Java面试篇:手撕hashmap与ArrayList,LinkedList。
这两个月来第一次8点下班,没有到12点甚至有点不习惯,马上就要到跳槽旺季,那么我给大家整理一套最常问的几个集合面条题,废话不多说,直接进入正题。
一、HASHMAP
1.如果想要了解hashmap首先要了解其数据结构
①.hashmap数据结构是什么?
hashmap数据结构中有数组和链表来实现对数据的存储
数组:数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1),随机读取效率很高。因为数组是连续的,知道每一个数据的内存地址,可以直接找到给定地址的数据,但是插入数据和删除数据效率低,插入数据时,这个位置后面的数据在内存中都要向后移。所以数组的特点是:寻址容易,插入和删除困难;
链表:链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N),链表的插入删除元素相对数组较为简单,不需要移动元素,且较为容易实现长度扩充,但是寻找某个元素较为困难。所以链表的特点是:寻址困难,插入和删除容易。
哈希表:那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表。哈希表((Hash table)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法—— 拉链法,我们可以理解为“链表中的数组“,如图所示:
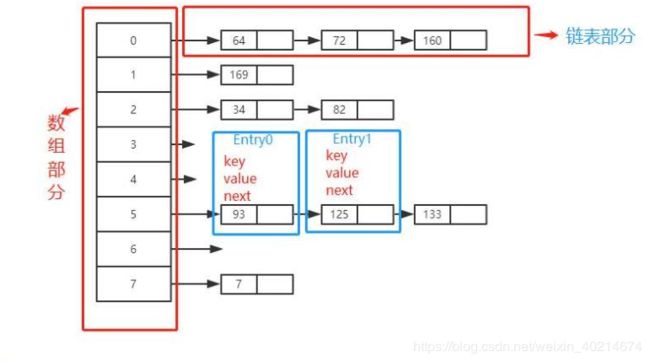
从上图我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。首先HashMap里面实现一个静态内部类Entry,其重要的属性有key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
2.存数据时
HashMap的存取实现既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现:
public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key.hashCode()); ------(1)
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length); ------(2)
//从i出开始迭代 e,找到 key 保存的位置
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
}
通过源码我们可以清晰看到HashMap保存数据的过程为:首先判断key是否为null,若为null,则直接调用putForNullKey方法。若不为空则先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则通过比较是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链头(最先保存的元素放在链尾)。若table在该处没有元素,则直接保存。这个过程看似比较简单,其实深有内幕。有如下几点:
1、 先看迭代处。此处迭代原因就是为了防止存在相同的key值,若发现两个hash值(key)相同时,HashMap的处理方式是用新value替换旧value,这里并没有处理key,这就解释了HashMap中没有两个相同的key。
2、 在看(1)、(2)处。这里是HashMap的精华所在。首先是hash方法,该方法为一个纯粹的数学计算,就是计算h的hash值。
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
HashMap的底层数组长度总是2的n次方,在构造函数中存在:capacity <<= 1;这样做总是能够保证HashMap的底层数组长度为2的n次方。当length为2的n次方时,h&(length - 1)就相当于对length取模,而且速度比直接取模快得多,这是HashMap在速度上的一个优化。
3、JDK1.8之后 HashMap为什么要用到红黑树,先上图
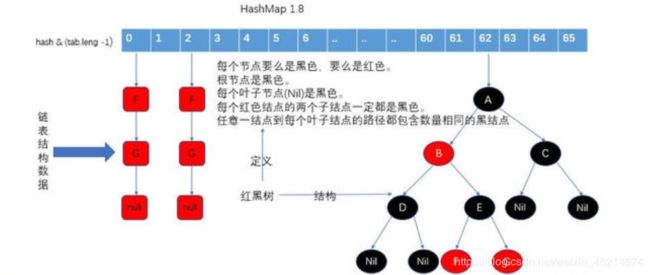 JDK1.8之后,当若桶中链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
JDK1.8之后,当若桶中链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
总结:

2.取数据时
相对于HashMap的存而言,取就显得比较简单了。通过key的hash值找到在table数组中的索引处的Entry,然后返回该key对应的value即可。
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
在这里能够根据key快速的取到value除了和HashMap的数据结构密不可分外,还和Entry有莫大的关系,在前面就提到过,HashMap在存储过程中并没有将key,value分开来存储,而是当做一个整体key-value来处理的,这个整体就是Entry对象。同时value也只相当于key的附属而已。在存储的过程中,系统根据key的hashcode来决定Entry在table数组中的存储位置,在取的过程中同样根据key的hashcode取出相对应的Entry对象。
3.HashMap 与 HashTable区别
主要几个区别是:
Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null。
跟HashMap相比,Hashtable是线程安全的,适合在多线程的情况下使用,因为加了锁所以效率并不乐观。
HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
二、ArrayList与LinkedList
ArrayList和LinkedList
1.ArrayList与LinkedList数据结构的区别
1.ArrayList 底层实现就是数组,且ArrayList实现了RandomAccess,表示它能快速随机访问存储的元素,通过下标 index 访问,只是我们需要用 get() 方法的形式, 数组支持随机访问, 查询速度快, 增删元素慢;
2.LinkedList 底层实现是链表, LinkedList 没有实现 RandomAccess 接口,链表支持顺序访问, 查询速度慢, 增删元素快;
2.ArrayList与LinkedList遍历的区别
List 实现RandomAccess使用的标记接口,用来表明支持快速(通常是固定时间)随机访问。这个接口的主要目的是允许一般的算法更改它们的行为,从而在随机或连续访问列表时提供更好的性能。
将操作随机访问列表(比如 ArrayList)的最好的算法应用到顺序访问列表(比如 LinkedList)时,会产生二次项行为。鼓励一般的列表算法检查给定的列表是否 instanceof 这个接口,防止在顺序访问列表时使用较差的算法,如果需要保证可接受的性能时可以更改算法。
公认的是随机和顺序访问的区别通常是模糊的。例如,当一些 List 实现很大时会提供渐进的线性访问时间,但实际是固定的访问时间。这样的 List 实现通常应该实现此接口。通常来说,一个 List 的实现类应该实现这个接口
package com.example.list;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.RandomAccess;
/**
* 测试Random Access List(随机访问列表)如 ArrayList 和 Sequence Access List(顺序访问列表)如 LinkedList
* 不同遍历算法的效率
* 结论:前者用循环,后者用迭代器
*/
@SuppressWarnings({"rawtypes", "unchecked"})
public class ListTest {
/**
* 初始化 list,添加n个元素
*
* @param list
* @return
*/
public static List initList(List list, int n) {
for (int i = 0; i < n; i++)
list.add(i);
return list;
}
/**
* 遍历 list,判断是否实现 RandomAccess 接口来使用不同的遍历方法
*
* @param list
*/
public static void accessList(List list) {
long startTime = System.currentTimeMillis();
if (list instanceof RandomAccess) {
System.out.println("实现了 RandomAccess 接口...");
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
} else {
System.out.println("没实现 RandomAccess 接口...");
for (Iterator iterator = list.iterator(); iterator.hasNext();) {
iterator.next();
}
}
long endTime = System.currentTimeMillis();
System.out.println("遍历时间:" + (endTime - startTime));
}
/**
* loop 遍历 list
*/
public static void accessListByLoop(List list) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
long endTime = System.currentTimeMillis();
System.out.println("loop遍历时间:" + (endTime - startTime));
}
/**
* 迭代器遍历
*/
public static void accessListByIterator(List list) {
long startTime = System.currentTimeMillis();
for (Iterator iterator = list.iterator(); iterator.hasNext();) {
iterator.next();
}
long endTime = System.currentTimeMillis();
System.out.println("Iterator遍历时间:" + (endTime - startTime));
}
public static void main(String[] args) {
ArrayList aList = (ArrayList) initList(new ArrayList<>(), 2000000);
LinkedList lList = (LinkedList) initList(new LinkedList<>(), 50000);
accessList(aList);
accessList(lList);
System.out.println("ArrayList");
accessListByLoop(aList);
accessListByIterator(aList);
System.out.println("LinkedList");
accessListByLoop(lList);
accessListByIterator(lList);
}
}
实现了 RandomAccess 接口... 遍历时间:19 没实现 RandomAccess 接口... 遍历时间:4 ArrayList loop遍历时间:14 Iterator遍历时间:25 LinkedList loop遍历时间:3002 Iterator遍历时间:1