2019独角兽企业重金招聘Python工程师标准>>> 
Elasticsearch是什么
Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎。它可以在很短的时间内存储,搜索和分析大量的数据。它通常作为具有复杂搜索场景情况下的核心发动机。我们举几个例子来说明Elasticsearch能做什么?
当你经营一家网上商店,你可以让你的客户搜索你卖的商品。在这种情况下,你可以使用Elasticsearch来存储您的整个产品目录和库存信息,为客户提供精准搜索,可以为客户推荐相关商品。
当你想收集日志或者交易数据的时候,要分析和挖掘这些数据,寻找趋势,统计,总结,或异常。在这种情况下,你可以使用LogStash 或者其他工具来进行收集数据,当这些数据存储到Elasticsearch中 。你可以搜索和汇总这些数据,找到任何你感兴趣的信息。
当你运行一个价格提醒的平台,可以给客户提供一些规则,如我有兴趣购买一个特定的电子设备,当商品的价格在未来一个月内的价格低于多少钱的时候通知我。在这种情况下,你可以把供应商的价格,把他们定期存储到Elasticsearch中,使用定时器过滤的能力来匹配客户的需求,当查询到价格低于客户设定的值后给客户发送一条通知。
当你有商业智能分析的需求时,你希望快速调查,分析和可视化,并有大量的数据(千万条记录)的时候。在这种情况下,你可以使用Elasticsearch来存储你的数据,然后用Kibana建立自定义的仪表板或者任何你熟悉的语言开发展示界面,您可以使用Elasticsearch的聚合功能来执行复杂的商业智能与数据查询。
本文由赛克蓝德(secisland)原创,转载请标明作者和出处。
对于码农来说,比较有名的案例是github,gihtub 的搜索是基于 Elasticsearch 构建的,在 github.com/search 页面,你可以检索项目、用户、issue、pull request,还有代码。共有 40-50个 索引库,分别用于索引网站需要跟踪的各种数据。虽然只索引项目的主分支(master),但这个数据量依然巨大,20亿索引文档,30TB的索引文件。
Elasticsearch的核心概念
下面介绍Elasticsearch的几个核心概念,准实时索引(Near Realtime),集群(cluster),节点(node), 索引(index),类型(type),文档(document),分片和复制(shards Replicas)。
准实时索引(Near Realtime)
Elasticsearch是准实时搜索平台。这意味着有轻微的延迟(通常为1秒)就可以从入库建索引文件到已经进行关键字搜索。
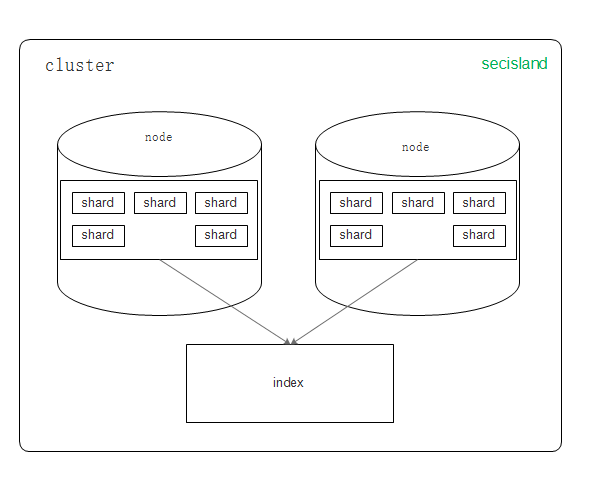
集群(cluster)
集群是由一个或多个节点组成,对外提供服务,对外提供索引和搜索功能。在所有节点,一个集群有一个唯一的名称默认为“Elasticsearch”。此名称是很重要的,因为每个节点只能是群集的一部分,当该节点被设置为相同的名称时,就会自动加入群集。当需要有多个集群的时候,要确保每个集群的名称不能重复,否则,节点可能会加入错误的群集。请注意,一个节点只能加入一个集群。此外,您还可以拥有多个独立的集群,每个集群都有其不同的集群名称。例如,在开发过程中,你可以建立开发集群库和测试集群库,分别为开发,测试服务。
节点(node)
一个节点是一个逻辑上独立的服务,它是群集的一部分,可以存储数据,并参与集群的索引和搜索功能。就像集群一样,一个节点也有唯一的名字,默认是一个随机的和机器相关的名称,在启动的时候分配。如果你不想要的默认值,你可以定义任何你想要的节点名。这个名字在管理中很重要,在网络中Elasticsearch群集通过节点名称进行管理和通信。一个节点可以被配置为加入一个特定的群集。默认情况下,每个节点会加入名为Elasticsearch的集群中,这意味着如果你在网络上启动多个节点,如果网络畅通,他们能彼此发现并自动加入一个名为Elasticsearch的集群中。在一个单一的集群中,你可以拥有多个你想要的节点。当网络没有集群运行的时候,只要启动任何一个节点,这个节点会默认生成一个新的集群,这个集群会有一个节点。
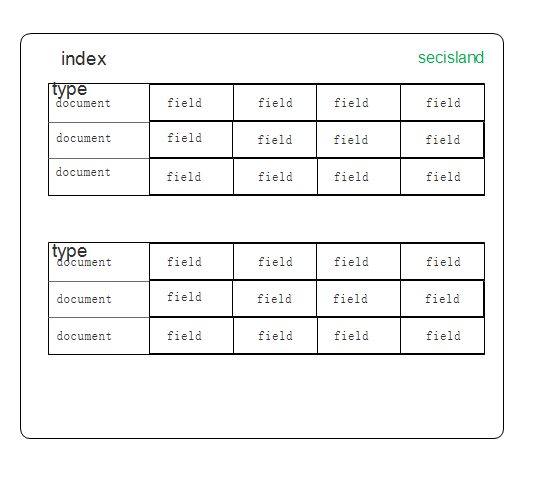
索引(index)
索引是有点结构的文档集合。例如,可以有一个客户数据的索引,另一个是产品目录的索引,还有一个订单数据的索引。一个索引是一个名称(必须是全部小写),这个名字是用来指在执行索引、搜索、更新和删除操作时对文档的索引。在一个单一的集群中,您可以定义多个你想要的索引。
类型(type)
在索引中,可以定义一个或多个类型。类型是索引的逻辑分区。在一般情况下,一种类型被定义为具有一组公共字段的文档。例如,让我们假设你运行一个博客平台,并把所有的数据存储在一个索引中。在这个索引中,您可以定义一个类型为用户数据,另一种类型为博客数据,另一种类型的评论数据。
文档(document)
文档是可以被索引的基本单位。例如,你可以有一个的客户文档,有一个产品文档,还有一个订单的文档。文档是以JSON(JavaScript Object Notation)格式存储的。在一个索引中,您可以存储多个的文档。请注意,虽然在一个索引中有多分文档,但这些文档的结构是一致的,并在第一次存储的时候指定。
分片(shards)
一个索引可以存储很大的数据,这些空间可以超过一个节点的物理存储的限制。例如,十亿个文档占用磁盘空间为1TB。仅从单个节点搜索可能会很慢,还有一台物理机器也不一定能存储这么多的数据。为了解决这一问题,Elasticsearch将索引分解成多个分片。当你创建一个索引,你可以简单地定义你想要的分片数量。每个分片本身是一个全功能的、独立的单元,可以托管在集群中的任何节点。
分片主要有两个很重要的原因是:
1、它允许你水平分割扩展你的数据。
2、它允许你分配和并行操作(可能在多个节点上)从而提高性能和吞吐量
这些很强大的功能对用户来说是透明的,你不需要做什么操作,系统会自动处理。
复制(Replicas)
复制是一个非常有用的功能,不然会有单点问题。当网络中的某个节点出现问题的时候,复制可以对故障进行转移,保证系统的高可用。因此,Elasticsearch允许你创建一个或多个拷贝,你的索引分片就形成了所谓的副本或副本分片。
复制是重要的,主要的原因有:
1、它提供了高可用性,当节点失败的时候不受影响。需要注意的是,一个复制的分片不会存储在同一个节点中。
2、它允许您扩展您的搜索量,提高并发量,因为搜索可以在所有副本上并行的执行。
总结一下,每个索引可以拆分成多个分片。索引可以复制零个或者多个分片。一旦复制,每个索引就有了主分片和复本分片。分片的数量和副本的数量可以在创建索引时定义。当创建索引后,你可以随时改变副本的数量,但你不能改变分片的数量。
默认情况下,每个索引分配5个分片和1个副本,这意味着你的集群节点至少要有两个节点,你将拥有5个主要的分片和5个副本分片共有10个分片。
注:每个Elasticsearch分片是一个Lucene的索引。有文档,你可以在一个单一的Lucene索引中存储的最大值为lucene-5843,极限是2147483519(= integer.max_value - 128)个文档。你可以使用_cat/shards api监控碎片的大小。
赛克蓝德(secisland)后续会逐步对Elasticsearch的最新版本的各项功能进行分析,近请期待。