利用上虚拟化,说一下TLB,以及VHE
arm给出了基于虚拟化技术会产生的优势:
1. 隔离: 虚拟化的核心是在单个物理系统上运行的虚拟机之间提供隔离。这种隔离允许在互不信任的计算环境之间共享物理系统。例如,两个竞争对手可以共享一个数据中心中的同一台物理计算机,而不必访问彼此的数据。
2. 高可用性: 虚拟化允许在物理计算机之间无缝,透明地迁移工作负载。此技术通常用于将工作负载从可能需要维护和更换的故障硬件平台上迁移出去。
3. 工作负载平衡: 为了优化数据中心的硬件和电源预算,重要的是尽可能多地使用每个硬件平台。同样,这可以通过迁移虚拟机或在物理机上共同托管合适的工作负载来实现。这意味着物理机将被尽可能多地使用。这为数据中心提供商提供了最佳的电源预算,并为租户提供了最佳的性能。
4. 沙箱: VM可用于为可能干扰其运行的计算机其余部分的应用程序提供沙箱。此类应用程序的示例包括旧版应用程序或正在开发的软件。在VM中运行这些应用程序可防止应用程序中的错误或恶意部分干扰物理机上的其他应用程序或数据。
虚拟化EL2层次是与内核态EL1/用户态EL0相提并论的,也就是说,在引入EL2之后,系统的复杂度是EL2✖️EL1✖️EL0的。
EL1由MMU页表转换将EL0的内存实现了隔离,而EL2就需要再实现一次MMU页表转换实现EL1内存地址的隔离,而内存主要由CPU(cache)访问,但在IOMMU(DMA)之后,外设也是有直接访问内存能力的,而外设要访问的内存地址却是由CPU处理得到,于是这中间就产生了一些冲突,CPU看着手中的虚拟地址(需要两次MMU翻译才能知道物理地址),欲哭无泪:不能破坏内存隔离,但外设只能认识物理地址。
这时候SMMU也就是x86世界的IOMMU就应运而生,特别是SMMU-v3/v3.1版本,根据cortext实现,可以支持1/2阶段页表转换,解决了这一冲突;当然,并不是所有cortext实现都支持SMMU,更不必说v3/v3.1。那就另当别论了。
虚拟化EL2层次的引入在实现第二级内存隔离的同时,同样引入了新的问题,即第二级内存的分配、管理、回收,在EL2中运行hypervisor需要关注的只是为每个VM分配内存,在每个VM中再加个内存气球就可以较少考虑开销、效率的实现这一任务,但是当EL2中不只是hypervisor,而是支撑EL1中的驱动task、支撑EL0的内核态,这就不再是一个简单回答的问题了。这个问题需要更加详细的分析,给出更好的答案。
另一个是ASID在虚拟化层次的引入后的处理,要用第二阶段页表隔离VM的地址空间,就要像第一阶段也表一样标注每一条TLB条目所属的VM。在仅有ASID时,TCR_EL1控制TTBR0_EL1/TTBR1_EL1保有ASID值以及ASID是8/16bit,ASID是为了标志TLB条目所属的进程,一个EL0级具有独立地址空间的任务,ASID是其地址空间TLB条目的标记,也就是在切换地址空间时,TLBI ASID x0即可使ASID为x0的cache失效,而大多数EL0地址空间切换都不必执行TLBI,因为新的地址空间要加载未进TLB的TLB条目时,会自行TTW,假设系统仅在两个地址空间切换,并且TLB能装下两个地址空间的常用TLB条目,TTW几乎不回发生,我找了一个Cortex-A73的文档,把它的TLB配置以及一个TLB条目的格式拿出来晾一下。

这是Cortex-A73的TLB的配置,啥意思呢:
1. Cortex-A73的TLB分两级,即microTLB和MainTLB;类似L1/2 cache
2. microTLB分为指令microTLB和数据microTLB,在microTLB中缓存了的TLB条目,只需要1个CLK周期就可以完成转换(吓人不,综合了ASID判断、VMID(还没说)判断、可能是1阶段/2阶段/1+2阶段转换、各种权限PXN/XN/AP/NS。。。一个CLK就得到结果,一个CLK可以理解为一个时钟周期,差不多可以理解为CPU主频2.xGHz分之一)。
3. 指令microTLB支持缓存32条;
4. 数据microTLB支持缓存48条;
5. MainTLB在microTLB miss的时候起作用,包含两个并行缓存,其一为4路,支持1024条VA-PA 4/16/64KB页;其二为2路,支持128条 VA-PA 1/2/16/32/512/1024MB块映射,或 IPA-PA的2MB(4K粒度)/16MB(16K粒度)/512M(64K粒度)。对于在EL2中,这条尤其重要,很多cortex都会有IPA-PA相对于VA-PA的缩水,所以EL2中的代码要怎么做也是需要思考的问题。(经过最近在EL2中写一些代码引起的分析,我确定上面这段话是错的,因为我之前默认的认为了:1阶段页表的虚拟地址是VA,对应EL0所用的地址,2阶段页表的虚拟地址是IPA,对应EL1和EL2所使用的地址;这种理解是错误的,因为在经过多处查找发现,arm文档中,对于EL2中使用的地址,也表述为VA,也就是说,VA这个东西,在EL1/0异常等级下,需要两阶段页表翻译才能得到PA,IPA是其中间过程,而在EL2异常等级下,VA-PA只需要一个阶段的页表翻译,只不过这个阶段对应着EL1/0下的第二阶段页表翻译,有点绕口,我会写一篇东西来说明这处误解)。
再拿Cortex-A73的TLB条目格式来看看:



到这里是一般格式128bit的大TLB条目,后面还有TLB walk格式的编码依旧是128bit。


然后还有IPA-PA的格式编码,都贴出来并不是凑篇幅,看不懂各bit含义的也不必看,看懂的则需要多看看。
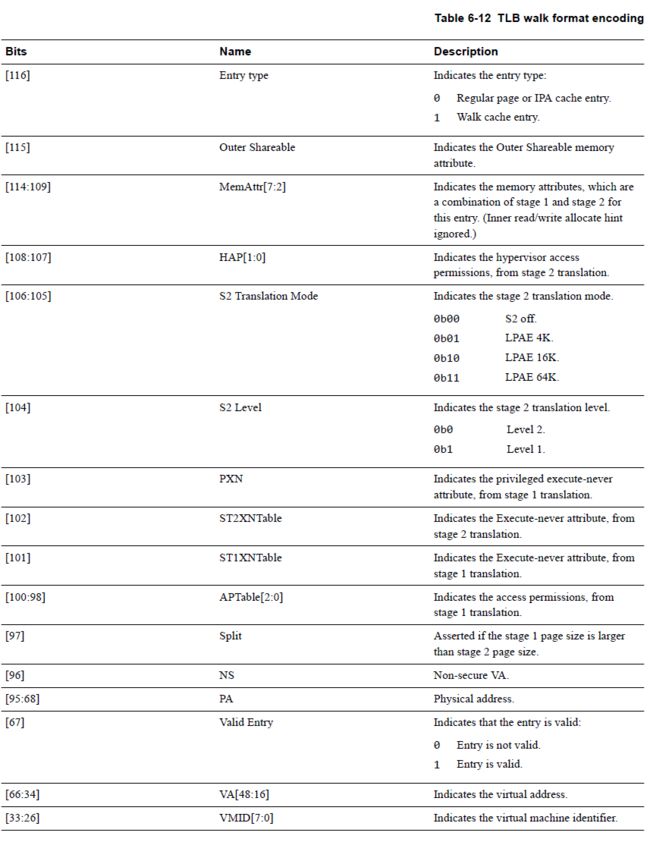
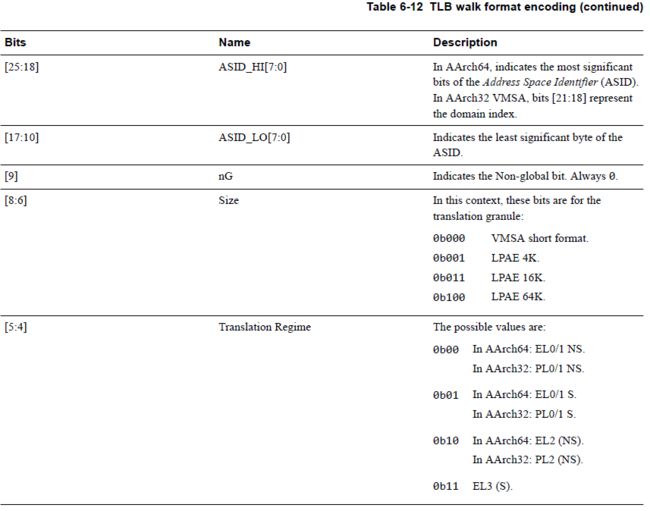


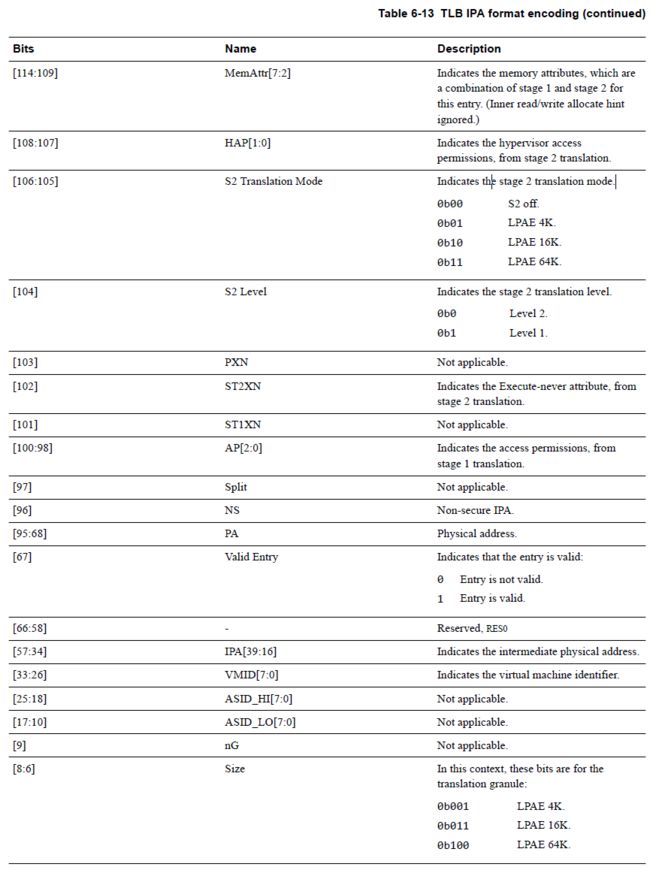
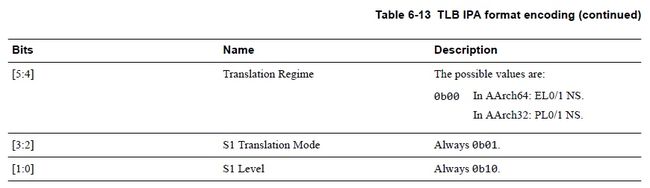
从上面来看,TLB有没有一种很奢华的感觉,都已经到128bit了,hit microTLB的话1个CLK即完成转换。
用了很长篇幅其实就是表示出ASID的位置,知道了ASID在TLB条目中,自然也就知道了ASID在地址转换中的地位,而在加入了虚拟化EL2层次之后,地址空间更多了,VM数量✖️VM平均进程数量才是一个物理计算实体保有的地址空间量,并且层次更加复杂,同一个ASID的地址空间可以属于不同VM,于是VMID(8/16bit)和ASID共同决定一个TLB条目所属的地址空间。当然,VM内能支撑的地址空间数量远超2^ASIDbit,但这是另一个问题了。
很明显VMID与ASID的共同作用将会在EL2层有非常大的影响,比如用户台进程的context切换在当前内核设计是明确的,VM的context切换也是明确的,但是如果EL2层次做context切换如何妥善处理则需要做出考量。
在引入第二阶段页表后,普通内存地址与外设操作寄存器/内存地址的映射也开始变复杂,比如在一阶段页表映射为外设/普通内存的地址段可能在2阶段页表是普通内存/外设,在实现虚拟化时,这是模拟外设的基础,但是在EL2小内核的目标中,这种捕获内存映射异常以实现数据拉取的方式似乎也可一用,毕竟EL1驱动的逻辑特别是数据的交互要做在各个使用者进程的地址空间,这种异常捕获将会是EL2小内核的有力工具,但是该怎么用还要再仔细考虑一下。
还有一个有力的工具是SMMU,虽然v1/2与v3/3.1有不兼容的差异,但是SMMU这种能够为EL1使用DMA提供一致内存视图的宝贝资源也是不可多得的好东西,不过很明显要实现没有SMMU/低版本SMMU/高版本SMMU三种情况的代码,这部分要怎么做也是需要考虑的问题。
为了虚拟化EL2,ARM还有一些对指定指令的捕获的使能如HCR_EL2.TWI捕获WFI指令、HCR_EL2.TVM捕获对MMU相关寄存器操作的指令;另外MIDR_EL1这种表征CPU信息的(如arm Cortex-a73)以及MPIDR_EL1表示CPU多核信息的寄存器也可以设置VPIDR_EL2/VMPIDR_EL2来使EL1读MIDR_EL1/MPIDR_EL1时读到EL2设入的数据;这似乎可以向EL1给出一些信息,可以考虑利用一下,毕竟我要的EL1并不是用来运行VM。
还有一个定时器的问题,ARM的虚拟化还提供有EL1虚拟定时器,在物理定时器CNTPCT_EL0走过10,虚拟定时器CNTVCT_EL0可能由于vPE只被调度执行4而只走了4,设定CNTVOFF_EL2,可以让VCT与PCT同步。
在ARM架构的虚拟化支撑设计中,我觉着最最重要的就是VHE(Virtualization Host Extensions),主要目的就是让内核如Linux等修改HCR_EL2.E2H(El2 Host)并结合HCR_EL2.TGE(Trap General Exception)实现了将EL1的Linux分分钟拉到EL2,并且不耽误EL0,在ARM的设计上是为了让KVM执行hypercall少一次context switch,做了:
1. E2H打开后*_EL1被映射到*_EL2,比如访问TTBRx_EL1会跑到TTBRx_EL2;
2. 访问真正的*_EL1则需要通过MSR *_EL12, x0完成;
3. 这些*_EL1/2/12主要是指:ESR_ELx,TCR_ELx,TTBRx_ELx。
解决了:
1. 进入EL2要切换到EL2页表的问题,EL2虽然有自己的TTBRx_EL2,但是TLB却没有单独做一套,能用的TLB条目更少,进入EL2用EL2页表是凉且少的。
2. EL2没有ASID,似乎还要刷TLB。
3. EL2的页表定义与EL0有很大不同,EL0的UXN在EL2是XN,EL0的PXN在EL2时RES0,不能直接使用,而EL0与EL1的页表定义是一致的。
所以VHE将会是非常重要的可用的提升性能的特性,不过这是虚拟化的选配特性,也存在大量硬件不支持的可能,所以如何合理利用VHE特性提升性能也是需要再考虑的事情,毕竟让TLB热起来是非常重要的。