三、python高级:正则表达式
一、re模块(re.match、group()方法)
1、

2、re.match() 能够匹配出以xxx开头的字符串(从左到右开始依次匹配)
若匹配成功,则返回匹配对象(Match Object),否则返回None,
group方法,用来返回字符串的匹配成功的部分。

3、match方法有一个特点:校验的字符串从左往右去匹配规则,在这个匹配的过程中只要满足了全部的规则,即使要校验的字符串后面还有字符串,它就认为你已经符合这个规则了,也就是你所定义的规则只是描述了你所定义字符串的一部分,而且是从左到右启始的,这个点很重要的
二、正则表达式的单字符匹配

1、. 匹配任意1个字符(除了\n都能匹配)——(例如#、?都能匹配)

2、\d 匹配数字,即0-9
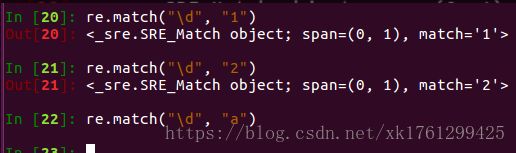
3、\D 匹配非数字,即不是数字
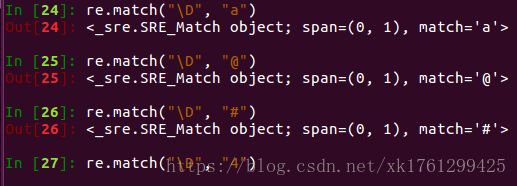
4、\s 匹配空白,即空格、\t、\n、\r

5、\S 匹配非空白

6、\w 匹配单词数字下划线,即a-z A-Z 0-9 _
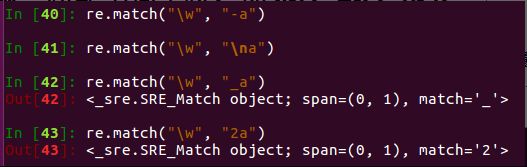
7、\W 匹配非单词数字下划线,即不是a-z A-Z 0-9 _
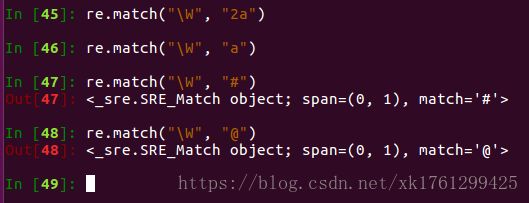
8、[ ] :匹配[ ]中列举的字符
① 第二位匹配3578的任意一个
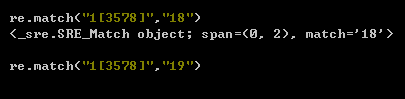
② 取反,加个^ 即非34578

③ 第二位匹配 a-z 5-9

三、正则数量描述
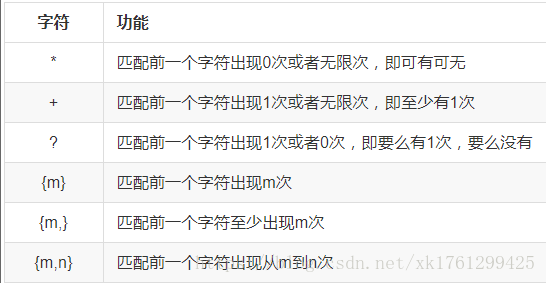
1、* 匹配前一个字符出现0次或者无限次,即可有可无
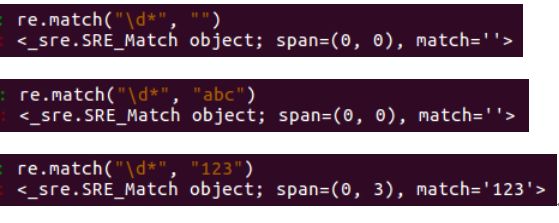

2、+ 匹配前一个字符出现1次或者无限次,即至少有1次
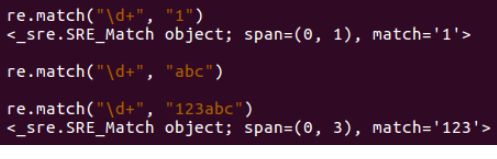

3、? 匹配前一个字符出现1次或者0次,即要么有1次,要么没有
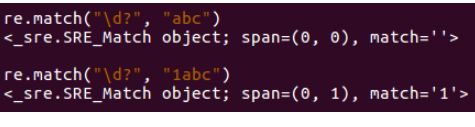

4、{m} 匹配前一个字符出现m次(必须满足m次)

5、{m,} 匹配前一个字符至少出现m次

6、{m,n} 匹配前一个字符出现从m次到n次

7、{0,} 与 * 类似——0次或无限次
8、{1,} 与+类似——至少有1次
9、{0,1} 与?类似——出现1次或0次
四、正则边界描述
1、$ 匹配字符串结尾——加上$后,结束的意思,限制匹配字符串内容个数,超出不输出

2、^ 匹配字符串开头
^ 不是出现在[ ]当中的话(出现在[ ]内叫取反),而是出现在描述的开始位置,所要表达的意义是不一样的
但是这个在match()方法中是体现不出来的,因为match()方法就是从头开始进行匹配的

3、\b 匹配一个单词的边界
一个字符串中(“ ”内),出现空格会分成单独的单词,连在一块会默认一个整体
总结:^和$是描述整个字符串(整个规则)的边界,也就是 " " 里面所有的都考虑;
\b 、\B是描述中间某个单词的边界(有空格分割,可分割成单独的单词)
如果字符串没有要匹配的字母,也不返回输出任何值
① 要以ve作为单词的结尾才可以:
也就是,先匹配\w,再找ve字母,比较是否符合\b意义,以ve结尾

② 下面:有空格hove作为单独的单词,检查边界
从左到右匹配,匹配到hove是以ve结尾的,返回hove,因为有空格,abc是另一个单词不管它

③ \s匹配了空格,而ve前边和后边都是ve,所以输出 ho ve

4、\B 匹配非单词边界 ,与上述相反
① \B要求ve的e右边部分必须得出现字符,不能出现空白字符,一旦出现了空白字符,就意味着e是这个单词的结尾了,也就是e是这个单词的边界了。——不输出
如果字符串没有ve字母,也不返回输出任何值
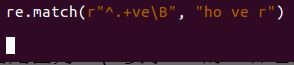
只要单词不是ve结尾就匹配成功,返回值

五、转义 使用 原始字符串 r 能够自动转义\t、\n等
来理解转义:
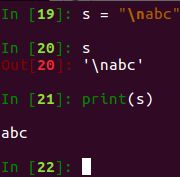
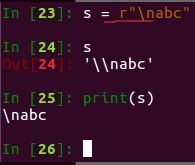
print(\n) 是打印空格,加上r后自动转义,相当于\\nabc,此时的 \n仅仅是个字符,是原义

总结:
1、r的意思是说:它是英文单词raw的一个缩写,也就是说当你在定义这个字符串的时候它是什么样的,最终在输出打印的时候
就是什么样的,中间转义的过程python帮我们实现了。
2、例如:re.match(r"[a-z0-9][a-z0-9_]{2,14}[a-z0-9]@sina\.com$ " , "[email protected]") ——新浪邮箱注册限制
① 以后写正则表达式要习惯加上 r ,因为\n、\t没在正则表达式中出现过,所以用r自动转义;而 . 在正则表达式中出现了,所以单独转义 \.
② 而\d、\w有特殊意义,在正则表达式中出现,如果转义单独转义。
③ 点在正则中有特殊意义,要匹配,想要后面字符串输入的sina.com必须是点,而不是sina@com要用 \. 自动转义(\自动转义)
六、匹配分组
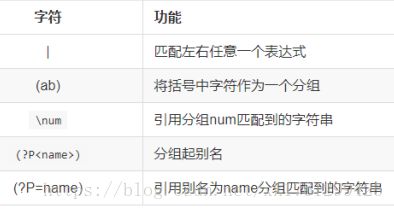
1、| 匹配左右任意一个表达式 (| 或者的意思,匹配字符串整个内容的)
需求:匹配出0-100之间的数字

可以改进一下:

2、(ab)将括号中字符作为一个分组,可单独拿出来
① 进行group()的时候是得到的整个匹配的内容
group()方法添加参数,例如group( 1 ) 可单独拿出第一个分组内的内容
(参数0,写上和不写一样,都代表得到整个内容)
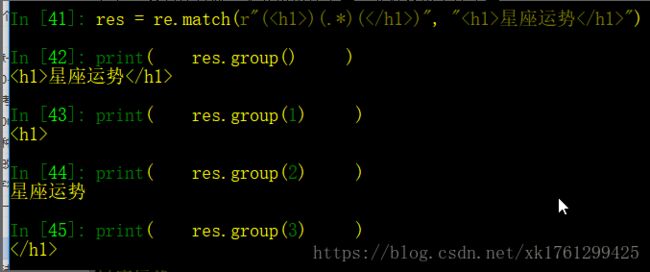
② groups()方法:是得到所有的组的内容 —— (以元组的形式返回)
以元组的形式返回:

可拿到元组下标0、1、2的内容
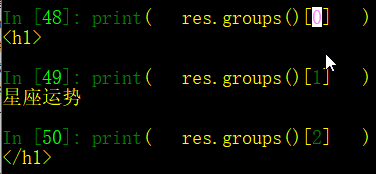
3、\num 引用分组num匹配到的字符串

![]()
4、 (?P
(?P=name) 引用别名为name分组匹配到的字符串

![]()
七、search、findall、sub、split方法介绍
1、search方法是在字符串中从左向右进行搜索,直到在整个字符串当中搜索到匹配的内容以后才截止了
找到第一个匹配的,就不会往下搜索了
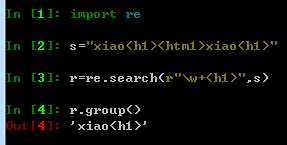
2、findall找到所有匹配的内容 — 直接以列表的形式输出数据,不需要group()方法
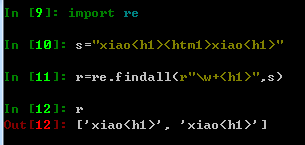
3、sub 将匹配到的数据进行替换(需三个参数)
(查找的内容,替换的值,字符串)

那想要:根据原有的值进行相应的替换,而不是替换成统一的值,这种需要求的话就可以使用函数了,
以函数的返回值作为要替换的内容,下面result是匹配的结果作为了参数了:(不常用)
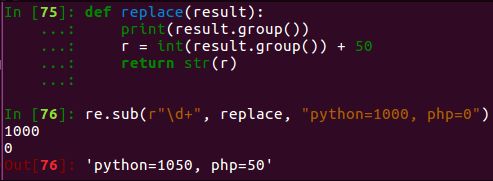
4、split 根据匹配进行切割字符串,并返回一个列表
下面是以【冒号】或是【空格】进行分割。(也就是见这几个符号进行切割)

![]()
示例:下面是以【空格】【冒号】【逗号】【中横线】进行分割
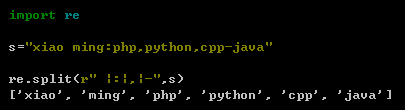
示例:hello world ha ha ,查找所有的单词 (以空格+查找简单)
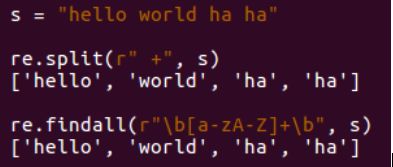
八、贪婪与非贪婪
1、贪婪就是尝试在满足后面正则约束的最小条件下,自身尽可能匹配更多的字符。
2、非贪婪就是在满足自身正则约束的条件下,尽可能让后面的正则约束匹配到更多的字符。
3、实例:
贪婪模式:

贪婪模式下,第一组正则约束会在满足第二组正则约束的最小条件下,也就是只匹配一个数字的条件下,匹配更多的字符,所以第一组正则会一直匹配到数字23才结束。
非贪婪模式:在贪婪的规则后面加上?
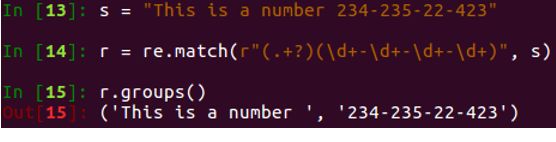
非贪婪模式下,第一组正则约束会尽可能满足后面正则约束的规则,也就是让后面的正则匹配到更多的字符,所以第二组正则会从它的最大匹配范围开始,也就是从234开始,而第一组正则匹配到空格就结束了。