网页搜索引擎中的核心索引结构 - 利用 Google Protobuf 构建
索引结构 — Index
利用 Google Protobuf 构建索引结构 —– Index
在搜索引擎中,常见的索引方法就是正排索引和倒排索引,因此我们 Index 索引结构要包括两两个方面:
正排索引 — ( forward_index )
倒排索引 — ( inverted_index )
正排索引
正排索引是根据文件的id号,得到所有的文件信息,因此正排索引中存放的是整个文件的所有文件信息,包括文件的内容及其他的id号,这里以网页索引为例子:
正排索引中一个结点,应该包含的基本信息有:
id: 网页id号title: 网页标题content: 网页内容jump_url: 网页跳转urlshow_url: 网页显示url
除了上面的内容,正排索引中还应该给出文件标题和正文中都包含有哪些关键字,这样方便我们构建倒排索引。
因此,还应该加上:
title_token:网页标题中的关键字content_token: 网页正文中的关键字
正排索引是由一个个包含的文件信息的结点构成的数组形式的结构,而这个结点包含以上7个数据,我们将这个信息结点起名叫doc_info。
后面添加的两个类型,因为一个文件中不可能只包含一个关键词,因此title_token和content_token应该是字符串类型的数组,这里我们可以优化一下,如果我们存放的是字符串,相当于存入了整个文件(网站),不仅占内存而且不方便查询,因此我们可以考虑存放该关键字在正文或者标题中出现的位置,记录其初始位置和结束的位置,规定为左闭右开的形式。由于我们在正排索引中已经存放了网站的标题与正文,那我们在使用时就可以根据关键字的位置得到关键字。因此这两个数组,存放的数据类型是二元数,记录了关键字的位置。
如上所述:我们队正排索引的机构有了大致的了解:一个存放文件信息(doc_info)的数组(forward_index),且文件id可以当做数组的下标。
用protobuf构建的话,正排索引forward_index应该是doc_info类型的repeated(可重复类型)数据。
倒排索引
倒排索引(inverted_index),是根据给定的关键字得到相应的文件id,然后我们在根据文件id(就是正排索引中数组的下标)得到整个文件的信息。
一个倒排索引要包含的信息(信息结点的类型名定义为:Kwdinfo):
key:关键字doc_list: 文件列表
同一个关键字,有可能存在不同的文件中,因此这里的doc_list也是数组的形式,而且每个关键字对应文件的重要性也不相同,相同的关键字对应不同的文件应有不同的权重,这样也利于我们进行排序,权重我们可以根据该关键字在该文件中的出现次数算得到。这样doc_list也就不是简单的整形数组了,存放的应是文件id及其权重的集合我们称这个结构为DocList,doc_list这个数组存放的类型结构Doclist 如下:
doc_id: 文件idweight: 权重first_pos: 关键字第一次出现的位置
这个doc_list,我们称之为倒排拉链,即一个关键字对应一个倒排拉链,由于我们要通过关键字找对应的倒排拉链,因此倒排索引invented_index我们一般定义为map结构,方便查找
这个map结构的key是关键字,而val是倒排拉链
而在proto中的定义为:invented_index是Kwdinfo + repeated类型的,表示该数据个数是可变的;doc_list这个数据的类型为Doclist + repeated。
整体结构
index索引结构
//索引结构
massage Index
{
//正排索引
repeated Docinfo forward_index = 1;
//倒排索引
repeated Kwdinfo inderted_index = 2;
}正排索引结点结构
massage Docinfo
{
// 一个文档对应的信息
required uint64 id = 1;
required string title = 2;
required string content = 3;
required string show_url = 4;
required string jump_url = 5;
// 以下两个字段, 把标题和正文的分词结果先罗列好,
// 以备后面实现倒排的时候使用
repeated Pair title_token = 6;
repeated Pair content_token = 7;
}//`pair` 结构用来存放文件的关键字信息
massage pair
{
required uint32 beg = 1;
required uint32 end = 2;
}倒排索引结点结构
massage Kwdinfo
{
required string key = 1;
repeated Doclist doc_list = 2;
}//Doclist 倒排拉链
massage Doclist
{
required uint64 doc_id = 1;
required int32 weight = 2;
required int32 first_pos = 3;
}结构图:
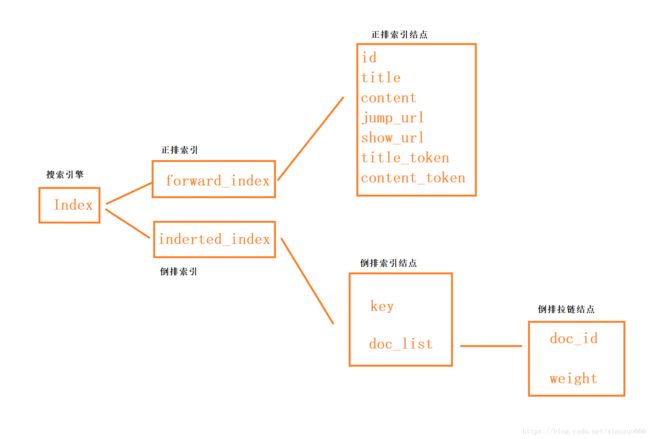
整个索引结构如上,整体分为两个大的模块,正排和倒排