Python Spark MLlib之逻辑回归
数据准备
和决策树分类一样,依然使用StumbleUpon Evergreen数据进行实验。
Local模式启动ipython notebook
cd ~/pythonwork/ipynotebook
PYSPARK_DRIVER_PYTHON=ipython PYSPARK_DRIVER_PYTHON_OPTS="notebook" MASTER=local[*] pyspark
导入并转换数据
## 定义路径
global Path
if sc.master[:5]=="local":
Path="file:/home/yyf/pythonwork/PythonProject/"
else:
Path="hdfs://master:9000/user/yyf/"
## 读取train.tsv
print("开始导入数据...")
rawDataWithHeader = sc.textFile(Path+"data/train.tsv")
## 取第一项数据
header = rawDataWithHeader.first()
## 剔除字段名(特征名)行,取数据行
rawData = rawDataWithHeader.filter(lambda x:x!=header)
## 将双引号"替换为空字符(剔除双引号)
rData = rawData.map(lambda x:x.replace("\"",""))
## 以制表符分割每一行
lines = rData.map(lambda x: x.split("\t"))
print("共有:"+str(lines.count())+"项数据")
数据预处理
1、处理特征
该数据集tran.tsv和test.tsv的第3个字段是alchemy_category网页分类,是一个离散值特征,要采用OneHotEncode的方式进行编码转换为数值特征,主要过程如下:
(1) 创建categoriesMap字典,key为网页类别名,value为数字(网页类别名的索引值),每个类别名对应一个索引值
(2) 根据categoriesMap字典查询每个alchemy_category特征值对应的索引值,例如business的索引值categoryIdx为2
(3) 根据categoryIdx=2,以OneHotEncodeer的方式转换为一个列表categoryFeatures List,该列表长度为14(统计所有网页类别),categoryIdx=2对应的列表为[0,0,1,0,0,0,0,0,0,0,0,0,0,0]。建立categoriesMap网页分类字典
categoriesMap = lines.map(lambda fields: fileds[3]).distinct().zipWithIndex().collectAsMap()其中,lines.map()表示处理之前读取的数据的每一行,.map(lambda fields: fileds[3])表示读取第3个字段,.distinct()保留不重复数据,.zipWithIndex()将第3个字段中不重复的数据进行编号,.collectAsMap()转换为dict字典格式
将每个alchemy_category网页分类特征值转化为列表categoryFeatures List
## 给定一个alchemy_category网页分类特征转化为OneHot 列表
## 查询对应索引值
import numpy as np
categoryIdx = categoriesMap[lines.first()[3]]
OneHot = np.zeros(len(categoriesMap))
OneHot[categoryIdx] = 1
print(OneHot)对于第4~25字段的数值特征,要转换为数值,用float函数将字符串转换为数值,同时简单处理缺失值”?”为0.
整个处理特征的过程可以封装成一个函数:
import numpy as np
def convert(v):
"""处理数值特征的转换函数"""
return (0 if v=="?" else float(v))
def process_features(line, categoriesMap, featureEnd):
"""处理特征,line为字段行,categoriesMap为网页分类字典,featureEnd为特征结束位置,此例为25"""
## 处理alchemy_category网页分类特征
categoryIdx = categoriesMap[line[3]]
OneHot = np.zeros(len(categoriesMap))
OneHot[categoryIdx] = 1
## 处理数值特征
numericalFeatures = [convert(value) for value in line[4:featureEnd]]
# 返回拼接的总特征列表
return np.concatenate((OneHot, numericalFeatures))
## 处理特征生成featureRDD
featureRDD = lines.map(lambda r: process_features(r, categoriesMap, len(r)-1))2、数据标准化
与决策树不同的是,逻辑回归需要对数值型特征进行数据标准化,主要原因在于逻辑回归算法过程中使用了梯度下降法,不进行标准化会使得部分数值较大的特征对梯度的影响很大,造成难以收敛等不良现象。数据标准化使得每个特征的数值规范到同一水平上(比如都分布在-1~1之间)进而平衡不同特征对梯度的影响。
没有标准化之前的特征值:
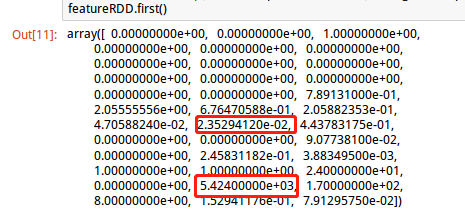
上图可以看到,有5424.0的比较大的数值特征,也有最小0.0235的小数值特征,所以有必要对数据进行标准化。
对数值特征进行标准化:
## 数据标准化
from pyspark.mllib.feature import StandardScaler # 导入数据标准化模块
## 对featureRDD进行标准化
stdScaler = StandardScaler(withMean=True, withStd=True).fit(featureRDD) # 创建一个标准化实例
ScalerFeatureRDD = stdScaler.transform(featureRDD)
ScalerFeatureRDD.first()查看标准化之后的数值特征:
![]()
3、处理label构成labelpoint数据格式
处理标签数据(test.tsv最后一列),只需把字符串类型转化为float型:
## 处理标签
def process_label(line):
return float(line[-1]) # 最后一个字段为类别标签
labelRDD = lines.map(lambda r: process_label(r))构成labelpointRDD,Spark Mllib分类任务支持的数据类型为LabeledPoint格式,LabeledPoint数据由标签label和特征feature组成。构建LabeledPoint数据:
## 构建LabeledPoint数据:
from pyspark.mllib.regression import LabeledPoint
## 拼接标签和特征
labelpoint = labelRDD.zip(ScalerFeatureRDD)
labelpointRDD = labelpoint.map(lambda r: LabeledPoint(r[0],r[1]))
labelpointRDD.first()4、划分训练集、验证集及测试集
## 划分训练集、验证集和测试集
(trainData, validationData, testData) = labelpointRDD.randomSplit([7,1,2])# 将数据暂存在内存中,加快后续运算效率
trainData.persist()
validationData.persist()
testData.persist()训练模型
Spark Mllib封装了LogisticRegressionWithSGD逻辑回归分类器,其.train()方法训练模型,调用形式如下:
LogisticRegressionWithSGD.train(data, iterations=100, step=1.0, miniBatchFraction=1.0,
initialWeights=None, regParam=0.01, regType="l2", intercept=False,
validateData=True, convergenceTol=0.001)主要参数说明如下:
- data:输入的训练数据,数据格式为LabeledPoint格式
- iterations:使用SGD的迭代次数,默认为100
- step:每次执行SGD迭代步长大小,默认为1
- miniBatchFraction:小批量随机梯度下降法每次参与计算的样本比例,数值在0~1,默认为1
- initialWeights:初始化系数,默认为None
- regParam:正则项系数大小
- regType:正则化类型”l1”或”l2”或”None”,默认为”l2”,
## 使用逻辑回归模型进行训练
from pyspark.mllib.classification import LogisticRegressionWithSGD
## 使用默认参数训练模型
model = LogisticRegressionWithSGD.train(trainData, iterations=100, step=1.0, miniBatchFraction=1.0, regParam=0.01, regType="l2")模型评估
使用AUC(Area under the Curve of ROC)来对模型进行评估,接收者操作特征(Receiver Operating Characteristic , ROC)曲线是一种比较分类器模型有用的可视化工具。
ROC曲线显示了给定模型的真正例率(TPR=TP/P)(纵轴)和假正例率(FPR=FP/N)(横轴)之间的权衡。TPR的增加以FPR的增加为代价。ROC曲线下方的面积是模型准确率的度量:AUC
- AUC=1:预测准确率100%
0.5 < AUC <1:优于随机猜测,具有预测意义
AUC=0.5: 与随机猜测一样,没有预测意义
AUC<0.5: 比随机预测还差
定义评估函数计算AUC
## 使用BinaryClassificationMetrics计算AUC
from pyspark.mllib.evaluation import BinaryClassificationMetrics
## 定义模型评估函数
def evaluateModel(model, validationData):
## 使用模型进行预测(作用于验证集上)
## 计算AUC
predict = model.predict(validationData.map(lambda p:p.features))
predict = predict.map(lambda p: float(p))
## 拼接预测值和实际值
predict_real = predict.zip(validationData.map(lambda p: p.label))
# predict_real.take(5)
metrics = BinaryClassificationMetrics(predict_real)
metrics.areaUnderROC
return metrics.areaUnderROC
AUC = evaluateModel(model, validationData)
## 打印AUC
print("AUC="+str(AUC))返回结果:AUC=0.677684903749
模型参数调优
逻辑回归的参数:迭代次数iterations,SGD步长step,训练批次大小miniBatchFraction, 正则项系数regParam=0.01, 正则化方式regType=”l2”,会影响模型的准确率及训练的时间,下面对不同模型参数取值进行测试评估。
创建trainEvaluateModel函数包含训练与评估功能,并计算训练评估的时间。
## 创建trainEvaluateModel函数包含训练与评估功能,并计算训练评估的时间。
from time import time
def trainEvaluateModel(trainData, validationData, iterations, step, miniBatchFraction, regParam, regType):
startTime = time()
## 创建并训练模型
Model = LogisticRegressionWithSGD.train(trainData, iterations=iterations, step=step,
miniBatchFraction=miniBatchFraction, regParam=regParam, regType=regType)
## 计算AUC
AUC = evaluateModel(Model, validationData)
duration = time() - startTime # 持续时间
print("训练评估:参数"+"iterations="+str(iterations) +
", step="+str(step)+", miniBatchFraction="+str(miniBatchFraction)+
", regParam"+str(regParam)+", regType=" + str(regType) +"\n"+
"===>消耗时间="+str(duration)+", 结果AUC="+str(AUC))
return AUC, duration, iterations, step, miniBatchFraction, regParam, regType, model1、评估iterations参数
分别测试iterations迭代次数为[10, 100, 1000, 10000] 的模型运行时间及在验证集上的AUC
## 评估iterations参数
iterationsList = [10, 100, 1000, 10000]
stepList = [1]
miniBatchFractionList = [1]
regParamList = [0.01]
regTypeList = ["l2"]
## 返回结果存放至metries中
metrics = [trainEvaluateModel(trainData, validationData,iterations, step, miniBatchFraction, regParam, regType)
for iterations in iterationsList
for step in stepList
for miniBatchFraction in miniBatchFractionList
for regParam in regParamList
for regType in regTypeList]运行结果:
训练评估:参数iterations=10, step=1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=0.74197101593, 结果AUC=0.679249710355
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.56789708138, 结果AUC=0.679825333275
训练评估:参数iterations=1000, step=1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.64229202271, 结果AUC=0.679825333275
训练评估:参数iterations=10000, step=1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.58939695358, 结果AUC=0.679825333275观察发现,迭代次数小的时候运行时间少,迭代次数大到一定程度,运行时间差不多。AUC也都很接近,由此看来,iterations可能不是关键。
2、评估参数step
分别测试step为[0.1, 1, 10, 100, 500, 1000] 的模型运行时间及在验证集上的AUC
## 评估istep参数
iterationsList = [100]
stepList = [0.1, 1, 10, 100, 500, 1000]
miniBatchFractionList = [1]
regParamList = [0.01]
regTypeList = ["l2"]
## 返回结果存放至metries中
metrics = [trainEvaluateModel(trainData, validationData,iterations, step, miniBatchFraction, regParam, regType)
for iterations in iterationsList
for step in stepList
for miniBatchFraction in miniBatchFractionList
for regParam in regParamList
for regType in regTypeList]运行结果:
训练评估:参数iterations=100, step=0.1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.84775495529, 结果AUC=0.689995893645
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.34834504128, 结果AUC=0.679825333275
训练评估:参数iterations=100, step=10, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=0.813359022141, 结果AUC=0.682534794022
训练评估:参数iterations=100, step=100, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.75270915031, 结果AUC=0.577324123367
训练评估:参数iterations=100, step=500, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.66944003105, 结果AUC=0.511446463402
训练评估:参数iterations=100, step=1000, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=2.39376091957, 结果AUC=0.479116253831观察发现,步长过小或过大,运行时间都会增加,而步长过大会导致AUC降低。
3、评估参数训练批次大小miniBatchFraction
分别测试miniBatchFraction为[[0.01, 0.1, 0.5, 1]] 的模型运行时间及在验证集上的AUC
## 评估miniBatchFractionList参数
iterationsList = [100]
stepList = [100]
miniBatchFractionList = [0.01, 0.1, 0.5, 1]
regParamList = [0.01]
regTypeList = ["l2"]
## 返回结果存放至metries中
metrics = [trainEvaluateModel(trainData, validationData,iterations, step, miniBatchFraction, regParam, regType)
for iterations in iterationsList
for step in stepList
for miniBatchFraction in miniBatchFractionList
for regParam in regParamList
for regType in regTypeList]运行结果:
训练评估:参数iterations=100, step=1, miniBatchFraction=0.01, regParam0.01, regType=l2
===>消耗时间=1.55241012573, 结果AUC=0.685335914471
训练评估:参数iterations=100, step=1, miniBatchFraction=0.1, regParam0.01, regType=l2
===>消耗时间=1.4033370018, 结果AUC=0.681134233798
训练评估:参数iterations=100, step=1, miniBatchFraction=0.5, regParam0.01, regType=l2
===>消耗时间=1.38880395889, 结果AUC=0.678516432751
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.30457305908, 结果AUC=0.679825333275参数miniBatchFractionList影响不显著
4、评估参数正则项系数regParam及正则化方式regType
分别测试regParam为 [0.01, 0.1, 1,10, 100]的模型运行时间及在验证集上的AUC
测试结果:
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.51532578468, 结果AUC=0.679825333275
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam0.1, regType=l2
===>消耗时间=0.746392011642, 结果AUC=0.672246909235
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam1, regType=l2
===>消耗时间=0.438490867615, 结果AUC=0.688870312523
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam10, regType=l2
===>消耗时间=1.67466306686, 结果AUC=0.688961972223
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam100, regType=l2
===>消耗时间=1.94846796989, 结果AUC=0.321875870767
值得注意的是,如果正则化系数过大,会使得逻辑回归各个特征相对应的系数变得很小,失去预测效果。
分别测试正则化方式参数regType=[“l2”,”l1”,None]
运行结果:
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam0.01, regType=l2
===>消耗时间=1.64927506447, 结果AUC=0.679825333275
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam0.01, regType=l1
===>消耗时间=0.902688026428, 结果AUC=0.688137034919
训练评估:参数iterations=100, step=1, miniBatchFraction=1, regParam0.01, regType=None
===>消耗时间=1.48943686485, 结果AUC=0.683843694546
差别不是很大。
选择最佳模型参数组合
以网格搜索的方式进行查找:
def trainEvaluateModel(trainData, validationData, iterations, step, miniBatchFraction, regParam, regType):
startTime = time()
## 创建并训练模型
Model = LogisticRegressionWithSGD.train(trainData, iterations=iterations, step=step,
miniBatchFraction=miniBatchFraction, regParam=regParam, regType=regType)
## 计算AUC
AUC = evaluateModel(Model, validationData)
duration = time() - startTime # 持续时间
return AUC, duration, iterations, step, miniBatchFraction, regParam, regType, model
## 定义函数gridSearch网格搜索最佳参数组合
def gridSearch(trainData, validationData, iterationsList, stepList, miniBatchFractionList, regParamList, regTypeList):
metrics = [trainEvaluateModel(trainData, validationData,iterations, step, miniBatchFraction, regParam, regType)
for iterations in iterationsList
for step in stepList
for miniBatchFraction in miniBatchFractionList
for regParam in regParamList
for regType in regTypeList]
# 按照AUC从大到小排序,返回最大AUC的参数组合
sorted_metics = sorted(metrics, key=lambda k:k[0], reverse=True)
best_parameters = sorted_metics[0]
print("最佳参数组合:"+"impurity="+str( best_parameters[2]) +
", maxDepth="+str( best_parameters[3])+", maxBins="+str( best_parameters[4])+"\n"+
", 结果AUC="+str( best_parameters[0]))
return best_parameters
## 参数组合
iterationsList = [10, 100, 1000, 5000]
stepList = [0.1, 1, 10, 100]
miniBatchFractionList = [0.01, 0.1, 0.5, 1]
regParamList = [0.001, 0.01, 0.1]
regTypeList = ["l2", "l1", None]
## 调用函数返回最佳参数组合
best_parameters = gridSearch(trainData, validationData, iterationsList, stepList, miniBatchFractionList, regParamList, regTypeList)得出最佳参数组合为:iterations=100, step=10, miniBatchFraction=1, regParam0.001, regType=l2
判断是否发生过拟合及模型预测
1、判断是否过拟合
前面已经得到最佳参数组合iterations=100, step=10, miniBatchFraction=1, regParam0.001, regType=l2及相应的AUC评估。使用该最佳参数组合作用于测试数据,是否会过拟合
## 使用最佳参数组合iterations=100, step=10, miniBatchFraction=1, regParam0.001, regType=l2训练模型
best_model = LogisticRegressionWithSGD.train(trainData, iterations=100, step=10,
miniBatchFraction=1, regParam=0.001, regType="l2")
trainAUC = evaluateModel(best_model, trainData)
testAUC2= = evaluateModel(best_model, testData)
print("training: AUC="+str(AUC1))
print("testing: AUC="+str(AUC2))返回结果:
training: AUC=0.672151080827
testing: AUC=0.670369502427
二者非常接近,说明模型很好的抑制了过拟合的产生。
2、使用模型进行预测
使用最佳参数组合对test.tsv中的数据进行预测
## 使用模型进行预测
def predictData(sc,model,categoriesMap):
print("开始导入数据...")
rawDataWithHeader = sc.textFile(Path+"data/test.tsv")
## 取第一项数据
header = rawDataWithHeader.first()
## 剔除字段名(特征名)行,取数据行
rawData = rawDataWithHeader.filter(lambda x:x!=header)
## 将双引号"替换为空字符(剔除双引号)
rData = rawData.map(lambda x:x.replace("\"",""))
## 以制表符分割每一行
lines = rData.map(lambda x: x.split("\t"))
## 预处理测试数据集(都是特征字段)
testDataRDD=lines.map(lambda r: process_features(r, categoriesMap, len(r)))
## 数据标准化
stdScaler = StandardScaler(withMean=True, withStd=True).fit(testDataRDD) # 创建一个标准化实例
ScalertestRDD = stdScaler.transform(testDataRDD)
DescDict={0:"暂时型(ephemeral)网页",
1:"长久型(evergreen)网页"}
## 预测前5项数据
for i in range(5):
predictResult=model.predict(ScalertestRDD.take(5)[i])
print("网址:"+str(lines.collect()[i][0])+"\n"+" ===>预测结果为: "+str(predictResult) + "说明: "+DescDict[predictResult]+"\n")
predictData(sc,best_model,categoriesMap)返回结果:
开始导入数据...
网址:http://www.lynnskitchenadventures.com/2009/04/homemade-enchilada-sauce.html
===>预测结果为: 1说明: 长久型(evergreen)网页
网址:http://lolpics.se/18552-stun-grenade-ar
===>预测结果为: 0说明: 暂时型(ephemeral)网页
网址:http://www.xcelerationfitness.com/treadmills.html
===>预测结果为: 0说明: 暂时型(ephemeral)网页
网址:http://www.bloomberg.com/news/2012-02-06/syria-s-assad-deploys-tactics-of-father-to-crush-revolt-threatening-reign.html
===>预测结果为: 0说明: 暂时型(ephemeral)网页
网址:http://www.wired.com/gadgetlab/2011/12/stem-turns-lemons-and-limes-into-juicy-atomizers/
===>预测结果为: 0说明: 暂时型(ephemeral)网页