在日常工作中,大部分人都会使用 Microsoft Office Word、WPS 或 macOS Pages 等文字处理程序进行 Word 文档处理。除了使用上述的文字处理程序之外,对于 Word 文档来说,还有其他的处理方式么?答案是有的。
接下来阿宝哥将介绍在前端如何玩转 Word 文档,阅读本文之后,你将了解以下内容:
- Microsoft Office Word 支持的文件格式和 Docx 文档的特点;
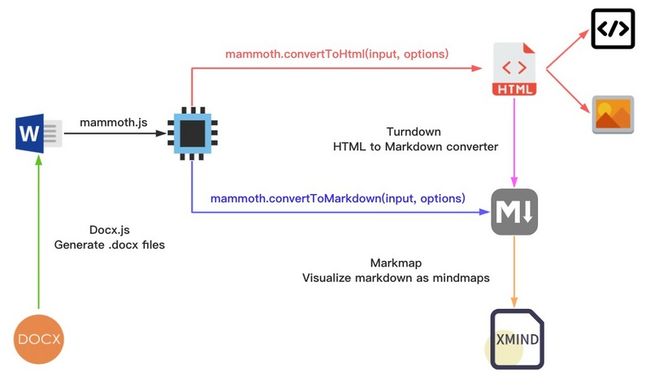
- 如何将 Word 文档转换成 HTML 文档;
- 如何在浏览器中处理 ZIP 文档;
- 如何将 Word 文档转换成 Markdown 文档;
- 如何在前端动态生成 Word 文档。
小伙伴们准备好了吗,玩转 Word 文档之旅 开始了,Let's go!
一、Microsoft Office Word 简介
Microsoft Office Word 是微软公司的一个文字处理器应用程序。它最初是由 Richard Brodie 为了运行 DOS 的 IBM 计算机而在 1983 年编写的。随后的版本可运行于 Apple Macintosh(1984 年)、SCO UNIX 和 Microsoft Windows(1989 年),并成为了 Microsoft Office 的一部分。
Word 给用户提供了用于创建专业而优雅的文档工具,帮助用户节省时间,并得到优雅美观的结果。一直以来,Microsoft Office Word 都是最流行的文字处理程序。
1.1 Word 支持的文件格式
下表列出了常见的几种 Word 支持的文件格式,按扩展名的字母顺序排序。
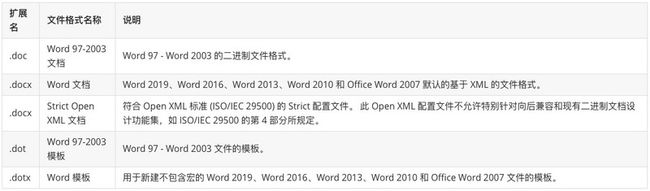
若想了解 Word 所有支持的格式,可参考微软 office-file-format-reference 在线文档。目前大家接触比较多的是扩展名为 .docx 的文档,因此它就是本文的主角。
1.2 Docx 文档
俗话说 “知己知彼百战百胜”,在 “出战” 前我们先来简单了解一下 docx 文档。97-2003 的旧版本文件名后缀就是 .doc, 2007 版以后的后缀名是 .docx。docx 格式是被压缩过的文档,体积更小,能处理更加复杂的内容,访问速度更快。
实际上 docx 文档是一个压缩文件( ZIP 格式)。ZIP 文件格式是一种数据压缩和文档储存的文件格式,原名 Deflate,发明者为菲尔·卡茨(Phil Katz),他于 1989 年 1 月公布了该格式的资料。ZIP 通常使用后缀名 “.zip”,它的 MIME 格式为 application/zip。
这里阿宝哥已经提前准备了一个包含阿宝哥头像和某些文本的 abao.docx 文档,接着复制一份重命名为 abao.zip,然后使用 ZIP 压缩/解压软件进行解压。
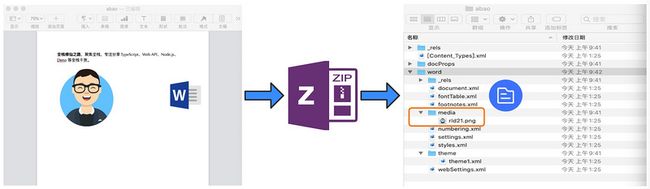
通过观察解压后的目录,我们发现 Word 文档由一系列的 XML 文件和多媒体文件组成, abao.docx 文档中的阿宝哥头像,最终被解压到 word/media 目录下。下面我们来查看一下 abao 文件夹的目录结构:
-rw-rw-r--@ 1 fer staff 1641 7 11 01:25 [Content_Types].xml
drwxr-xr-x@ 3 fer staff 96 7 11 09:41 _rels
drwxr-xr-x@ 4 fer staff 128 7 11 09:41 docProps
drwxr-xr-x@ 13 fer staff 416 7 11 09:42 word很明显 abao 目录下含有一个 [Content_Types].xml 文件和 _rels、docProps、word 三个子目录。
-
[Content_Types].xml:该文件用于定义里面每一个 XML 文件的内容类型; -
_rels:该目录下一般会有一个 .rels 后缀的文件,它里面保存了这个目录下各个 Part 之间的关系。_rels目录不止一个,它实际上是有层级的。 -
docProps:该目录下的 XML 文件用于保存 docx 文件的属性; -
word:该目录下包含了 Word 文档中的内容、字体、样式或主题等信息。
介绍完 Word 支持的文件格式和 Docx 文档,我们开始进入正题 —— “在前端如何玩转 Word 文档”。
二、Word 文档转换成 HTML 文档
在日常工作中,有些时候我们希望在富文本编辑器中导入已有的 Word 文档进行二次加工,要满足这个需求,我们就需要先把 Word 文档转换成 HTML 文档。要实现这个功能,有 服务端转换和前端转换 两种方案:
- 服务端转换:对于 Java 开发者来说,可以直接基于 POI 项目,POI 是 Apache 的一个开源项目,它的初衷是处理基于 Office Open XML 标准(OOXML)和 Microsoft OLE 2 复合文档格式(OLE2)的各种文件格式的文档,而且支持读写操作。
- 前端转换:对于前端开发者来说,要想在前端解析 Word 文档,我们首先需要对 Word 文档进行解压,然后再进一步解析解压后的 XML 文档。看起来整个功能实现起来比较繁琐,但值得庆幸的是 Mammoth.js 这个库已经为我们实现上述功能。
在介绍如何利用 Mammoth.js 把之前创建的 Word 文档转换成 HTML 文档前,我们来提前体验一下最终的转换效果。
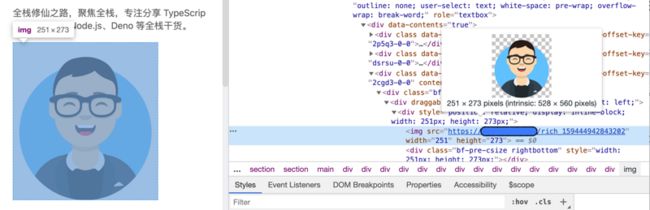
2.1 Mammoth.js 简介
Mammoth.js 旨在转换 .docx 文档(例如由 Microsoft Word 创建的文档),并将其转换为 HTML。 Mammoth 的目标是通过使用文档中的语义信息并忽略其他细节来生成简单干净的 HTML。 比如,Mammoth 会将应用标题 1 样式的任何段落转换为 h1 元素,而不是尝试完全复制标题的样式(字体,文本大小,颜色等)。
由于 .docx 使用的结构与 HTML 的结构之间存在很大的不匹配,这意味着对于较复杂的文档而言,这种转换不太可能是完美的。但如果你仅使用样式在语义上标记文档,则 Mammoth 能实现较好的转换效果。
当前 Mammoth 支持以下主要特性:
- Headings
- Lists,Table
- Images
- Bold, italics, underlines, strikethrough, superscript and subscript
- Links,Line breaks
- Footnotes and endnotes
它还支持自定义映射规则。例如,你可以通过提供适当的样式映射将 WarningHeading 转换为 h1.warning。另外文本框的内容被视为单独的段落,出现在包含文本框的段落之后。
Mammoth.js 这个库为我们提供了很多方法,这里我们来介绍三个比较常用的 API:
-
mammoth.convertToHtml(input, options):把源文档转换为 HTML 文档 -
mammoth.convertToMarkdown(input, options):把源文档转换为 Markdown 文档。这个方法与convertToHtml方法类似,区别就是返回的 result 对象的 value 属性是 Markdown 而不是 HTML。 -
mammoth.extractRawText(input):提取文档的原始文本。这将忽略文档中的所有格式。每个段落后跟两个换行符。
介绍完 Mammoth.js 相关的特性和 API,接下来我们开始进入实战环节。
2.2 Mammoth.js 实战
Mammoth.js 这个库同时支持 Node.js 和浏览器两个平台,在浏览器端 mammoth.convertToHtml 方法的 input 参数的格式是 {arrayBuffer: arrayBuffer},其中 arrayBuffer 就是 .docx 文件的内容。在前端我们可以通过 FileReader API 来读取文件的内容,此外该接口也提供了 readAsArrayBuffer 方法,用于读取指定的 Blob 中的内容,一旦读取完成,result 属性中保存的将是被读取文件的 ArrayBuffer 数据对象。下面我们定义一个 readFileInputEventAsArrayBuffer 方法:
export function readFileInputEventAsArrayBuffer(event, callback) {
const file = event.target.files[0];
const reader = new FileReader();
reader.onload = function(loadEvent: Event) {
const arrayBuffer = loadEvent.target["result"];
callback(arrayBuffer);
};
reader.readAsArrayBuffer(file);
}该方法用于实现把输入的 File 对象转换为 ArrayBuffer 对象。在获取 Word 文档对应的 ArrayBuffer 对象之后,就可以调用 convertToHtml 方法,把 Word 文档内容转换为 HTML 文档。
mammoth.convertToHtml({ arrayBuffer })此时如果你的文档中不包括特殊的图片类型,比如 wmf 或 emf 类型,而是常见的 jpg 或 png 等类型的话,那么你可以看到 Word 文档中的图片。难道这样就搞定了,那是不是太简单了,其实这只是个开始。当你通过浏览器的开发者工具审查 Word 解析后的 HTML 文档后,会发现图片都以 Base64 的格式进行嵌入。如果图片不多且单张图片也不会太大的话,那这种方案是可以考虑的。
针对多图或大图的情况,一种比较好的方案是把图片提交到文件资源服务器上。在 Mammoth.js 中要实现上述的功能,可以使用 convertImage 配置选项来自定义图片处理器。具体的使用示例如下:
let options = {
convertImage: mammoth.images.imgElement(function(image) {
return image.read("base64").then(function(imageBuffer) {
return {
src: "data:" + image.contentType + ";base64," + imageBuffer
};
});
})
};以上示例实现的功能就是把 Word 中的图片进行 Base64 编码,然后转成 Data URL 的形式,以实现图片的显示。很明显这不符合我们的要求,所以我们需要做以下调整:
const mammothOptions = {
convertImage: mammoth.images.imgElement(function(image) {
return image.read("base64").then(async (imageBuffer) => {
const result = await uploadBase64Image(imageBuffer, image.contentType);
return {
src: result.data.path // 获取图片线上的URL地址
};
});
})
};顾名思义 uploadBase64Image 方法的作用就是上传 Base64 编码后的图片:
async function uploadBase64Image(base64Image, mime) {
const formData = new FormData();
formData.append("file", base64ToBlob(base64Image, mime));
return await axios({
method: "post",
url: "http://localhost:3000/uploadfile", // 本地图片上传的API地址
data: formData,
config: { headers: { "Content-Type": "multipart/form-data" } }
});
}为了减少图片文件的大小,我们需要把 Base64 格式的图片先转成 Blob 对象,然后在通过创建 FormData 对象进行提交。base64ToBlob 方法的定义如下:
function base64ToBlob(base64, mimeType) {
let bytes = window.atob(base64);
let ab = new ArrayBuffer(bytes.length);
let ia = new Uint8Array(ab);
for (let i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob([ia], { type: mimeType });
}这时把 Word 文档转换为 HTML 并自动把 Word 文档中的图片上传至文件资源服务器的基本功能已经实现了。对于 Mammoth.js 内部是如何解析 Word 中的 XML 文件,我们就不做介绍了,反之我们来简单介绍一下 Mammoth.js 内部依赖的 JSZip 这个库。
2.3 JSZip 简介
JSZip 是一个用于创建、读取和编辑 .zip 文件的 JavaScript 库,含有可爱而简单的 API。该库的兼容性如下所示:
| Opera | Firefox | Safari | Chrome | Internet Explorer | Node.js |
|---|---|---|---|---|---|
| Yes | Yes | Yes | Yes | Yes | Yes |
| 经过最新版本的测试 | 经过 3.0/3.6/最新版本测试 | 经过最新版本的测试 | 经过最新版本的测试 | 经过 IE 6 / 7 / 8 / 9 / 10 测试 | 经过 Node.js 0.10 / 最新版本测试 |
2.3.1 JSZip 安装
使用 JSZip 时,你可以通过以下几种方式进行安装:
- npm:
npm install jszip - bower:
bower install Stuk/jszip - component :
component install Stuk/jszip - 手动:先下载 JSZip 安装包,然后引入
dist/jszip.js或dist/jszip.min.js文件
2.3.2 JSZip 使用示例
let zip = new JSZip();
zip.file("Hello.txt", "Hello Semlinker\n");
let img = zip.folder("images");
img.file("smile.gif", imgData, {base64: true});
zip.generateAsync({type: "blob"})
.then(function(content) {
// see FileSaver.js
saveAs(content, "example.zip");
});该示例来自 JSZip 官网,成功运行之后,会自动下载并保存 example.zip 文件。该文件解压后的目录结构如下所示:

三、Word 文档转换成 Markdown 文档
Markdown 是一种轻量级标记语言 ,创始人为约翰·格鲁伯(英语:John Gruber)。它允许人们使用易读易写的纯文本格式编写文档,然后转换成有效的 XHTML(或者 HTML)文档。这种语言吸收了很多在电子邮件中已有的纯文本标记的特性。
由于 Markdown 的轻量化、易读易写特性,并且对于图片,图表、数学式都有支持,目前许多网站都广泛使用 Markdown 来撰写帮助文档或是用于论坛上发表消息。
了解完 Markdown 是什么之后,我们来分析一下如何把 Word 文档转换成 Markdown 文档。对于这个功能,我们也有两种处理方式:
- 第一种:使用 Mammoth.js 这个库提供的
mammoth.convertToMarkdown(input, options)方法; - 第二种:基于
mammoth.convertToHtml(input, options)生成的 HTML 文档,在利用 HTML to Markdown 的转换工具,来间接实现上述功能。
下面我们来介绍第二种方案,这里我们使用 Github 上一个开源的转换器 —— turndown,它是使用 JavaScript 开发的 HTML to Markdown 转换器,使用起来很简单。
首先你可以通过以下两种方式来安装它:
- npm:
npm install turndown - script:
安装完之后,你就可以通过调用 TurndownService 构造函数,来创建 turndownService 实例,然后调用该实例的 turndown() 方法执行转换操作:
let markdown = turndownService.turndown(
document.getElementById('content')
)对于前面使用的 abao.docx 文档,最终转换生成的 Markdown 文档如下:
全栈修仙之路,聚焦全栈,专注分享 TypeScript、Web API、Node.js、Deno 等全栈干货。
需要注意的是,TurndownService 构造函数支持很多配置项,这里阿宝哥就不详细介绍了。感兴趣的小伙伴,可以自行阅读 turndown 官方文档或访问 turndown 在线示例 实际体验一下。
既然已经讲到 Markdown,阿宝哥再给小伙伴们介绍一个 Github 上不错的开源库 markmap,该库使用思维导图的方式来实现 Markdown 文档的可视化,整体效果还蛮不错的:

(图片来源:https://markmap.js.org/repl/)
最后,我们再来看一下在前端如何动态生成 Word 文档。
四、前端动态生成 Word 文档
在前端如果要动态生成 Word 文档,我们可以直接利用一些成熟的第三方开源库,比如:docx 或 html-docx-js。
下面我们将以 docx 为例,来介绍如何在前端如何生成 .docx 格式的 Word 文档。Docx 这个库提供了优雅的声明式 API,让我们可以使用 JS/TS 轻松生成 .docx 文件。此外,它还同时支持 Node.js 和浏览器。
Docx 这个库为开发者提供了许多类,用于创建 Word 中的对应元素,这里我们简单介绍几个常见的类:
- Document:用于创建新的 Word 文档;
- Paragraph:用于创建新的段落;
- TextRun:用于创建文本,支持设置加粗、斜体和下划线样式;
- Tables:用于创建表格,支持设置表格每一行和每个表格单元的内容。
接下来阿宝哥将使用 Docx 这个库,来动态生成前面介绍过的 abao.docx 文档,具体代码如下所示:
阿宝哥 - 动态生成 Word 文档示例
在以上示例中,当用户点击 点击生成 Docx 文档 按钮之后,会调用 generate() 回调函数。在该回调函数内,首先会创建新的 Document 对象,然后使用 fetch API 从 Github 上下载阿宝哥的头像,当成功获取图片的数据之后,会继续调用 docx.Media.addImage() 方法添加图片。
接着我们会调用 doc.addSection() 方法来添加 Section 块,该块将作为段落的容器。在示例中,我们创建的 Section 块包含两个段落,一个用于存放文本信息,而另一个用于存放图片信息。最后我们会把 Document 对象转换成 Blob 对象,然后通过 saveAs() 方法下载到本地。
五、参考资源
