Java学习笔记16(集合!HashSet, ArrayList, HashMap)
文章目录
- 集合概述(容器类)
- List与ArrayList
- 特点
- list具体方法
- 添加元素list.add方法
- 索引
- list.addAll(index,value)
- 查找数据list.indexOf(),list.lastindexOf()
- 移除数据list.remove(index)
- 改值list.set(index,value)
- 切片list.subList(a,b)
- 列表长度list.size()
- 结论:
- Set,HashSet
- 遍历集合元素的方法
- Map
- 特点
- Map接口与HashMap类
- TreeMap
集合概述(容器类)
Java集合类存放于 java.util 包中
Java 集合可分为 Set、List 和 Map 三种大体系
Set:无序、不可重复的集合
List:有序,可重复的集合
Map:具有映射关系的集合
接口:Set,List,Map不是直接使用的,而是通过他们的实现类!


个人感觉:
对应python里面的集合,列表,字典
List与ArrayList
ArrayList是可实例化的
特点
列表(和python里列表一样,但是这里把列表属于集合!)
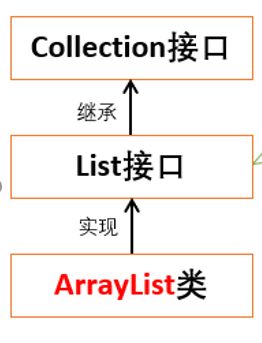
List 代表一个元素有序、且可重复的集合,集合中的每个元素都有其对应的顺序索引
List 允许使用重复元素,可以通过索引来访问指定位置的集合元素。
List 默认按元素的添加顺序设置元素的索引。
List 集合里添加了一些根据索引来操作集合元素的方法
list具体方法
添加元素list.add方法
看代码学习!
import java.util.List;
import java.util.ArrayList;
public class Test5 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("v");
list.add("v2");
list.add("v");//列表可重复
list.add("b");
list.add("a");
System.out.println(list);
}
}
备注:
很方法,会自动提示import
import java.awt.List;(不是这个,why?先留着这个问题)
import java.util.List;
import java.util.ArrayList;

索引
list.get(index)
list.add(index,“value”);
public class Test5 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("v");
list.add("v2");
list.add("v");//列表可重复
list.add("b");
list.add("a");
System.out.println(list);
System.out.println(list.get(3));//索引第四个元素,因为从0开始,下标
list.add(0,"a");
System.out.println(list);//结果为[a, v, v2, v, b, a]
}
}
list.addAll(index,value)
List<String> list1 = new ArrayList<String>();
list1.add("acdf");
list1.add("9989");
list.addAll(0,list1);
System.out.println(list);//[acdf, 9989, a, v, v2, v, b, a]
查找数据list.indexOf(),list.lastindexOf()
第一个出现元素 的下标和最后一个出现元素的下标。
移除数据list.remove(index)
根据索引remove
改值list.set(index,value)
根据索引set
切片list.subList(a,b)
根据索引a,b 切一段,左开右闭。
List<String> list2 = list.subList(2,5);
System.out.println(list2);//[a, v, v2]
列表长度list.size()
结论:
Vector是一个古老的集合,通常建议使用 ArrayList
ArrayList 是线程不安全的,而 Vector 是线程安全的。
即使为保证 List 集合线程安全,也不推荐使用 Vector
Set,HashSet
我们说的集合,都是HashSet

遍历集合元素的方法
Iterator 接口主要用于遍历 Collection 集合中的元素,Iterator 对象也被称为迭代器
Java 5 提供了 foreach 循环迭代访问 Collection
方法在代码里。
import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.List;
import java.util.Set;
public class Test3 {
public static void main(String[] args) {
// Set set = new HashSet();
//
Set<Object> set = new HashSet<Object>();//与上面的等价
set.add(1);//添加元素
set.add("a");
//
System.out.println(set);
//
// set.remove(1);//移除元素
//
// System.out.println(set);
//
// System.out.println(set.contains(1));//判断是否包含元素
//
// set.clear();//清空集合
//
// System.out.println(set);
set.add("a");
set.add("b");
set.add("c");
set.add("d");
// set.add("d");//set集合是存的值是不重复
set.add(1);
set.add(true);
set.add(null);
System.out.println(set);
//使用迭代器遍历集合
Iterator it = set.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//for each迭代集合,推荐使用这种
for(Object obj : set){
//这个的意思是把set的每一个值取出来,赋值给obj,直到循环set的所有值
System.out.println(obj);
}
System.out.println(set.size());//获取集合的元素个数
//如果想要让集合只能存同样类型的对象,怎么做
//使用泛型集合是无序的!!!
为了有序咋办?
TreeSet是自然排序,从小到大。默认情况下,TreeSet 采用自然排序。
import java.util.Set;
import java.util.TreeSet;//为了有序集合
public class Test4 {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<Integer>();
set.add(3);
set.add(5);
set.add(7);
set.add(9);
System.out.println(set);
}
}
遍历集合set,强制for循环
//遍历集合set
for(Integer i : set) {
System.out.println(i);
}
如果不是数字怎么排序?
如果需要实现定制排序,则需要在创建 TreeSet 集合对象时,提供一个 Comparator 接口的实现类对象。由该 Comparator 对象负责集合元素的排序逻辑

import java.util.Comparator;//为了定制排序
import java.util.Set;
import java.util.TreeSet;//为了有序集合
public class Test4 {
//step4
public static void main(String[] args) {
Person p1 = new Person(18,"Tom");//因为有参构造,这里可以直接写参数。
Person p2 = new Person(18,"Tom1");
Person p3 = new Person(14,"Tom3");
Person p4 = new Person(16,"Tom4");
Person p5 = new Person(10,"Tom5");
//step5
//然后建立set,去排序
Set <Person> set = new TreeSet<Person>(new Person());//指明泛型为Person
set.add(p1);
set.add(p2);
set.add(p3);
set.add(p4);
set.add(p5);
//step6
//**强制for循环**
for(Person p:set) {
System.out.println(p.name + ""+ p.age);
}
}
}
/**
* 定制排序
* @author jkjkjk
*
*/
class Person implements Comparator<Person>{
//step3
public Person() {
}
//有参构造
public Person(int age, String name) {
this.age = age;
this.name = name;
}//然后再去new Person类
//step1
int age;
String name;
//step2
@Override
public int compare(Person o1, Person o2) {
// TODO Auto-generated method stub
if(o1.age > o2.age) {
return 1;
}else if(o1.age < o2.age){
return -1;
}else {
return 0;
}
//再去写构造
}
}
Map
特点
Map 用于保存具有映射关系的数据,因此 Map 集合里保存着两组值,一组值用于保存 Map 里的 Key,另外一组用于保存 Map 里的 Value
Map 中的 key 和 value 都可以是任何引用类型的数据
Map 中的 Key 不允许重复,即同一个 Map 对象的任何两个 Key 通过 equals 方法比较中返回 false
**Key 和 Value 之间存在单向一对一关系,即通过指定的 Key 总能找到唯一的,**确定的 Value。
Map接口与HashMap类

看代码学习!
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class Test6 {
public static void main(String[] args) {
//new HashMap这个类,赋值给map,指明泛型,是一对的
Map<String, Integer> map = new HashMap<String, Integer>();
map.put("b", 1);//添加数据
map.put("c", 2);
map.put("e", 2);
System.out.println(map);//{b=1, c=2, e=2}
System.out.println(map.get("b"));//根据key取值
map.remove("c");//根据key移除键值对
System.out.println(map);//{b=1, e=2}
System.out.println(map.containsKey("a"));//判断当前的map集合是否包含指定的key
//
System.out.println(map.containsValue(10));//判断当前的map集合是否包含指定的value
//
//// map.clear();//清空集合
遍历map,注意!
第一种方法,遍历key,
Set<String> keys = map.keySet();//import java.util.Set;
for(String key:keys) {
System.out.println(map.get(key));
}
这种方法效率低
第一种方法,map.entrySet()
//通过map.entrySet();遍历map集合
Set<Entry<String, Integer>> entrys = map.entrySet();//import java.util.Map.Entry;
for(Entry<String, Integer> en : entrys){
System.out.println("key: " + en.getKey() + ", value: " + en.getValue());
}
//key: b, value: 1
//key: e, value: 2
TreeMap
TreeMap 存储 Key-Value 对时,需要根据 Key 对 key-value 对进行排序。TreeMap 可以保证所有的 Key-Value 对处于有序状态。
TreeMap 的 Key 的排序:
自然排序:TreeMap 的所有的 Key 必须实现 Comparable 接口,而且所有的 Key 应该是同一个类的对象,否则将会抛出 ClasssCastException
import java.util.HashMap;
import java.util.Map;
import java.util.TreeMap;
public class Test6 {
public static void main(String[] args) {
//new HashMap这个类,赋值给map1,指明泛型,是一对的
Map<Integer,String> map1 = new HashMap<Integer,String>();
map1.put(6, "xx33");//添加数据
map1.put(2, "xx34");//添加数据
map1.put(3, "xxx1");//添加数据
map1.put(1, "xxx");//添加数据
System.out.println(map1);//{1=xxx, 2=xx34, 3=xxx1, 6=xx33}
Map<Integer,String> map2 = new TreeMap<Integer,String>();
map2.put(6, "xx33");//添加数据
map2.put(2, "xx34");//添加数据
map2.put(3, "xxx1");//添加数据
map2.put(1, "xxx");//添加数据
System.out.println(map2);//{1=xxx, 2=xx34, 3=xxx1, 6=xx33}
}
}
定制排序(了解):创建 TreeMap 时,传入一个 Comparator 对象,该对象负责对 TreeMap 中的所有 key 进行排序。此时不需要 Map 的 Key 实现 Comparable 接口
天天学一点点,开心一点点,头发还剩亿点点!