Centos7中搭建Hadoop3.2(Centos6、Centos7搭建Hadoop2、Hadoop3)完整详细操作步骤
虽然企业开发、生产一般多用比较稳定较前版本,但 自己在学习新技术时比较喜欢用较新版本软件,而网上更多的资料是Centos6中搭建Hadoop2,故在Centos7中搭建Hadoop3.2时,参考的是网上的前者资料,遇到很多问题,故在搭建通hadoop后,将搭建过程整理了一遍,并在文中将影响搭建的Centos6和Centos7差别、Haoop2和Hadoop3的区别详细说明,和有需要的同行分享一下。
本文内容包括三部分:
一、linux环境的准备
二、jdk的安装
三、Hadoop安装过程
环境准备为:在window系统上安装vmware,在vmware中安装三台Centos7虚拟机,ip分别为
192.168.99.122(作为主节点机) 192.168.99.129(从节点机) 192.168.99.135 (从节点机)
hadoop为3.2版本。
Hadoop集群搭建详细步骤(Centos6或Centos7,Hadoop2或Hadoop3)
1、配置好虚拟机的网络(可选择Net模式或桥接模式):
方式一(桌面版centos):通过Linux图形化界面进行修改(桌面版centos)
进入Linux图形界面-->右键点击右上方的两个小电脑的图标-->点击Edit connections-->点击add按钮
-->添加IP:192.168.99.122 子网掩码:255.255.255.0 网关:192.168.99.1 -->apply
方式二(适用于所有情况):修改配置文件方式:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE=ens33 #网卡接口名称
BOOTPROTO=static #启用地址协议 --static:静态协议 --bootp协议 --dhcp协议
HWADDR=00:0C:29:0E:02:04 #网卡设备MAC地址,根据自己虚拟机对应的网卡信息配置
IPV6INIT=yes #ipv6初始化(IPV6现在未启用,不考虑其影响)
NM_CONTROLLED=yes #network manger的参数,实时生效,修改后无需要重启网卡立即生
ONBOOT=yes #系统启动时是否自动加载
TYPE=Ethernet #网卡类型
UUID=099c0329-467e-4d4a-80d9-dbec407cb845
IPADDR=192.168.99.150 #网卡IP地址
NETMASK=255.255.255.0 #网卡网络地址
GATEWAY=192.168.99.2 #网卡网关地址
2、同步三台服务器时间(采用以下任何一种即可):
(1)手动同步集群各机器时间:
date -s "2019-03-23 10:50:00"
(2)网络同步时间
yum install ntpdate
ntpdate cn.pool.ntp.norg
3、修改各虚拟主机机名
参考资料:https://cloud.tencent.com/developer/article/1398575
Centos6方式:vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node-1
Centos7方式:
vim /etc/hostname (Centos7方式)
node-1
4、修改主机名和ip是的映射关系
vi /etc/hosts
192.168.99.122 node-1
192.168.99.129 node-2
192.168.99.135 node-3
5、关闭防火墙
#查看防火墙状态
Centos6方式: service iptables status
Centos7方式:firewall-cmd --state
#关闭防火墙
Centos6方式: service iptables stop
Centos7方式:systemctl stop firewalld.service
#查看防火墙开机启动状态
Centos6方式: chkconfig iptables --list
Centos7方式:systemctl status firewalld.service
#关闭防火墙开机启动
Centos6方式: chkconfig iptables off
Centos7方式:systemctl disable firewalld.service
6、配置ssh免登陆
#生成ssh免登陆密钥
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
首先要给自己拷贝一个
ssh-copy-id node-1 提示输入密码:输入密码
再次给另外两台机子拷贝
ssh-copy-id node-2 提示输入密码:输入密码
ssh-copy-id node-3 提示输入密码:输入密码
验证免密登录是否配置成功:
ssh node-1 无需输入密码即可进入node-1
exit
ssh node-2 无需输入密码即可进入node-1
exit
ssh node-3 无需输入密码即可进入node-1
exit
因为node-1是主节点,所有操作都是在node-1上完成,所以只需在node-1配置其对自己、对node-2、node-3免密登录,无需配置其他免密。
如果因网络环境恶劣,要求必须开启防火墙,则需要配置相应的访问规则。
7、linux中jdk安装:
参考资料:https://www.cnblogs.com/Dylansuns/p/6974272.html
(1)检查系统中是否已经有jdk,一般linux中会有默认的openjdk(hadoop中需要的是sun公司<现在sun公司被orcale公司收购>的jdk):
java -version
(2)展示信息:openjdk version "1.8.0_102"
OpenJDK Runtime Environment (build 1.8.0_102-b14)
OpenJDK 64-Bit Server VM (build 25.102-b14, mixed mode)
(3)检测jdk安装包:[root@localhost centos]# rpm -qa | grep java
显示:java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
python-javapackages-3.4.1-11.el7.noarch
tzdata-java-2016g-2.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
(4)卸载openjdk:<1>:[root@localhost centos]# rpm -e --nodeps tzdata-java-2016g-2.el7.noarch
[root@localhost centos]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64
[root@localhost centos]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64
[root@localhost centos]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.102-4.b14.el7.x86_64
[root@localhost centos]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.102-4.b14.el7.x86_64
或者使用这种方式<2>:[root@localhost jvm]# yum remove *openjdk*
(5)查看卸载情况:rpm -qa | grep java
(6)结果:[root@localhost centos]# rpm -qa | grep java
python-javapackages-3.4.1-11.el7.noarch
javapackages-tools-3.4.1-11.el7.noarch
(7)安装新的jdk:首先到jdk官网上下载你想要的jdk版本,下载完成之后将需要安装的jdk安装包放到Linux系统指定的文件夹下
(上传文件命令rz,或者SCRT的Alt+p),并且命令进入该文件夹下,解压 jdk-8u131-linux-x64.tar.gz安装包:tar -zxvf jdk-8u201-linux-x64.tar.gz
(8)设置环境变量:[root@localhost centos]# vim /etc/profile
在最前面添加:
export JAVA_HOME=/usr/centos/jdk1.8.0_201
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
(9)执行profile文件,使对jdk的配置生效:
[root@localhost centos]# source /etc/profile
(10)检查新安装的jdk:
[root@localhost centos]# java -version
显示如下,则安装成功:java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
(11)查看jdk安装路径位置:[root@localhost centos]# which java
显示:/usr/centos/jdk1.8.0_201/bin/java
8、Hadoop配置文件的修改:
Hadoop安装主要就是配置文件的修改,一般在主节点进行修改,完毕后scp下发给其他各个从节点机器,避免在每台机子上单独修改
配置文件的麻烦。将hadoop压缩包上传至linux系统,并进行解压:tar -zxvf hadoop-3.2.0.tar.gz,得到hadoop-3.2.0,
对其进行重命名为hadoop:rm hadoop-3.2.0 hadoop。进入配置文件:cd /usr/centos/hadoop/etc/hadoop/ ,将会进入配置文件目录。
(1)第一个:文件中设置的是hadoop运行时需要的环境。JAVA_HOME时必须设置的,即使我们当前的系统中设置了
JAVA_HOME,他也是不认识的,因为Hadoop即使是在本机上运行,他也是把当前的执行环境当成远程服务器。
vim hadoop-env.sh
export JAVA_HOME=/usr/centos/jdk1.8.0_201
(2)第二个:core-site.xml
hadoop的核心配置文件,有默认的配置项 core-default.xml。
hdfs:// :hdfs文件系统
tfs:// :淘宝文件系统
file:// :本地文件系统
gfs:// :google文件系统
node-1:主节点名
9000:端口号
vim core-site.xml
(3)第三个:hdfs-site.xml
vim hdfs-site.xml
(4)第四个:mapred-site.xml
如果只有mapred-site.xml.template而没有mapred-site.xml,则复制并修改其名字为mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml
如果有则直接修改:
vim mapred-site.xml
(5)第五个:yarn-site.xml
vim yarn-site.xml
(6)第六个:slaves文件,里面写上从节点所在主机名字
hadoop2中为slaves文件:vim slaves
hadoop3.x中slaves名字改为workers:vim workers
进入workers文件后,删掉localhost,新增如下(注意必须换行):
node-1
node-2
node-3
9、将hadoop添加到环境变量中
vim /etc/profile
添加:
export HADOOP_HOME=/usr/centos/hadoop/
修改PATH为:
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载配置文件:
source /etc/profile
10、将node-1主机上配置的hadoop复制到node-2、node-3主机:
scp -r /usr/centos/hadoop/ root@node-2:/usr/centos/
scp -r /usr/centos/hadoop/ root@node-3:/usr/centos/
11、将配置文件profile从node-1拷贝到node-2、node-3:
scp -r /etc/profile root@node-2:/etc/profile
scp -r /etc/profile root@node-3:/etc/profile
然后重新加载node-2、node-3配置文件。
12、hadoop集群的启动:
要启动Hadoop集群,需要启动HDFS和YARN两个集群。
注意: (1)首次启动时,必须要对其进行格式化操作。本质上是一些清理和准备工作(创建文件),因为HDFS在物理上还是不存在的。
(2)格式化之后,集群启动成功,后续再也不需要进行格式化,因为每次格式化会产生一个id,多次格式化,
产生多个id,或出现匹配问题。
(3)格式化操作在hdfs集群的主角色(namenode)所在的机器上操作(node-1),不要在从角色上操作(node2、node3)!
格式化命令与版本关系: hadoop1时:hadf namenode -format
hadoop2时:hadf namenode -format 或者hadoop namenode -format
hadoop3时:hadoop namenode -format
启动方式一:单节点逐个启动方式:
(1)在主节点上使用以下命令启动HDFS NameNode:
hadoop-daemon.sh start namenode
(2)在每个节点上使用以下命令启动HDFS DataNode:
hadoop-daemon.sh start datanode
(3)在主节点上使用以下命令启动YARN ResourceManager:
yarn-daemon.sh start resourcemanager
(4)在每个从节点上使用以下命令启动YARN nodemanager:
yarn-daemon.sh start nodemanager
以上脚本位于$HADOOP_PREFIX/sbin/目录下。如果想要溶质某个节点上某个角色,只需把命令中的start改为stop即可。
启动方式二:脚本一键启动:
如果配了 etc/hadoop/workers(Hadoop2为etc/hadoop/slaves) 和ssh免密登录,则可以是用程序脚本启动。
所有Hadoop两个集群的相关进程,在主节点所设定的机器上上执行。
进入到$HADOOP_PREFIX/sbin/目录下,发现有很多启动、关闭命令文件。
启动集群:
start-dfs.sh
start-yarn.sh
停止集群:stop-dfs.sh
stop-yarn.sh
如果启动报:ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
则需在
在/hadoop/sbin路径下:将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
查看启动状态命令:jps
回显:21941 ResourceManager
22069 NodeManager
21528 DataNode
22408 Jps
21402 NameNode
则表示启动成功。
13、访问hdfs和yarn:
(1)先在自己Windows电脑中配置hotsts文件(路径:C:\Windows\System32\drivers\etc)
192.168.99.122 node-1
192.168.99.129 node-2
192.168.99.135 node-3
(2)在浏览器中访问hdfs和yarn:
hdfs:Hadoop2:node-1:50077
Hadoop3:node-1:9870
yarn:
Hadoop2和Hadoop3相同:node-1:8088
hadf成功标志:
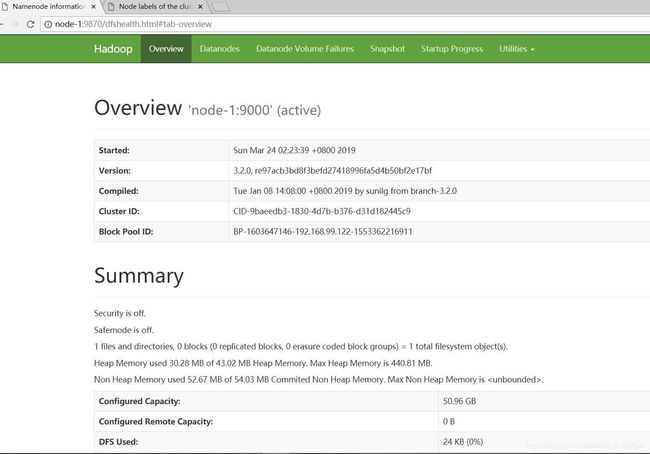
yarn成功标志:
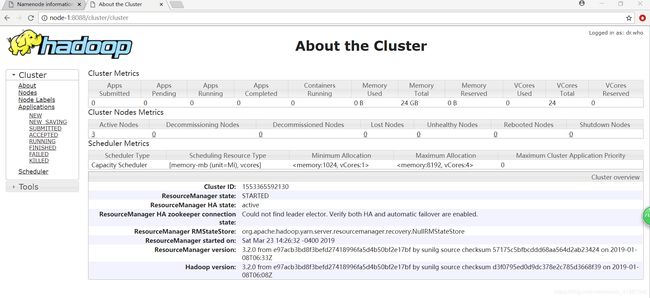
关于hadoop配置文件:
***-default.xml 这里面配置了hadoop默认的配置选项,如果用户没有更改,那么这里面的选项将会生效。
****-site.xml 这里面配置了用户需要自定义的配置选项。
site中的配置选项大于default中的配置,如果用户用配置的话,则会覆盖默认的配置选项。