(四)(假视频生成)基本文本的会话头视频编辑Text-based Editing of Talking-head Video 2019
目录
项目地址:https://www.ohadf.com/projects/text-based-editing/
效果:给定任意文本,就能随意改变一段视频里人物说的话。
Section 1:introduction
展示了基于文本的编辑结果以及以前技术的对比,主要的技术贡献:
Section 2:Related Work
面部重塑(Facial Reenactment)
视觉配音(Visual Dubbing):
装配模型的语音动画(Speech Animation for rigged models)
基于文本的视频和音频编辑(Text-Based Video and Audio Editing)
音频合成(Audio Synthesis)
深度生成模型(Deep Generative Models):
单目三维人脸重建(Monocular 3D Face Reconstruction):
Section 3:Method
Method overview
3.1音素对齐(Phoneme Alignment)
3.2三维人脸跟踪与重建(3D Face Tracking and Reconstruction)
3.3 视位搜索(Viseme Search)
3.4 参数重定时和混合( Parameter Retiming & Blending)
3.5 神经面部渲染(Neural Face Rending):
I.训练神经面部渲染器(Training the Neural Face Renderer)
4.1.视频编辑(Video Editing)
4.2.翻译(Translation)
4.3.使用合成语音进行全句合成(Full Setence Synthesis Using Synthetic Voice)
Section 5:Evaluation analysis and Compare
Section 6:局限性和未来发展
Section 7:Conclusion
项目地址:https://www.ohadf.com/projects/text-based-editing/
paper:Text-based Editing of Talking-head Video 2019
相关解析地址:https://mp.weixin.qq.com/s/59G434OvgYR928v5qvxnaQ
效果:给定任意文本,就能随意改变一段视频里人物说的话。
编辑会话头视频以改变语音内容或删除填充词是具有挑战性的。我们提出了一种基于其转录本来编辑会话头视频的新方法,以产生真实的输出视频,其中扬声器的对话被修改,同时保持无缝的视听流[audio-visual flow](即没有跳跃切换)。
通过音素(phonemes),视位(visemes),3D面部姿势(3D face pose)和几何(geometry),反射(reflectance),表达(expression)和每帧场景照明(scene illumination per frame)自动注释输入的说话头视频。要编辑视频,用户必须仅编辑脚本,然后优化策略选择输入语料库的片段作为基础材料。对应于所选片段的注释参数被无缝地拼接在一起并用于产生中间视频表示,其中面部的下半部分用参数面部模型来呈现。最后,循环视频生成网络将该表示转换为与编辑的转录本匹配的逼真视频。
演示了各种各样的编辑,例如词的添加,删除和更改,以及令人信服的语言翻译和完整句子合成。
Section 1:introduction
方法仅接受文本作为合成的输入,建立在Kim等人的Deep Video Portraits方法的基础之上制作合成视频。
- 我们的方法通过无缝拼接从原始素材跟踪的不同运动片段来驱动3D模型。
- 基于动态编程优化来选择片段,该动态编程优化使用基于viseme的新颖相似性度量来搜索应当看起来像我们想要合成的单词的抄本中的声音序列。这些片段可以重新定时以匹配目标视位序列,并且被混合以创建无缝嘴部动作。
- 为了合成输出视频,我们首先创建一个合成复合视频,其中下面区域被屏蔽掉。在插入新文本的情况下,我们将边界的其余部分和背景重新定时。使用先前通过优化找到的嘴部运动,使用合成的3D人脸模型进行合成遮蔽的区域(如下图)

3D面部模型的不完整性和不完美性而缺乏真实感。例如,面部外观不完全匹配,缺少动态高频细节,并且嘴部内部不存在。尽管如此,这些数据对于新学习的循环视频生成网络来说是足够的线索,能够将它们转换为逼真的图像。新的复合表示和循环网络公式显着扩展了Kim等人的神经面部转换方法到 [2018b]基于文本的现有视频编辑。
-
展示了基于文本的编辑结果以及以前技术的对比,主要的技术贡献:
(1)一种基于文本的会话头视频编辑工具,除了在现有的脚本中剪切和复制粘贴外,还允许编辑插入新文本。
(2)基于动态编程的策略,适用于视频合成,根据包含输入视频中观察到的视频序列的片段组合新词
(3)一种参数混合方案,当与我们的综合管道结合使用时,即使将不同姿势和表达的片段组合在一起,也可以产生无缝的会话头
(4)一种经常性的视频生成网络,它将真实背景视频和合成渲染的下部面部的合成转换为逼真的视频
Section 2:Related Work
-
面部重塑(Facial Reenactment)
采用面部重演方法来显示基于文本的编辑结果,并展示如何通过神经面部渲染来解决面部重演问题
-
视觉配音(Visual Dubbing):
面部重演是视觉配音的基础,因为它允许改变目标演员的表达,以匹配以不同语言说话的配音演员的动作。视觉配音方法:
(1)语音驱动(speech-driven)语言驱动的方法已被证明可以产生准确的唇同步视频(Synthesizing Obama: learning lip sync from audio),这种方法可以合成相当准确的唇形同步视频,但它需要新的音频听起来与原始扬声器类似,而我们使用基于文本的编辑来合成新视频。
本文方法优势:基于3D的方法和神经渲染器可以产生细微的现象,例如唇部滚动,并且在更一般的环境中工作
(2)绩效驱动(performance-driven)
-
装配模型的语音动画(Speech Animation for rigged models)
几种相关方法产生语音动画曲线,它们专为动画3D模型而设计,不适用于逼真的视频,需要角色装备和艺术家提供的装备通信。
本文方法优势:只是根据文本和主题的单眼记录来“动画”真实的人。
-
基于文本的视频和音频编辑(Text-Based Video and Audio Editing)
基于时间对齐的转录开发了各种音频和视频编辑工具,工具允许编辑缩短和重新安排音频播客的语音;注释带有评论反馈的视频;提供视频内容的音频描述;用于分割B-roll素材并生成讲座视频的结构化摘要等;使用由时间对齐的脚本强加的结构,根据编辑器指定的更高级别的电影习语自动编辑脚本场景的多个镜头;通过剪切,复制和粘贴脚本文本来编辑面试风格的谈话视频的工具是最接近的工作
本文方法优势:同样通过剪切,复制和粘贴文本来重新排列视频,但与以前的所有基于文本的编辑工具不同,我们只需在脚本中输入新文本即可合成新视频。
-
音频合成(Audio Synthesis)
基于脚本的视频编辑中,合成视频剪辑伴随着音频合成。本文方法与音频无关,可以使用各种文本到语音(TTS)方法。TTS方法分为
(1)参数方法:(parametric methods):基于文本生成声学特征,然后从这些特征合成波形。Ref:2016. WaveNet: A generative model for raw audio.
(2)单位选择(unit selection):是一种数据驱动的方法,通过将转录本中其他地方发现的小块音频(或单位)拼接在一起来构建新的波形。
- VoCo合成音频:在现有记录中执行搜索以找到可以拼接在一起的短音频范围,使得它们在插入点周围的上下文中无缝地混合
Ref:[VoCo: text-based insertion and replacement in audio narration. AC 2017]
- 目前最先进的TTS方法依赖于深度学习:
ref:
2018. Natural TTS synthesis by conditioning wavenet on mel spectrogram predictions.
2016. WaveNet: A generative model for raw audio. In SSW. 125
-
深度生成模型(Deep Generative Models):
研究人员提出了用于合成图像和视频的深度生成对抗网络(GAN)
方法:
(1)从零开始创建新图像(配对语料库)
Ref:2017. Photographic Image Synthesis with Cascaded Refinement Networks
(2)在输入视频上调节合成(配对语料库):
Ref:Image-to-Image Translation with Conditional Adversarial Networks. 2017
(3)高分辨率条件视频合成(配对语料库)
Ref:2018a. Video-to-Video Synthesis. In Advances in Neural Information Processing Systems (NeurIPS)
(4)不成对的视频到视频翻译技术只需要两个训练视频(不成对)应用:人类头部的再现,头部,上半身以及整个个体显示了清晰的结果
Ref:2018. Recycle-GAN: Unsupervised Video Retargeting. In ECCV
-
单目三维人脸重建(Monocular 3D Face Reconstruction):
概念:使用优化方法从单一图像重建面部几何和外观。
技术:
(1)使用参数化人脸模型作为更好地约束重建问题的先行者
(2)基于深度学习的方法来训练卷积网络直接回归模型参数
(3)Depth maps(其他方法见详细深度图)
(1)Ref:2018. Large Scale 3D Morphable Models.
(2)Ref:
2017. End-To-End 3D Face Reconstruction With Deep Neural Networks.
- Unsupervised Training for 3D Morphable Model Regres- sion CVPR
2016 3D Face Reconstruction by Learning from Synthetic Data.
- Regressing Robust and Discriminative 3D Morphable Models with a very Deep Neural Network. (CVPR)
(3)Ref:
2018.Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz.CVPR
- CNN-based Real-time Dense Face Reconstruction with Inverse-rendered Photo-realistic Face Images.IEEE
2015 Real-time High-fidelity Facial Performance Capture.ACM
Section 3:Method
- input:将语音记录和文本上指定的任意数量的编辑视频记录作为输入
- 支持三种类型的编辑操作:
- 添加新词:编辑在视频中的某个点添加一个或多个连续的单词(例如,因为演员跳过单词或制作人想要插入短语)。
- 重新排列现有单词:编辑移动视频中存在的一个或多个连续单词(例如,为了更好的单词排序而不引入跳跃切换)。
- 删除现有单词:编辑会从视频中删除一个或多个连续单词(例如,为了简化措辞和删除填充程序,例如“嗯”或“呃”)
-
Method overview

方法概述:给定输入头部视频和脚本,我们执行基于文本的编辑。我们首先将音素(Phonemes)与输入音频(input audio)对齐并跟踪每个输入帧以构建参数化头部模型。然后,对于给定的编辑操作(将蜘蛛变为狐狸),我们发现输入视频的片段与新词具有相似的视位(Viseme)。在上述情况下,我们使用毒蛇和牛来构建狐狸。我们使用来自相应视频帧的混合头部参数(blended head parameters)以及重新定时的背景序列(retimed background sequence)来生成合成图像,该合成图像用于使用我们的神经面部渲染(neural face rendering method.)方法生成逼真的帧。在最终的视频中,这位女演员似乎在说狐狸,尽管在原始录音中她从未说过这个词。
3.1音素对齐(Phoneme Alignment)
音素:感知上不同的单位,用于在特定语言中区分不用的词
方法:依赖于音素来查找视频中的片段,我们后来将这些片段组合在一起以生成新内容
- 计算输入视频中音素的标识(identity)和时间(time)
- 为将视频的语音音频分割成电话(音素的可听实现),假设我们有一个准确的文本记录,并使用P2FA方法将其与音频对齐。
每个音素具有表示音素名称,开始时间和结束时间的标签vi =(vlbl i,vin i,vout i)如果没有将输入内容作为输入的一部分,我们可以使用自动语音转录工具或众包转录服务获得它。音素的有序序列V =(v1,...,vn)
P2FA->一种音素对其工具ref:2013. Content-based tools for editing audio stories.
3.2三维人脸跟踪与重建(3D Face Tracking and Reconstruction)
- 为输入的会话头视频的每一帧注册3D参数面部模型。模型的参数(例如表情,头部姿势等)稍后将允许我们选择性地混合面部的不同方面(例如,从一个框架中获取表达并从另一个框架中获取姿势)。
- 应用了基于单眼模型的面部重建的最新研究。技术参数化刚性头部姿势T∈SE(3),面部几何形状α∈R80,面部反射率β∈R80,面部表情δ∈R64和场景照射γ∈R27。
III.模型拟合基于非线性重建能量的最小化。见ref
我们为输入视频的每帧获得257参数矢量p∈R257。
非线性重建能量的最小化-》Ref:2016. Reconstruction of Personalized 3D Face Rigs from Monocular Video. ACMTransactions
3.3 视位搜索(Viseme Search)
- 目标:是在视频中找到可以组合以产生W语言序列的匹配的序列序列。
- 匹配过程:平均来说,相同的音素在视觉上与不相同的音素相比在视觉上更相似(尽管共同发音效果)。考虑视位,视觉上彼此相似的听觉上不同的音素组,作为良好的潜在匹配。匹配过程不能指望在视频中为编辑操作中的长字或序列找到良好的连贯视位序列。相反,我们必须找到几个匹配的子序列和一种最佳组合方式。
- 匹配一个子序列(Matching one subsequence)
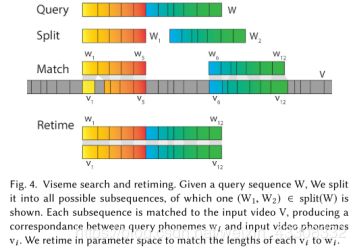
Viseme搜索和重新定时;给定查询序列W,我们将其分成所有可能的子序列,其中显示了一个(W1,W2)∈分裂(W)。每个子序列与输入视频V匹配,产生查询音素wi和输入视频音素vi之间的对应关系。我们在参数空间中重新定时以将每个vi的长度与wi匹配。
3.4 参数重定时和混合( Parameter Retiming & Blending)
- 问题:视频子序列的序列V描述视频的部分以供我们组合以便创建W.我们不能直接使用对应于(V1,...,Vk)的视频帧。原因:(1)序列Vi对应于视在同一性中的W的一部分,但不是视位长度,当与语音音频结合时将产生非自然视频,(2)连续序列Vi和Vi + 1可以来自原始视频中相距很远的部分。由于姿势和姿势变化,头发移动或相机运动,受试者在这些部位可能看起来不同。连续序列之间的转换看起来不自然

- 解决:使用参数化人脸模型来混合不同来自不同的输入帧的属性(姿势,表达,等),并将它们混合在参数空间中。我们还选择背景序列B并将其用于姿势数据和背景图像。背景序列允许我们编辑具有头发运动和轻微相机运动的具有挑战性的视频。
(1)背景重新定时和姿势提取(Background retiming and pose extraction)
(2)子序列重定时(Subsequence retiming)
(3)参数混合(Parameter bending):避免跳跃切割,我们对不同的参数使用不同的策略
3.5 神经面部渲染(Neural Face Rending):
- 概念:采用神经面部渲染来合成与修改后的参数序列相匹配的逼真的视频头部视频。
- Pre-Output:编辑的参数序列,其描述新的期望的面部运动和对应的重新定时的背景视频剪辑。
- 合成步骤的目标是改变重新定时的背景视频的面部运动以匹配参数序列。
- 做法:在重新定时的背景视频中屏蔽下脸区域,包括颈部的部分(b),并在顶部呈现具有所需面部表情的新合成下脸。这导致了复合物ri(c)的视频。最后,我们使用我们的神经面部渲染方法来弥合ri和人的真实视频片段之间的领域差距

对于每个对照框架fi(a),我们获得了3D人脸重建。重建的几何代理用于掩盖下面区域(b,左)并渲染口罩mi(b,右),其用于我们的训练重建损失。我们从参数面模型叠加下面区域以获得合成复合ri(c)。我们的表达式引导神经渲染器的目标是学习从合成复合ri到对照真实帧fi的映射。
I.训练神经面部渲染器(Training the Neural Face Renderer)
- 训练面部神经网络(基于GAN)
- 涉及生成器(RNN)
![]()
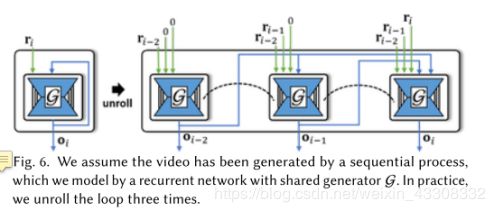
我们假设视频是由顺序过程生成的,我们通过具有共享生成器G的循环网络进行建模。实际上,我们将循环展开三次.
- 鉴别器(D)

我们使用空间鉴别器Ds,时间鉴别器Dt和基于对抗基于patch的鉴别器损失来训练我们的神经面部渲染网络
- 训练目标函数L

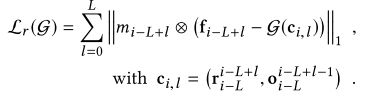
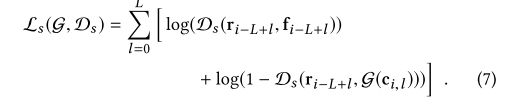
Lr是光度重建损失,Ls是每帧空间对抗性损失,Lt是我们基于差异图像的新颖的对抗性时间一致性损失。
- 网络结构(Network Architecture)
见原文相应的论文
- 添加音频
管道制作的视频是静音的。添加音频方法(1)使用由Mac OS X中的内置语音合成器或VoCo (2)获得表演者声音的实际记录。在这种情况下,我们重新定时生成的视频以匹配电话级别的录制。对于移动和删除编辑,我们使用原始视频中的表演者的声音。
Section 4:Result
针对各种视频展现完整方法的结果,鼓励读者在补充视频和网站中查看视频结果(带音频),结果很难从静态帧中评估。
4.1.视频编辑(Video Editing)
优势:
- 能够将修改后的视频片段无缝重新组合成原始的全帧视频片段,并将新片段无缝地融合到原始(更长)视频中。可以处理任意帧的镜头,并且与输入视频的分辨率和宽高比无关。
- 能够实现本地化编辑(即使用较少的计算),这些编辑不会改变大部分原始视频,并且可以合并到标准编辑管道中。
- 神经面部渲染策略可以在原始背景视频上调节视频生成,从而实现无缝合成。
- 这种方法使我们能够准确地再现身体运动和场景背景(图11)。

其他神经渲染方法,如Deep Video Portraits [Kim et al。 2018b]不对背景进行条件限制,因此不能保证在帧中的正确位置合成主体。
4.2.翻译(Translation)
优势:
- 用于视频翻译,只要源材料包含与目标语言类似的视图。
- viseme搜索管道与语言无关。为了支持新语言,我们只需要一种方法将单词转换为单个音素,这些音素已经可用于许多语言。
4.3.使用合成语音进行全句合成(Full Setence Synthesis Using Synthetic Voice)
优势:
(1)可用于为助理可能制作的任何话语制作视频。我们使用原生Mac OS语音合成(补充W7)显示完整句子合成的结果。
(2)用于轻松创建具有针对不同目标受众的更细粒度内容适应的教学视频,或创建针对特定年龄组定制的讲故事视频的变体。
Section 5:Evaluation analysis and Compare
为了评估我们的方法,我们分析了产生良好结果所需的输入视频数据的内容和大小,并且我们将我们的方法与替代的会话头视频合成技术进行了比较。
5.1输入视频的大小(Size of Input Video)
5.2编辑大小(Size od Edit)
5.3参数空间混合的评估(Evaluation of Parameter Space Blending)
5.4 与MorphCut的比较:

MorphCut在第2,3,4帧的场景删除中失败,本文的方法效果比较好
5.5与面部重演技术的比较(Comparison to Facial Reenactment Techniques)

与面部重演技术相比,新技术避免了画面中出现的“鬼影”,合成画面也更加高清、稳定。
5.6 消融研究(Ablation Study)
5.7 用户研究(User Study)
Section 6:局限性和未来发展
(1)我们的综合方法需要重新定时的背景视频作为输入。
(2)目前我们的音素检索对于说出音素的情绪是不可知的。
(3)我们目前的视觉搜索旨在提高质量而非速度。我们想探索viseme搜索问题的近似解决方案,我们认为这可以允许交互式编辑操作。
(4)我们需要大约1小时的视频才能产生最佳质量的结果。为了使我们的方法更广泛适用,我们正在研究用更少的数据产生更好结果的方法。具体来说,我们正在研究在个体之间传递表达参数的方法,这将允许我们为所有编辑操作使用一个预处理数据集。
(5)下脸区域的遮挡,例如通过移动的手,干扰我们的神经面部渲染器并导致合成伪像,因为手不能可靠地重新渲染。解决这个问题还需要跟踪和合成手部动作。尽管如此,我们相信我们展示了各种引人注目的基于文本的编辑和综合结果。将来,端到端学习可用于学习从文本到视听内容的直接映射。
Section 7:Conclusion
我们提出了第一种方法,通过修改相应的记录,实现了对视频头视频的基于文本的编辑。我们的方法可以进行各种各样的编辑,例如词的添加,删除和更改,以及令人信服的语言翻译和完整的句子合成。是实现基于文本的编辑和一般视听内容合成目标的第一个重要步骤