SIMD、SSE、AVX指令集
指令集
指令集是指CPU能执行的所有指令的集合,每一指令对应一种操作,任何程序最终要编译成一条条指令才能让CPU识别并执行。CPU依靠指令来计算和控制系统,所以指令强弱是衡量CPU性能的重要指标,指令集也成为提高CPU效率的有效工具。
CPU都有一个基本的指令集,比如说目前英特尔和AMD的绝大部分处理器都使用的是X86指令集,因为它们都源自于X86架构。但无论CPU有多快,X86指令也只能一次处理一个数据,这样效率就很低下,毕竟在很多应用中,数据都是成组出现的,比如一个点的坐标(XYZ)和颜色(RGB)、多声道音频等。为了提高CPU在某些方面的性能,就必须增加一些特殊的指令满足时代进步的需求,这些新增的指令就构成了扩展指令集。该指令集采用单指令多数据(single instruction multiple data,简称 SIMD)扩展技术。
Intel扩展指令集的演变
Intel扩展指令集链接:intel扩展指令集机票
MMX
英特尔在1996年率先引入了MMX(Multi Media eXtensions)多媒体扩展指令集,也开创了SIMD(Single Instruction Multiple Data,单指令多数据)指令集之先河,即在一个周期内一个指令可以完成多个数据操作,MMX指令集的出现让当时的MMX Pentium大出风头。
SSE
SSE(Streaming SIMD Extensions,流式单指令多数据扩展)指令集是1999年英特尔在Pentium III处理器中率先推出的,并将矢量处理能力从64位扩展到了128位。在Willamette核心的Pentium 4中英特尔又将扩展指令集升级到SSE2(2000年),而SSE3指令集(2004年)是从Prescott核心的Pentium 4开始出现。
SSE4(2007年)指令集是自SSE以来最大的一次指令集扩展,它实际上分成Penryn中出现的SSE4.1和Nehalem中出现的SSE4.2,其中SSE4.1占据了大部分的指令,共有47条,Nehalem中的SSE4指令集更新很少,只有7条指令,这样一共有54条指令,称为SSE4.2。
AVX
2007年8月,AMD抢先宣布了SSE5指令集(SSE到SSE4均为英特尔出品),英特尔当即黑脸表示不支持SSE5,转而在2008年3月宣布Sandy Bridge微架构将引入全新的AVX指令集,同年4月英特尔公布AVX指令集规范,随后开始不断进行更新,业界普遍认为支持AVX指令集是Sandy Bridge最重要的进步,没有之一。
AVX(Advanced Vector Extensions,高级矢量扩展)指令集借鉴了一些AMD SSE5的设计思路,进行扩展和加强,形成一套新一代的完整SIMD指令集规范。
MMX、SSE、AVX
MMX
MMX系列指令集使用单独的64bit寄存器(MM寄存器),寄存器个数不清楚,一次处理64bit的数据。可以存放数据如下。
寄存器结构:
| MM0 |
|---|
| MM1 |
| MM2 |
| MM3 |
| MM4 |
| … |
每个MM寄存器可以存储的值的大小和个数如下(bit, 1字节(B)= 8bit)
MMX指令只能处理整型(字符,短整,整型,这里的整形为32bit)
寄存器大小:
| 64bit |
|---|
一次处理两个32bit整型
| 32bit | 32bit |
|---|
一次处理4个16bit整型
| 16bit | 16bit | 16bit | 16bit |
|---|
一次处理8个字符
| 8bit | 8bit | 8bit | 8bit | 8bit | 8bit | 8bit | 8bit |
|---|
SSE
MMX系列指令集使用单独的128bit寄存器(XMM寄存器),寄存器个数16(不同计算机可能不同),一次处理128bit的数据。可以存放数据如下。
寄存器结构:
| XMM0 |
|---|
| XMM1 |
| XMM2 |
| XMM3 |
| XMM4 |
| … |
每个XMM寄存器可以存储的值的大小和个数如下
SSE指令能处理整型,单精度浮点,双精度浮点
注:为什么会有16bit?拿整型来说,对于不同的计算机,占的字节不同,有一个size_t的数据类型,在不同计算机上可能占得字节不同(4B,或者2B),具体可以使用sizeof(数据类型)来查看此类型占得字节数。
寄存器大小:
| 128bit |
|---|
一次处理2个64bit的数据类型
| 64bit | 64bit |
|---|
一次处理4个32bit的数据类型
| 32bit | 32bit | 32bit | 32bit |
|---|
一次处理8个16bit数据类型
| 16bit | 16bit | 16bit | 16bit | 16bit | 16bit | 16bit | 16bit |
|---|
AVX
AVX高级矢量扩展,在SSE的基础上又把寄存器大小扩展为256bit。这次AVX将所有16个128位XMM寄存器扩充为256位的YMM寄存器,从而支持256位的矢量计算。理想状态下,浮点性能最高能达到前代的2倍水平。同时所有的SSE/SSE2/SSE3/SSSE3/SSE4指令是被AVX全面兼容的(AVX不兼容MMX),因此实际操作的是YMM寄存器的低128位,在这一点上与原来的SSE系列指令集无异。
-
支持256位矢量计算,浮点性能最大提升2倍
-
增强的数据重排,更有效存取数据
-
支持3操作数和4操作数,在矢量和标量代码中能更好使用寄存器
-
支持灵活的不对齐内存地址访问
-
支持灵活的扩展性强的VEX编码方式,可减少代码
寄存器结构:
| YMM0 |
|---|
| YMM1 |
| YMM2 |
| YMM3 |
| YMM4 |
| … |
寄存器大小
| 256bit |
|---|
一次处理4个64bit的数据类型
| 64bit | 64bit | 64bit | 64bit |
|---|
一次处理8个32bit的数据类型
| 32bit | 32bit | 32bit | 32bit | 32bit | 32bit | 32bit | 32bit |
|---|
指令的使用
指令功能介绍
这里只讲解指令的简单使用,内部原理及其寻址什么的流程,自行深抛。
程序必然包括数据和操作,要计算数据,肯定要去cpu的运算器,所以数据会从(如果数据小可能直接全放cache了)内存到cache,再从cache到register,然后进入运算器计算,计算得到数据如果短时间不用,或者想长久保存,则可能需要重写回内存或者硬盘。
简单来说,分三步:
- 写入数据
- 运算数据
- 数据写出
那么数据的写入和写出就对应了扩展指令集的访存指令,数据计算就对应了运算指令。另外还有许多指令类型。具体如下:
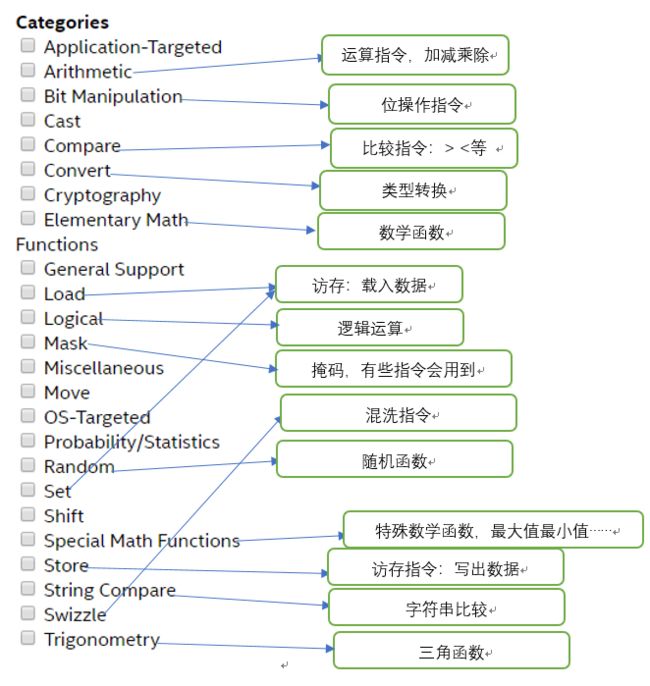
指令导读
指令的具体用法还是要查指令手册
每一个指令的构成都可以理解一个函数。
返回值类型 函数名 (形参列表)
1)类型
- __m128 128bit 存储单精度浮点float
__m128i 128bit 存储整形int
__m128d 128bit 存储双精度浮点double - __m256 256bit 存储单精度float
__m256i 256bit 存储整型int
__m256d 256bit 存储双精度double
2)函数名
| _mm :128bit | _mm256 :256bit |
|---|---|
| _load :操作 | _load :操作 |
| _ps :p=package,s=float | _ps :p=package,s=float |
| _pd :p=package,s=double | _pd :p=package,s=double |
| _ss :p=scalar,s=float | _ss :p=scalar,s=float |
package:是向量数据打包的意思 scalar是标量,一个数据的意思
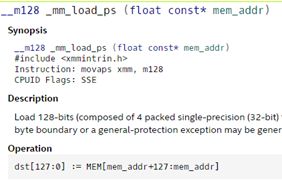

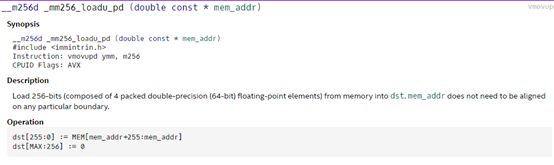
3)形参:要传入的数据的类型指定,一般为地址
如下图:
函数
头文件
指令
编译Flags
Op:指令数据的操作规则
SSE,AVX为什么会提升性能
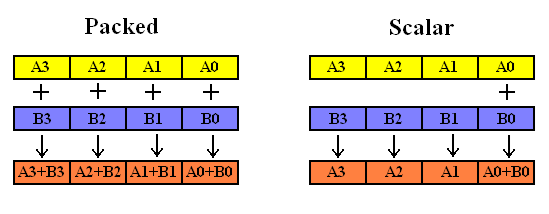
SIMD

SSE指令的不同形式
- 垂直计算形式
例如:_mm_add_ps();

- 水平计算形式
例如:_mm_hadd_ps();
_mm256_hadd_ps();

- 标量形式(scalar)

示例代码
1-loop.c
#include2-ctrl_flow-f4
#include
int block = N / 8;
__m256 ymm_a = _mm256_setzero_ps();
__m256 ymm_b = _mm256_setzero_ps();
__m256 ymm_c = _mm256_setzero_ps();
__m256 avx_sum, avx_sub;
__m256 mask;
__m256 blendv;
for(i = 0; i < 1; i++){
ymm_a = _mm256_loadu_ps(a +i*8);
ymm_b = _mm256_loadu_ps(b +i*8);
ymm_c = _mm256_loadu_ps(c +i*8);
avx_sum = _mm256_add_ps(ymm_b, ymm_c);
avx_sub = _mm256_sub_ps(ymm_c, ymm_a);
mask = _mm256_cmp_ps(ymm_b,ymm_c, 2); //30
blendv = _mm256_blendv_ps(avx_sub, avx_sum, mask);
printf("%f, %f, %f, %f, %f, %f, %f, %f\n",
blendv[0], blendv[1], blendv[2], blendv[3],
blendv[4], blendv[5], blendv[6], blendv[7]);
_mm256_storeu_ps(a + i*8, blendv);
}
if(a[2]==3)
printf("\n结果正确,测试完成!\n\n");
else
printf("\n结果不正确,测试完成!\n\n");
return 0;
}
3-reducetion-d4.c
#include
__m256 avx_sum = _mm256_setzero_ps();
__m256 ymm0;
int block = N / 8;
for(i = 0; i < block; i++){
ymm0 = _mm256_loadu_ps(a + i*8);
avx_sum = _mm256_hadd_ps(ymm0, avx_sum);
}
avx_sum = _mm256_hadd_ps(avx_sum, avx_sum);
avx_sum = _mm256_hadd_ps(avx_sum, avx_sum);
sum += avx_sum[0] + avx_sum[4];
printf("sum = %f ", sum);
if(sum==7)
printf("\n结果正确,测试完成!\n\n");
else
printf("\n结果不正确,测试完成!\n\n");
return 0;
}
4-unalign-d4.c
#include
int block = N / 4 / 4;
__m256d avx_sum0 = _mm256_setzero_pd();
__m256d ymm0, ymm1;
for(i = 0; i < block; i++){
ymm0 = _mm256_loadu_pd(a + 1 +i*4);
ymm1 = _mm256_loadu_pd(b + 1 +i*4);
avx_sum0 = _mm256_add_pd(avx_sum0, ymm0);
avx_sum0 = _mm256_add_pd(avx_sum0, ymm1);
_mm256_storeu_pd(c + i*4, avx_sum0);
avx_sum0 = _mm256_setzero_pd();
}
if(c[2]==7)
printf("\n结果正确,测试完成!\n\n");
else
printf("\n结果不正确,测试完成!\n\n");
return 0;
}
5-cvt-df.c
#include
int block = N / 4;
__m256d ymm_pd;
__m128 ymm_ps;
for(i = 0; i < block; i++){
ymm_pd = _mm256_loadu_pd(b + i*4);
ymm_ps = _mm256_cvtpd_ps(ymm_pd);
//printf("%f, %f, %f, %f\n",
// ymm_ps[0], ymm_ps[1], ymm_ps[2], ymm_ps[3]);
_mm_storeu_ps(a + i*4,ymm_ps);
}
if(a[2]==3)
printf("\n结果正确,测试完成!\n\n");
else
printf("\n结果不正确,测试完成!\n\n");
return 0;
}