超详细的Redis入门教程
目录:
- redis简介
- Linux环境安装redis
- redis的数据类型和常用命令
- redis多数据库
- redis数据的持久化
- redis的事务
- Redis主从复制(读写分离)、主从切换(一主二从三哨兵)
- redis发布订阅
- redis单线程模型
- redis批量执行命令
- redis禁用或重命名危险
一、Redis简介
官网:https://redis.io/

1、什么是Redis?
Redis是一个完全开源免费的、遵守BSD协议的、高性能的key-value存储系统。它既可基于内存作为高性能缓存,也可将数据持久化到磁盘,是目前最热门的NoSql数据库之一。
了解:BSD协议是一个给于使用者很大自由的协议。可以自由的使用,修改源代码,也可以将修改后的代码作为开源或者专有软件再发布。
2、我们为什么要使用Redis?
(1).缓存数据,减少对数据库的访问次数,提高响应速度;
(2).性能极高,Redis读取速度可达110000次/s,写速度可达81000次/s ;
(3).支持数据的持久化;
(3).支持丰富的数据结构:String(字符串)、Hash(散列)、List(列表)、Set(集合)以及zset(Sorted Set:有序集合);
......
3、Redis与Memcache的比较
| Memcache |
Redis |
|
| 持久性 |
不支持持久化 |
支持将数据持久化到磁盘 |
| 灾难恢复 |
宕机后数据消失不可恢复 |
数据可恢复 |
| 支持的数据结构 |
简单的k/v类型 |
Hash、List、Set、zset等 |
| 虚拟内存 |
memcache所有数据全部一直存储 在内存中,存储的数据量不能超过 内存的大小。 |
虚拟内存:Redis会将暂时不常用的Values从 内存交换到磁盘中,在内存中只保留Keys的 数据,当这些被换出的Values需要被读取时, Redis则将其再次读回到主内存中。 |
| 并发 |
Memcache支持多线程,通过CAS 实现线程安全保证数据的一致性; |
Redis是单线程的,且Redis支持事务; |
| ...... |
总结:Redis在很多方面具备数据库的特征,或者说就是一个数据库系统,而Memcached只是简单的K/V缓存。有持久化需求或者对数据结构的处理有高级要求的应用,选择redis。简单的key/value存储,可以选择memcache。
4、Redis的使用场景
> 缓存热数据
> 计数器
> Redis 作分布式锁
> 最新列表
例如要展示最新新闻列表,如果总数量很大的情况下,尽量不要使用select a from A limit 10这种low操作,尝试redis的 LPUSH命令构建List。
> 排行榜
可以使用sorted set(有序集)来构建,命令:ZADD。
二、Linux安装Redis
(1)、安装gcc
gcc:linux系统编译器,如果没有安装,在执行make命令时会报Command not found;
>执行如下命令用来查看是否已安装gcc
# gcc -v
出现如下信息表示已安装:gcc version 4.4.7 20120313 (Red Hat 4.4.7-16) (GCC)
>否则,执行如下命令,先安装gcc
# yum install gcc-c++
(2)、安装tcl(非必须,如果不需要测试Redis也可以不安装)
tcl:tcl是一种脚本语言,而Redis的测试用例是tcl脚本,安装后如果需要测试Redis,我们就需要安装tcl解释器,否则在步骤(4)执行make test时会报:You need 'tclsh8.5' in order to run the Redis test。
执行如下命令安装tcl:
# cd /usr/local
# mkdir tcl
# cd tcl
# wget http://downloads.sourceforge.net/tcl/tcl8.6.3-src.tar.gz
# tar -zxvf tcl8.6.3-src.tar.gz
# cd tcl8.6.3/unix/
# ./configure
# make
# make install
(3)、安装Redis
# cd /usr/local
# mkdir redis
# cd redis
# wget http://download.redis.io/releases/redis-4.0.10.tar.gz
# tar -zxvf redis-4.0.10.tar.gz
# cd redis-4.0.10
# make
# make PREFIX=/usr/local/redis install
其中PREFIX=/usr/local/redis可以省略,省略redis默认会安装到/usr/local/bin目录下。
(4)、测试Redis
# cd src
# make test
通过以上命令就可以对redis进行测试。返回"\o/ All tests passed without errors!"表示所有测试都没有错误。
(5)初步配置redis
# cd /usr/local/redis/redis-4.0.10
# vi redis.conf
修改redis配置文件中的下面两个属性:
> daemonize no ——> daemonize yes
配置redis作为守护进程运行。daemonize 设置为no时,退出或关闭终端都会导致redis进程退出;而设置为yes redis会在后台一直运行。
另外还有一个属性:pidfile /var/run/redis_6379.pid,表示当redis服务以守护进程方式运行时,redis默认会把pid(进程Id)写入/var/run/redis_6379.pid,服务运行时该文件就存在,服务一旦停止该文件就自动删除。
> timeout 0 ——> timeout 600
表示客户端闲置多长时间关闭连接;
redis的配置参数很多,此处只修改两项最基本的配置,其他后面会涉及到的配置我们在后面会讲,剩余配置大家可自行了解。
(6)、设置redis开机自启动
# vi /etc/init.d/redis
init.d目录下原本不存在redis文件,执行vi /etc/init.d/redis时会新建redis文件;
> 找到redis启动脚本
# find / -name 'redis_init_script '
启动脚本所在路径:/usr/local/redis/redis-4.0.10/utils/redis_init_script
> 拷贝启动脚本文件
#cp /usr/local/redis/redis-4.0.10/utils/redis_init_script /etc/init.d/redis
> 修改redis文件
# vi /etc/init.d/redis
> 修改以下4处为自己的安装路径,保存
EXEC=/usr/local/redis/redis-4.0.10/src/redis-server
CLIEXEC=/usr/local/redis/redis-4.0.10/src/redis-cli
PIDFILE=/var/run/redis_${REDISPORT}.pid
CONF="/usr/local/redis/redis-4.0.10/redis.conf"
> 设置权限
# chmod 777 /etc/init.d/redis
> 设置开机自启动【此处的redis就代表之前init.d下的redis】
# chkconfig redis on
(7)、启动或关闭redis服务
# service redis start
# service redis stop
(8)、使用redis,简单示例如下【退出redis客户端命令:quit】
[root@JD /]# ./usr/local/redis/redis-4.0.10/src/redis-cli
127.0.0.1:6379> set felixRedis:username yuanlong
OK
127.0.0.1:6379> set felixRedis:password 111111
OK
127.0.0.1:6379> get felixRedis:username
"yuanlong"
127.0.0.1:6379> get felixRedis:password
"111111"
127.0.0.1:6379> quit
[root@JD /]#
三、Redis数据类型和常用命令
> Redis目前支持5种数据类型,分别是:
String(字符串)
Hash(散列)
List(列表)
Set(集合)
Sorted Set(zSet:有序集合)
下面分别介绍五种数据类型及相应的操作命令,Redis总共有14个命令组200多个命令。另外注意Redis的命令不区分大小写,但是key严格区分大小写。
>>> String(字符串):Value最大值为512M
| 命令 |
描述 |
| set key value |
设值,若给定的Key已经存在,则被覆盖 |
| setnx key value |
若给定的key不存在,执行set操作,返回1; 若给定的Key已经存在,不做任何操作,返回0; |
| get key |
获值 |
| mset key value[key value ...] |
同时设置一个或多个Key-Value键值对,如 果某个给定key已经存在,那么MSET新值 会覆盖旧值,mset是原子操作,所有Key都 会在同一时间被设置 |
| msetnx key value[key value ...] |
同mset,但是仅当所有key都不存在时 才会进行set操作 |
| mget key [key ...] |
返回一个或多个指定key对应的value,某个 key不存在那么这个key返回nil |
| setex key seconds value |
设置失效时间,单位s,原子操作,如: setex city 10 shanghai >设置失效时间还可以这样: set key value expire key 10【单位s】 pexpire key 10【单位ms】 >查看缓存的失效时间:ttl key 当key不存在时,返回-2; 当key存在但未设置存活时间时,返回-1; 否则,返回key的剩余存活时间(单位s); |
| incr key |
+1,若key不存在,先将key的值初始化为0 再执行incr; 特殊的String操作:INCR/DECR 使用场景:统计在线人数、秒杀场景的库存 增减; |
| decr key |
-1,若key不存在,先将key的值初始化为0 再执行decr |
| incrby key increment |
+指定增量 |
| decrby key decrement |
-指定减量 |
>>> Hash(散列)
| 命令 |
描述 |
| hset key field value |
将哈希表key中的域field的值设为value; 若key不存在,一个新的Hash表被创建; 若field已经存在,旧的值被覆盖; |
| hget key field |
获取哈希表key中给定域field的值 |
| hdel key filed [field ...] |
删除哈希表key中的一个或多个指定域,不存在 的域将被忽略 |
| hexists key field |
查看哈希表key中,指定域field是否存在, 存在返回1,不存在返回0; |
| hincryby key filed increment |
为哈希表key中的域field加上增量increment, 其余同INCR命令 |
| hmset key field value [field value ...] |
同时将多个field-value对设置到哈希表key中 |
| hmget key field [field ...] |
返回哈希表key中,一个或多个给定域的值, 如果给定的域不存在于哈希表,返回nil; |
| hlen key |
返回哈希表key中域的数量 |
| hkeys key |
返回哈希表key中的所有域 |
| hvals key |
返回哈希表key中所有的值 |
| hgetall key |
返回哈希表key中,所有的域值对 |
>>> List
| 命令 |
描述 |
| lpush key value [value ...] |
从左边插入一个元素(插入表头元素), key不存在时会创建一个新列表 |
| lpushx key value |
从左边插入一个元素(插入表头元素), key不存在时什么操作也不做 |
| rpush key value [value ...] |
|
| rpushx key value |
|
| lpop key |
移除表头元素并返回移除的元素 |
| rpop key |
移除表尾元素并返回移除的元素 |
| lrange key start stop |
返回列表key中指定区间内的元素,下标从0 开始,闭区间; (1).start>stop或start>列表的最大下标,返回 空列表; (2).stop>列表最大下标,按照stop=列表最大 下标来返回; (3).可使用负数下标,-1表示列表最后一个 元素,-2表示列表倒数第二个元素; |
| lrem key count value |
移除count个列表中值为value的元素; (1).count>0表示从头到尾搜索,移除与value 相等的元素,数量为count; (2).count<0表示从尾到头搜索,移除与value 相等的元素,数量为count; (3).count=0表示移除表中所有与value相等 的元素; |
| lindex key index |
返回列表key中,下标为index的元素 |
| lset key index value |
将列表key中下标为index的元素值设为value |
| linsert key BEFORE|AFTER pivot value |
(1).将值value插入列表key中,位于pivo之前或之后; (2).当pivot不存在于列表key时,不执行任何操作; (3).当key不存在时,不执行任何操作; |
| llen key |
返回列表key的长度 |
| ltrim key start stop |
对一个列表进行修剪,让列表只返回指定区 间内的元素,不存在指定区间内的都将被移 除 |
| rpoplpush source destination |
(1).在一个原子操作内,执行两个动作: (2).将列表source的最后一个元素弹出并返回给客 户端; (3).将source弹出的元素作为destination列表的头 元素,插入到列表desination; |
>>> Set:无序、元素不可重复
| 命令 |
描述 |
| sadd key number [member ...] |
将一个或多个member元素加入到key中,已 存在于集合的member将被忽略(set元素不可 重复) |
| scard key |
返回key对应集合中的元素数量 |
| sinter key [key ...] |
返回一个集合的全部成员,该集合是第一个Key对 应的集合和后面key对应的集合的交集 |
| sinter destination key [key ...] |
求两个集合的交集,将结果保存到destination 集合,如果destination已存在,则覆盖,此处注意 destination可以是key本身 |
| sdiff key [key ...] |
返回一个集合的全部成员,该集合是第一个Key对 应的集合和后面key对应的集合的差集 |
| sdiffstore destionation key [key ...] |
求两个集合的差集,将结果保存到destination 集合,如果destination已存在,则覆盖,此处注意 destination可以是key本身 |
| sunion key [key ...] |
返回一个集合的全部成员,该集合是第一个Key对 应的集合和后面key对应的集合的并集 |
| sunion destination key [key ...] |
求两个集合的并集,将结果保存到destination 集合,如果destination已存在,则覆盖,此处注意 destination可以是key本身 |
| sismember key member |
判断member元素是否key的成员,0表示不 是,1表示是; |
| smembers key |
返回集合key中的所有成员 |
| smove source desination member |
(1).原子性地将member元素从source集合移动到 destination集合; (2).source集合中不包含member元素,smove命令 不执行任何操作,仅返回0; (3).destination中已包含member元素,smove命令 只是简单做source集合的member元素移除; |
| spop key [count] |
(1).如果count不指定,移除并返回集合中的一个 随机元素; (2).count为正数且小于集合元素数量,那么移除并 且返回一个含count个元素的数组; (3).count为正数且大于等于集合元素数量,那么返 回整个集合; |
| srandmember key [count] |
类似pop,但仅仅是返回count个元素,不会把元素 从集合中移除; |
| srem key member [member ...] |
移除集合key中的一个或多个member元素, 不存在的member将被忽略 |
>>> SortedSet:有序、元素不可重复
SortedSet中的每个元素都会关联一个整型或double型的分数(score),Redis正是通过分数(score)来为集合中的成员进行从小到大的排序(Redis SortedSet默认从小到大排序)。SortedSet的成员是不可重复的,但分数(score)却可以重复,在score相同的情况下,SortedSet会使用字典排序。
SortedSet是通过哈希表实现的,但在Redis SortedSet里面当items内容大于64时,同时使用了hash和skiplist。
| 命令 |
描述 |
| zadd key score member [score member...] |
(1).将一个或多个member及其score值加入有序集 key中; (2).如果member已经是有序集的成员,那么更新 member对应的score并重新插入member,保证 member在正确的位置上 |
| zcard key |
返回有序集key中元素的个数 |
| zcount key min max |
返回有序集key中,score在[min,max]之间的元素 数量 |
| zrange key start stop [withscores] |
(1).有序集成员按照score从小到大排序(如果想要 从大到小排序,则使用zrevrange命令),具有相 同score值的成员按字典序排列; (2).返回排序后的集合中指定下标区间内的成员; (3).下标参数start和stop都以0为底,也可以用 负数,-1表示最后一个成员,-2表示倒数第二 个成员; (4).可通过withscores选项让成员和它的score 值一并返回; |
| zrank key number |
(1).返回有序集key中成员member的排名,有序集 默认按score值从小到大排列,如果想要从大到小, 可使用zremrank命令。 (2).名次从0开始; (3).此处注意,对于有序集:1 1 2 3,由于有两个1,因 此3正序的Rank应当为2(以0为下标),但实际 上会是3; |
| zrem key member [member ...] |
移除有序集key中的一个或多个成员,不存在的成 员将被忽略 |
| zremrangebyrank key start stop |
移除有序集key中指定排名区间内的成员 |
| zremrangebyscore key min max |
移除有序集key中,所有score值在[min,max]之间的 成员; |
>>> 与Redis key相关的一些命令
| 命令 |
描述 |
| del key [key ...] |
删除一个或多个指定的key,不存在的key将被忽略; |
| exists key |
检查指定的key是否存在; |
| expire key seconds |
为指定key设置生存时间,单位s |
| pexpire key millisecond |
为指定key设置生存时间,单位ms |
| expireat key timestamp |
为指定key设置生存时间,时间戳,单位s |
| keys pattern |
查找所有符合给定模式pattern的key,如: (1).keys *:匹配所有key (2).keys h?llo:匹配hello、hallo、hxllo等 (3).keys h*llo:匹配hllo、heeeeello等 (4).keys h[ae]llo:匹配hello和hallo 注意:虽然keys命令速度非常快,但是当Redis中 有百万、千万甚至过亿数据的时候,扫描所有Redis 的Key,速度仍然会下降,而由于Redis是单线程 模型,所以势必将导致后面的命令阻塞直到KEYS 命令执行完成。 因此当Redis中存储的数据达到了一定量级(经验值 10W以上就值得注意了)的时候,必须警惕KEYS 造成Redis整体性能的下降。 对 Redis 稍微有点使用经验的人都知道线上是不 能执行 keys * 相关命令的,虽然其模糊匹配功能 使用非常方便也很强大,在小数据量情况下使用 没什么问题,数据量大会导致 Redis 锁住及 CPU 飙升,在生产环境建议禁用或者重命名! |
| migrate host port key destination-db timeout [COPY] [REPLACE] |
(1).将 key 原子性地从当前实例传送到目标实例的 指定数据库上,一旦传送成功, key会出现在目标 实例上,而当前实例上的 key会被删除。 (2).这个命令是一个原子操作,它在执行的时候会 阻塞进行迁移的两个实例,直到迁移成功、迁移 失败或等待超时。 (3).命令的内部实现是这样的:它在当前实例对给 定 key 执行 DUMP 命令 ,将它序列化,然后传送 到目标实例,目标实例再使用 RESTORE 对数据 进行反序列化,并将反序列化所得的数据添加到 数据库中;当前实例就像目标实例的客户端那样, 只要看到 RESTORE 命令返回 OK ,它就会调用 DEL删除自己数据库上的 key 。 (4).timeout 参数以毫秒为格式,指定当前实例和 目标实例进行沟通的最大间隔时间。这说明操作并 不一定要在 timeout 毫秒内完成,只是说数据传送 的时间不能超过timeout。 |
| move key db |
当满足条件"当前数据库存在指定key,目的数据库 不存在指定key"时,将当前数据库的 key 移动到指定 的数据库 db 当中;移动完成后,当前数据库不存在 key,目的数据库存在key; |
| persist key |
移除指定key的生效时间,变为永久存活; |
| randomkey |
从当前数据库随机返回而不删除一个key; |
| rename key newkey |
(1).将key重命名为newkey (2).当key和newkey相同或key不存在时报错 (3).如果newkey已存在,将覆盖旧值 |
| ttl key |
返回指定key的剩余存活时间,单位s; |
| pttl key |
返回指定key的剩余存活时间,单位ms; |
| type key |
返回key所存储的值的类型; |
四、Redis多数据库
Redis是一个字典结构的存储服务器,一个Redis实例提供了多个用来存储数据的字典,客户端可以指定将数据存储在哪个字典中,所谓字典就是我们所说的一个redis数据库。每个数据库的数据是隔离的不能共享,并且基于单机才有,如果是集群就没有数据库的概念。
Redis支持多个数据库,每个数据库对外都是以一个从0开始的递增数字命名,Redis默认支持16个数据库(可以通过配置文件支持更多,无上限),可以通过修改配置文件的databases属性来设置。
这就像在一个关系数据库实例中可以创建多个数据库类似。客户端与Redis建立连接后会自动选择0号数据库,不过可以随时使用SELECT命令更换数据库,如要切换到n号数据库,执行select n命令即可切换:
redis> select 1
ok
然而这些以数字命名的数据库又与我们理解的数据库有所区别。首先Redis不支持自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。另外Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么全部没有权限访问。
flushDB命令可以清空当前数据库的所有数据,flushAll命令会清空整个Redis实例中所有数据库的数据。综上所述,这些数据库更像是一种命名空间,而不适宜储不同应用程序的数据。
五、Redis数据的持久化
Redis支持两种数据持久化的方式:RDB和AOF。RDB是根据配置的规则定时将内存中的数据持久化到硬盘上,而AOF则是在每次执行写命令后将命令记录下来。
1、RDB
RDB持久化是通过快照的方式完成的,当满足配置规则(redis.conf文件)时,会将内存中的数据全量复制一份存储到硬盘上,这个过程称作”快照”。RDB文件是经过压缩处理的二进制文件,占用的空间较小。
(1).满足配置规则时自动快照
默认情况下,Redis会把快照数据存放在磁盘上的二进制文件中,文件名为dump.rdb,通过配置文件来设置Redis服务器dump快照的频率。打开redis.conf配置文件,找到如下配置属性:
#save后的第一个参数T是时间,单位是秒,第二个参数M是更改的键的个数;
#表示的含义是:当时间T内更新的键的个数大于M时,自动进行快照;
#各个条件之间是或的关系,只要满足其中一个就进行快照;
save 900 1
save 300 10
save 60 10000
#设置快照文件的名称
dbfilename dump.rdb
#指定快照文件的存储路径
dir ./
对于上面的配置不难看出,如果出现宕机断电等情况的话,RDB死有可能造成数据丢失的,比如save 300 10,如果在300s之内有9条key有更新时宕机,那么就造成了这9条更新key数据的丢失。
除了配置文件中配置的快照规则外,当执行save/bgsave命令、flushall命令、以及主从模式复制初始化时也会触发快照。
(1).save命令&bgsave命令
除了让Redis自动进行快照外,当我们需要重启、迁移、备份Redis时,我们也可以手动执行save或bgsave命令主动进行快照操作。
- save命令:Redis Save 命令执行一个同步保存操作,将当前 Redis 实例的所有数据快照以 RDB 文件的形式快照保存到磁盘,期间会阻塞所有来自客户端的请求;
- bgsave命令: 这个命令与save命令的区别就在于该命令的快照操作是在后台异步进行的,进行快照操作的同时还能处理来自客户端的请求。执行bgsave命令后Redis服务端会马上返回OK表示开始进行快照操作,如果想知道快照操作是否已经完成,可以使用lastsave命令获取最后一次成功执行快照的时间,返回结果是一个Unix时间戳。
(2).flushall
当执行flushall命令时,Redis会清除redis实例中的所有数据。在执行flushall命令之前,只要redis.conf文件中设置的自动快照条件不为空,Redis就会执行一次快照操作,当没有定义自动快照条件时,执行flushall命令不会进行快照操作。
(3).执行复制
当设置了主从模式时,Redis会在复制初始化时自进行快照。
(4).快照原理
快照执行的过程如下:
> Redis使用fork函数复制一份当前进程(父进程)的副本(子进程);
> 父进程继续处理来自客户端的请求,子进程开始将内存中的数据写入磁盘中的临时文件;
> 当子进程写完所有的数据后,再用临时文件替换老的RDB文件,至此,一次快照操作完成。
Redis启动时会自动读取RDB快照文件,将数据从硬盘载入到内存,根据数量的不同,这个过程持续的时间也不尽相同。
2、AOF
(1).AOF配置
Append Only File,只允许追加不允许改写的文件。AOF方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行一遍。
默认情况下,Redis没有开启AOF持久化功能,可以通过在配置文件中作如下配置启用:
#开启AOF持久化功能
appendonly yes
# 设置AOF文件名称,默认appendonly.aof
appendfilename "appendonly.aof"
#AOF文件的保存位置(和dump.db文件保存的位置一样,为同一个属性设置);
dir ./
appendfsync属性:
# appendfsync always
appendfsync everysec
# appendfsync no
在AOF模式下,执行的Redis命令会暂时先存放在缓冲区,再将缓冲区的的数据持久化到磁盘。
appendfsync属性表示调用fsync函数将数据持久化到磁盘的频率。当设置为no时,Redis不会主动调用fsync去将AOF日志内容同步到磁盘,所以这一切就完全依赖于操作系统了;appendfsync everysec表示每秒同步一次;appendfsync always表示每一次写操作都会调用一次fsync。默认为appendfsync everysec。
(2).AOF文件重写
AOF是可识别的纯文本文件,它的内容就是一个个的Redis操作命令,每执行一条写命令,都会追加到AOF文件,所以AOF文件会变的越来越大。
为了解决AOF文件体积膨胀的问题,Redis提供了AOF重写功能:Redis服务器可以创建一个新的AOF文件来替换现有的AOF文件,新旧两个文件所保存的数据状态是相同的,但是新的AOF文件不会包含任何浪费空间的冗余命令,通常体积会较旧AOF文件小很多。
手动触发命令:bgrewriteaof
即使 bgrewriteaof执行失败,也不会有任何数据丢失,因为旧的AOF文件在bgrewriteaof成功之前不会被修改。
据说从Redis 2.4开始,AOF重写由Redis自行触发, bgrewriteaof仅仅用于手动触发重写操作。但网上有说貌似redis还是没有自动触发bgrewriteaof,我们可以写个定时任务隔段时间去执行重写擦操作。
(3).Redis数据恢复
如果只配置RBD,启动时加载dump.rdb文件恢复数据;
如果只配置AOF,重启时加载AOF文件恢复数据;
如果同时配置了RBD和AOF,启动时只加载AOF文件恢复数据;
六、Redis的事务
Redis事务的本质是一次执行多条命令的集合,所有命令都保证顺序执行且不会被其它命令插入。将一组需要执行的命令放到multi和exec两个命令之间,multi命令代表事务开始,exec命令代表事务提交执行。
Redis事务相关的命令有:MULTI、EXEC、DISCARD、WATCH和UNWATCH。
MULTI:标记一个事务块的开始;
EXEC:执行所有事务块内的命令;
DISCARD:表示放弃执行事务;
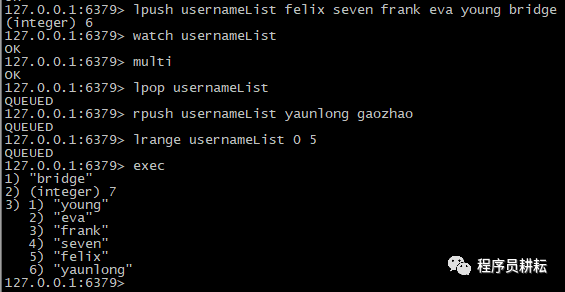
WATCH:监视一个或多个key ,如果在事务执行之前所监视的key有过更新,那么事务执行将被打断;
UNWATCH:取消WATCH命令对所有key的监视;
一个Redis事务从开始到执行会经历以下三个阶段:
- 开始事务
- 命令入队
- 执行事务
执行MULTI命令标志着事务开始,操作命令在执行EXEC 命令前被放入缓存队列,收到 EXEC 命令后开始顺序执行命令,在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中。
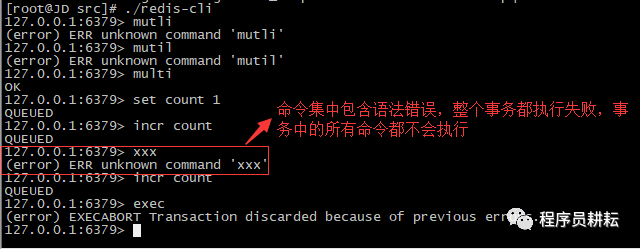
对于命令集错误:
(1).命令集中含有语法错误的,EXEC提交时所有命令均不会被执行;
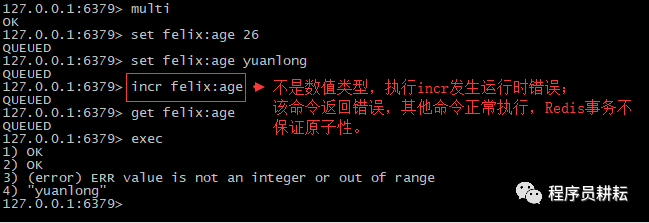
(2).命令集中有命令发生运行时错误,那么正确的命令会正常执行,错误命令返回错误。所以Redis事务不保证原子性。
>下面我们看一下Redis事务的相关操作:
(1).正常操作
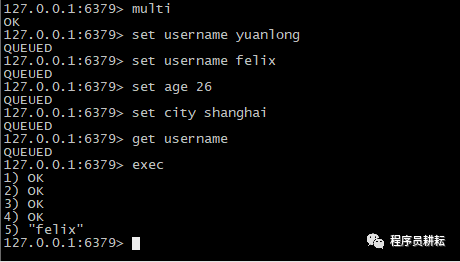
(2).取消事务

(3).WATCH监听
(4).执行错误
七、Redis主从复制(读写分离)、主从切换(一主二从三哨兵)
1、Redis主从复制(读写分离)
和MySQL一样,Redis支持主从同步,读写分离。假设有多台redis实例,一台作为主机Master,其他redis实例作为从机Slave,从机会定期的从主机上同步数据,进而达到主从数据同步。
读写分离,Master负责写请求,Slave负责读请求,这么做一方面通过将读请求分散到其他机器从而大大减少了master服务器的压力,另一方面slave专注于提供读服务从而提高了响应和读取速度。如果master宕机,slave可以介入并取代master的位置,以保证Redis能够正常提供服务。另外,一个Slave同样可以作其他redis实例的Master,即Redis支持一主多从或者多层级联结构。
(1).Redis主从的搭建配置
此处我们在一台Linux服务器上启动多个redis服务,模拟多个Redis实例。
> 新建目录
mkdir redis-cluster
> 将Redis安装目录copy三份到redis-cluster目录下并重命名如下
redis-master-6666
redis-slave-6667
redis-slave-6668
> 分别修改三服务的redis.config配置文件
a.port
6666/6667/6668
b.pidfile
pidfile /var/run/redis_6666.pid
pidfile /var/run/redis_6667.pid
pidfile /var/run/redis_6668.pid
c.dir
dir /usr/local/redis-cluster/redis-slave-6666
dir /usr/local/redis-cluster/redis-slave-6667
dir /usr/local/redis-cluster/redis-slave-6668
d.主机设置连接密码(修改主机的redis.conf文件)
requirepass 111111
也可以不配置,如果配置了,客户端或者从机在连接的时候就需要提供密码;
e.从机配置连接主机的密码(只修改从机的redis.conf配置文件)
masterauth 111111
f.主从复制的关键:指定Master,配从不配主(只修改从机的redis.conf文件)
slaveof 127.0.0.1 6666
> 启动三个redis服务,启动后如图

 转存失败重新上传取消
转存失败重新上传取消
> 启动Master客户端,使用info replication命令查看master信息
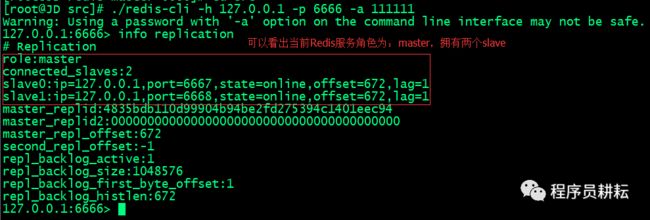
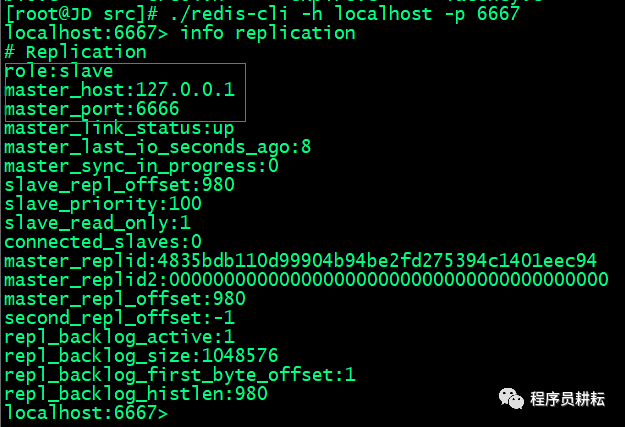
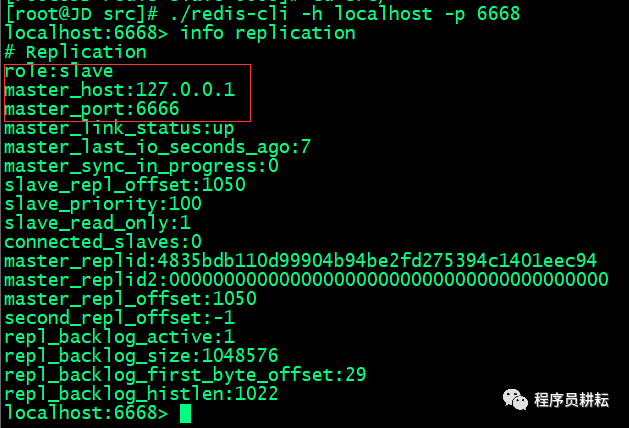
> 分别启动Slave客户端,使用info replication命令查看slave信息
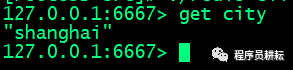
> 验证Master和Slave之间的数据同步,在Master中set几个key值,检验在Slave中是否能够获取到对应的key值
Matser-6666:

Slave-6667:
Slave-6668:
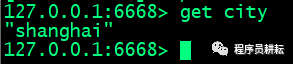
可以看到主机执行写命令,从机同步主机的值,主从复制成功。
2、主从切换(一主二从三哨兵)
我们想一下,在主从分离模式下,如果Master宕机了怎么办?显然,如果对Master宕机没有应对措施的话,那就尴尬了~
所以Redis提供了"sentinel(哨兵)",哨兵的作用就是监控redis主、从服务是否正常运行,如果Master出现故障,会自动将Slave转换为Master以保证Redis对外正常提供服务。所以哨兵的作用就是:
>监控主服务和从服务是否正常运行;
>Master出现故障时自动将Slave转换为Master;
(1).配置哨兵sentinel
查看redis的安装目录,会看到有个sentinel.cnf配置文件,分别对做如下配置:
> 分别修改端口为:
port 26379
port 26389
port 26399
> 如果想要配置sentinel在后台运行,可在sentinel.conf文件中加入如下配置:
daemonize yes
> 设置监控配置
sentinel monitor mymaster 127.0.0.1 6666 2
sentinel monitor mymaster 127.0.0.1 6666 2
sentinel monitor mymaster 127.0.0.1 6666 2
代表sentinel监控的master的名字叫做mymaster ,地址为127.0.0.1:6666,2代表当有2个sentinel主观的认为master已死时,master将会被客观的认为已死。
> 解释几个配置的含义
# sentinel down-after-milliseconds mymaster 30000
sentinel会向master发送心跳PING来确认master是否存活,如果master在down-after-milliseconds时间内(单位:毫秒)不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地认为这个master已经不可用了(SDOWN)。不过这个时候sentinel并不会马上进行主备切换,这个sentinel还需要参考其他sentinel的意见,如果超过quorum(法定人数)数量的sentinel也主观地认为该master死了,那么这个master就会被客观地认为已经死了(ODOWN),将会触发failover(失效备援)操作。
那么触发failover后马上就开始主从切换吗?不是的!
假设有5个sentinel,quorum(法定人数)被设置为2,当2个sentinel认为一个master已经不可用时,sentinel将会触发failover,但是,进行failover的那个sentinel必须获得至少3个sentinel(总哨兵的一半以上)的授权才可以真正执行主从切换操作。
# sentinel failover-timeout mymaster 180000
上面这个配置表示failover过期时间,表示触发failover后,在failover-timeout时间段内仍然没有真正执行failover主从切换操作, 那么此次failover失败。
> 启动sentinel
进入src,执行./redis-sentinel ../sentinel.conf 启动;
(2).验证主从切换
> 首先我们kill掉主服务

> 然后我们再去使用info replication查看之前的从机
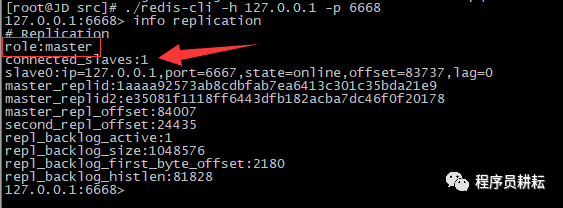
我们发现,原先的slave-6668被切换为新master,新master-6668有一个slave,即6667,6667原本作为6666的slave,主从切换后作为新master-6668的slave。在切换的同时相关的redis.conf配置文件也被修改。
> 重启6666
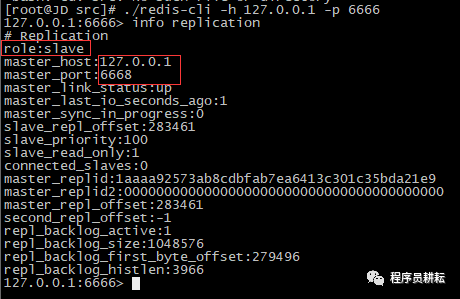
当我们重启6666后,发现它作为了6668的slave。
八、Redis发布订阅
跟MQ的机制很类似。
发布者不直接发送消息给特定的订阅者,而是发布消息到不同的频道,订阅者可以订阅任意数量的频道,当有新消息发送给频道时, 这个消息就会被发送到订阅它的客户端。发布者和订阅者都是Redis客户端。
> 订阅频道
subscribe felixChat
> 发布消息到指定频道
publish redisChat 'Hello Redis'
> 退订频道
unsubscribe redisChat
九、Redis单线程模型
Redis服务端是单线程来处理命令的,所有到达服务端的命令都会进入一个队列,逐个执行,不会有两条命令被同时执行,不会产生并发问题,这就是Redis的单线程基本模型。
※ Redis是单线程来处理命令的,为什么能够达到每秒万级别的处理能力呢?
> 纯内存操作
> 单线程免去了创建维护线程的成本以及线程间切换开销
> redis使用了IO多路复用技术,可以让单个线程高效的处理多个连接请求
※IO多路复用简述
IO多路复用相比于多线程的优势在于系统的开销小,系统不必创建和维护线程,免去了线程切换带来的开销。这里"多路"指的是多个网络连接,"复用"指的是复用同一个线程。
IO多路复用就是利用select、poll、epoll监控多个流的 I/O事件,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态唤醒线程。其中select和poll是程序去轮询监控所有的流。而epoll是只轮询那些真正发出了事件的流,并且只依次顺序的处理准备就绪的流,这种做法就避免了大量的无用操作。
而select、poll、epoll都是IO多路复用的实现机制,Redis采用的就是epoll实现。
举例epoll:一个酒吧服务员(一个线程),前面趴了一群醉汉,突然一个大吼一声"倒酒"(事件),你小跑过去给他倒一杯,然后随他去吧,突然又一个要倒酒,你又过去倒上,就这样一个服务员服务好多人,有时没人喝酒,服务员处于空闲状态,可以干点别的事比如玩玩手机。至于select和poll,需要你挨个去问要不要酒,就没时间玩手机了。
十、Redis批量执行命令
> 准备txt文件
将要执行的命令一行一行写进去,或者从其他文件拷贝进来。在批量插入数据时,我们可以写程序将原始数据构建为一行一行的redis命令,保存到该txt文件中。
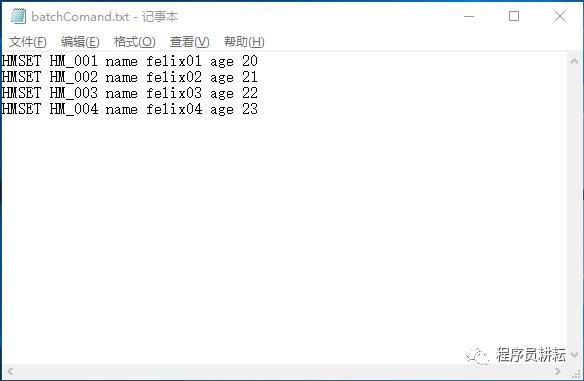
> 转码(使用unix2dos命令)
redis-cli中只支持dos格式的换行符 \r\n ,所以你在linux、mac或windows下创建的文件,最好都转个码,没有转码的文件,执行会失败。
[root@JD ~]# cd /opt/
[root@JD opt]# ls
batchComand.txt
[root@JD opt]# unix2dos batchComand.txt
-bash: unix2dos: command not found
如果在转码时提示命令不存在,那么我们就需要安装unix2dos转码工具。
[root@JD opt]# yum install unix2dos
安装成功后再执行转码命令:
[root@JD opt]# unix2dos batchComand.txt
unix2dos: converting file batchComand.txt to DOS format ...
转码成功!
> 执行导入
[root@JD src]# cat /opt/batchComand.txt | /usr/local/redis/redis-4.0.10/src/redis-cli --pipe
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 4
如果要想导入远程主机,只需执行如下命令即可:
[root@JD src]#cat /opt/batchComand.txt | /usr/local/redis/redis-4.0.10/src/redis-cli -p 6666 -h 127.0.0.1 --pipe
All data transferred. Waiting for the last reply...
Last reply received from server.
errors: 0, replies: 4
十一、安全禁用或者重命名危险命令
对 Redis 稍微有点使用经验的人都知道线上是不能执行 keys * 命令的,虽然其模糊匹配功能使用方便也很强大,在小数据量情况下使用没什么问题,但数据量大会导致 Redis 锁住及 CPU 飙升,在生产环境建议禁用或者重命名!
1、Redis还有哪些危险命令
> keys
> flushdb
> flushall
> config:客户端可修改 Redis 配置
对于以上几个危险命令,在生产环境建议禁用或者重命名;
2、怎么禁用或重命名危险命令?
看下 redis.conf 默认配置文件,找到 SECURITY 区域,如图:
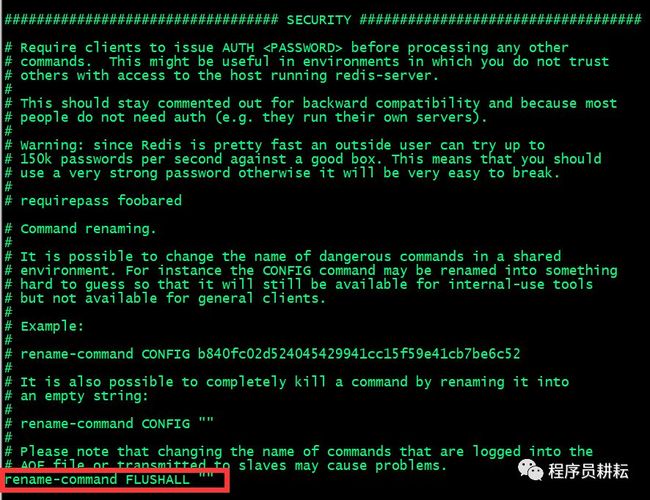
看说明,添加 rename-command 配置即可达到安全目的。
1)禁用命令
rename-command KEYS ""
rename-command FLUSHALL ""
rename-command FLUSHDB ""
rename-command CONFIG ""
2)重命名命令
rename-command KEYS "XXXXXXXXXXXX"
rename-command FLUSHALL "XXXXXXXXXXXX"
rename-command FLUSHDB "XXXXXXXXXXXX"
rename-command CONFIG "XXXXXXXXXXXX"
上面的 XX 可以定义新命令名称,或者用随机字符代替。经过以上的设置之后,危险命令就不会被客户端执行了。
感兴趣的小伙伴可以关注一下博主的公众号,1W+技术人的选择,致力于原创技术干货,包含Redis、RabbitMQ、Kafka、SpringBoot、SpringCloud、ELK等热门技术的学习&资料。
