示引起缺页异常的存储器访问的类型,随后调用Linux的缺页异常处理函数进行处理。
Linux中进行缺页异常处理的函数如下:
asmlinkage void do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
……………………
__asm__("movl %%cr2,%0":"=r" (address));
……………………
vma = find_vma(mm, address);
if (!vma)
goto bad_area;
if (vma->vm_start <= address)
goto good_area;
if (!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area;
if (error_code & 4) {
if (address + 32 <
regs-
>esp)
goto bad_area;
……………………
bad_area:
……………………
no_context:
/* Are we prepared to handle this kernel fault? */
if ((fixup = search_exception_table(regs->eip)) != 0) {
regs->eip = fixup;
return;
}
………………………
}
首先让我们来看看传给这个函数调用的两个参数:它们都是通过entry.S在堆栈中建立的(arch/i386/kernel/entry.S),参数regs指向保存在堆栈中的寄存器,error_code中存放着异常的出错码,具体的堆栈布局参见图一(堆栈的生成过程请参考《Linux内核源代码情景分析》一书)
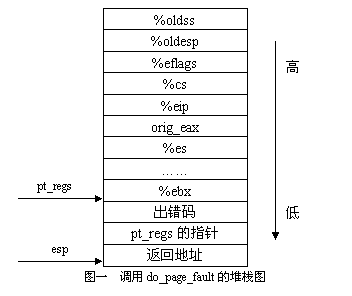
该函数首先从CPU的控制寄存器CR2中获取出现缺页异常的虚拟地址。由于缺页异常处理程序需要处理的缺页异常类型很多,分支也很复杂。基于本文的主旨,我们只关心以下的几种内核缺页异常处理的情况:
1. 程序要访问的内核地址空间的内容不在内存中,先跳转到标号vmalloc_fault,如果当前访问的内容所对应的页目录项不在内存中,再跳转到标号no_context;
2. 缺页异常发生在中断或者内核线程中,跳转到标号no_context;
3. 程序在核心态运行时访问用户空间的数据,被访问的数据不在内存中
- a) 出现异常的虚拟地址在进程的某个vma中,但是系统内存无法分配空闲页框(page frame),则先跳转到标号out_of_memory,再跳转到标号no_context;
- b) 出现异常的虚拟地址不属于进程任一个vma,而且不属于堆栈扩展的范畴,则先跳转到标号bad_area,最终也是到达标号no_context。
从上面的这几种情况来看,我们关注的焦点最后集中到标号no_context处,即对函数search_exception_table的调用。这个函数的作用就是通过发生缺页异常的指令(regs->eip)在异常表(exception table)中寻找下一条可以继续运行的指令(fixup)。这里提到的异常表包含一些地址对,地址对中的前一个地址表示出现异常的指令的地址,后一个表示当前一个指令出现错误时,程序可以继续得以执行的修复地址。
如果这个查找操作成功的话,缺页异常处理程序将堆栈中的返回地址(regs->eip)修改成修复地址并返回,随后,发生异常的进程将按照fixup中安排好的指令继续执行下去。当然,如果无法找到与之匹配的修复地址,系统只有打印出出错信息并停止运作。
那么,这个所谓的修复地址又是如何生成的呢?是系统自动生成的吗?答案当然是否定的,这些修复指令都是编程人员通过as提供的扩展功能写进内核源码中的。下面我们就来分析一下其实现机制。
异常表的实现机制
笔者取include/asm-i386/uaccess.h中的宏定义__copy_user编写了一段程序作为例子加以讲解。
/* hello.c */
#include <
stdio.h
>
#include <
string.h
>
#define __copy_user(to,from,size) \
do { \
int __d0, __d1; \
__asm__ __volatile__( \
"0: rep; movsl\n" \
" movl %3,%0\n" \
"1: rep; movsb\n" \
"2:\n" \
".section .fixup,\"ax\"\n" \
"3: lea 0(%3,%0,4),%0\n" \
" jmp 2b\n" \
".previous\n" \
".section __ex_table,\"a\"\n" \
" .align 4\n" \
" .long 0b,3b\n" \
" .long 1b,2b\n" \
".previous" \
: "=&c"(size), "=&D" (__d0), "=&S" (__d1) \
: "r"(size & 3), "0"(size / 4), "1"(to), "2"(from) \
: "memory"); \
} while (0)
int main(void)
{
const char *string = "Hello, world!";
char buf[20];
unsigned long n, m;
m = n = strlen(string);
__copy_user(buf, string, n);
buf[m] = '\0';
printf("%s\n", buf);
exit(0);
}
先看看本程序的执行结果:
$ gcc hello.c -o hello
$ ./hello
Hello, world!
显然,这就是一个简单的"hello world"程序,那为什么要写得这么复杂呢?程序中的一大段汇编代码在内核中才能体现出其价值,笔者将其加入到上面的程序中,是为了后面的分析而准备的。
系统在核心态运行的时候,参数是通过寄存器来传递的,由于寄存器所能够传递的信息有限,所以传递的参数大多数是指针。要使用指针所指向的更大块的数据,就需要将用户空间的数据拷贝到系统空间来。上面的__copy_user在内核中正是扮演着这样的一个拷贝数据的角色,当然,内核中这样的宏定义还很多,笔者也只是取其中的一个来讲解,读者如果感兴趣的话可以看完本文以后自行学习。
如果读者对于简单的嵌入式汇编还不是很了解的话,可以参考《Linux内核源代码情景分析》一书。下面我们将程序编译成汇编程序来加以分析:
$ gcc -S hello.c
/* hello.s */
movl -60(%ebp), %eax
andl $3, %eax
movl -60(%ebp), %edx
movl %edx, %ecx
shrl $2, %ecx
leal -56(%ebp), %edi
movl -12(%ebp), %esi
#APP
0: rep; movsl
movl %eax,%ecx
1: rep; movsb
2:
.section .fixup,"ax"
3: lea 0(%eax,%ecx,4),%ecx
jmp 2b
.previous
.section __ex_table,"a"
.align 4
.long 0b,3b
.long 1b,2b
.previous
#NO_APP
movl %ecx, %eax
从上面通过gcc生成的汇编程序中,我们可以很容易的找到访问用户地址空间的指令,也就是程序中的标号为0和1的两条语句。而程序中伪操作.section的作用就是定义了.fixup和__ex_table这样的两个段,那么这两段在可执行程序中又是如何安排的呢?下面就通过objdump给读者一个直观的概念:
$ objdump --section-headers hello
hello: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .interp 00000013 080480f4 080480f4 000000f4 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
………………………………
9 .init 00000018 080482e0 080482e0 000002e0 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
10 .plt 00000070 080482f8 080482f8 000002f8 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
11 .text 000001c0 08048370 08048370 00000370 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
12 .fixup 00000009 08048530 08048530 00000530 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
13 .fini 0000001e 0804853c 0804853c 0000053c 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
14 .rodata 00000019 0804855c 0804855c 0000055c 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
15 __ex_table 00000010 08048578 08048578 00000578 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
16 .data 00000010 08049588 08049588 00000588 2**2
CONTENTS, ALLOC, LOAD, DATA
CONTENTS, READONLY
………………………………
26 .note 00000078 00000000 00000000 0000290d 2**0
CONTENTS, READONLY
上面通过objdump显示出来的可执行程序的头部信息中,有一些是读者所熟悉的,例如.text、.data以及被笔者省略掉的.bss,而我们所关心的是12和15,也就是.fixup和__ex_table。对照hello.s中段的定义来看,两个段声明中的FLAGS字段分别为'ax'和'a',而objdump的结果显示,.fixup段是可重定位的代码段,__ex_table段是可重定位的数据段,两者是吻合的。
那么为什么要通过.section定义独立的段呢?为了解开这个问题的答案,我们需要进一步看看我们所写的代码在可执行文件中是如何表示的。
$objdump --disassemble --section=.text hello
hello: file format elf32-i386
Disassembly of section .text:
8048498: 8b 45 c4 mov 0xffffffc4(%ebp),%eax
804849b: 83 e0 03 and $0x3,%eax
804849e: 8b 55 c4 mov 0xffffffc4(%ebp),%edx
80484a1: 89 d1 mov %edx,%ecx
80484a3: c1 e9 02 shr $0x2,%ecx
80484a6: 8d 7d c8 lea 0xffffffc8(%ebp),%edi
80484a9: 8b 75 f4 mov 0xfffffff4(%ebp),%esi
80484ac: f3 a5 repz movsl %ds:(%esi),%es:(%edi)
80484ae: 89 c1 mov %eax,%ecx
80484b0: f3 a4 repz movsb %ds:(%esi),%es:(%edi)
80484b2: 89 c8 mov %ecx,%eax
前面的hello.s中的汇编片断在可执行文件中就是通过上面的11条指定来表达,读者也许会问,由.section伪操作定义的段怎么不见了?别着急,慢慢往下看,由.section伪操作定义的段并不在正常的程序执行路径上,它们是被安排在可执行文件的其它地方了:
$objdump --disassemble --section=.fixup hello
hello: file format elf32-i386
Disassembly of section .fixup:
08048530 <.fixup>:
8048530: 8d 4c 88 00 lea 0x0(%eax,%ecx,4),%ecx
8048534: e9 79 ff ff ff jmp 80484b2 <
main
+0x42>
由此可见,.fixup是作为一个单独的段出现在可执行程序中的,而此段中所包含的语句则正好是和源程序hello.c中的两条语句相对应的。
将.fixup段和.text段独立开来的目的是为了提高CPU流水线的利用率。熟悉体系结构的读者应该知道,当前的CPU引入了流水线技术来加快指令的执行,即在执行当前指令的同时,要将下面的一条甚至多条指令预取到流水线中。这种技术在面对程序执行分支的时候遇到了问题:如果预取的指令并不是程序下一步要执行的分支,那么流水线中的所有指令都要被排空,这对系统的性能会产生一定的影响。在我们的这个程序中,如果将.fixup段的指令安排在正常执行的.text段中,当程序执行到前面的指令时,这几条很少执行的指令会被预取到流水线中,正常的执行必然会引起流水线的排空操作,这显然会降低整个系统的性能。
下面我们就可以看到异常表是如何形成的了:
$objdump --full-contents --section=__ex_table hello
hello: file format elf32-i386
Contents of section __ex_table:
8048578 ac840408 30850408 b0840408 b2840408 ....0...........
由于x86使用小尾端的编址方式,上面的这段数据比较凌乱。让我把上面的__ex_table中的内容转变成大家通常看到的样子,相信会更容易理解一些:
8048578 80484ac 8048530 80484b0 80484b2 ....0...........
上面的红色部分就是我们最感兴趣的地方,而这段数据是如何形成的呢?将前面objdump生成的可执行程序中的汇编语句和hello.c中的源程序结合起来看,就可以发现一些有趣的东西了!
先让我们回头看看hello.c中__ex_table段的语句 .long 0b,3b。其中标签0b(b代表backward,即往回的标签0)是可能出现异常的指令的地址。结合objdump生成的可执行程序.text段的汇编语句可以知道标签0就是80484ac:
原始的汇编语句: 0: rep; movsl
链接到可执行程序后: 80484ac: f3 a5 repz movsl %ds:(%esi),%es:(%edi)
而标签3就是处理异常的指令的地址,在我们的这个例子中就是80484b0:
原始的汇编语句: 3: lea 0(%eax,%ecx,4),%ecx
链接到可执行程序后: 8048530: 8d 4c 88 00 lea 0x0(%eax,%ecx,4),%ecx
因此,相应的汇编语句
.section __ex_table,"a"
.align 4
.long 0b,3b
就变成了: 8048578 80484ac 8048530 …………
这样,异常表中的地址对(80484ac,8048530)就诞生了,而对于地址对(80484b0 80484b2)的生成,情况相同,不再赘述。
读到这儿了,有一件事要告诉读者的是,其实例子中异常表的安排在用户空间是不会得到执行的。当运行在用户态的进程访问到标签0处的指令出现缺页异常时,do_page_fault只会将该指令对应的进程页调入内存中,使指令能够重新正确执行,或者直接就杀死该进程,并不会到达函数search_exception_table处。
也许有的读者会问了,既然不执行,前面的例子和围绕例子所展开的讨论又有什么作用呢?大家大可打消这样的疑虑,我们前面的分析并没有白费,因为真正的内核异常表中地址对的生成机制和前面讲述的原理是完全一样的,笔者通过一个运行在用户空间的程序来讲解也是希望让读者能够更加容易的理解异常表的机制,不至于陷入到内核源码的汪洋大海中去。现在,我们可以自己通过objdump工具查看一下内核中的异常表:
$objdump --full-contents --section=__ex_table vmlinux
vmlinux: file format elf32-i386
Contents of section __ex_table:
c024ac80 e36d10c0 e66d10c0 8b7110c0 6c7821c0
……………………
做一下转化:
c024ac80 c0106de3 c0106de6 c010718b c021786c
上面的vmlinux就是编译内核所生成的内核可执行程序。和本文给出的例子相比,唯一的不同就是此时的地址对中的异常指令地址和修复地址都是内核空间的虚拟地址。也正是在内核中,异常表才真正发挥着它应有的作用。
总结
下面我对前面所讲述的内容做一个归纳,希望读者能够对内核缺页异常处理有一个清楚的认识:
- 进程访问内核地址空间的"非法"地址c010718b
- 存储管理部件(MMU)产生一个缺页异常;
- CPU调用函数do_page_fault;
- do_page_fault调用函数search_exception_table(regs->eip == c010718b);
- search_exception_table在异常表中查找地址c010718b,并返回地址对中的修复地址c021786c;
- do_page_fault将堆栈中的返回地址eip修改成c021786c并返回;
- 代码按照缺页异常处理程序的返回地址继续执行,也就是从c021786c开始继续执行。
将验证用户空间地址信息"合法"性的工作交给硬件来完成(通过缺页异常的方式)其实就是一种Lazy Computation,也就是等到真正出现缺页异常的时候才进行处理。通过本文的分析可以看出,这种方法与本文前面所提到的通过verify_area来验证的方法相比,较好的避免了系统在无用验证上的开销,能够有效的提高系统的性能。 此外,在分析源码的过程中读者会发现,异常表并不仅仅用在缺页异常处理程序中,在通用保护(General Protection)异常等地方,也同样用到了这一技术。
由此可见,异常表是一种广泛应用于Linux内核中的异常处理方法。在系统软件的设计中,异常表也应该成为一种提高系统稳定性的重要手段。
结束语
公开的Linux源码,对许多计算机爱好者来说,无异于一座取之不尽的宝库。在Linux的设计和程序的编写中,处处体现着程序员们的思想结晶。越来越多的人正加入到分析Linux操作系统行列中来,大家都想去揭开计算机世界那神秘的面纱。但是,源码中那些GCC的扩展语法、嵌入式汇编等生僻的用法,给很多人的成长之路设置了无形的障碍。
分析源码的过程本来就不是一片坦途,很多专家也都是通过十多年的研究才能在操作系统的某个方面取得成就的。计算机的世界其实也并不枯燥,关键是要找到其中的乐趣所在。
linux进程地址空间(2) 缺页异常详解(1)原理和内核缺页异常处理
首先明确下什么是缺页异常,CPU通过地址总线可以访问连接在地址总线上的所有外设,包括物理内存、IO设备等等,但从CPU发出的访问地址并非是这些外设在地址总线上的物理地址,而是一个虚拟地址,由MMU将虚拟地址转换成物理地址再从地址总线上发出,MMU上的这种虚拟地址和物理地址的转换关系是需要创建的,并且MMU还可以设置这个物理页是否可以进行写操作,当没有创建一个虚拟地址到物理地址的映射,或者创建了这样的映射,但那个物理页不可写的时候,MMU将会通知CPU产生了一个缺页异常。
下面总结下缺页异常的几种情况:
1、当MMU中确实没有创建虚拟页物理页映射关系,并且在该虚拟地址之后再没有当前进程的线性区vma的时候,可以肯定这是一个编码错误,这将杀掉该进程;
2、当MMU中确实没有创建虚拟页物理页映射关系,并且在该虚拟地址之后存在当前进程的线性区vma的时候,这很可能是缺页异常,并且可能是栈溢出导致的缺页异常;
3、当使用malloc/mmap等希望访问物理空间的库函数/系统调用后,由于linux并未真正给新创建的vma映射物理页,此时若先进行写操作,将如上面的2的情况产生缺页异常,若先进行读操作虽也会产生缺页异常,将被映射给默认的零页(zero_pfn),等再进行写操作时,仍会产生缺页异常,这次必须分配物理页了,进入写时复制的流程;
4、当使用fork等系统调用创建子进程时,子进程不论有无自己的vma,“它的”vma都有对于物理页的映射,但它们共同映射的这些物理页属性为只读,即linux并未给子进程真正分配物理页,当父子进程任何一方要写相应物理页时,导致缺页异常的写时复制;
目前来看,应该就是这四种情况,还是比较清晰的,可发现一个重要规律就是,linux是直到实在不行的时候才会分配物理页,把握这个原则理解的会好一些,下面详细的看缺页处理:
arm的缺页处理函数为arch/arm/mm/fault.c文件中的do_page_fault函数,关于缺页异常是怎么一步步调到这个函数的,同上一篇位置进程地址空间创建说的一样,后面会有专题文章描述这个问题,现在只关心缺页异常的处理,下面是函数do_page_fault:
static int __kprobes
do_page_fault(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
struct task_struct *tsk;
struct mm_struct *mm;
int fault, sig, code;
/*空函数*/
if (notify_page_fault(regs, fsr))
return 0;
/*获取到缺页异常的进程描述符和其内存描述符*/
tsk = current;
mm = tsk->mm;
/*
* If we're in an interrupt or have no user
* context, we must not take the fault..
*/
/*1、判断当前是否是在原子操作中(中断、可延迟函数、临界区)发生的异常
2、通过mm是否存在判断是否是内核线程,对于内核线程,进程描述符的mm总为NULL
一旦成立,说明是在内核态中发生的异常,跳到标号no_context*/
if (in_atomic() || !mm)
goto no_context;
/*
* As per x86, we may deadlock here. However, since the kernel only
* validly references user space from well defined areas of the code,
* we can bug out early if this is from code which shouldn't.
*/
if (!down_read_trylock(&mm->mmap_sem)) {
if (!user_mode(regs) && !search_exception_tables(regs->ARM_pc))
goto no_context;
down_read(&mm->mmap_sem);
} else {
/*
* The above down_read_trylock() might have succeeded in
* which case, we'll have missed the might_sleep() from
* down_read()
*/
might_sleep();
#ifdef CONFIG_DEBUG_VM
if (!user_mode(regs) &&
!search_exception_tables(regs->ARM_pc))
goto no_context;
#endif
}
fault = __do_page_fault(mm, addr, fsr, tsk);
up_read(&mm->mmap_sem);
/*
* Handle the "normal" case first - VM_FAULT_MAJOR / VM_FAULT_MINOR
*/
/*如果返回值fault不是这里面的值,那么应该会是VM_FAULT_MAJOR或VM_FAULT_MINOR,说明问题解决了,返回,一般正常情况下,__do_page_fault的返回值fault会是0(VM_FAULT_MINOR)或者其他一些值,都不是下面之后会看到的这些*/
if (likely(!(fault & (VM_FAULT_ERROR | VM_FAULT_BADMAP | VM_FAULT_BADACCESS))))
return 0;
/*如果fault是VM_FAULT_OOM这个级别的错误,那么这要杀掉进程*/
if (fault & VM_FAULT_OOM) {
/*
* We ran out of memory, call the OOM killer, and return to
* userspace (which will retry the fault, or kill us if we
* got oom-killed)
*/
pagefault_out_of_memory();
return 0;
}
/*
* If we are in kernel mode at this point, we
* have no context to handle this fault with.
*/
/*再次判断是否是内核空间出现了页异常,并且通过__do_page_fault没有没有解决,跳到到no_context*/
if (!user_mode(regs))
goto no_context;
/*下面两个情况,通过英文注释可以理解,
一个是无法修复,另一个是访问非法地址,都是要杀掉进程的错误*/
if (fault & VM_FAULT_SIGBUS) {
/*
* We had some memory, but were unable to
* successfully fix up this page fault.
*/
sig = SIGBUS;
code = BUS_ADRERR;
} else {
/*
* Something tried to access memory that
* isn't in our memory map..
*/
sig = SIGSEGV;
code = fault == VM_FAULT_BADACCESS ?
SEGV_ACCERR : SEGV_MAPERR;
}
/*给用户进程发送相应的信号,杀掉进程*/
__do_user_fault(tsk, addr, fsr, sig, code, regs);
return 0;
no_context:
/*内核引发的异常处理,如修复不畅,内核也要杀掉*/
__do_kernel_fault(mm, addr, fsr, regs);
return 0;
}
首先看第一个重点,源码片段如下:
/*1、判断当前是否是在原子操作中(中断、可延迟函数、临界区)发生的异常
2、通过mm是否存在判断是否是内核线程,对于内核线程,进程描述符的mm总为NULL,一旦成立,说明是在内核态中发生的异常,跳到标号no_context*/
if (in_atomic() || !mm)
goto no_context;
如果当前执行流程在内核态,不论是在临界区(中断/推后执行/临界区)还是内核进程本身(内核的mm为NULL),说明在内核态出了问题,跳到标号no_context进入内核态异常处理,由函数__do_kernel_fault完成,这个函数首先尽可能的设法解决这个异常,通过查找异常表中和目前的异常对应的解决办法并调用执行,这个部分的细节一直没有找到在哪里,如果找到的话留言告我一下吧!如果无法通过异常表解决,那么内核就要在打印其页表等内容后退出了!其源码如下:
static void
__do_kernel_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
/*
* Are we prepared to handle this kernel fault?
*/
/*fixup_exception()用于搜索异常表,并试图找到一个对应该异常的例程来进行修正,这个例程在fixup_exception()返回后执行*/
if (fixup_exception(regs))
return;
/*
* No handler, we'll have to terminate things with extreme prejudice.
*/
/*走到这里就说明异常确实是由于内核的程序设计缺陷导致的了,内核将产生一个oops,下面的工作就是打印CPU寄存器和内核态堆栈的信息到控制台并终结当前的进程*/
bust_spinlocks(1);
printk(KERN_ALERT
"Unable to handle kernel %s at virtual address %08lx\n",
(addr < PAGE_SIZE) ? "NULL pointer dereference" :
"paging request", addr);
/*打印内核一二级页表信息*/
show_pte(mm, addr);
/*内核产生一个oops,打印一堆东西准备退出*/
die("Oops", regs, fsr);
bust_spinlocks(0);
/*内核退出了!*/
do_exit(SIGKILL);
}
linux进程地址空间(2) 缺页异常详解(2)请求调页详解
回到函数do_page_fault,如果不是内核的缺页异常而是用户进程的缺页异常,那么调用函数__do_page_fault,这个应该是本文的重点,主要讨论的是用户进程的缺页异常,结合最前面说的用户进程产生缺页异常的四种情况,函数__do_page_fault都会排查到,源码如下:
__do_page_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
struct task_struct *tsk)
{
struct vm_area_struct *vma;
int fault;
/*搜索出现异常的地址前向最近的的vma*/
vma = find_vma(mm, addr);
fault = VM_FAULT_BADMAP;
/*如果vma为NULL,说明addr之后没有vma,所以这个addr是个错误地址*/
if (unlikely(!vma))
goto out;
/*如果addr后面有vma,但不包含addr,不能断定addr是错误地址,还需检查*/
if (unlikely(vma->vm_start > addr))
goto check_stack;
/*
* Ok, we have a good vm_area for this
* memory access, so we can handle it.
*/
good_area:
/*权限错误也要返回,比如缺页报错(由参数fsr标识)报的是不可写/不可执行的错误,但addr所属vma线性区本身就不可写/不可执行,那么就直接返回,因为问题根本不是缺页,而是vma就已经有问题*/
if (access_error(fsr, vma)) {
fault = VM_FAULT_BADACCESS;
goto out;
}
/*
* If for any reason at all we couldn't handle the fault, make
* sure we exit gracefully rather than endlessly redo the fault.
*/
/*为引发缺页的进程分配一个物理页框,它先确定与引发缺页的线性地址对应的各级页目录项是否存在,如不存在则分进行分配。具体如何分配这个页框是通过调用handle_pte_fault完成的*/
fault = handle_mm_fault(mm, vma, addr & PAGE_MASK, (fsr & FSR_WRITE) ? FAULT_FLAG_WRITE : 0);
if (unlikely(fault & VM_FAULT_ERROR))
return fault;
if (fault & VM_FAULT_MAJOR)
tsk->maj_flt++;
else
tsk->min_flt++;
return fault;
check_stack:
/*addr后面的vma的vm_flags含有VM_GROWSDOWN标志,这说明这个vma是属于栈的vma,所以addr是在栈中,有可能是栈空间不够时再进栈导致的访问错误,同时查看栈是否还能扩展,如果不能扩展(expand_stack返回非0)则确认确实是栈溢出导致,即addr确实是栈中地址,不是非法地址,应该进入缺页中的请求调页*/
if (vma->vm_flags & VM_GROWSDOWN && !expand_stack(vma, addr))
goto good_area;
out:
return fault;
}
l 首先,查看缺页异常的这个虚拟地址addr,找它后面最近的vma,如果真的没有找到,那么说明访问的地址是真的错误了,因为它根本不在所分配的任何一个vma线性区;这是一种严重错误,将返回错误码(fault)VM_FAULT_BADMAP,内核会杀掉这个进程;
l 如果addr后面有vma,但addr并未落在这个vma的区间内,这存在一种可能,要知道栈的增长方向和堆是相反的即栈是向下增长,所以也许addr实际上是栈的一个地址,它后面的vma实际上是栈的vma,栈已无法扩展,即访问addr时,这个addr并没有落在vma中所以更无二级页表映射,导致缺页异常,所以查看addr后面的vma是否是向下增长并且栈是否无法扩展,以此界定addr是不是栈地址,如果是则进入缺页异常处理流程,否则同样返回错误码(fault)VM_FAULT_BADMAP,内核会杀掉这个进程;
l 权限错误也就返回,比如缺页报错(fsr)报的是不可写,但vma本身就不可写,那么就直接返回,因为问题根本不是缺页,而是vma就已经有问题;返回错误码(fault) VM_FAULT_BADACCESS,这也是一种严重错误,内核会杀掉这个进程;s
l 最后是对确实缺页异常的情况进行处理,调用函数handle_mm_fault,正常情况下将返回VM_FAULT_MAJOR或VM_FAULT_MINOR,返回错误码fault并加一task的maj_flt或min_flt成员;
函数handle_mm_fault,就是为引发缺页的进程分配一个物理页框,它先确定与引发缺页的线性地址对应的各级页目录项是否存在,如不存在则分进行分配。具体如何分配这个页框是通过调用handle_pte_fault()完成的,注意最后一个参数flag,它来源于fsr,标识写异常和非写异常,这是为了达到进一步推后分配物理内存的一个铺垫;源码如下:
int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
__set_current_state(TASK_RUNNING);
count_vm_event(PGFAULT);
if (unlikely(is_vm_hugetlb_page(vma)))
return hugetlb_fault(mm, vma, address, flags);
/*返回addr对应的一级页表条目*/
pgd = pgd_offset(mm, address);
/*对于arm,pud就是pgd*/
pud = pud_alloc(mm, pgd, address);
if (!pud)
return VM_FAULT_OOM;
/*对于arm,pmd就是pud就是pgd*/
pmd = pmd_alloc(mm, pud, address);
if (!pmd)
return VM_FAULT_OOM;
/*返回addr对应的二级页表条目*/
pte = pte_alloc_map(mm, pmd, address);
if (!pte)
return VM_FAULT_OOM;
/*该函数根据页表项pte所描述的物理页框是否在物理内存中,分为两大类:
请求调页:被访问的页框不在主存中,那么此时必须分配一个页框,分为线性(匿名/文件)映射、非线性映射、swap情况下映射
写时复制:被访问的页存在,但是该页是只读的,内核需要对该页进行写操作,
此时内核将这个已存在的只读页中的数据复制到一个新的页框中*/
return handle_pte_fault(mm, vma, address, pte, pmd, flags);
}
首先注意下个细节,在二级页表条目不存在时,会先创建条目;最终会调用函数handle_pte_fault,该函数功能注释已经描述很清楚,源码如下:
static inline int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, unsigned int flags)
{
pte_t entry;
spinlock_t *ptl;
entry = *pte;
/*调页请求:分为线性(匿名/文件)映射、非线性映射、swap情况下映射
注意,pte_present(entry)为0说明二级页表条目pte映射的物理地址(即*pte)不存在,很可能是调页请求*/
if (!pte_present(entry)) {
/*(pte_none(entry))为1说明二级页表条目pte尚且没有写入任何物理地址,说明还根本从未分配物理页*/
if (pte_none(entry)) {
/*如果该vma的操作函数集合实现了fault函数,说明是文件映射而不是匿名映射,将调用do_linear_fault分配物理页*/
if (vma->vm_ops) {
if (likely(vma->vm_ops->fault))
return do_linear_fault(mm, vma, address,
pte, pmd, flags, entry);
}
/*匿名映射的情况分配物理页,最终调用alloc_pages*/
return do_anonymous_page(mm, vma, address,
pte, pmd, flags);
}
/*(pte_file(entry))说明是非线性映射,调用do_nonlinear_fault分配物理页*/
if (pte_file(entry))
return do_nonlinear_fault(mm, vma, address,
pte, pmd, flags, entry);
/*如果页框事先被分配,但是此刻已经由主存换出到了外存,则调用do_swap_page()完成页框分配*/
return do_swap_page(mm, vma, address,
pte, pmd, flags, entry);
}
/*写时复制
COW的场合就是访问映射的页不可写,有两种情况、:
一种是之前给vma映射的是零页(zero_pfn),
另外一种是访问fork得到的进程空间(子进程与父进程共享父进程的只读页)
共同特点就是: 二级页表条目不允许写,简单说就是该页不可写*/
ptl = pte_lockptr(mm, pmd);
spin_lock(ptl);
if (unlikely(!pte_same(*pte, entry)))
goto unlock;
/*是写操作时发生的缺页异常*/
if (flags & FAULT_FLAG_WRITE) {
/*二级页表条目不允许写,引发COW*/
if (!pte_write(entry))
return do_wp_page(mm, vma, address,
pte, pmd, ptl, entry);
/*标志本页已脏*/
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vma, address, pte, entry, flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vma, address, entry);
} else {
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (flags & FAULT_FLAG_WRITE)
flush_tlb_page(vma, address);
}
unlock:
pte_unmap_unlock(pte, ptl);
return 0;
}
回过头看下那四个异常的情况,上面的内容会比较好理解些,首先获取到二级页表条目值entry,对于写时复制的情况,它的异常addr的二级页表条目还是存在的(就是说起码存在标志L_PTE_PRESENT),只是说映射的物理页不可写,所以由(!pte_present(entry))可界定这是请求调页的情况;
在请求调页情况下,如果这个二级页表条目的值为0,即什么都没有,那么说明这个地址所在的vma是完完全全没有做过映射物理页的操作,那么根据该vma是否存在vm_ops成员即操作函数,并且vm_ops存在fault成员,这说明是文件映射而非匿名映射,反之是匿名映射,分别调用函数do_linear_fault、do_anonymous_page;
仍然在请求调页的情况下,如果二级页表条目的值含有L_PTE_FILE标志,说明这是个非线性文件映射,将调用函数do_nonlinear_fault分配物理页;其他情况视为物理页曾被分配过,但后来被linux交换出内存,将调用函数do_swap_page再分配物理页;
文件线性/非线性映射和交换分区的映射除请求调页方面外,还涉及文件、交换分区的很多内容,为简化起见,下面仅以匿名映射为例描述用户空间缺页异常的实际处理,而事实上日常使用的malloc都是匿名映射;
匿名映射体现了linux为进程分配物理空间的基本态度,不到实在不行的时候不分配物理页,当使用malloc/mmap申请映射一段物理空间时,内核只是给该进程创建了段线性区vma,但并未映射物理页,然后如果试图去读这段申请的进程空间,由于未创建相应的二级页表映射条目,MMU会发出缺页异常,而这时内核依然只是把一个默认的零页zero_pfn(这是在初始化时创建的,前面的内存页表的文章描述过)给vma映射过去,当应用程序又试图写这段申请的物理空间时,这就是实在不行的时候了,内核才会给vma映射物理页,源码如下:
static int do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags)
{
struct page *page;
spinlock_t *ptl;
pte_t entry;
/*如果不是写操作的话(即读操作),那么非常简单,把zero_pfn的二级页表条目赋给entry,因为这里已经是缺页异常的请求调页的处理,又是读操作,所以肯定是本进程第一次访问这个页,所以这个页里面是什么内容无所谓,分配个默认全零页就好,进一步推迟物理页的分配,这就会让entry带着zero_pfn跳到标号setpte*/
if (!(flags & FAULT_FLAG_WRITE)) {
entry = pte_mkspecial(pfn_pte(my_zero_pfn(address),
vma->vm_page_prot));
ptl = pte_lockptr(mm, pmd);
spin_lock(ptl);
/*如果这个缺页的虚拟地址对应的二级页表条目所映射的内容居然在内存中,直接跳到标号unlock准备解锁返回*/
if (!pte_none(*page_table))
goto unlock;
/*跳到标号setpte就是写二级页表条目的内容即映射内容,对于这类就是把entry即zero_pfn写进去了*/
goto setpte;
}
/*如果是写操作,就要分配一个新的物理页了*/
/* Allocate our own private page. */
/*这里为空函数*/
pte_unmap(page_table);
/*分配一个anon_vma实例,反向映射相关,可暂不关注*/
if (unlikely(anon_vma_prepare(vma)))
goto oom;
/*它将调用alloc_page,这个页被0填充*/
page = alloc_zeroed_user_highpage_movable(vma, address);
if (!page)
goto oom;
__SetPageUptodate(page);
/*空函数*/
if (mem_cgroup_newpage_charge(page, mm, GFP_KERNEL))
goto oom_free_page;
/*把该页的物理地址加属性的值赋给entry,这是二级页表映射内容的基础值*/
entry = mk_pte(page, vma->vm_page_prot);
/*如果是写访问,那么设置这个二级页表条目属性还要加入:脏且可写*/
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
/*把page_table指向虚拟地址addr的二级页表条目地址*/
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
/*如果这个缺页的虚拟地址对应的二级页表条目所映射的内容居然在内存中,报错返回*/
if (!pte_none(*page_table))
goto release;
/*mm的rss成员加一,用于记录分配给本进程的物理页总数*/
inc_mm_counter(mm, anon_rss);
/*page_add_new_anon_rmap用于建立线性区和匿名页的反向映射,可暂不关注*/
page_add_new_anon_rmap(page, vma, address);
setpte:
/*给page_table这个二级页表条目写映射内容,内容是entry*/
set_pte_at(mm, address, page_table, entry);
/* No need to invalidate - it was non-present before */
/*更新MMU*/
update_mmu_cache(vma, address, entry);
unlock:
pte_unmap_unlock(page_table, ptl);
return 0;
release:
mem_cgroup_uncharge_page(page);
page_cache_release(page);
goto unlock;
oom_free_page:
page_cache_release(page);
oom:
return VM_FAULT_OOM;
}
linux进程地址空间(2) 缺页异常详解(3)写时复制COW详解
现在分析写时复制COW,对于写时复制,首先把握一点就是只有写操作时才有可能触发写时复制,所以首先总要判断异常flag是否含有标志FAULT_FLAG_WRITE,然后判断二级页表条目值是否含有L_PTE_WRITE标志,这是意味着这个物理页是否可写,如果不可写则说明应该进入写时复制流程,调用处理函数do_wp_page;
可见,COW的应用场合就是访问映射的页不可写,它包括两种情况,第一种是fork导致,第二种是如malloc后第一次对他进行读操作,获取到的是zero_pfn零页,当再次写时需要写时复制,共同特点都是虚拟地址的二级页表映射内容在内存中,但是对应的页不可写,在函数do_wp_page中对于这两种情况的处理基本相似的;
另外一个应该知道的是,如果该页只有一个进程在用,那么就直接修改这个页可写就行了,不要搞COW,总之,不到不得以的情况下是不会进行COW的,这也是内核对于COW使用的原则,就是尽量不使用;
函数do_wp_page源码如下:
static int do_wp_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
spinlock_t *ptl, pte_t orig_pte)
{
struct page *old_page, *new_page;
pte_t entry;
int reuse = 0, ret = 0;
int page_mkwrite = 0;
struct page *dirty_page = NULL;
/*返回不可写的页的页描述符,如果是COW的第一种情况即zero_pfn可读页,返回NULL,将进入下面的if流程;第二种情况即(父子进程)共享页将正常返回其页描述符*/
old_page = vm_normal_page(vma, address, orig_pte);
if (!old_page) {
/*
* VM_MIXEDMAP !pfn_valid() case
*
* We should not cow pages in a shared writeable mapping.
* Just mark the pages writable as we can't do any dirty
* accounting on raw pfn maps.
*/
/*如果这个vma是可写且共享的,跳到标号reuse,这就不会COW
否则跳到标号gotten*/
if ((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))
goto reuse;
goto gotten;
}
/*
* Take out anonymous pages first, anonymous shared vmas are
* not dirty accountable.
*/
/*下面的if和else流程,都是为了尽可能不进行COW,它们试图进入标号reuse*/
/*如果该页old_page是匿名页(由页描述符的mapping),
并且只有一个进程使用该页(reuse_swap_page,由页描述符的_mapcount值是否为0),那么不要搞什么COW了,这个进程就是可以使用该页*/
if (PageAnon(old_page) && !PageKsm(old_page)) {
/*排除其他进程在使用该页的情况,由页描述符的flag*/
if (!trylock_page(old_page)) {
page_cache_get(old_page);
pte_unmap_unlock(page_table, ptl);
lock_page(old_page);
page_table = pte_offset_map_lock(mm, pmd, address,
&ptl);
if (!pte_same(*page_table, orig_pte)) {
unlock_page(old_page);
page_cache_release(old_page);
goto unlock;
}
page_cache_release(old_page);
}
/*判断该页描述符的_mapcount值是否为0*/
reuse = reuse_swap_page(old_page);
unlock_page(old_page);
}
/*如果vma是共享且可写,看看这种情况下有没有机会不COW*/
else if (unlikely((vma->vm_flags & (VM_WRITE|VM_SHARED)) ==
(VM_WRITE|VM_SHARED))) {
/*
* Only catch write-faults on shared writable pages,
* read-only shared pages can get COWed by
* get_user_pages(.write=1, .force=1).
*/
if (vma->vm_ops && vma->vm_ops->page_mkwrite) {
struct vm_fault vmf;
int tmp;
vmf.virtual_address = (void __user *)(address &
PAGE_MASK);
vmf.pgoff = old_page->index;
vmf.flags = FAULT_FLAG_WRITE|FAULT_FLAG_MKWRITE;
vmf.page = old_page;
/*
* Notify the address space that the page is about to
* become writable so that it can prohibit this or wait
* for the page to get into an appropriate state.
*
* We do this without the lock held, so that it can
* sleep if it needs to.
*/
page_cache_get(old_page);
pte_unmap_unlock(page_table, ptl);
tmp = vma->vm_ops->page_mkwrite(vma, &vmf);
if (unlikely(tmp &
(VM_FAULT_ERROR | VM_FAULT_NOPAGE))) {
ret = tmp;
goto unwritable_page;
}
if (unlikely(!(tmp & VM_FAULT_LOCKED))) {
lock_page(old_page);
if (!old_page->mapping) {
ret = 0; /* retry the fault */
unlock_page(old_page);
goto unwritable_page;
}
} else
VM_BUG_ON(!PageLocked(old_page));
/*
* Since we dropped the lock we need to revalidate
* the PTE as someone else may have changed it. If
* they did, we just return, as we can count on the
* MMU to tell us if they didn't also make it writable.
*/
page_table = pte_offset_map_lock(mm, pmd, address,
&ptl);
if (!pte_same(*page_table, orig_pte)) {
unlock_page(old_page);
page_cache_release(old_page);
goto unlock;
}
page_mkwrite = 1;
}
dirty_page = old_page;
get_page(dirty_page);
reuse = 1;
}
/*reuse: 不进行COW,直接操作该页old_page*/
if (reuse) {
reuse:
flush_cache_page(vma, address, pte_pfn(orig_pte));
entry = pte_mkyoung(orig_pte);
/*写该页的二级页表属性,加入可写且脏*/
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
if (ptep_set_access_flags(vma, address, page_table, entry,1))
update_mmu_cache(vma, address, entry);
ret |= VM_FAULT_WRITE;
goto unlock;
}
/*
* Ok, we need to copy. Oh, well..
*/
/*真正的COW即将开始*/
/*首先增加之前的页的被映射次数(get_page(), page->_count)*/
page_cache_get(old_page);
gotten:
pte_unmap_unlock(page_table, ptl);
if (unlikely(anon_vma_prepare(vma)))
goto oom;
/*COW的第一种情况(zero_pfn),将分配新页并清零该页*/
if (is_zero_pfn(pte_pfn(orig_pte))) {
new_page = alloc_zeroed_user_highpage_movable(vma, address);
if (!new_page)
goto oom;
}
/*COW的第二种情况(fork),申请一个页,并把old_page页的内容拷贝到新页new_page(4K字节的内容)*/
else {
new_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
if (!new_page)
goto oom;
cow_user_page(new_page, old_page, address, vma);
}
__SetPageUptodate(new_page);
/*
* Don't let another task, with possibly unlocked vma,
* keep the mlocked page.
*/
/*COW第二种情况下,如果vma还是锁定的,那还需要解锁*/
if ((vma->vm_flags & VM_LOCKED) && old_page) {
lock_page(old_page); /* for LRU manipulation */
clear_page_mlock(old_page);
unlock_page(old_page);
}
/*空函数*/
if (mem_cgroup_newpage_charge(new_page, mm, GFP_KERNEL))
goto oom_free_new;
/*
* Re-check the pte - we dropped the lock
*/
/*再获取下访问异常的地址addr对应的二级页表条目地址page_table*/
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
if (likely(pte_same(*page_table, orig_pte))) {
if (old_page) {
if (!PageAnon(old_page)) {
dec_mm_counter(mm, file_rss);
inc_mm_counter(mm, anon_rss);
}
} else
inc_mm_counter(mm, anon_rss);
flush_cache_page(vma, address, pte_pfn(orig_pte));
/*写新页的二级页表条目内容为脏*/
entry = mk_pte(new_page, vma->vm_page_prot);
entry = maybe_mkwrite(pte_mkdirty(entry), vma);
/*
* Clear the pte entry and flush it first, before updating the
* pte with the new entry. This will avoid a race condition
* seen in the presence of one thread doing SMC and another
* thread doing COW.
*/
ptep_clear_flush(vma, address, page_table);
page_add_new_anon_rmap(new_page, vma, address);
/*
* We call the notify macro here because, when using secondary
* mmu page tables (such as kvm shadow page tables), we want the
* new page to be mapped directly into the secondary page table.
*/
set_pte_at_notify(mm, address, page_table, entry);
update_mmu_cache(vma, address, entry);
if (old_page) {
/*
* Only after switching the pte to the new page may
* we remove the mapcount here. Otherwise another
* process may come and find the rmap count decremented
* before the pte is switched to the new page, and
* "reuse" the old page writing into it while our pte
* here still points into it and can be read by other
* threads.
*
* The critical issue is to order this
* page_remove_rmap with the ptp_clear_flush above.
* Those stores are ordered by (if nothing else,)
* the barrier present in the atomic_add_negative
* in page_remove_rmap.
*
* Then the TLB flush in ptep_clear_flush ensures that
* no process can access the old page before the
* decremented mapcount is visible. And the old page
* cannot be reused until after the decremented
* mapcount is visible. So transitively, TLBs to
* old page will be flushed before it can be reused.
*/
page_remove_rmap(old_page);
}
/* Free the old page.. */
new_page = old_page;
ret |= VM_FAULT_WRITE;
}
else
mem_cgroup_uncharge_page(new_page);
if (new_page)
page_cache_release(new_page);
if (old_page)
page_cache_release(old_page);
unlock:
pte_unmap_unlock(page_table, ptl);
if (dirty_page) {
/*
* Yes, Virginia, this is actually required to prevent a race
* with clear_page_dirty_for_io() from clearing the page dirty
* bit after it clear all dirty ptes, but before a racing
* do_wp_page installs a dirty pte.
*
* do_no_page is protected similarly.
*/
if (!page_mkwrite) {
wait_on_page_locked(dirty_page);
set_page_dirty_balance(dirty_page, page_mkwrite);
}
put_page(dirty_page);
if (page_mkwrite) {
struct address_space *mapping = dirty_page->mapping;
set_page_dirty(dirty_page);
unlock_page(dirty_page);
page_cache_release(dirty_page);
if (mapping) {
/*
* Some device drivers do not set page.mapping
* but still dirty their pages
*/
balance_dirty_pages_ratelimited(mapping);
}
}
/* file_update_time outside page_lock */
if (vma->vm_file)
file_update_time(vma->vm_file);
}
return ret;
oom_free_new:
page_cache_release(new_page);
oom:
if (old_page) {
if (page_mkwrite) {
unlock_page(old_page);
page_cache_release(old_page);
}
page_cache_release(old_page);
}
return VM_FAULT_OOM;
unwritable_page:
page_cache_release(old_page);
return ret;
}
一级一级返回,最终返回到函数__do_page_fault,会根据返回值fault累计task的相应异常类型次数(maj_flt或min_flt),并最终把fault返回给函数do_page_fault,释放信号量mmap_sem,正常情况下就返回0,缺页异常处理完毕。