【Oracle】一条SQL的一生
一,基础概念
1,Oracle内存结构
oracle内存结构由两部分组成SGA(系统全局区)和PGA(用户全局区)组成
1.1, SGA(System Global Area)系统全局区
这是一个非常庞大的内存区间,也是为什么开启oracle之后占用了很大内存的原因。这块区域由所有服务进程和后台进程共享; SGA分为不同的池,我们可以通过视图v$sgastat查看
select pool ,sum(bytes) bytes from v$sgastat group by pool;
SQL执行过程中最主要的pool是
共享缓冲区(shared pool):缓存了各用户间可共享的各种结构。
数据库缓冲区缓存(database buffer cache):缓存了从磁盘上检索的数据块。
重做日志缓冲区(redo log buffer):缓存了写到磁盘之前的重做信息。
SGA详细内容参考:https://blog.csdn.net/paopaopotter/article/details/79217539
1.2,PGA(Program Global Area) 用户全局区
当用户(客户端)要连接Oracle数据库时, Oracle就会创建1个session(会话),并且在服务器上创建1个专门处理这个session的进程,就是服务进程。每个服务进程私有的内存区域——PGA,其包含如下结构:
1)Private SQL area:包含绑定信息、运行时的内存结构。每个发出sql语句的会话,都有一个private SQL area(私有SQL区)。
2)Session memory:为保存会话中的变量以及其他与会话相关的信息,而分配的内存区。
2,Oracle数据库文件
Oracle数据库文件主要有以下三类
2.1,数据文件(data files)
每一个Oracle数据库有一个或多个物理的数据文件(data file),数据文件包含全部数据库数据,逻辑数据库结构(如表、索引、视图、函数)的数据物理地存储在数据文件中。数据文件中的数据在需要时可以读取并存储在数据库缓冲区缓存中。如用户要存取数据库一表的某些数据,如果请求数据不在数据库缓冲区缓存内,则从相应的数据文件中读取并存储在数据库缓冲区缓存内,当修改或插入新数据时,为了减少磁盘输出的总数,提高性能,不必立刻写入数据文件,修改的数据先存储在数据库缓冲区缓存,然后由Oracle后台进程DBWRn(负责将数据库缓冲区缓存里被修改的数据写入磁盘的数据文件)决定如何将其写入到相应的数据文件。
2.2,日志文件(Redo Log Files)
每一个数据库实例有两组或以上日志文件组,为了防止日志文件本身的故障,每个日志文件组可以有一个或以上日志成员。日志的主要功能是记录对数据所作的修改,用于在出现故障时,如果不能将修改数据永久地写入数据文件,则可利用日志得到该修改,从而保证数据不丢失。当在数据库缓冲区缓存修改数据时,会产生一定量的日志数据,这些日志数据不会直接就写到日志文件中,而是实时存放在重做日志缓冲区,然后由Oracle后台进程LGWR(负责将重做日志缓冲区的内容写入到磁盘的日志文件中)决定如何将其写入到相应的日志文件。
2.3,控制文件(Control files)
每一Oracle数据库有一个控制文件(Control File)或同一个控制文件的多个拷贝,它记录数据库的物理结构信息,包括数据库名、数据库数据文件和日志文件的名字和位置、数据库建立日期等。 由于控制文件记录数据库的物理结构信息,对数据库运行至关重要,为了安全起见,Oracle建议保存两份以上的控制文件镜像于不同的存储设备。
3,物理读和逻辑读
所谓逻辑读,就是从缓存(一般是内存)里读取数据,而物理读,也就是从磁盘(数据文件)里读取数据。
二,一条SQL的一生
(一)客户端发送SQL语句

当我们在客户端执行SQL语句时,客户端会把这条SQL语句发送给服务器端,让服务器端的进程来处理这语句。也就是说,Oracle 客户端是不会做任何的操作,他的主要任务就是把客户端产生的一些SQL语句发送给服务器端。服务器进程从用户进程把信息接收到后, 在PGA 中就要此进程分配所需内存,存储相关的信息。
(二)SQL语句解析
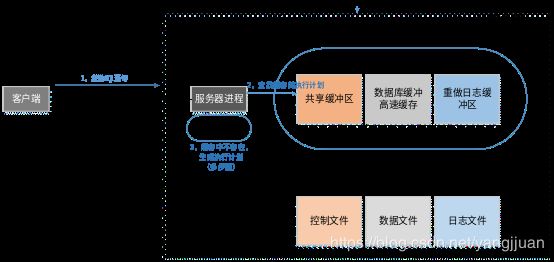
当客户端把SQL语句传送到服务器后,服务器进程会对改语句进行解析。同理,这个解析的工作,也是在服务器端进行的。虽然这只是一个解析的动作,但是,其中包含多个步骤。
1,查询共享缓冲区中的库缓存(library cache)
服务器进程在接到客户端传送过来的SQL语句时,不会直接去数据库查询,服务器进程将到库缓存中的库缓存中去查找是否存在相同语句的执行计划。如果存在,服务器进程将使用这条语句已缓存在共享缓冲区中的库缓存中的已分析好的执行计划来执行,省去后续的解析工作,这便是软解析。若缓存中不存在,则需要进行后面的步骤,这便是硬解析。硬解析通常是昂贵的操作。
2,语句合法性检查
当在库缓存中找不到对应的SQL语句时,则服务器进程就会开始检查这条语句的合法性。这里主要是对SQL语句的语法进行检查,看看其是否合乎语法规则。如果服务器进程认为这条SQL语句不符合语法规则的时候,就会把这个错误信息反馈给客户端。在这个语法检查的过程中,不会对SQL语句中所包含的表名、列名等等进行检查,只是检查语法。
3,语言含义检查
若SQL 语句符合语法上的定义的话,则服务器进程接下去会对语句中涉及的表、索引、视图等对象进行解析,并对照数据字典检查这些对象的名称以及相关结构,看看这些字段、表、视图等是否在数据库中。如果表名与列名不准确的话,则数据库会就会反馈错误信息给客户端。所以,有时候我们写select语句的时候,若语法与表名或者列名同时写错的话,则系统是先提示说语法错误,等到语法完全正确后再提示说列名或表名错误。
4,获得对象解析锁
当语法、语义都正确后,系统就会对我们需要查询的对象加锁。这主要是为了保障数据的一致性,防止我们在查询的过程中,其他用户对这个对象的结构发生改变。
5,数据访问权限的核对
当语法、语义通过检查之后,客户端还不一定能够取得数据,服务器进程还会检查连接用户是否有这个数据访问的权限。若用户不具有数据访问权限的话,则客户端就不能够取得这些数据。要注意的是数据库服务器进程先检查语法与语义,然后才会检查访问权限。
6,确定最佳执行计划
当语句与语法都没有问题,权限也匹配的话,服务器进程还是不会直接对数据库文件进行查询。服务器进程会根据一定的规则,对这条语句进行优化。不过要注意,这个优化是有限的。一般在SQL开发的过程中,需要对数据库的SQL语言进行优化,这个优化的作用优于服务器进程的自我优化。所以,编写完SQL后需要进行优化。当服务器进程的优化器确定这条查询语句的最佳执行计划后,就会将这条SQL语句与执行计划保存到共享缓冲区的库缓存。如此的话,等以后还有这个查询时,就会省略以上的语法、语义与权限检查的步骤,直接执行SQL语句,提高SQL语句处理效率。
(三)绑定变量赋值
如果SQL语句中使用了绑定变量,扫描绑定变量的声明,给绑定变量赋值,将变量值带入执行计划。
(四)语句执行
语句解析只是对SQL语句的语法进行解析,以确保服务器能够知道这条语句到底表达的是什么意思。等到语句解析完成之后,数据库服务器进程才会真正的执行这条SQL语句。最常用的就是DML操作,对应的执行过程也有所不同。
1,select操作
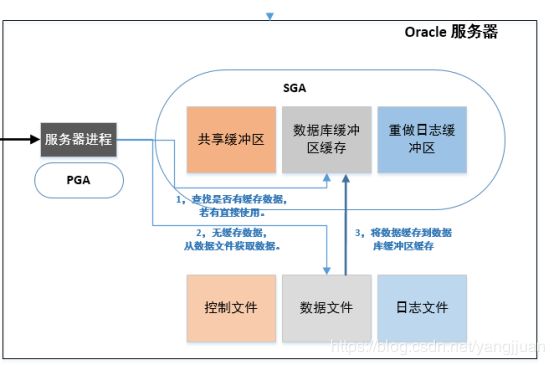
1.1,服务器进程先到数据库缓冲区缓存里找有没有现成的数据. 如果有最好, 如果无或者缓存中数据不全的话就只能去访问数据文件,因为数据文件存在于物理磁盘中,物理读写会耗费IO,降低查询效率。
1.2,若在缓存中没找到对应的数据,只能从数据文件获得数据。
1.3,得到数据后也不是直接发给用客户端,而是将数据缓存到数据库缓冲区缓存里面, 以便当前或其他用户二次使用。
2,update,insert,delete操作
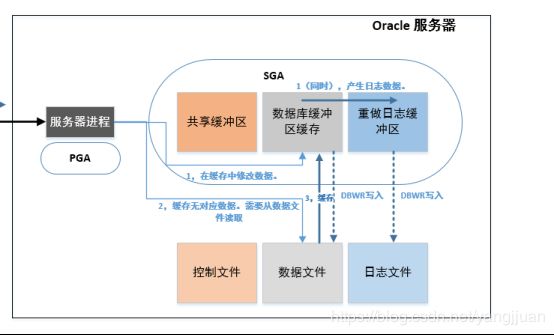
2.1,检查所需的数据库是否已经被读取到缓冲区缓存中。如果已经存在缓冲区缓存,修改缓存中的数据,同时存放产生的日志数据到重做日志缓冲区。
2.2,若所需的数据库并不在缓冲区缓存中,则服务器将数据块从数据文件读取到缓冲区缓存中。
2.3,DBWR:Database writer,后台进程之一,负责将数据缓冲区缓存里被修改的数据写入数据文件。
2.4,LGWR: Log writer,后台进程之一,负责将重做日志缓冲区里的日志数据写入到日志文件。
详细过程可以看:https://blog.csdn.net/eagle89/article/details/80855584
(五)提取数据
当语句执行完成之后,查询到的语句还是在服务器进程中,还没有被传送到客户端的用户进程。所以,在服务器端的进程中,有一个专门负责数据提取的一段代码。它的作用就是把查询到的数据结果返回给用户端进程,从而完成这个查询动作。
三,参考
https://www.cnblogs.com/augus007/articles/7999586.html
https://www.cnblogs.com/Justsoso-WYH/p/9635846.html
https://blog.csdn.net/eagle89/article/details/80855584
https://blog.csdn.net/paopaopotter/article/details/79217539
https://blog.csdn.net/baidu_36457652/article/details/78816731