黑马mybatis框架笔记day03
第三天
1 Mybatis 连接池与事务深入
1.1 Mybatis 的连接池技术
我们在前面的 WEB 课程中也学习过类似的连接池技术,而在 Mybatis 中也有连接池技术,但是它采用的是自己的连接池技术。在 Mybatis 的 SqlMapConfig.xml 配置文件中,通过< dataSource type=”pooled”>来实现 Mybatis 中连接池的配置。
1.1.1 Mybatis 连接池的分类
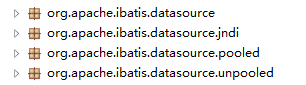
在 Mybatis 中我们将它的数据源 dataSource 分为以下几类:
可以看出 Mybatis 将它自己的数据源分为三类:
UNPOOLED 不使用连接池的数据源
POOLED 使用连接池的数据源
JNDI 使用 JNDI 实现的数据源
具体结构如下:
相应地,MyBatis 内部分别定义了实现了 java.sql.DataSource 接口的 UnpooledDataSource,
PooledDataSource 类来表示 UNPOOLED、POOLED 类型的数据源。
在这三种数据源中,我们一般采用的是 POOLED 数据源(很多时候我们所说的数据源就是为了更好的管理数据
库连接,也就是我们所说的连接池技术)。


1.1.2 Mybatis 中数据源的配置
我们的数据源配置就是在 SqlMapConfig.xml 文件中,具体配置如下:
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
dataSource>
MyBatis 在初始化时,根据<dataSource>的 type 属性来创建相应类型的的数据源 DataSource,即:
type=”POOLED”:MyBatis 会创建 PooledDataSource 实例
type=”UNPOOLED” : MyBatis 会创建 UnpooledDataSource 实例
type=”JNDI”:MyBatis 会从 JNDI 服务上查找 DataSource 实例,然后返回使用
1.1.3 Mybatis 中 DataSource 的存取
MyBatis 是 通 过 工 厂 模 式 来 创 建 数 据 源 DataSource 对 象 的 , MyBatis 定 义 了 抽 象 的 工 厂 接口:org.apache.ibatis.datasource.DataSourceFactory,通过其 getDataSource()方法返回数据源DataSource。
当我们需要创建 SqlSession 对象并需要执行 SQL 语句时,这时候 MyBatis 才会去调用 dataSource 对象来创建java.sql.Connection对象。也就是说,java.sql.Connection对象的创建一直延迟到执行SQL语句
的时候。
1.2 Mybatis 的事务控制
1.2.1 JDBC 中事务的回顾
在 JDBC 中我们可以通过手动方式将事务的提交改为手动方式,通过 setAutoCommit()方法就可以调整。
Mybatis 框架因为是对 JDBC 的封装,所以 Mybatis 框架的事务控制方式,本身也是用 JDBC 的setAutoCommit()方法来设置事务提交方式的。
1.2.2 Mybatis 中事务提交方式
Mybatis 中事务的提交方式,本质上就是调用 JDBC 的 setAutoCommit()来实现事务控制。
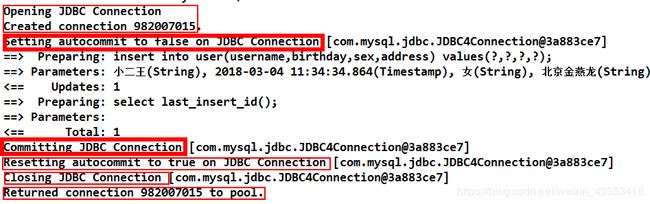
这是我们的 Connection 的整个变化过程,通过分析我们能够发现之前的 CUD 操作过程中,我们都要手动进
行事务的提交,原因是 setAutoCommit()方法,在执行时它的值被设置为 false 了,所以我们在 CUD 操作中,
必须通过 sqlSession.commit()方法来执行提交操作。
1.2.3 Mybatis 自动提交事务的设置
通过上面的研究和分析,为什么 CUD 过程中必须使用 sqlSession.commit()提交事务?主要原因就是在连接池中取出的连接,都会将调用 connection.setAutoCommit(false)方法,这样我们就必须使用 sqlSession.commit()方法,相当于使用了 JDBC 中的 connection.commit()方法实现事务提交。
明白这一点后,我们现在一起尝试不进行手动提交,一样实现 CUD 操作。
//4.创建 SqlSession 对象
session = factory.openSession(true);
此时事务就设置为自动提交了,同样可以实现CUD操作时记录的保存。虽然这也是一种方式,但就编程而言,设置为自动提交方式为 false 再根据情况决定是否进行提交,这种方式更常用。因为我们可以根据业务情况来决定提交是否进行提交。
2 Mybatis 的动态 SQL 语句
Mybatis 的映射文件中,前面我们的 SQL 都是比较简单的,有些时候业务逻辑复杂时,我们的 SQL 是动态变化的,此时在前面的学习中我们的 SQL 就不能满足要求了。
2.1 动态 SQL 之< if >标签
我们根据实体类的不同取值,使用不同的 SQL 语句来进行查询。比如在 id 如果不为空时可以根据 id 查询,如果 username 不同空时还要加入用户名作为条件。这种情况在我们的多条件组合查询中经常会碰到。
2.1.1 持久层 Dao 接口
/**
* 根据用户信息,查询用户列表
* @param user
* @return
*/
List<User> findByUser(User user);
2.1.2 持久层 Dao 映射配置
<select id="findByUser" resultType="user" parameterType="user">
select * from user where 1=1
<if test="username!=null and username != '' ">
and username like #{username}
if>
<if test="address != null">
and address like #{address}
if>
select>
注意:<if>标签的 test 属性中写的是对象的属性名,如果是包装类的对象要使用 OGNL 表达式的写法。
另外要注意 where 1=1 的作用~!
2.2 动态 SQL 之< where >标签
为了简化上面 where 1=1 的条件拼装,我们可以采用标签来简化开发。
2.2.1 持久层 Dao 映射配置
<select id="findByUser" resultType="user" parameterType="user">
<include refid="defaultSql">include>
<where>
<if test="username!=null and username != '' ">
and username like #{username}
if>
<if test="address != null">
and address like #{address}
if>
where>
select>
2.3 动态标签之标签
2.3.1 需求
传入多个 id 查询用户信息,用下边两个 sql 实现:
SELECT * FROM USERS WHERE username LIKE ‘%张%’ AND (id =10 OR id =89 OR id=16)
SELECT * FROM USERS WHERE username LIKE ‘%张%’ AND id IN (10,89,16)
这样我们在进行范围查询时,就要将一个集合中的值,作为参数动态添加进来。
这样我们将如何进行参数的传递?
2.3.1.1 在 QueryVo 中加入一个 List 集合用于封装参数
/**
*
* Title: QueryVo
* Description: 查询的条件
* Company: http://www.itheima.com/
*/
public class QueryVo implements Serializable {
private List<Integer> ids;
public List<Integer> getIds() {
return ids;
}
public void setIds(List<Integer> ids) {
this.ids = ids;
}
}
2.3.2 持久层 Dao 接口
/**
* 根据 id 集合查询用户
* @param vo
* @return
*/
List<User> findInIds(QueryVo vo);
2.3.3 持久层 Dao 映射配置
<select id="findInIds" resultType="user" parameterType="queryvo">
<include refid="defaultSql">include>
<where>
<if test="ids != null and ids.size() > 0">
<foreach collection="ids" open="id in ( " close=")" item="uid" separator=",">
#{uid}
foreach>
if>
where>
select>
SQL 语句:
select 字段 from user where id in (?)
<foreach>标签用于遍历集合,它的属性:
collection:代表要遍历的集合元素,注意编写时不要写#{}
open:代表语句的开始部分
close:代表结束部分
item:代表遍历集合的每个元素,生成的变量名
sperator:代表分隔符
2.4 Mybatis 中简化编写的 SQL 片段
Sql 中可将重复的 sql 提取出来,使用时用 include 引用即可,最终达到 sql 重用的目的。
2.4.1 定义代码片段
<sql id="defaultSql">
select * from user
sql>
2.4.2 引用代码片段
<select id="findAll" resultType="user">
<include refid="defaultSql">include>
select>
<select id="findById" resultType="UsEr" parameterType="int">
<include refid="defaultSql">include>
where id = #{uid}
select>
3 Mybatis 多表查询之一对多
表之间的关系有几种:
一对多
多对一
一对一
多对多
举例:
用户和订单就是一对多
订单和用户就是多对一
一个用户可以下多个订单
多个订单属于同一个用户
人和身份证号就是一对一
一个人只能有一个身份证号
一个身份证号只能属于一个人
老师和学生之间就是多对多
一个学生可以被多个老师教过
一个老师可以交多个学生
特例:
如果拿出每一个订单,他都只能属于一个用户。
所以Mybatis就把多对一看成了一对一。
3.1 一对一查询(多对一)
需求
查询所有账户信息,关联查询下单用户信息。
注意:
因为一个账户信息只能供某个用户使用,所以从查询账户信息出发关联查询用户信息为一对一查询。如果从用户信息
出发查询用户下的账户信息则为一对多查询,因为一个用户可以有多个账户。
3.1.1 方式一
3.1.1.1 定义账户信息的实体类
/**
* Title: Account
* Description: 账户的实体类
* Company: http://www.itheima.com/
*/
public class Account implements Serializable {
private Integer id;
private Integer uid;
private Double money;
...//省略getter/setter/tostring
}
3.1.1.2 编写 Sql 语句
实现查询账户信息时,也要查询账户所对应的用户信息。
SELECT
account.*,
user.username,
user.address
FROM
account,
user
WHERE account.uid = user.id
3.1.1.3 定义 AccountUser 类
为了能够封装上面SQL语句查询结果,定义了AccountCustomer类中要包含账户信息同时还要包含用户信息,所以我们要在定义AccountUser类是可以继承User类。
/**
*
* Title: AccountUser
* Description: 它是 account 的子类
* Company: http://www.itheima.com/
*/
public class AccountUser extends Account implements Serializable {
private String username;
private String address;
...getter/setter
@Override
public String toString() {
return super.toString() + " AccountUser [username=" + username + ",
address=" + address + "]";
}
}
3.1.1.4 定义账户的持久层 Dao 接口
/**
*
* Title: IAccountDao
* Description: 账户的持久层接口
* Company: http://www.itheima.com/
*/
public interface IAccountDao {
/**
* 查询所有账户,同时获取账户的所属用户名称以及它的地址信息
* @return
*/
List<AccountUser> findAll();
}
3.1.1.5 定义 AccountDao.xml 文件中的查询配置信息
<mapper namespace="com.itheima.dao.IAccountDao">
<select id="findAll" resultType="accountuser">
select a.*,u.username,u.address from account a,user u where a.uid =u.id;
select>
mapper>
注意:因为上面查询的结果中包含了账户信息同时还包含了用户信息,所以我们的返回值类型 returnType
的值设置为 AccountUser 类型,这样就可以接收账户信息和用户信息了。
小结:定义专门的 pojo 类作为输出类型,其中定义了 sql 查询结果集所有的字段。此方法较为简单,企业中使用普遍。
3.1.2 方式二
使用 resultMap,定义专门的 resultMap 用于映射一对一查询结果。通过面向对象的(has a)关系可以得知,我们可以在 Account 类中加入一个 User 类的对象来代表这个账户是哪个用户的。
3.1.2.1 修改 Account 类
在 Account 类中加入 User 类的对象作为 Account 类的一个属性。
/**
*
* Title: Account
* Description: 账户的实体类
* Company: http://www.itheima.com/
*/
public class Account implements Serializable {
private Integer id;
private Integer uid;
private Double money;
private User user;
...getter/setter/tostring
}
3.1.2.2 修改 AccountDao 接口中的方法
/**
*
* Title: IAccountDao
* Description: 账户的持久层接口
* Company: http://www.itheima.com/
*/
public interface IAccountDao {
/**
* 查询所有账户,同时获取账户的所属用户名称以及它的地址信息
* @return
*/
List<Account> findAll();
}
注意:第二种方式,将返回值改 为了 Account 类型。
因为 Account 类中包含了一个 User 类的对象,它可以封装账户所对应的用户信息。
3.1.2.3 重新定义 AccountDao.xml 文件
<mapper namespace="com.itheima.dao.IAccountDao">
<resultMap type="account" id="accountMap">
<id column="aid" property="id"/>
<result column="uid" property="uid"/>
<result column="money" property="money"/>
<association property="user" javaType="user">
<id column="id" property="id"/>
<result column="username" property="username"/>
<result column="sex" property="sex"/>
<result column="birthday" property="birthday"/>
<result column="address" property="address"/>
association>
resultMap>
<select id="findAll" resultMap="accountMap">
select u.*,a.id as aid,a.uid,a.money from account a,user u where a.uid =u.id;
select>
mapper>
3.2 一对多查询
需求:
查询所有用户信息及用户关联的账户信息。
分析:
用户信息和他的账户信息为一对多关系,并且查询过程中如果用户没有账户信息,此时也要将用户信息查询出来,我
们想到了左外连接查询比较合适。
3.2.1 编写 SQL 语句
SELECT
u.*, acc.id id,
acc.uid,
acc.money
FROM
user u
LEFT JOIN account acc ON u.id = acc.uid
3.2.2 User 类加入 List< Account >
/**
*
* Title: User
* Description: 用户的实体类
* Company: http://www.itheima.com/
*/
public class User implements Serializable {
private Integer id;
private String username;
private Date birthday;
private String sex;
private String address;
private List<Account> accounts;
//...getter/setter/tostring
}
3.2.4 用户持久层 Dao 映射文件配置
<mapper namespace="com.itheima.dao.IUserDao">
<resultMap type="user" id="userMap">
<id column="id" property="id"/>
<result column="username" property="username"/>
<result column="address" property="address"/>
<result column="sex" property="sex"/>
<result column="birthday" property="birthday"/>
<collection property="accounts" ofType="account">
<id column="aid" property="id"/>
<result column="uid" property="uid"/>
<result column="money" property="money"/>
collection>
resultMap>
<select id="findAll" resultMap="userMap">
select u.*,a.id as aid ,a.uid,a.money from user u left outer join account a on u.id =a.uid
select>
mapper>
collection
部分定义了用户关联的账户信息。表示关联查询结果集
property="accList":
关联查询的结果集存储在 User 对象的上哪个属性。
ofType="account":
指定关联查询的结果集中的对象类型即List中的对象类型。此处可以使用别名,也可以使用全限定名。
4 Mybatis 多表查询之多对多
mybatis中的多表查询:
示例:用户和账户
一个用户可以有多个账户
一个账户只能属于一个用户(多个账户也可以属于同一个用户)
步骤:
1、建立两张表:用户表,账户表
让用户表和账户表之间具备一对多的关系:需要使用外键在账户表中添加
2、建立两个实体类:用户实体类和账户实体类
让用户和账户的实体类能体现出来一对多的关系
3、建立两个配置文件
用户的配置文件
账户的配置文件
4、实现配置:
当我们查询用户时,可以同时得到用户下所包含的账户信息
当我们查询账户时,可以同时得到账户的所属用户信息
示例:用户和角色
一个用户可以有多个角色
一个角色可以赋予多个用户
步骤:
1、建立两张表:用户表,角色表
让用户表和角色表具有多对多的关系。需要使用中间表,中间表中包含各自的主键,在中间表中是外键。
2、建立两个实体类:用户实体类和角色实体类
让用户和角色的实体类能体现出来多对多的关系
各自包含对方一个集合引用
3、建立两个配置文件
用户的配置文件
角色的配置文件
4、实现配置:
当我们查询用户时,可以同时得到用户所包含的角色信息
当我们查询角色时,可以同时得到角色的所赋予的用户信息
4.1 实现 Role 到 User 多对多
通过前面的学习,我们使用 Mybatis 实现一对多关系的维护。多对多关系其实我们看成是双向的一对多关系。
4.1.1 用户与角色的关系模型

4.1.2 业务要求及实现 SQL
需求:
实现查询所有对象并且加载它所分配的用户信息。
分析:
查询角色我们需要用到Role表,但角色分配的用户的信息我们并不能直接找到用户信息,而是要通过中间表
(USER_ROLE 表)才能关联到用户信息。
下面是实现的 SQL 语句:
SELECT
r.*,u.id uid,
u.username username,
u.birthday birthday,
u.sex sex,
u.address address
FROM
ROLE r
INNER JOIN
USER_ROLE ur
ON ( r.id = ur.rid)
INNER JOIN
USER u
ON (ur.uid = u.id);
4.1.3 编写Role实体类
/**
* @author 黑马程序员
* @Company http://www.ithiema.com
*/
public class Role implements Serializable {
private Integer roleId;
private String roleName;
private String roleDesc;
//多对多的关系映射:一个角色可以赋予多个用户
private List<User> users;
//...getter/setter/tostring
}
4.1.4 编写 Role 持久层接口
/**
* @author 黑马程序员
* @Company http://www.ithiema.com
*/
public interface IRoleDao {
/**
* 查询所有角色
* @return
*/
List<Role> findAll();
}
4.1.5 编写映射文件
<mapper namespace="com.itheima.dao.IRoleDao">
<resultMap id="roleMap" type="role">
<id property="roleId" column="rid">id>
<result property="roleName" column="role_name">result>
<result property="roleDesc" column="role_desc">result>
<collection property="users" ofType="user">
<id column="id" property="id">id>
<result column="username" property="username">result>
<result column="address" property="address">result>
<result column="sex" property="sex">result>
<result column="birthday" property="birthday">result>
collection>
resultMap>
<select id="findAll" resultMap="roleMap">
select u.*,r.id as rid,r.role_name,r.role_desc from role r
left outer join user_role ur on r.id = ur.rid
left outer join user u on u.id = ur.uid
select>
mapper>
4.2 实现 User 到 Role 的多对多
4.2.1 User 到 Role 的多对多
从 User 出发,我们也可以发现一个用户可以具有多个角色,这样用户到角色的关系也还是一对多关系。这样我们就可以认为 User 与 Role 的多对多关系,可以被拆解成两个一对多关系来实现。