面试题:redis
redis
- 1、介绍一下redis
- 2、为什么要用 redis/为什么要用缓存?
- 3、为什么要用 redis 而不用 map/guava 做缓存?
- 4、讲一下redis的线程模型
- 5、redis 和 memcached 的区别
- 6、redis 常见数据结构以及使用场景分析
- 7、redis 设置过期时间
- 8、redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
- 9、redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
- 10、redis 事务
- 11、缓存穿透,缓存击穿,缓存雪崩原因+解决方案
- 缓存处理流程
- 12、如何解决redis并发争抢key的问题?
- 13、如何保证缓存和数据库的数据一致性?
1、介绍一下redis
redis是一个分布式的KV键值对的数据库,不同于传统的关系型数据库,它是将数据存储在内存中的,处理数据效率很快,所以redis经常被使用,redis除了存储处理数据之外,还可以做分布式锁、简单的消息队列。数据类型很多,单线程、多路IO复用。
2、为什么要用 redis/为什么要用缓存?
从高性能和高并发两个角度来看。
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
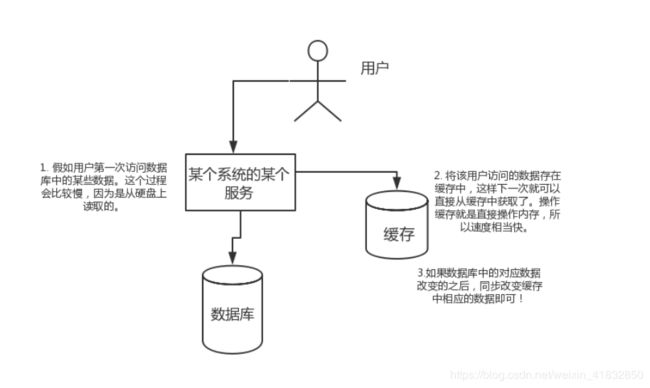
高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
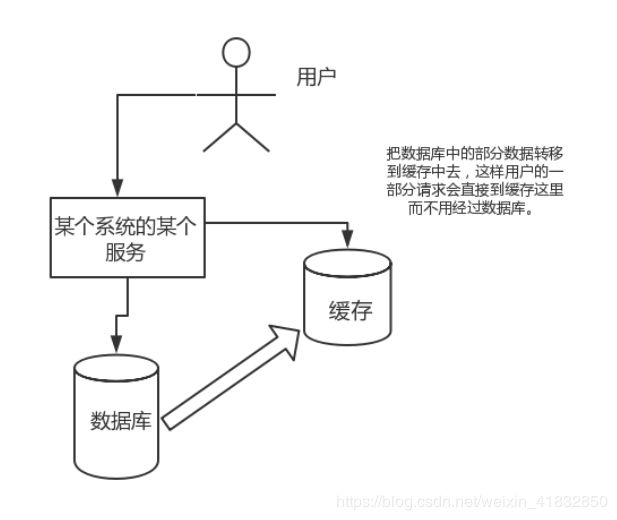
3、为什么要用 redis 而不用 map/guava 做缓存?
redis是分布式缓存、map/guava是本地缓存,本地缓存会跟着jvm的销毁而结束、而且如果有多个实例,就要创建多个缓存,还不能保证数据的一致性。
redis是一个独立的进程。
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
4、讲一下redis的线程模型
redis 内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
多个 socket
IO 多路复用程序
文件事件分派器
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
redis内部使用文件事件处理器 file event handler,这个文件事件处理器是单线程的,所以redis是单线程模型,它采用IO多路复用机制去监听多个socket,根据socket上的事件选择对应的事件处理器来处理。
文件事件处理器包括四个部分:
- 多个socket
- IO多路复用程序
- 文件事件分发器
- 事件处理器
多个socket会有不同的事件,IO多路复用程序监听多个socket,并把事件放入队列中,文件事件分发器把事件交给各个事件处理器处理。
5、redis 和 memcached 的区别
redis支持数据类型更多、redis支持持久化、单线程、事务、IO多路复用机制、集群模式、哨兵模式,memcached没。
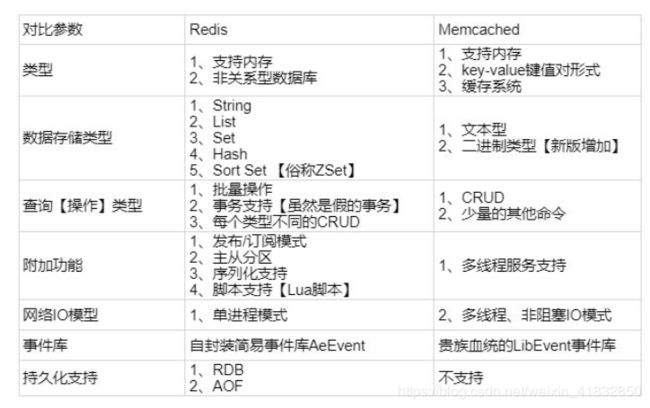
6、redis 常见数据结构以及使用场景分析
参考该博客:https://www.cnblogs.com/ottll/p/9470480.html
7、redis 设置过期时间
Redis中有个设置时间过期的功能,即对存储在 redis 数据库中的值可以设置一个过期时间。作为一个缓存数据库,这是非常实用的。如我们一般项目中的 token 或者一些登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
我们 set key 的时候,都可以给一个 expire time,就是过期时间,通过过期时间我们可以指定这个 key 可以存活的时间。
如果假设你设置了一批 key 只能存活1个小时,那么接下来1小时后,redis是怎么对这批key进行删除的?
定期删除+惰性删除。
通过名字大概就能猜出这两个删除方式的意思了。
- 定期删除:redis默认是每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
- 惰性删除 :定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,也是够懒的哈!
但是仅仅通过设置过期时间还是有问题的。我们想一下:如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了。怎么解决这个问题呢? redis 内存淘汰机制。
8、redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
redis 提供 6种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0版本后增加以下两种:
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
- allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
9、redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
Redis不同于Memcached的很重一点就是,Redis支持持久化,而且支持两种不同的持久化操作。Redis的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file,AOF)。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
快照(snapshotting)持久化(RDB)
Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
快照持久化是Redis默认采用的持久化方式,在redis.conf配置文件中默认有此下配置:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
AOF(append-only file)持久化
与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
appendonly yes
开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。
在Redis的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
appendfsync no #让操作系统决定何时进行同步
为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec选项 ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
Redis 4.0 对于持久化机制的优化
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 aof-use-rdb-preamble 开启)。
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
补充内容:AOF 重写
AOF重写可以产生一个新的AOF文件,这个新的AOF文件和原有的AOF文件所保存的数据库状态一样,但体积更小。
AOF重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有AOF文件进行任何读入、分析或者写入操作。
在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新AOF文件期间,记录服务器执行的所有写命令。当子进程完成创建新AOF文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新AOF文件的末尾,使得新旧两个AOF文件所保存的数据库状态一致。最后,服务器用新的AOF文件替换旧的AOF文件,以此来完成AOF文件重写操作
10、redis 事务
Redis 通过 MULTI \ EXEC \ WATCH 等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有持久性(Durability)。
补充内容:
redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。
11、缓存穿透,缓存击穿,缓存雪崩原因+解决方案
缓存处理流程
请求进来先查缓存中有没有数据,如果没有去查数据库,数据库再将数据存入缓存并返回给前端,当更新数据的时候,更新数据库的同时更新缓存。
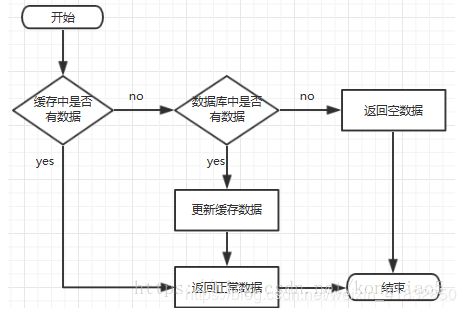
缓存穿透原因:当用户大量请求一个不存在的key的时候,缓存失效,从而请求打到数据库上,导致数据库宕机。
解决方案:
- 缓存无效的key
- 使用布隆过滤器
缓存击穿原因:当有大量请求请求同一个key,这时候key刚好过期了,从而请求打到了数据库上,导致数据库宕机。
解决方案:
- 设置热点数据永不过期
- 使用互斥锁
缓存雪崩原因:当一大片key同时过期,这时候请求都会跳过缓存去请求数据库,导致数据库宕机。
解决方案:
- 设置key随机时间过期
- 设置key永不过期
对于redis整体三者的解决方案:
- 事前要对redis做高可用,使用redis-cluster模式,选择适合的内存淘汰机制
- 事中要使用本地缓存和hystrix限流熔断降级,避免mysql挂掉
- 事后如果redis崩了,使用redis持久化机制aof和rdb恢复数据
12、如何解决redis并发争抢key的问题?
并发争抢key的问题就是多个系统一起去修改获得key,导致最后程序的结果和预想的不一样。
解决方案是使用分布式锁,具体实现有zookeeper和redis。
一般我们使用zookeeper,基于zk临时有序节点实现的分布式锁。大致思想是:每个客户端对方法加锁的时候,再zk上的与该方法对应的指定节点目录下,创建一个唯一的临时有序节点,判断是否获取锁通过判断有序节点中序号最小的一个。当释放锁的时候,只需要将该临时有序节点删除即可。同时,既可以避免服务宕机导致的锁无法释放而产生的思索问题。完成业务流程后,删除对应子节点释放锁。
13、如何保证缓存和数据库的数据一致性?
一般来说,只要系统不严格要求缓存和数据库的数据一致性,都会有数据不一致的情况,解决方案有把读请求和写请求串行化,放到一个内存队列中去,这样一定不会出现不一致情况,但是这样系统的效率就大大降低了。不划算的。