hadoop集群环境搭建教程(超级详细)
搭建hadoop集群环境教程
文章目录
- 搭建hadoop集群环境教程
- 1、硬件条件
- 2、虚拟机安装
- 2.1、虚拟机搭建
- 2.2、完成操作系统搭建并登记IP
- 2.3、修改hosts
- 3、JDK配置
- 3.1、安装JDK
- 3.2、查看JDK是否安装成功
- 4、ssh配置
- 4.1、前置条件
- 4.2、安装ssh
- 4.3、生成密匙
- 4.4、发送公匙
- 4.5、关闭防火墙
- 4.6、测试ssh是否成功
- 5、hadoop配置
- 5.1、安装hadoop
- 5.2、设置java环境变量
- 5.3、修改三个xml
- 5.4、配置conf/masters和conf/slaves
- 5.5、hadoop部署
- 5.6、判断启动成功
- 5.7、配置hadoop环境变量
- 5.8、关闭hadoop
- 6、报错解决
- 6.1、ssh配置好了还需要输入密码
- 6.2、启动hadoop提示权限不足
- 6.3、启动集群后用jps查看没有(datanode、live nodes)
请注意,如果没有特别提醒,所有操作均需要五台虚拟机同步进行!
1、硬件条件
- 虚拟机软件:VMware 12
- 操作系统:5台Ubuntu 16.04(确保你的电脑配置够,至少需要8G内存)
- JDK:jdk-7u79-linux-x64
- Hadoop:hadoop-0.20.2
JDK和Hadoop我将打包为百度云链接下载(当然你也可以自己下载)
链接:https://pan.baidu.com/s/1i0srl8F8j5rI2lFFw5nqDA
提取码:qcb5
2、虚拟机安装
一共需要5台虚拟机,1台master,4台slave
2.1、虚拟机搭建
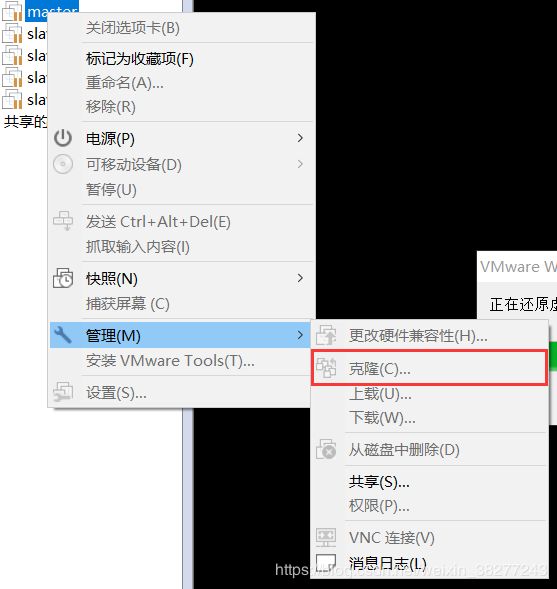
我的办法是先搭建1个ubuntu 16.04虚拟机(语言、分辨率、配套软件都设置好)然后再克隆4台,省时间
克隆的方法如下图
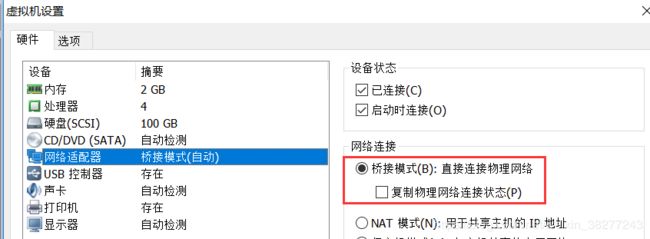
另外需要注意的是:虚拟机的网络请选择桥接模式,否则虚拟机之前无法通信
2.2、完成操作系统搭建并登记IP
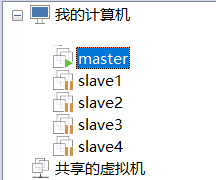
现在已经建立了5台虚拟机,然后请依次命名为
master、slave1、slave2、slave3、slave4
然后分别启动,对每一台机器输入以下指令查询ip地址并且记录
ifconfig -a
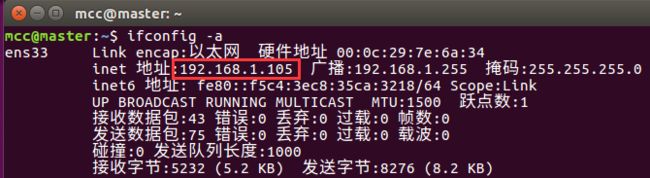
先把这些IP记录下来保存到一个文档(我的机器是这样)
192.168.1.105 master
192.168.1.107 slave1
192.168.1.108 slave2
192.168.1.109 slave3
192.168.1.110 slave4
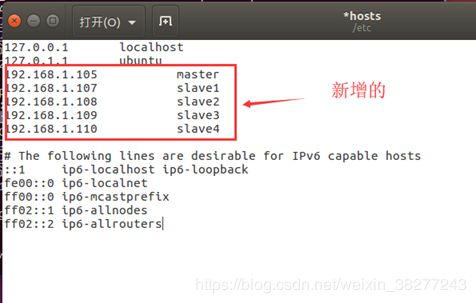
2.3、修改hosts
在每台机器中输入以下代码来修改hosts
sudo gedit /etc/hosts
修改格式如下(请按照自己上一步中记录的IP来修改,每台机器都要修改!)
然后再用maste机去ping其他所有的机器看是否能ping通,通了就说明第二步配置完成
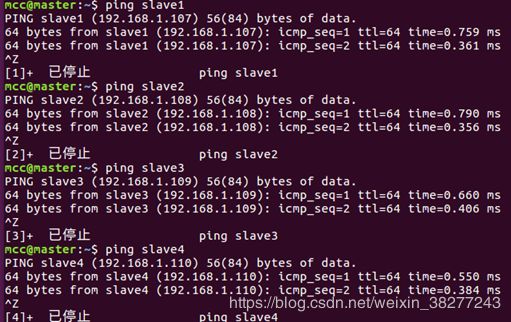
PS:按ctrl + c 来结束ping的过程,不按的话会一直ping下去
这样第二步就大功告成了!
3、JDK配置
3.1、安装JDK
将下载好的JDK分别复制到每一台虚拟机的桌面
输入以下代码来将JDK移动到制定目录
(正常情况应该装到lib目录,我这里装到bin目录了,不过不影响,可以跟着我的走)
sudo mv Desktop/jdk-7u79-linux-x64.tar.gz /usr/bin
然后添加环境变量,输入以下代码编辑profile
sudo gedit /etc/profile
再这个文件的最末尾粘贴上以下代码
export JAVA_HOME=/usr/bin/jdk1.7.0_79
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
需要注意的是,你装到哪个目录就得修改JAVA_HOME的值为对应的路径
然后运行以下代码使得环境变量立即生效
source /etc/profile
然后提升java.sh的权限:
chmod 775 /etc/profile.d/java.sh
最后再在运行以下代码
sudo update-alternatives --install /usr/bin/java java /usr/bin/jdk1.7.0_79/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/bin/jdk1.7.0_79/bin/javac 300
sudo update-alternatives --install /usr/bin/jar jar /usr/bin/jdk1.7.0_79/bin/jar 300
如果目录和我一样,就不用看这句话了。
如果目录和我不一样,需要注意的是,路径得选自己对应的路径,还有三行中间的 java javac jar和前后都有空格的,不要去掉了,不然会报错
3.2、查看JDK是否安装成功
到这里基本上就成功了
输入以下代码查看jdk版本
java –version

我这里已经安装成功了
4、ssh配置
ssh是为了免密通信,本质上是为了方便使用,每次链接去掉输入密码的繁琐
原理:用master机生成一个ras密匙和一个公匙,这两个钥匙相互对应,把其中的公匙复制到所有slave机里对应的文件夹,之后master用ssh链接其他的slave机器就不用输入密码了
4.1、前置条件
如果安装ssh提示本机ssh client版本过高的话则需要降级
输入以下代码降级
sudo apt-get install openssh-client=1:7.2p2-4
4.2、安装ssh
输入以下代码安装ssh
sudo apt-get install ssh
用chmod将.ssh/目录权限提升到700
4.3、生成密匙
输入以下代码生成密匙
ssh-keygen -t rsa
然后会在你ssh安装的目录下生成密匙和公匙,其中.pub后缀的是公匙
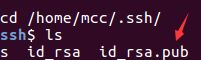
先移动到安装目录下,然后将公匙拷贝一份修改名字为authorized_keys
cd /home/mcc/.ssh/
cp id_rsa.pub authorized_keys
这时.ssh目录下应该有三个文件
![]()
用chmod将.ssh/目录下的authorized_keys权限提升到600
4.4、发送公匙
将公匙发送到所有slave机器,注意对应的名字和目录,自己做相应的修改
scp authorized_keys mcc@slave1:/home/mcc/.ssh/
scp authorized_keys mcc@slave2:/home/mcc/.ssh/
scp authorized_keys mcc@slave3:/home/mcc/.ssh/
scp authorized_keys mcc@slave4:/home/mcc/.ssh/
4.5、关闭防火墙
不关闭防火墙无法通信,所以必须关闭所有机器的防火墙
sudo ufw disable
然后再去网上查下ubuntu16.04怎么查看防火墙状态,确认关闭了
4.6、测试ssh是否成功
用master去ssh所有slave机器看是不是不需要密码就能连上
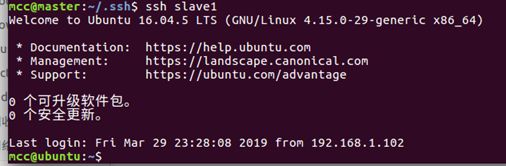
请打开多个终端,每个终端仅ssh一个slave,因为你一旦ssh成功,这个终端就是slave了,而你要测试的是master是否能免密登录slave
到现在我们做的所有的,只能让master去免密链接所有slave,而不能让slave免密链接master,也不能让slave免密互相链接,原因自己想。
5、hadoop配置
5.1、安装hadoop
将下载好的hadoop(前面提供了)复制到每一台虚拟机中桌面,然后移动到对应的目录,
我这里是在ubuntu根目录下的/opt/目录下新建了一个hadoop目录用于安装hadoop
提前创建好这三个目录后面要用
/opt/hadoop/
/opt/hadoop/hdfs
/opt/hadoop/tmp
sudo mv /home/mcc/Desktop/hadoop-0.20.2.tar.gz /opt/hadoop/
sudo tar -zxvf hadoop-0.20.2.tar.gz
5.2、设置java环境变量
解压后,cd到/opt/hadoop/hadoop-0.20.2/目录下输入以下代码
sudo vim conf/hadoop-env.sh
然后修改下图对应位置代码为
export JAVA_HOME=/usr/bin/jdk1.7.0_79

然后保存退出
5.3、修改三个xml
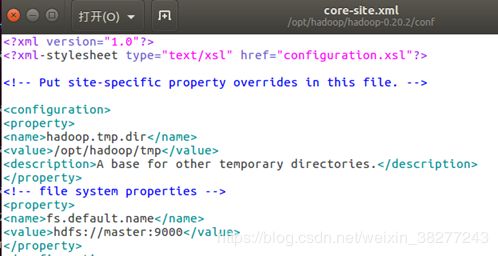
①core-site.xml
sudo gedit hadoop-0.20.2/conf/core-site.xml
增加代码
hadoop.tmp.dir
/opt/hadoop/tmp
A base for other temporary directories.
fs.default.name
hdfs://master:9000
增加后如下图
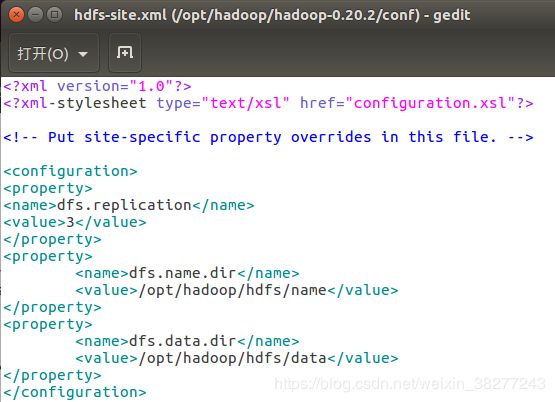
②hdfs-site.xml
sudo gedit hadoop-0.20.2/conf/hdfs-site.xml
增加代码
dfs.replication
3
(replication 是数据副本数量,默认为3,datanode 少于3台就会报错)
dfs.name.dir
/opt/hadoop/hdfs/name
dfs.data.dir
/opt/hadoop/hdfs/data
增加后如下图
③mapred-site.xml
sudo gedit hadoop-0.20.2/conf/mapred-site.xml
增加代码
mapred.job.tracker
master:9001
增加后如下图
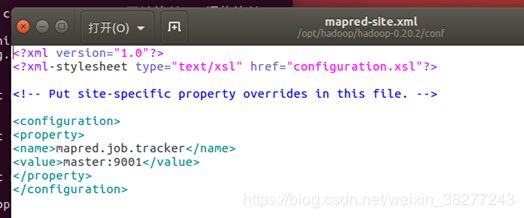
特别提醒:三个xml的顶部一定不能有空行,否则会报错
5.4、配置conf/masters和conf/slaves
配置masters
sudo gedit hadoop-0.20.2/conf/masters
将打开的文档修改为如下
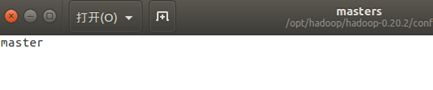
配置slaves
sudo gedit hadoop-0.20.2/conf/slaves
将打开的文档修改为如下
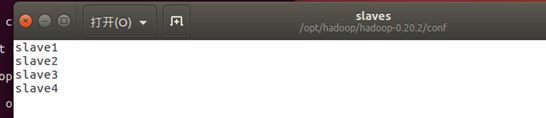
5.5、hadoop部署
到这里大部分前置工作都完成了,现在正式开始部署hadoop,如果以下步骤遇到问题请往下翻,下面有解决策略
格式化hadoop
本操作只需要在master中进行,其他的slave不要动
先cd到hadoop-0.20.2目录下再进行以下操作
./bin/hadoop namenode -format
请注意以上命令不要用sudo!!!!
请注意以上命令不要用sudo!!!!
请注意以上命令不要用sudo!!!!
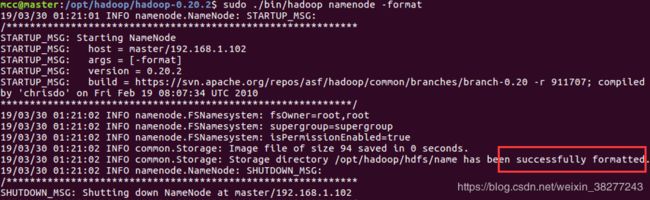
出现successfully即表示成功
开启hadoop
./bin/start-all.sh
请注意以上命令不要用sudo!!!!
请注意以上命令不要用sudo!!!!
请注意以上命令不要用sudo!!!!
5.6、判断启动成功
①在master机器上输入jps命令
能看到四个进程再运行,其中一定要看到NameNode
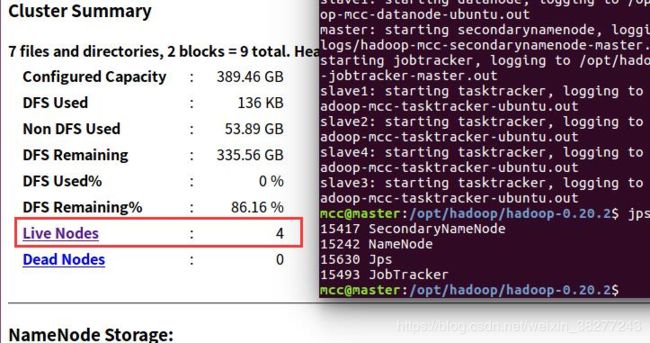
②打开网址http://master:50070
能看到上图中的Live Nodes为4
③在所有的slave机器中输入jps命令能看到datanode进程
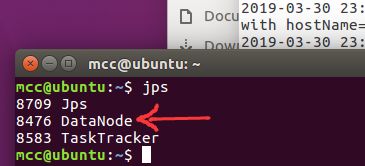
5.7、配置hadoop环境变量
为了使用hadoop命令还需要配置hadoop环境变量
修改/etc/profile文件
sudo gedit /etc/profile
在末尾新增,即刚才配置java环境变量的末尾如下两行
export HADOOP_HOME=XXX(hadoop的安装路径)
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
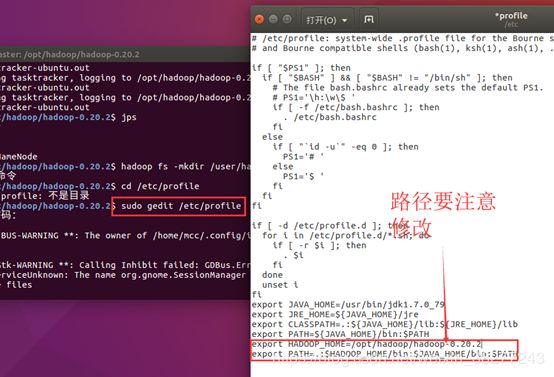
最后更新环境变量
source /etc/profile
5.8、关闭hadoop
到这里hadoop的部署就全部完成了
下面讲一下如何关闭hadoop
./bin/stop-all.sh
6、报错解决
6.1、ssh配置好了还需要输入密码
输入以下代码,注意路径
ssh-add /home/mcc/.ssh/id_rsa
6.2、启动hadoop提示权限不足
输入以下代码,注意xxx替换为用户名
chown -R xxx:xxx hadoop-0.20.2/
6.3、启动集群后用jps查看没有(datanode、live nodes)
原因:多次格式化导致主从机间namespaceID不一致
解决办法
按照图中(图中是slave机器),把主机上的namespaceID复制直接拷到所有的slaves机器上对应文件中
master机器中的路径是/opt/hadoop/hdfs/name/current/
slaves机器中的路径是/opt/hadoop/hdfs/data/current/
