多线程爬取猪八戒网站
此项目是使用多线程爬取猪八戒网址it类的所有公司信息
猪八戒主页网址:https://guangzhou.zbj.com/
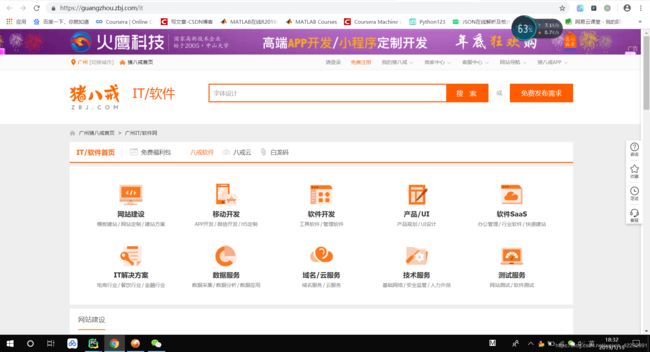
我们要爬的是it这个大类的这10小类
通过检查我们发现,所有的网址都是放在带有class=‘channel-service-grid clearfix’这个属性的div标签下面,我们可以通过使用lxml库以及xpath语法来获得所有小类的url
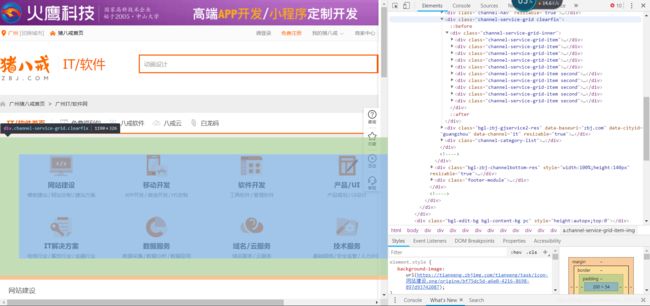
这个函数代码如下:
def get_categories_url(url):
details_list = []
text = getHTMLText(url)
html = etree.HTML(text)
divs = html.xpath("//div[@class='channel-service-grid-inner']//div[@class='channel-service-grid-item' or @class='channel-service-grid-item second']")
for div in divs:
detail_url = div.xpath("./a/@href")[0]
details_list.append(detail_url)
return details_list
随便进入一个类,我们右键检查一个公司,发现这个公司的url就放在一个带有class=‘name’的a标签下的href属性,然后再加上'https://'就好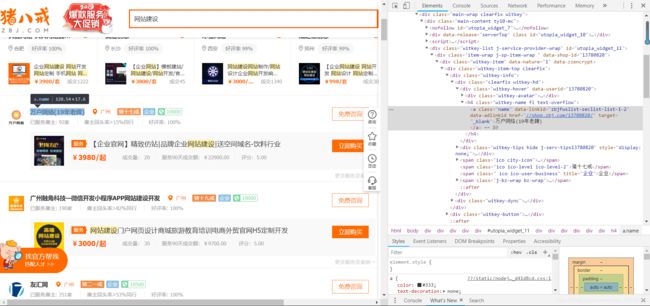
函数如下:
def get_company_urls(url):
companies_list = []
text = getHTMLText(url)
html = etree.HTML(text)
h4s = html.xpath("//h4[@class='witkey-name fl text-overflow']/a/@href")
for h4 in h4s:
company_url = 'https:' + h4
companies_list.append(company_url)
return companies_list
对于每一页,我们只需要循环遍历就能够得到一页中所有公司的信息
这时候我们随便点进去几个公司来看,发现所有公司基本可以分为两类:
一种是有首页、买服务、看案例、交易评价、人才档案之类的
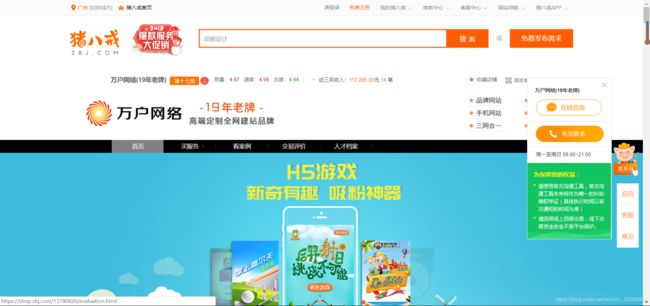
另一种是像这样就直接到人才档案这一页面的

可以看出我们要爬取的数据基本都在人才档案这个页面,因此我们要设定一个判断条件,如果它有首页、买服务、看案例、交易评价、人才档案这些的话就跳到人才档案的页面那里
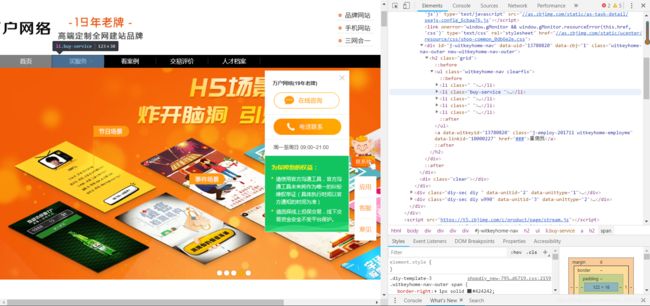
我们可以看到它这些是放在li标签下面的,我们可以这样来设定判定条件:在网页中找到带有class='witkeyhome-nav clearfix'的ul标签,获取它下面的li标签。如果获取不到li标签或者带有li标签的列表的长度为0的话就代表已经是在人才档案这个页面下面,对这一类的url就不用采取特别处理。如下图所示,对于不是直接到人才档案的网页,我们只需要找到最后一个li标签下面的href属性 再加上'https://'就ok了
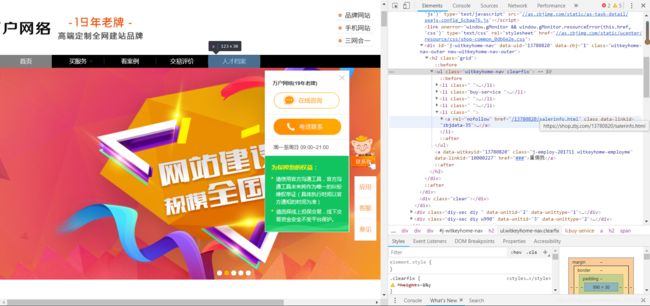
代码如下:
lis = html.xpath("//ul[@class='witkeyhome-nav clearfix']//li[@class=' ']")
if len(lis) == 0:
company_url_queue.put(company)
continue
for li in lis:
try:
if li.xpath(".//text()")[1] == '人才档案':
rcda_url = ('https://profile.zbj.com'+ li.xpath("./a/@href")[0]).split('/salerinfo.html')[0]+'?isInOldShop=1'
company_url_queue.put(rcda_url)
break
else:continue
except:pass #有一些网站的li标签是空的,因此会报错,pass掉就好
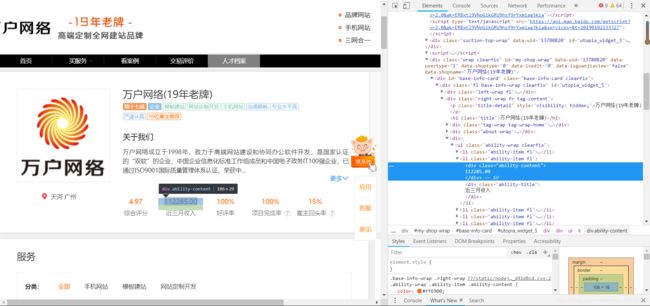
拿到每一个公司的人才档案页面url之后,正常来说我们就能够按照这个思路拿到我们所有想拿的信息。可是我第一次对爬取下来的人才档案页面url用xpath库查找信息时,发现无论写什么都是返回一个空的列表给我。我自己很确信自己写的xpath语法没有任何问题(没错就是这么自信),然后把获取到的text打印出来看一下,发现上面并没有我想要的信息。就如下图所示:我复制的是公司的近三个月利润,发现是不存在这个信息的

因此我断定这个网页采取了反爬虫的机制。我们点击右键检查找到network按F5刷新一下,然后在右边的search输入这个交易额
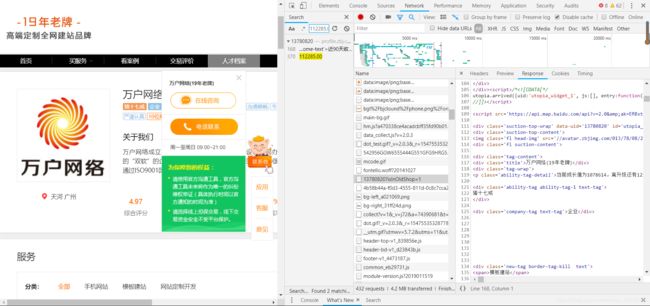
就能发现这些数据其实是写在这个名为13780820?isInOldShop=1的js文件下面。因为它采用的是ajax写进去的,所以我们正常的请求方法请求不到它的数据。我们来看下它的reques url
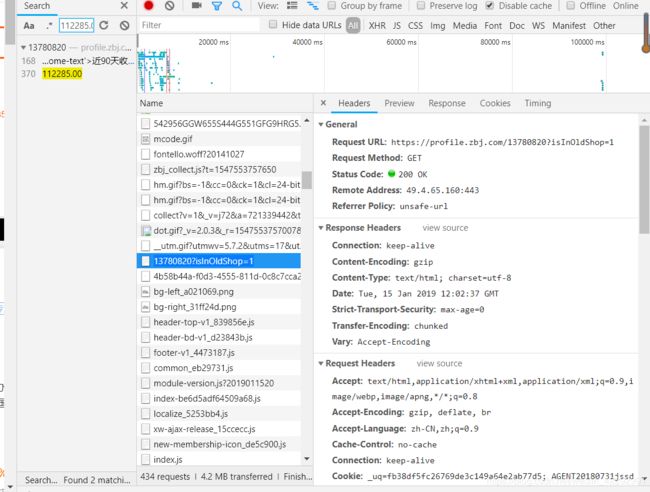
人才档案url:https://shop.zbj.com/13780820/salerinfo.html
我们可以发现只要把原来的人才档案页面的url去除掉后面的/salerinfo.html 再加上?isInOldShop=1就能拿到包含有真正数据的url
代码如下图所示:
rcda_url = ('https://profile.zbj.com'+ li.xpath("./a/@href")[0]).split('/salerinfo.html')[0]+'?isInOldShop=1'
最后对每个拿到的公司url获取自己想要的信息就可以了,代码如下
def get_company_infos(url):
company_url = url
text = getHTMLText(url)
html = etree.HTML(text)
company_name = html.xpath("//h1[@class='title']/text()")[0]
try:
grade = html.xpath("//div[@class='ability-tag ability-tag-3 text-tag']/text()")[0].strip()
except:
grade = html.xpath("//div[@class='tag-wrap tag-wrap-home']/div/text()")[0].replace('\n', '')
lis = html.xpath("//ul[@class='ability-wrap clearfix']//li")
score = float(lis[0].xpath("./div/text()")[0].strip())
profit = float(lis[1].xpath("./div/text()")[0].strip())
good_comment_rate = float(lis[2].xpath("./div/text()")[0].strip().split("%")[0])
try:
again_rate = float(lis[4].xpath("./div/text()")[0].strip().split("%")[0])
except:
again_rate=0.0
try:
finish_rate = float(lis[4].xpath("./div/text()")[0].strip().split("%")[0])
except:
finish_rate = 0.0
company_info = html.xpath("//div[@class='conteng-box-info']//text()")[1].strip().replace("\n", '')
skills_list = []
divs = html.xpath("//div[@class='skill-item']//text()")
for div in divs:
if len(div) >= 3:
skills_list.append(div)
good_at_skill = json.dumps(skills_list, ensure_ascii=False)
try:
divs = html.xpath("//div[@class='our-info']//div[@class='content-item']")
build_time = divs[1].xpath("./div/text()")[1].replace("\n", '')
address = divs[3].xpath("./div/text()")[1].replace("\n", '')
except:
build_time = '暂无'
address = '暂无'
最后再来处理几个小问题。1.每个小类它的页数,翻页的url该怎么设定?2.我们都知道一家公司可能存在于几个小类中,我们如何判断这个公司已经被爬取过?3.那么多的数据,要解析那么多页面,如何提高速度?
1.对于每一页的页数,我们翻到最下面右键检查就能发现,它写在了带有属性class='pagination-total'的div标签下的ul标签的最后一个li标签里面。因此我们可以通过下面的代码得到:

pages = int(html.xpath("//p[@class='pagination-total']/text()")[0].split("共")[1].split('页')[0])
按照正常套路,每个页面都应该是第一页带有p=0 然后后面的页数每页再加上每一页的公司总数(这里是40),可是当我检查的时候把我给奇葩到了:像这个网站开发小类的第一页看似没有问题
![]()
然后我们再看第二页
![]()
然后再看第三第四页
![]()
![]()
然后我们再看其他几个小类就会发现,每个小类的第一页后缀都是相同的,都是/p.html,然后第二页基本每个小类都会有一个对应的值,后面的从第三页开始就在第二页对应那个值得基础上加40
因此我想到用字典来存储每个小类第二页所对应的值,然后在遍历每一页前先判断它是第几页,再来确定url
代码如下
second_page_num = {'https://guangzhou.zbj.com/wzkf/p.html':34,
'https://guangzhou.zbj.com/ydyykf/p.html':36,
'https://guangzhou.zbj.com/rjkf/p.html':37,
'https://guangzhou.zbj.com/uisheji/p.html':35,
'https://guangzhou.zbj.com/saas/p.html':38,
'https://guangzhou.zbj.com/itfangan/p.html':39,
'https://guangzhou.zbj.com/ymyfwzbj/p.html':40,
'https://guangzhou.zbj.com/jsfwzbj/p.html':40,
'https://guangzhou.zbj.com/ceshifuwu/p.html':40,
'https://guangzhou.zbj.com/dashujufuwu/p.html':40
}
for category in categories_list:
j = second_page_num[category]
for i in range(1,pages+1):
if i == 1:
company_list = get_company_urls(category)
elif i == 2:
page_url = category.split('.html')[0] +'k'+str(j) +'.html'
company_list = get_company_urls(page_url)
else:
page_url = category.split('.html')[0] + 'k' + str(j+40*(i-2)) + '.html'
company_list = get_company_urls(page_url)问题解决
第二个问题 其实很简单,我们只要先设置一个列表用来存储被爬取过的公司就行。在对每一页得公司遍历时,先判断这家公司是否在列表中,如果在,就continue,如果不在,就把它加到列表中然后再进行爬取。代码如下:
is_exists_company = []
for company in company_list:
if company in is_exists_company:
continue
else:
is_exists_company.append(company)对于最后一个问题,我们都很容易想到解决方式:采用多线程
整个爬虫代码如下:
import requests
from lxml import etree
import json
import pymysql
from queue import Queue
import threading
import time
gCondition = threading.Condition()
HEADERS = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Referer':'https://guangzhou.zbj.com/'
}
company_nums = 0
is_exists_company = []
class Producer(threading.Thread):
def __init__(self,page_queue,company_url_queue,company_nums,is_exists_company,*args,**kwargs):
super(Producer,self).__init__(*args,**kwargs)
self.page_queue = page_queue
self.company_url_queue = company_url_queue
self.company_nums = company_nums
self.is_exists_company = is_exists_company
def run(self):
while True:
if self.page_queue.empty():
break
self.parse_url(self.page_queue.get())
def parse_url(self,url):
company_url_list = self.get_company_urls(url)
for company in company_url_list:
gCondition.acquire()
if company in self.is_exists_company:
gCondition.release()
continue
else:
self.is_exists_company.append(company)
self.company_nums += 1
print('已经存入{}家公司'.format(self.company_nums))
gCondition.release()
text = getHTMLText(company)
html = etree.HTML(text)
lis = html.xpath("//ul[@class='witkeyhome-nav clearfix']//li[@class=' ']")
if len(lis) == 0:
self.company_url_queue.put(company)
continue
for li in lis:
try:
if li.xpath(".//text()")[1] == '人才档案':
rcda_url = ('https://profile.zbj.com' + li.xpath("./a/@href")[0]).split('/salerinfo.html')[
0] + '?isInOldShop=1'
self.company_url_queue.put(rcda_url)
break
else:continue
except:pass # 有一些网站的li标签是空的,因此会报错,pass掉就好
def get_company_urls(self,url):
companies_list = []
text = getHTMLText(url)
html = etree.HTML(text)
h4s = html.xpath("//h4[@class='witkey-name fl text-overflow']/a/@href")
for h4 in h4s:
company_url = 'https:' + h4
companies_list.append(company_url)
return companies_list
class Consunmer(threading.Thread):
def __init__(self,company_url_queue,page_queue,*args,**kwargs):
super(Consunmer, self).__init__(*args,**kwargs)
self.company_url_queue = company_url_queue
self.page_queue = page_queue
def run(self):
while True:
if self.company_url_queue.empty() and self.page_queue.empty():
break
company_url = self.company_url_queue.get()
self.get_and_write_company_details(company_url)
print(company_url + '写入完成')
def get_and_write_company_details(self,url):
conn = pymysql.connect(host=****, user=*****, password=*****, database=****,port=****, charset='utf8')
cursor = conn.cursor() # 连接数据库放在线程主函数中的,如果放在函数外面,就会导致无法连接数据库
company_url = url
text = getHTMLText(url)
html = etree.HTML(text)
company_name = html.xpath("//h1[@class='title']/text()")[0]
try:
grade = html.xpath("//div[@class='ability-tag ability-tag-3 text-tag']/text()")[0].strip()
except:
grade = html.xpath("//div[@class='tag-wrap tag-wrap-home']/div/text()")[0].replace('\n', '')
lis = html.xpath("//ul[@class='ability-wrap clearfix']//li")
score = float(lis[0].xpath("./div/text()")[0].strip())
profit = float(lis[1].xpath("./div/text()")[0].strip())
good_comment_rate = float(lis[2].xpath("./div/text()")[0].strip().split("%")[0])
try:
again_rate = float(lis[4].xpath("./div/text()")[0].strip().split("%")[0])
except:
again_rate=0.0
try:
finish_rate = float(lis[4].xpath("./div/text()")[0].strip().split("%")[0])
except:
finish_rate = 0.0
company_info = html.xpath("//div[@class='conteng-box-info']//text()")[1].strip().replace("\n", '')
skills_list = []
divs = html.xpath("//div[@class='skill-item']//text()")
for div in divs:
if len(div) >= 3:
skills_list.append(div)
good_at_skill = json.dumps(skills_list, ensure_ascii=False)
try:
divs = html.xpath("//div[@class='our-info']//div[@class='content-item']")
build_time = divs[1].xpath("./div/text()")[1].replace("\n", '')
address = divs[3].xpath("./div/text()")[1].replace("\n", '')
except:
build_time = '暂无'
address = '暂无'
sql = """
insert into(数据表名)(id,company_name,company_url,grade,score,profit,good_comment_rate,again_rate,company_info,good_at_skill,build_time,address) values(null,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
cursor.execute(sql, (
company_name, company_url, grade, score, profit, good_comment_rate, again_rate, company_info, good_at_skill,
build_time, address))
conn.commit()
def getHTMLText(url):
resp = requests.get(url,headers=HEADERS)
resp.encoding='utf-8'
return resp.text
def get_categories_url(url):
details_list = []
text = getHTMLText(url)
html = etree.HTML(text)
divs = html.xpath("//div[@class='channel-service-grid-inner']//div[@class='channel-service-grid-item' or @class='channel-service-grid-item second']")
for div in divs:
detail_url = div.xpath("./a/@href")[0]
details_list.append(detail_url)
return details_list
def main():
second_page_num = {'https://guangzhou.zbj.com/wzkf/p.html':34,
'https://guangzhou.zbj.com/ydyykf/p.html':36,
'https://guangzhou.zbj.com/rjkf/p.html':37,
'https://guangzhou.zbj.com/uisheji/p.html':35,
'https://guangzhou.zbj.com/saas/p.html':38,
'https://guangzhou.zbj.com/itfangan/p.html':39,
'https://guangzhou.zbj.com/ymyfwzbj/p.html':40,
'https://guangzhou.zbj.com/jsfwzbj/p.html':40,
'https://guangzhou.zbj.com/ceshifuwu/p.html':40,
'https://guangzhou.zbj.com/dashujufuwu/p.html':40
}
global company_nums
company_url_queue = Queue(100000)
page_queue = Queue(1000)
categories_list = get_categories_url('https://guangzhou.zbj.com/it')
for category in categories_list:
text = getHTMLText(category)
html = etree.HTML(text)
pages = int(html.xpath("//p[@class='pagination-total']/text()")[0].split("共")[1].split('页')[0])
j = second_page_num[category]
for i in range(1,pages+1):
if i == 1:
page_queue.put(category)
elif i == 2:
page_url = category.split('.html')[0] +'k'+str(j) +'.html'
page_queue.put(page_url)
else:
page_url = category.split('.html')[0] + 'k' + str(j+40*(i-2)) + '.html'
page_queue.put(page_url)
print('{}的第{}页已经保存到队列中'.format(category,i))
time.sleep(1)
print('url存入完成,多线程开启')
for x in range(5):
t = Producer(page_queue,company_url_queue,company_nums,is_exists_company)
t.start()
for x in range(5):
t = Consunmer(company_url_queue,page_queue)
t.start()
if __name__ == '__main__':
main()感谢观看