Redis概述
简介
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
Redis是一个速度非常快的非关系型(NoSQL)内存键值数据库,可以存储键和5种不同类型的值之间的映射。
键的类型只能为字符串,值支持5种数据类型:字符串、列表、集合、散列表、有序集合。
Redis支持很多特性,例如将内存中的数据持久化到硬盘中,使用复制来扩展读性能,使用分片来扩展写性能。
Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
特性:
1.速度快
2.支持数据持久化
3.五种数据类型
4.支持多种编程语言
5.功能丰富
6.简单
7.主从复制模式的数据备份
8.高可用,分布式
9.数据分区
应用场景:
缓存系统
任务队列
分布式锁
应用排行榜
网站访问统计
数据过期处理
分布式集群架构中的session分离
键
Redis键的类型为字符串类型,key支持的操作有添加、删除、设置过期时间、清除过期时间、更新过期时间、重命名、序列化、
当newkey不存在时添加key等操作。
> set hello world
OK
> get hello
"world"
> del hello
(integer) 1
> get hello
(nil)
set key value [EX seconds] [PX ms] [nx|xx]
key: 键名
value: 键值
ex seconds: 键秒级过期时间
px ms: 键毫秒级过期时间
nx: 键不存在才能设置,setnx和nx选项作用一样,用于添加分布式锁的实现
xx: 键存在才能设置,setxx和xx选项作用一样,用于更新,安全性更高
键过期
Keys的过期时间
通常Redis keys创建时没有设置相关过期时间。他们会一直存在,除非使用显示的命令移除,例如,使用DEL命令。
EXPIRE一类命令能关联到一个有额外内存开销的key。当key执行过期操作时,Redis会确保按照规定时间删除他们。
key的过期时间和永久有效性可以通过EXPIRE和PERSIST命令(或者其他相关命令)来进行更新或者删除过期时间。
过期和持久
Keys的过期时间使用Unix时间戳存储(从Redis 2.6开始以毫秒为单位)。这意味着即使Redis实例不可用,时间也是一直在流逝的。
要想过期的工作处理好,计算机必须采用稳定的时间。 如果你将RDB文件在两台时钟不同步的电脑间同步,有趣的事会发生(所有的 keys装载时就会过期)。
即使正在运行的实例也会检查计算机的时钟,例如如果你设置了一个key的有效期是1000秒,然后设置你的计算机时间为未来2000秒,这时key会立即失效,而不是等1000秒之后。
Redis如何淘汰过期的keys
Redis keys过期有两种方式:被动和主动方式。
当一些客户端尝试访问它时,key会被发现并主动的过期。
当然,这样是不够的,因为有些过期的keys,永远不会访问他们。 无论如何,这些keys应该过期,所以定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
具体就是Redis每秒10次做的事情:
- 测试随机的20个keys进行相关过期检测。
- 删除所有已经过期的keys。
- 如果有多于25%的keys过期,重复步奏1.
这是一个平凡的概率算法,基本上的假设是,我们的样本是这个密钥控件,并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys。
在复制AOF文件时如何处理过期
为了获得正确的行为而不牺牲一致性,当一个key过期,DEL将会随着AOF文字一起合成到所有附加的slaves。在master实例中,这种方法是集中的,并且不存在一致性错误的机会。
然而,当slaves连接到master时,不会独立过期keys(会等到master执行DEL命令),他们任然会在数据集里面存在,所以当slave当选为master时淘汰keys会独立执行,然后成为master。
数据类型
| 类型 |
简介 |
特性 |
场景 |
| String(字符串) |
二进制安全 |
可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M |
--- |
| Hash(字典) |
键值对集合,即编程语言中的Map类型 |
适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) |
存储、读取、修改用户属性 |
| List(列表) |
链表(双向链表) |
增删快,提供了操作某一段元素的API |
1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) |
哈希表实现,元素不重复 |
1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 |
1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) |
将Set中的元素增加一个权重参数score,元素按score有序排列 |
数据插入集合时,已经进行天然排序 |
1、排行榜 2、带权重的消息队列 |
1)string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。
2)Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
每个 hash 可以存储 232 -1 键值对(40多亿)。
3)Redis 列表是简单的字符串列表,按照插入顺序排序。列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)
4)Redis的Set是string类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。集合中最大的成员数为 232 - 1
sadd 命令
添加一个 string 元素到 key 对应的 set 集合中,成功返回1,如果元素已经在集合中返回 0,如果 key 对应的 set 不存在则返回错误。可利用此特性进行爬虫的URL去重。
5)Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
事务
一个事务包含了多个命令,服务器在执行事务期间,不会改去执行其它客户端的命令请求。
事务中的多个命令被一次性发送给服务器,而不是一条一条发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
Redis 最简单的事务实现方式是使用 MULTI 和 EXEC 命令将事务操作包围起来。
redis 127.0.0.1:7000> multi
OK
redis 127.0.0.1:7000> set a aaa
QUEUED
redis 127.0.0.1:7000> set b bbb
QUEUED
redis 127.0.0.1:7000> set c ccc
QUEUED
redis 127.0.0.1:7000> exec
1) OK
2) OK
3) OK
内存淘汰策略(可进行缓存配置)
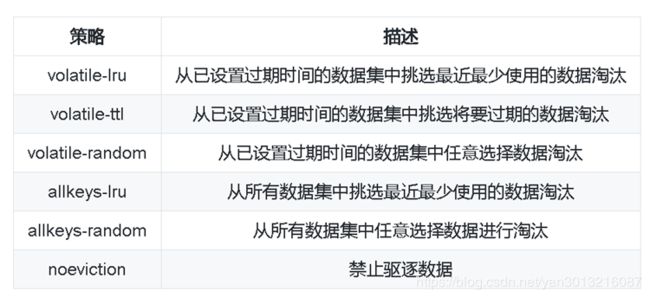
maxmemory配置指令用于配置Redis存储数据时指定限制的内存大小。
设置maxmemory为0代表没有内存限制。对于64位的系统这是个默认值,对于32位的系统默认内存限制为3GB。当指定的内存限制大小达到时,需要选择不同的行为,也就是策略。
一般的经验规则:
- 使用allkeys-lru策略:当你希望你的请求符合一个幂定律分布,也就是说,你希望部分的子集元素将比其它其它元素被访问的更多。如果你不确定选择什么,这是个很好的选择。.
- 使用allkeys-random:如果你是循环访问,所有的键被连续的扫描,或者你希望请求分布正常(所有元素被访问的概率都差不多)。
- 使用volatile-ttl:如果你想要通过创建缓存对象时设置TTL值,来决定哪些对象应该被过期。
数据持久化
Redis是内存型数据库,为了保证数据在断电后不会丢失,需要将内存中的数据持久化到硬盘上。
RDB持久化(保存数据快照)
将某个时间点的所有数据都存到硬盘上
可以将快照复制到其他服务器从而创建具有相同数据的服务器副本
如果系统发生故障,将会丢失最后一次创建快照之后的数据
如果数据量很大,保存快照的时间会很长
bgsave或者save
AOF持久化(保存操作日志)
写命令添加到AOF文件(Append only file)的末尾
使用AOF持久化需要设置同步项,从而确保写命令什么时候会同步到磁盘文件上。这是因为对文件进行写入并不会
马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。有以下同步选项:

>always 选项会严重减低服务器的性能;
>everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,
并且 Redis 每秒执行一次同步对服务器性能几乎没有任何影响;
>no 选项并不能给服务器性能带来多大的提升,而且也会增加系统崩溃时数
据丢失的数量。
主从复制
通过使用 slaveof host port 命令来让一个服务器成为另一个服务器的从服务器。
客户端每次向主服务器进行写入时,从服务器都会实时地得到更新。在部署好主从服务器之后,客户端就可以向任意一个从服务器发送读请求了,而不必再像之前一样,总是把每个读请求都发送给主服务器。
一个从服务器只能有一个主服务器,并且不支持主主复制。
连接过程
1.主服务器创建快照文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,
开始向从服务器发送存储在缓冲区中的写命令;
2.从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令;
3.主服务器每执行一次写命令,就向从服务器发送相同的写命令。
多数据库
Redis支持多个数据库,并且每个数据库的数据是隔离的不能共享,并且基于单机才有,如果是集群就没有数据库的概念。
Redis是一个字典结构的存储服务器,而实际上一个Redis实例提供了多个用来存储数据的字典,客户端可以指定将数据存储在哪个字典中。这与我们熟知的在一个关系数据库实例中可以创建多个数据库类似,所以可以将其中的每个字典都理解成一个独立的数据库。
每个数据库对外都是一个从0开始的递增数字命名,Redis默认支持16个数据库(可以通过配置文件支持更多,无上限),可以通过配置databases来修改这一数字。客户端与Redis建立连接后会自动选择0号数据库,不过可以随时使用SELECT命令更换数据库,如要选择1号数据库:
redis> SELECT 1
OK
redis [1] > GET foo
(nil)
然而这些以数字命名的数据库又与我们理解的数据库有所区别。首先Redis不支持自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。另外Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么连一个数据库也没有权限访问。最重要的一点是多个数据库之间并不是完全隔离的,比如FLUSHALL命令可以清空一个Redis实例中所有数据库中的数据。
综上所述,这些数据库更像是一种命名空间,而不适宜存储不同应用程序的数据。比如可以使用0号数据库存储某个应用生产环境中的数据,使用1号数据库存储测试环境中的数据,但不适宜使用0号数据库存储A应用的数据而使用1号数据库B应用的数据,不同的应用应该使用不同的Redis实例存储数据。由于Redis非常轻量级,一个空Redis实例占用的内在只有1M左右,所以不用担心多个Redis实例会额外占用很多内存。