Linux 根文件系统挂载过程
Table of Contents
一、代码流程
二、相关数据结构
0.基本概念
1.进程控制块PCB
2.文件系统类型
3.文件系统挂载vfsmount
4.超级块(struct super_bloc)
5.目录索引节点(struct inode):
5.目录项对象(struct dentry):
6.file 结构体
7. 打开的文件集
8.文件查找相关的数据结构
三、注册/创建、安装/挂载rootfs
1.向内核注册rootfs虚拟文件系统init_rootfs
2.建立rootfs的根目录,并将rootfs挂载到自己的根目录
一、代码流程
在执行kernel_init之前,会建立roofs文件系统。(kernel_init启动用户空间的第一个进程init)
根文件系统的挂载会经过如下步骤:
- [1*]处设置了根目录的名字为“/”。
- [2*]处设置了vfsmount中的root目录
- [3*]处设置了vfsmount中的超级块
- [4*]处设置了vfsmount中的文件挂载点,指向了自己
- [5*]处设置了vfsmount中的父文件系统的vfsmount为自己
start_kernel
vfs_caches_init
mnt_init
init_rootfs注册rootfs文件系统
init_mount_tree 挂载rootfs文件系统
vfs_kern_mount
mount_fs
type->mount其实是rootfs_mount
mount_nodev
fill_super 其实是ramfs_fill_super
inode = ramfs_get_inode(sb, NULL, S_IFDIR | fsi->mount_opts.mode, 0);
sb->s_root = d_make_root(inode);
static const struct qstr name = QSTR_INIT("/", 1);[1*]
__d_alloc(root_inode->i_sb, &name);
...
mnt->mnt.mnt_root = root;[2*]
mnt->mnt.mnt_sb = root->d_sb;[3*]
mnt->mnt_mountpoint = mnt->mnt.mnt_root;[4*]
mnt->mnt_parent = mnt;[5*]
root.mnt = mnt;
root.dentry = mnt->mnt_root;
mnt->mnt_flags |= MNT_LOCKED;
set_fs_pwd(current->fs, &root);
set_fs_root(current->fs, &root);
...
rest_init
kernel_thread(kernel_init, NULL, CLONE_FS);二、相关数据结构
0.基本概念
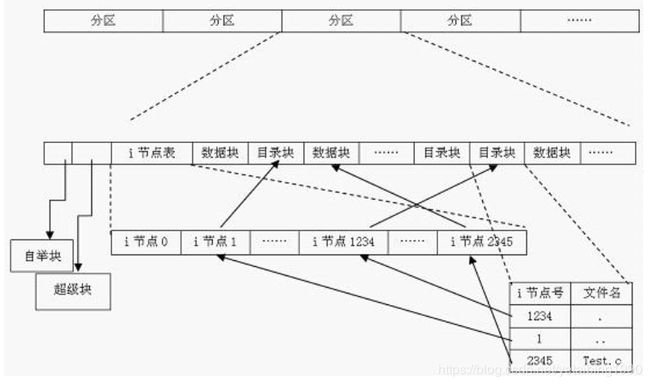
从本质上讲,文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。为了描述 这个结构,Linux引入了一些基本概念:
文件 一组在逻辑上具有完整意义的信息项的系列。在Linux中,除了普通文件,其他诸如目录、设备、套接字等 也以文件被对待。总之,“一切皆文件”。
目录 目录好比一个文件夹,用来容纳相关文件。因为目录可以包含子目录,所以目录是可以层层嵌套,形成 文件路径。在Linux中,目录也是以一种特殊文件被对待的,所以用于文件的操作同样也可以用在目录上。
目录项 在一个文件路径中,路径中的每一部分都被称为目录项;如路径/home/source/helloworld.c中,目录 /, home, source和文件 helloworld.c都是一个目录项。
索引节点 用于存储文件的元数据的一个数据结构。文件的元数据,也就是文件的相关信息,和文件本身是两个不同 的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息。
超级块 用于存储文件系统的控制信息的数据结构。描述文件系统的状态、文件系统类型、大小、区块数、索引节 点数等,存放于磁盘的特定扇区中。
如上的几个概念在磁盘中的位置关系如图所示。
1.进程控制块PCB
struct task_struct {
......
struct thread_info *thread_info;
struct list_head tasks;
pid_t pid;
pid_t tgid;
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
struct fs_struct *fs; //本节将大量使用这个
struct files_struct *files;
......
}
struct fs_struct {
int users;
spinlock_t lock;
seqcount_t seq;
int umask;
int in_exec;
struct path root, pwd;
};2.文件系统类型
kernel/include/linux/fs.h
struct file_system_type {
const char *name;
int fs_flags;
#define FS_REQUIRES_DEV 1
#define FS_BINARY_MOUNTDATA 2
#define FS_HAS_SUBTYPE 4
#define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */
#define FS_USERNS_DEV_MOUNT 16 /* A userns mount does not imply MNT_NODEV */
#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *); //安装/挂载文件系统时,会调用;获取超级块。
void (*kill_sb) (struct super_block *); //卸载文件系统时会调用。
struct module *owner;
struct file_system_type * next; //指向下一个文件系统类型。
struct hlist_head fs_supers; //同一个文件系统类型中所有超级块组成双向链表。
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key s_writers_key[SB_FREEZE_LEVELS];
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
};3.文件系统挂载vfsmount
本质上,mount操作的过程就是新建一个vfsmount结构,然后将此结构和挂载点(目录项对象)关联。关联之后,目录查找时就能沿着vfsmount挂载点一级级向下查找文件了。对于每一个mount的文件系统,都由一个vfsmount实例来表示。
kernel/include/linux/mount.h
struct vfsmount {
struct list_head mnt_hash; //内核通过哈希表对vfsmount进行管理
struct vfsmount *mnt_parent; //指向父文件系统对应的vfsmount
struct dentry *mnt_mountpoint; //指向该文件系统挂载点对应的目录项对象dentry
struct dentry *mnt_root; //该文件系统对应的设备根目录dentry
struct super_block *mnt_sb; //指向该文件系统对应的超级块
struct list_head mnt_mounts;
struct list_head mnt_child; //同一个父文件系统中的所有子文件系统通过该字段链接成双联表
int mnt_flags;
/* 4 bytes hole on 64bits arches */
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list; //所有已挂载文件系统的vfsmount结构通过该字段链接在一起
struct list_head mnt_expire; /* link in fs-specific expiry list */
struct list_head mnt_share; /* circular list of shared mounts */
struct list_head mnt_slave_list;/* list of slave mounts */
struct list_head mnt_slave; /* slave list entry */
struct vfsmount *mnt_master; /* slave is on master->mnt_slave_list */
struct mnt_namespace *mnt_ns; /* containing namespace */
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
/*
* We put mnt_count & mnt_expiry_mark at the end of struct vfsmount
* to let these frequently modified fields in a separate cache line
* (so that reads of mnt_flags wont ping-pong on SMP machines)
*/
atomic_t mnt_count;
int mnt_expiry_mark; /* true if marked for expiry */
int mnt_pinned;
int mnt_ghosts;
/*
* This value is not stable unless all of the mnt_writers[] spinlocks
* are held, and all mnt_writer[]s on this mount have 0 as their ->count
*/
atomic_t __mnt_writers;
};
4.超级块(struct super_bloc)
kernel/include/linux/fs.h
struct super_block {
struct list_head s_list; /* 指向超级块链表的指针 */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type; //文件系统类型
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
int s_count;
atomic_t s_active;
#ifdef CONFIG_SECURITY
void *s_security;
#endif
const struct xattr_handler **s_xattr;
struct list_head s_inodes; /* all inodes */
struct hlist_bl_head s_anon; /* anonymous dentries for (nfs) exporting */
struct list_head s_mounts; /* list of mounts; _not_ for fs use */
struct block_device *s_bdev;
struct backing_dev_info *s_bdi;
struct mtd_info *s_mtd;
struct hlist_node s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
struct sb_writers s_writers;
char s_id[32]; /* Informational name */
u8 s_uuid[16]; /* UUID */
void *s_fs_info; /* Filesystem private info */
unsigned int s_max_links;
fmode_t s_mode;
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
char *s_subtype;
/*
* Saved mount options for lazy filesystems using
* generic_show_options()
*/
char __rcu *s_options;
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/*
* Saved pool identifier for cleancache (-1 means none)
*/
int cleancache_poolid;
struct shrinker s_shrink; /* per-sb shrinker handle */
/* Number of inodes with nlink == 0 but still referenced */
atomic_long_t s_remove_count;
/* Being remounted read-only */
int s_readonly_remount;
/* AIO completions deferred from interrupt context */
struct workqueue_struct *s_dio_done_wq;
struct hlist_head s_pins;
/*
* Keep the lru lists last in the structure so they always sit on their
* own individual cachelines.
*/
struct list_lru s_dentry_lru ____cacheline_aligned_in_smp;
struct list_lru s_inode_lru ____cacheline_aligned_in_smp;
struct rcu_head rcu;
/*
* Indicates how deep in a filesystem stack this SB is
*/
int s_stack_depth;
};5.目录索引节点(struct inode):
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
kernel/include/linux/fs.h
struct inode {
struct hlist_node i_hash; //哈希表节点
struct list_head i_list;
struct list_head i_sb_list;
struct list_head i_dentry;
unsigned long i_ino;
atomic_t i_count;
unsigned int i_nlink;
uid_t i_uid; //文件所有者
gid_t i_gid; //文件所有者所属的用户组
dev_t i_rdev;
u64 i_version;
loff_t i_size;
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
struct timespec i_atime;
struct timespec i_mtime; //修改时间
struct timespec i_ctime; //创建时间
unsigned int i_blkbits;
blkcnt_t i_blocks;
unsigned short i_bytes;
umode_t i_mode; //文件的读写权限
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
struct mutex i_mutex;
struct rw_semaphore i_alloc_sem;
const struct inode_operations *i_op;
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct super_block *i_sb;
struct file_lock *i_flock;
struct address_space *i_mapping;
struct address_space i_data;
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS];
#endif
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
};
int i_cindex;
__u32 i_generation;
#ifdef CONFIG_DNOTIFY
unsigned long i_dnotify_mask; /* Directory notify events */
struct dnotify_struct *i_dnotify; /* for directory notifications */
#endif
#ifdef CONFIG_INOTIFY
struct list_head inotify_watches; /* watches on this inode */
struct mutex inotify_mutex; /* protects the watches list */
#endif
unsigned long i_state;
unsigned long dirtied_when; /* jiffies of first dirtying */
unsigned int i_flags;
atomic_t i_writecount;
#ifdef CONFIG_SECURITY
void *i_security;
#endif
void *i_private; /* fs or device private pointer */
};
5.目录项对象(struct dentry):
dentry的中文名称是目录项,是Linux文件系统中某个索引节点(inode)的链接。这个索引节点可以是文件,也可以是目录。
inode(可理解为ext2 inode)对应于物理磁盘上的具体对象,dentry是一个内存实体,其中的d_inode成员指向对应的inode。也就是说,一个inode可以在运行的时候链接多个dentry,而d_count记录了这个链接的数量。
kernel/include/linux/dcache.h
struct dentry {
atomic_t d_count; //一个inode可以在运行的时候链接多个dentry,而d_count记录了这个链接的数量
unsigned int d_flags; /* protected by d_lock */
spinlock_t d_lock; /* per dentry lock */
int d_mounted;
struct inode *d_inode; //目录项对象与目录索引的关联
/* Where the name belongs to - NULL is
* negative */
/*
* The next three fields are touched by __d_lookup. Place them here
* so they all fit in a cache line.
*/
struct hlist_node d_hash; //哈希表节点 /* lookup hash list */
struct dentry *d_parent; //目录项对象的父亲 /* parent directory */
struct qstr d_name; //d_name.name这个是文件名,目录对象与目录名的关联
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct list_head d_alias; /* inode alias list */
unsigned long d_time; /* used by d_revalidate */
struct dentry_operations *d_op;
struct super_block *d_sb; //指向文件系统的超级块/* The root of the dentry tree */
void *d_fsdata; /* fs-specific data */
unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* small names */
};
6.file 结构体
struct file(file结构体):
struct file结构体定义在include/linux/fs.h中定义。文件结构体代表一个打开的文件,系统中的每个打开的文件在内核空间都有一个关联的 struct file。
struct file {
/*
* fu_list becomes invalid after file_free is called and queued via
* fu_rcuhead for RCU freeing
*/
union {
struct list_head fu_list;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path; //重要!!!记录挂载信息和目录项信息
#define f_dentry f_path.dentry
#define f_vfsmnt f_path.mnt
const struct file_operations *f_op;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
spinlock_t f_ep_lock;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
#ifdef CONFIG_DEBUG_WRITECOUNT
unsigned long f_mnt_write_state;
#endif
};
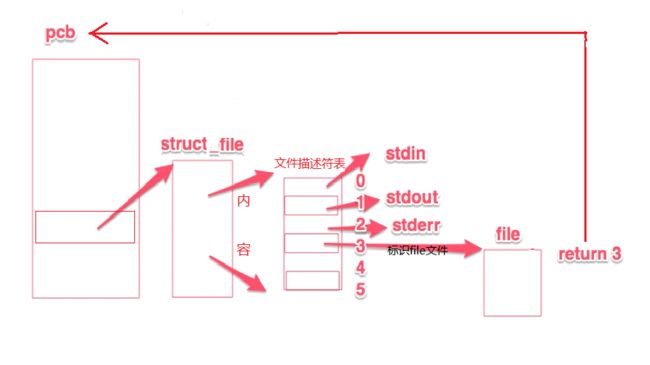
每个进程在PCB(Process Control Block)即进程控制块中都保存着一份文件描述符表,文件描述符就是这个表的索引,文件描述表中每个表项都有一个指
向已打开文件的指针,现在我们明确一下:已打开的文件在内核中用file结构体表示,文件描述符表中的指针指向file结构体。
我们在进程中打开一个文件F,实际上就是要在内存中建立F的dentry,和inode结构,并让它们与进程结构联系来,把VFS中定义的接口给接起来。我们来看一看这个经典的图:

7. 打开的文件集
struct files_struct {//打开的文件集
atomic_t count; /*结构的使用计数*/
……
int max_fds; /*文件对象数的上限*/
int max_fdset; /*文件描述符的上限*/
int next_fd; /*下一个文件描述符*/
struct file ** fd; /*全部文件对象数组*/
……
};
struct fs_struct {//建立进程与文件系统的关系
atomic_t count; /*结构的使用计数*/
rwlock_t lock; /*保护该结构体的锁*/
int umask; /*默认的文件访问权限*/
struct dentry * root; /*根目录的目录项对象*/
struct dentry * pwd; /*当前工作目录的目录项对象*/
struct dentry * altroot; /*可供选择的根目录的目录项对象*/
struct vfsmount * rootmnt; /*根目录的安装点对象*/
struct vfsmount * pwdmnt; /*pwd的安装点对象*/
struct vfsmount * altrootmnt;/*可供选择的根目录的安装点对象*/
};回顾上节的图片很容易理解这两个数据结构
8.文件查找相关的数据结构
include/linux/fs_struct.h
struct fs_struct {
atomic_t count;
rwlock_t lock;
int umask;
struct path root, pwd; //重要!!!记录挂载信息和目录项信息
};
include/linux/namei.h
struct nameidata {
struct path path; //重要!!!记录挂载信息和目录项信息
struct qstr last; //重要!!!记录目录名
unsigned int flags;
int last_type;
unsigned depth;
char *saved_names[MAX_NESTED_LINKS + 1];
/* Intent data */
union {
struct open_intent open;
} intent;
};
include/linux/path.h
struct path {
struct vfsmount *mnt; //重要!!!记录文件系统挂载信息
struct dentry *dentry; //重要!!!记录目录项信息
};
include/linux/dcache.h
struct qstr {
unsigned int hash;
unsigned int len;
const unsigned char *name;//重要!!!目录/文件名字,如"/","tank1"等具体的文件名
}; 三、注册/创建、安装/挂载rootfs
第一步:建立rootfs文件系统;
第二步:调用其get_sb函数(对于rootfs这种内存/伪文件系统是get_sb_nodev,实际文件系统比如ext2等是get_sb_bdev)、建立超级块(包含目录项和i节点);
第三步:挂载该文件系统(该文件系统的挂载点指向该文件系统超级块的根目录项);
第四步:将系统current的根文件系统和根目录设置为rootfs和其根目录。
kernel/init/main.c
asmlinkage void __init start_kernel(void)
{
setup_arch(&command_line);//解析uboot命令行,实际文件系统挂载需要
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param,
&unknown_bootoption);
vfs_caches_init(num_physpages);
}
kernel/fs/dcache.c
void __init vfs_caches_init(unsigned long mempages)
{
mnt_init();
bdev_cache_init(); //块设备文件创建
chrdev_init();//字符设备文件创建
}
kernel/fs/namespace.c
void __init mnt_init(void)
{
init_rootfs(); //向内核注册rootfs
init_mount_tree();//重要!!!rootfs根目录的建立以及rootfs文件系统的挂载;设置系统current根目录和根文件系统为rootfs
} 1.向内核注册rootfs虚拟文件系统init_rootfs
kernel/fs/ramfs/inode.c
int __init init_rootfs(void)
{
err = register_filesystem(&rootfs_fs_type);
}
static struct file_system_type rootfs_fs_type = {
.name = "rootfs",
.get_sb = rootfs_get_sb,
.kill_sb = kill_litter_super,
};
2.建立rootfs的根目录,并将rootfs挂载到自己的根目录
kernel/fs/namespace.c
static void __init init_mount_tree(void)
{
struct vfsmount *mnt;
struct mnt_namespace *ns;
struct path root;
//创建rootfs的vfsmount结构,建立rootfs的超级块、并将rootfs挂载到自己的根目录。
/*
mnt->mnt_mountpoint = mnt->mnt_root = dget(sb->s_root),而该mnt和自己的sb是关联的;
所以,是把rootfs文件系统挂载到了自己对应的超级块的根目录上。
这里也是实现的关键:一般文件系统的挂载是调用do_mount->do_new_mount而该函数中首先调用do_kern_mount,这时mnt->mnt_mountpoint = mnt->mnt_root;但后边
它还会调用do_add_mount->graft_tree->attach_recursive_mnt如下代码mnt_set_mountpoint(dest_mnt, dest_dentry, source_mnt)改变了其挂载点!!!
*/
mnt = do_kern_mount("rootfs", 0, "rootfs", NULL);
list_add(&mnt->mnt_list, &ns->list);
ns->root = mnt; //将创建好的mnt加入系统当前
mnt->mnt_ns = ns;
init_task.nsproxy->mnt_ns = ns; //设置进程的命名空间
get_mnt_ns(ns);
root.mnt = ns->root; //文件系统为rootfs,相当与root.mnt = mnt;
root.dentry = ns->root->mnt_root;//目录项为根目录项,相当与root.dentry = mnt->mnt_root;
//设置系统current的pwd目录和文件系统
set_fs_pwd(current->fs, &root);
//设置系统current根目录,根文件系统。这个是关键!!!整个内核代码最多只有两处调用
set_fs_root(current->fs, &root);
}