前言
在前文中,我们已经讨论了Android 渲染体系中整体流程。但是对于fence,每一个厂商对它的理解都有点点不同,但是大体的思路和框架是跟着Android渲染体系走的。就以上一篇的msm8960为例子,在hwc_set中执行了hwc_sync,这个方法做了一件十分重要的申请,如果发现FenceBuffer中的fence是有效的,则会调用阻塞,放开阻塞后,调用下面这个方法:
ioctl(fbFd, MSMFB_BUFFER_SYNC, &data);
MSMFB_BUFFER_SYNC 这个命令是对应上高通的fb驱动自己实现的同步命令,生产一个fence进行同步。
到了这里我们似乎没有办法研究fence继续下去了,因为我已经没有源码了。但是,还是秉承OpenGL es的思路,既然找不到硬件的开源,我们把目光转移到软件(CPU)模拟同步栅的逻辑中进行学习。
我们能在Android源码中,在目录/external/drm_hwcomposer下有一个基于drm驱动实现的hwcomposer。
drm(Direct Rendering Manager)驱动是什么?顾名思义,直接渲染控制器,基于dma-buf。为了取代直接复杂的fb驱动通信,当前Linux主流显示框架下,引入了一个新的内核模块,名为drm驱动。原来的fb内核模块,不支持dma-buf,多层图层合成等。而这些问题都会在drm中统一对GPU和Display驱动模块进行管理,是的面向硬件的编程变得统一化。
用一幅wiki上的一副图来表示:
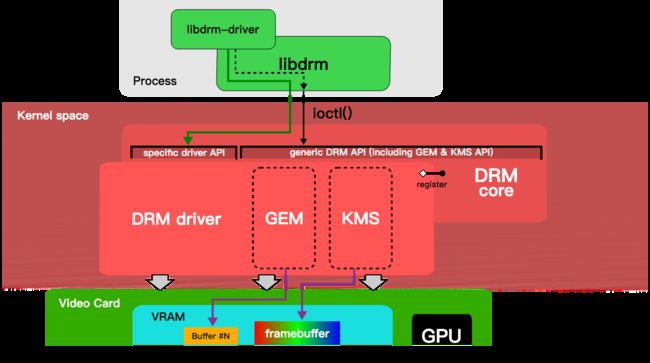
能看到整个drm中,大致分为三个模块:
- 1.面向用户空间的libdrm
- 2.KMS 更新画面以及设置显示参数
- 3.GEM 主要负责显示buffer的分配和释放,也是GPU唯一用到DRM的地方。
有一个大佬何小龙写了一系列的DRM入门文章,写的很棒。之后我将不会大篇幅的介绍DRM驱动的操作,只需要知道基础的操作,就能够进行drm_hwcomposer的解析。
drm的atomic操作
-
- drmSetClientCap(DRM_CLIENT_CAP_UNIVERSAL_PLANES) 初始化Plane硬件图层。DRM_CLIENT_CAP_UNIVERSAL_PLANES返回了OverLayer(YUV叠加图层),Cursor(光标),Primary(主要图层RGB)
-
- drmModePropertySetAlloc 申请一个参数承载内存
-
- drmModePropertySetAdd 添加显示参数,会传入每一个GrpahicBuffer对应的句柄,裁剪区域等,一系列操作就如同drmModeSetPlane一样设置硬件图层参数。
-
- drmModeAtomicCommit 提交参数到drm驱动进行显示。这个过程中有阻塞等待drm渲染到屏幕,也有非阻塞加入到drm的工作队列中进行消费
-
- drmModeAtomicFree 释放参数承载内存
本文将不会对drm驱动的源码和fb驱动源码进行解析,让我们把注意力集中到SF的机制上,以后有机会会和大家聊一聊这两个驱动的源码以及设计。
如果遇到问题请到本文https://www.jianshu.com/p/dca7c4d9495c互相讨论
正文
首先需要对drm_hwcomposer的hw_device_t结构体创建有一个大体的印象:
文件:ernal/drm_hwcomposer/hwcomposer.cpp
static int hwc_device_open(const struct hw_module_t *module, const char *name,
struct hw_device_t **dev) {
if (strcmp(name, HWC_HARDWARE_COMPOSER)) {
return -EINVAL;
}
std::unique_ptr ctx(new hwc_context_t());
if (!ctx) {
return -ENOMEM;
}
int ret = ctx->drm.Init();
if (ret) {
return ret;
}
ret = hw_get_module(GRALLOC_HARDWARE_MODULE_ID,
(const hw_module_t **)&ctx->gralloc);
if (ret) {
return ret;
}
ret = ctx->dummy_timeline.Init();
if (ret) {
return ret;
}
ctx->importer.reset(Importer::CreateInstance(&ctx->drm));
if (!ctx->importer) {
ALOGE("Failed to create importer instance");
return ret;
}
ret = hwc_enumerate_displays(ctx.get());
if (ret) {
return ret;
}
ctx->device.common.tag = HARDWARE_DEVICE_TAG;
ctx->device.common.version = HWC_DEVICE_API_VERSION_1_4;
ctx->device.common.module = const_cast(module);
ctx->device.common.close = hwc_device_close;
ctx->device.dump = hwc_dump;
ctx->device.prepare = hwc_prepare;
ctx->device.set = hwc_set;
ctx->device.eventControl = hwc_event_control;
ctx->device.setPowerMode = hwc_set_power_mode;
ctx->device.query = hwc_query;
ctx->device.registerProcs = hwc_register_procs;
ctx->device.getDisplayConfigs = hwc_get_display_configs;
ctx->device.getDisplayAttributes = hwc_get_display_attributes;
ctx->device.getActiveConfig = hwc_get_active_config;
ctx->device.setActiveConfig = hwc_set_active_config;
ctx->device.setCursorPositionAsync = NULL; /* TODO: Add cursor */
*dev = &ctx->device.common;
ctx.release();
return 0;
}
能看到在device中同样设置了set和prepare方法,对应渲染屏幕set方法是hwc_set。
fence 的介绍
在fence中有三个十分重要的对象:
-
- sync_timeline 每当hal的hw_device_t初始化时候,将会对整个渲染进行一个不断递增时间轴的创建,这个时间轴中有许多同步时间点,称为sync_pt。每一个sync_pt同步时间点只会属于一个fence。
-
- sync_pt sync_pt代表时间轴上的点,告诉SF这个时间点之前都需要进行同步。
-
- fence 同步等待的核心结构体,只有唤醒了fence,SF的渲染流程才能继续。
drm_hwc中整一个fence同步操作都是基于libsync操作dma中sw_sync中进行的,现有一个大致的印象后面该如何工作,我们接下来进行分析。
sync_timeline的初始化
其中在hw_device_t结构体初始化中,其实有一个操作占了很重要的逻辑。
ret = ctx->dummy_timeline.Init();
文件:/external/drm_hwcomposer/hwcomposer.cpp
class DummySwSyncTimeline {
public:
int Init() {
int ret = timeline_fd_.Set(sw_sync_timeline_create());
if (ret < 0)
return ret;
return 0;
}
...
这个方法很简单,实际上就是通过sw_sync_timeline_create创建一个时间轴,把对应内核对象的文件句柄fd返回给timeline_fd_。
sw_sync_timeline_create 创建
文件:/system/core/libsync/sync.c
int sw_sync_timeline_create(void)
{
int ret;
ret = open("/sys/kernel/debug/sync/sw_sync", O_RDWR);
if (ret < 0)
ret = open("/dev/sw_sync", O_RDWR);
return ret;
}
能看到在这个过程中会尝试打开驱动sw_sync。值得注意的是,在高版本中sw_sync已经放入了debug系列中,低版本中有可能使用sw_sync进行软件模拟fence。
sync_timeline 内核中的初始化
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/sw_sync.c( 网站上很少有高版本的Android的kernel,这是从google官网上fork的)
首先来看看这个内核模块的文件操作结构体:
const struct file_operations sw_sync_debugfs_fops = {
.open = sw_sync_debugfs_open,
.release = sw_sync_debugfs_release,
.unlocked_ioctl = sw_sync_ioctl,
.compat_ioctl = sw_sync_ioctl,
};
我们把目光放到sw_sync_debugfs_open中。
static int sw_sync_debugfs_open(struct inode *inode, struct file *file)
{
struct sync_timeline *obj;
char task_comm[TASK_COMM_LEN];
get_task_comm(task_comm, current);
obj = sync_timeline_create(task_comm);
if (!obj)
return -ENOMEM;
file->private_data = obj;
return 0;
}
通过sync_timeline_create创建一个sync_timeline,最后保存到对应的file私有数据中。
sync_timeline_create
struct sync_timeline *sync_timeline_create(const char *name)
{
struct sync_timeline *obj;
obj = kzalloc(sizeof(*obj), GFP_KERNEL);
if (!obj)
return NULL;
kref_init(&obj->kref);
obj->context = fence_context_alloc(1);
strlcpy(obj->name, name, sizeof(obj->name));
INIT_LIST_HEAD(&obj->child_list_head);
INIT_LIST_HEAD(&obj->active_list_head);
spin_lock_init(&obj->child_list_lock);
sync_timeline_debug_add(obj);
return obj;
}
void sync_timeline_debug_add(struct sync_timeline *obj)
{
unsigned long flags;
spin_lock_irqsave(&sync_timeline_list_lock, flags);
list_add_tail(&obj->sync_timeline_list, &sync_timeline_list_head);
spin_unlock_irqrestore(&sync_timeline_list_lock, flags);
}
此时sync_timeline初始化了context为1,并且初始化了active_list_head和child_list_head两个链表头。最后把sync_timeline添加到全局链表sync_timeline_list_head中。
hrm_hwcomposer 渲染中的同步栅参与的操作
经过前文的阅读,就能知道在渲染的时候,对应的方法是上面hwc_set方法。这里我们只关注其fence参与的核心事件。
static int hwc_set(hwc_composer_device_1_t *dev, size_t num_displays,
hwc_display_contents_1_t **sf_display_contents) {
struct hwc_context_t *ctx = (struct hwc_context_t *)&dev->common;
int ret = 0;
std::vector checked_output_fences;
std::vector displays_contents;
std::vector layers_map;
std::vector> layers_indices;
displays_contents.reserve(num_displays);
layers_indices.reserve(num_displays);
for (size_t i = 0; i < num_displays; ++i) {
hwc_display_contents_1_t *dc = sf_display_contents[i];
displays_contents.emplace_back();
DrmHwcDisplayContents &display_contents = displays_contents.back();
layers_indices.emplace_back();
std::vector &indices_to_composite = layers_indices.back();
if (!sf_display_contents[i])
continue;
...
std::string display_fence_description(display_index_formatter.str());
checked_output_fences.emplace_back(&dc->retireFenceFd,
display_fence_description.c_str(),
ctx->dummy_timeline);
display_contents.retire_fence = OutputFd(&dc->retireFenceFd);
size_t num_dc_layers = dc->numHwLayers;
...
for (size_t j = 0; j < num_dc_layers; ++j) {
hwc_layer_1_t *sf_layer = &dc->hwLayers[j];
display_contents.layers.emplace_back();
DrmHwcLayer &layer = display_contents.layers.back();
...
layer.acquire_fence.Set(sf_layer->acquireFenceFd);
sf_layer->acquireFenceFd = -1;
std::ostringstream layer_fence_formatter;
std::string layer_fence_description(layer_fence_formatter.str());
checked_output_fences.emplace_back(&sf_layer->releaseFenceFd,
layer_fence_description.c_str(),
ctx->dummy_timeline);
layer.release_fence = OutputFd(&sf_layer->releaseFenceFd);
}
...
}
if (ret)
return ret;
//设置Layer
...
std::unique_ptr composition(
ctx->drm.compositor()->CreateComposition(ctx->importer.get()));
ret = composition->SetLayers(layers_map.size(), layers_map.data());
ret = ctx->drm.compositor()->QueueComposition(std::move(composition));
for (size_t i = 0; i < num_displays; ++i) {
hwc_display_contents_1_t *dc = sf_display_contents[i];
if (!dc)
continue;
size_t num_dc_layers = dc->numHwLayers;
for (size_t j = 0; j < num_dc_layers; ++j) {
hwc_layer_1_t *layer = &dc->hwLayers[j];
...
hwc_add_layer_to_retire_fence(layer, dc);
}
}
composition.reset(NULL);
return ret;
}
我们把目光放在fence的参与的逻辑。这这里面有一个核心的vector集合checked_output_fences。大致做了如下几件事情:
- 1.设置retireFenceFd
checked_output_fences.emplace_back(&dc->retireFenceFd,
display_fence_description.c_str(),
ctx->dummy_timeline);
display_contents.retire_fence = OutputFd(&dc->retireFenceFd)
- 2.把Hal层的acquireFenceFd 设置给drmlayer
layer.acquire_fence.Set(sf_layer->acquireFenceFd);
sf_layer->acquireFenceFd = -1;
- 2.设置releaseFenceFd
checked_output_fences.emplace_back(&sf_layer->releaseFenceFd,
layer_fence_description.c_str(),
ctx->dummy_timeline);
layer.release_fence = OutputFd(&sf_layer->releaseFenceFd);
-
- 当QueueComposition 把图像渲染到屏幕后,将会把每一层的releaseFenceFd和retireFenceFd合并为一个fence,最后不用的退休的Fence。
static void hwc_add_layer_to_retire_fence(
hwc_layer_1_t *layer, hwc_display_contents_1_t *display_contents) {
if (layer->releaseFenceFd < 0)
return;
if (display_contents->retireFenceFd >= 0) {
int old_retire_fence = display_contents->retireFenceFd;
display_contents->retireFenceFd =
sync_merge("dc_retire", old_retire_fence, layer->releaseFenceFd);
close(old_retire_fence);
} else {
display_contents->retireFenceFd = dup(layer->releaseFenceFd);
}
}
QueueWork的消费原理
这里需要注意,在hrm_hwcomposer的处理模型中,每当进行hw_device_t初始化后会在hrm_hwcomposer后台初始化一个线程,接受每一个渲染到屏幕的任务,每当一个任务处理结束之后,将会唤醒队列进行下一个的渲染任务的消费。
消费的核心方法如下:
文件:/external/drm_hwcomposer/queue_worker.h
template
int QueueWorker::QueueWork(std::unique_ptr workitem) {
std::unique_lock lk(mutex_);
auto wait_func = [&] { return queue_.size() < max_queue_size_; };
int ret = WaitCond(lk, wait_func, queue_timeout_ms_);
if (ret)
return ret;
queue_.push(std::move(workitem));
lk.unlock();
cond_.notify_one();
return 0;
}
能看到每一个QueueWork进行入队都会进行阻塞,直到达到超时为止。这个时候将会等待上一个渲染任务结束之后,才会唤醒当前的线程。继续进行Commit方法提交到drm进行屏幕渲染。
当然,在提交之前还会做一次检测,看看本次渲染中,有没有OpenGL es等异步图元合成还没有完成。注意在hrm_hwcomposerr中,每一次提交都是通过drmcompositor控制不同屏幕的compositor(如主屏幕则是drmdisplaycompositor)通过drmcomposition(内含有对应不同屏幕的composition,如主屏幕对应drmdisplaycomposition),进行提交。最后会调用如下方法:
文件:/external/drm_hwcomposer/drmdisplaycompositor.cpp
if (!test_only && layer.acquire_fence.get() >= 0) {
int acquire_fence = layer.acquire_fence.get();
int total_fence_timeout = 0;
for (int i = 0; i < kAcquireWaitTries; ++i) {
int fence_timeout = kAcquireWaitTimeoutMs * (1 << i);
total_fence_timeout += fence_timeout;
ret = sync_wait(acquire_fence, fence_timeout);
if (ret)
ALOGW("Acquire fence %d wait %d failed (%d). Total time %d",
acquire_fence, i, ret, total_fence_timeout);
else
break;
}
if (ret) {
break;
}
layer.acquire_fence.Close();
}
if (!layer.buffer) {
break;
}
//drmModeAtomicAddProperty 设置提交的参数
...
}
out:
if (!ret) {
uint32_t flags = DRM_MODE_ATOMIC_ALLOW_MODESET;
if (test_only)
flags |= DRM_MODE_ATOMIC_TEST_ONLY;
ret = drmModeAtomicCommit(drm_->fd(), pset, flags, drm_);
其中会遍历每一个Layer中设置好的acquire_fence,进行等待。可以得知,实际上fence阻塞的核心方法是sync_wait。
回过头来,我们纵览全局。还记得Binder驱动中,所有的进程唤起Binder的执行操作都是从一个线程池中唤起,执行任务的。等到了SF进行GraphicBuffer queue入队之后,通过Handler归于SF的主线程中。
那么其实整个流程大致是如下的:

既然渲染的方法是耗时的,那么必定存在需要同步的事件,不允许那些正在渲染到屏幕的GraphicBuffer遭到修改,导致屏幕渲染出现割裂等问题。这个时候就轮到fence登场了。
那么创建fence的方法在哪里呢?其实奥妙和智能指针有着同工异曲的奥妙,我们看看checked_output_fences中每一个元素CheckedOutputFd。
CheckedOutputFd 作用域
文件:/external/drm_hwcomposer/hwcomposer.cpp
struct CheckedOutputFd {
CheckedOutputFd(int *fd, const char *description,
DummySwSyncTimeline &timeline)
: fd_(fd), description_(description), timeline_(timeline) {
}
CheckedOutputFd(CheckedOutputFd &&rhs)
: description_(rhs.description_), timeline_(rhs.timeline_) {
std::swap(fd_, rhs.fd_);
}
CheckedOutputFd &operator=(const CheckedOutputFd &rhs) = delete;
~CheckedOutputFd() {
if (fd_ == NULL)
return;
if (*fd_ >= 0)
return;
*fd_ = timeline_.CreateDummyFence().Release();
if (*fd_ < 0)
ALOGE("Failed to fill %s (%p == %d) before destruction",
description_.c_str(), fd_, *fd_);
}
private:
int *fd_ = NULL;
std::string description_;
DummySwSyncTimeline &timeline_;
};
实际上十分简单,我们主要关注析构函数。在析构函数中,实际上就是调用CreateDummyFence创建一个fence。那么我们就要看CheckedOutputFd析构的时机了。
在上面的代码中,我们其实能看到CheckedOutputFd对应的集合checked_output_fences作用域是整个hwc_set函数。换句话说,当这个方法结束之后将会对CheckedOutputFd进行结构。
DummySwSyncTimeline CreateDummyFence() 创建软件模拟fence
UniqueFd CreateDummyFence() {
int ret = sw_sync_fence_create(timeline_fd_.get(), "dummy fence",
timeline_pt_ + 1);
if (ret < 0) {
return ret;
}
UniqueFd ret_fd(ret);
ret = sw_sync_timeline_inc(timeline_fd_.get(), 1);
if (ret) {
return ret;
}
++timeline_pt_;
return ret_fd;
}
核心只有两件事情:
- 1.sw_sync_fence_create 创建一个软件模拟的fence
- 2.sw_sync_timeline_inc sync_timeline 时间轴向后推一个时间同步点。
sw_sync_fence_create 创建一个软件模拟的fence
int sw_sync_fence_create(int fd, const char *name, unsigned value)
{
struct sw_sync_create_fence_data data;
int err;
data.value = value;
strlcpy(data.name, name, sizeof(data.name));
err = ioctl(fd, SW_SYNC_IOC_CREATE_FENCE, &data);
if (err < 0)
return err;
return data.fence;
}
在这个过程中,SW_SYNC_IOC_CREATE_FENCE通过ioctl通信进行fence的创建。
内核的fence创建
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/sw_sync.c
static long sw_sync_ioctl(struct file *file, unsigned int cmd,
unsigned long arg)
{
struct sync_timeline *obj = file->private_data;
switch (cmd) {
case SW_SYNC_IOC_CREATE_FENCE:
return sw_sync_ioctl_create_fence(obj, arg);
case SW_SYNC_IOC_INC:
return sw_sync_ioctl_inc(obj, arg);
default:
return -ENOTTY;
}
}
static long sw_sync_ioctl_create_fence(struct sync_timeline *obj,
unsigned long arg)
{
int fd = get_unused_fd_flags(O_CLOEXEC);
int err;
struct sync_pt *pt;
struct sync_file *sync_file;
struct sw_sync_create_fence_data data;
if (fd < 0)
return fd;
if (copy_from_user(&data, (void __user *)arg, sizeof(data))) {
err = -EFAULT;
goto err;
}
pt = sync_pt_create(obj, sizeof(*pt), data.value);
if (!pt) {
err = -ENOMEM;
goto err;
}
sync_file = sync_file_create(&pt->base);
fence_put(&pt->base);
if (!sync_file) {
err = -ENOMEM;
goto err;
}
data.fence = fd;
if (copy_to_user((void __user *)arg, &data, sizeof(data))) {
fput(sync_file->file);
err = -EFAULT;
goto err;
}
fd_install(fd, sync_file->file);
return 0;
err:
put_unused_fd(fd);
return err;
}
- 1.通过sync_pt_create 创建一个新的sync_point
- 2.sync_file_create 一个fence文件描述符。
- 3.fd_install 为fence文件描述绑定fd句柄。
sync_pt_create 创建一个新的sync_point
static struct sync_pt *sync_pt_create(struct sync_timeline *obj, int size,
unsigned int value)
{
unsigned long flags;
struct sync_pt *pt;
if (size < sizeof(*pt))
return NULL;
pt = kzalloc(size, GFP_KERNEL);
if (!pt)
return NULL;
spin_lock_irqsave(&obj->child_list_lock, flags);
sync_timeline_get(obj);
fence_init(&pt->base, &timeline_fence_ops, &obj->child_list_lock,
obj->context, value);
list_add_tail(&pt->child_list, &obj->child_list_head);
INIT_LIST_HEAD(&pt->active_list);
spin_unlock_irqrestore(&obj->child_list_lock, flags);
return pt;
}
void
fence_init(struct fence *fence, const struct fence_ops *ops,
spinlock_t *lock, u64 context, unsigned seqno)
{
BUG_ON(!lock);
BUG_ON(!ops || !ops->wait || !ops->enable_signaling ||
!ops->get_driver_name || !ops->get_timeline_name);
kref_init(&fence->refcount);
fence->ops = ops;
INIT_LIST_HEAD(&fence->cb_list);
fence->lock = lock;
fence->context = context;
fence->seqno = seqno;
fence->flags = 0UL;
trace_fence_init(fence);
}
此时会为sync_pt申请内存。为fence文件描述符进行赋值,添加fence_ops的操作结构体,初始化fence中的回调队列。最后把sync_pt添加到sync_timeline的child_list_head链表中。
稍微看看fence结构体对应都有哪些操作方法 timeline_fence_ops
static const struct fence_ops timeline_fence_ops = {
.get_driver_name = timeline_fence_get_driver_name,
.get_timeline_name = timeline_fence_get_timeline_name,
.enable_signaling = timeline_fence_enable_signaling,
.disable_signaling = timeline_fence_disable_signaling,
.signaled = timeline_fence_signaled,
.wait = fence_default_wait,
.release = timeline_fence_release,
.fence_value_str = timeline_fence_value_str,
.timeline_value_str = timeline_fence_timeline_value_str,
};
int ret = sw_sync_fence_create(timeline_fd_.get(), "dummy fence",
timeline_pt_ + 1);
....
++timeline_pt_;
回顾当前设置的参数,最重要的是在fence记录了当前timeline_pt_+1,也就是fence预计唤醒的同步时间点。每一次创建都会往前推一个计数,作为新的fence的唤醒同步点。
sync_file_create 创建fence的file结构体
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/sync_file.c
struct sync_file *sync_file_create(struct fence *fence)
{
struct sync_file *sync_file;
sync_file = sync_file_alloc();
if (!sync_file)
return NULL;
sync_file->fence = fence_get(fence);
snprintf(sync_file->name, sizeof(sync_file->name), "%s-%s%llu-%d",
fence->ops->get_driver_name(fence),
fence->ops->get_timeline_name(fence), fence->context,
fence->seqno);
return sync_file;
}
static struct sync_file *sync_file_alloc(void)
{
struct sync_file *sync_file;
sync_file = kzalloc(sizeof(*sync_file), GFP_KERNEL);
if (!sync_file)
return NULL;
sync_file->file = anon_inode_getfile("sync_file", &sync_file_fops,
sync_file, 0);
if (IS_ERR(sync_file->file))
goto err;
kref_init(&sync_file->kref);
init_waitqueue_head(&sync_file->wq);
INIT_LIST_HEAD(&sync_file->cb.node);
return sync_file;
err:
kfree(sync_file);
return NULL;
}
能看到实际上是申请了sync_file的内存,并且初始化等待队列。同时为文件描述符注入对应的file_operation sync_file_fops:
static const struct file_operations sync_file_fops = {
.release = sync_file_release,
.poll = sync_file_poll,
.unlocked_ioctl = sync_file_ioctl,
.compat_ioctl = sync_file_ioctl,
};
那么我们可以得到一个关系,通过操作sync_file文件描述符的操作,进而进行fence结构体的操作。
sw_sync_timeline_inc sync_timeline 时间轴向后推一个时间同步点
文件:http://androidxref.com/9.0.0_r3/xref/system/core/libsync/sync.c
int sw_sync_timeline_inc(int fd, unsigned count)
{
__u32 arg = count;
return ioctl(fd, SW_SYNC_IOC_INC, &arg);
}
发送需要增加count传送到内核。
sw_sync_ioctl_inc
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/sw_sync.c
static long sw_sync_ioctl_inc(struct sync_timeline *obj, unsigned long arg)
{
u32 value;
if (copy_from_user(&value, (void __user *)arg, sizeof(value)))
return -EFAULT;
sync_timeline_signal(obj, value);
return 0;
}
最后进行sync_timeline_signal方法尝试唤醒timeline中的同步点。
static void sync_timeline_signal(struct sync_timeline *obj, unsigned int inc)
{
unsigned long flags;
struct sync_pt *pt, *next;
trace_sync_timeline(obj);
spin_lock_irqsave(&obj->child_list_lock, flags);
obj->value += inc;
list_for_each_entry_safe(pt, next, &obj->active_list_head,
active_list) {
if (fence_is_signaled_locked(&pt->base))
list_del_init(&pt->active_list);
}
spin_unlock_irqrestore(&obj->child_list_lock, flags);
}
在这个过程中,把sync_timeline中的记录时间点value的数值加1.紧接着开始遍历添加到active_list中的fence进行唤起。由于此时并没有添加到sync_timeline的active_list中,因此不会有任何操作。
如果发现有fence添加到active_list,将会调用fence_is_signaled_locked检测是否需要唤起这个fence,并且从active_list移除fence。
初始化说完了,并且每一次执行完渲染屏幕的操作就会唤起每一个保存在sync_timeline中active_list的fence。那么哪里进行阻塞呢?我们先把目光放到Fence中。我们能从之前几篇流程中可以的得出,实际上BufferSlot对应的BufferItem中的mFence对象就是Fence类,最后会在setUpHwcComposer中prepareFrame设置到Hal中。
Fence 的介绍
在Android Framework中有一个用于操作fence同步栅的类。这个类如果阅读前文,就已经是老朋友了。到处出现在SF的渲染合成逻辑。
我们先看部分核心逻辑。
文件:/frameworks/native/libs/ui/Fence.cpp
const sp Fence::NO_FENCE = sp(new Fence);
Fence::Fence(int fenceFd) :
mFenceFd(fenceFd) {
}
Fence::Fence(base::unique_fd fenceFd) :
mFenceFd(std::move(fenceFd)) {
}
status_t Fence::wait(int timeout) {
ATRACE_CALL();
if (mFenceFd == -1) {
return NO_ERROR;
}
int err = sync_wait(mFenceFd, timeout);
return err < 0 ? -errno : status_t(NO_ERROR);
}
status_t Fence::waitForever(const char* logname) {
ATRACE_CALL();
if (mFenceFd == -1) {
return NO_ERROR;
}
int warningTimeout = 3000;
int err = sync_wait(mFenceFd, warningTimeout);
if (err < 0 && errno == ETIME) {
err = sync_wait(mFenceFd, TIMEOUT_NEVER);
}
return err < 0 ? -errno : status_t(NO_ERROR);
}
Fence::NO_FENCE 我们在SF的dequeue初始化流程都能看到,实际上就是一个持有非法的fence的fd,不做任何事情。这里的fd其实就对应在hwc中申请的sync_file对应的文件句柄。
当我们需要进行阻塞时候,将会调用waitForever或者wait进行阻塞。wait方法需要你显示的设置超时参数。waitForever则会先设置一个3秒超时机制,如果返回err<0,则直接进行永久阻塞。
我们需要研究最核心的libsync中sync_wait的机制。
sync_wait fence阻塞原理
int sync_wait(int fd, int timeout)
{
struct pollfd fds;
int ret;
if (fd < 0) {
errno = EINVAL;
return -1;
}
fds.fd = fd;
fds.events = POLLIN;
do {
ret = poll(&fds, 1, timeout);
if (ret > 0) {
if (fds.revents & (POLLERR | POLLNVAL)) {
errno = EINVAL;
return -1;
}
return 0;
} else if (ret == 0) {
errno = ETIME;
return -1;
}
} while (ret == -1 && (errno == EINTR || errno == EAGAIN));
return ret;
}
实际上fence使用的是poll系统调用阻塞整个线程。当然关于poll的源码我还没有解析,但是可以去看看我写的epoll系统调用有进行epoll和poll的比较和解析。
既然是对应上poll的系统调用,就会对应上file_operation 结构体中的poll方法指针。也就是对应sync_file_fops中的poll方法sync_file_poll
内核中fence阻塞原理
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/sync_file.c
static unsigned int sync_file_poll(struct file *file, poll_table *wait)
{
struct sync_file *sync_file = file->private_data;
poll_wait(file, &sync_file->wq, wait);
if (!test_and_set_bit(POLL_ENABLED, &sync_file->fence->flags)) {
if (fence_add_callback(sync_file->fence, &sync_file->cb,
fence_check_cb_func) < 0)
wake_up_all(&sync_file->wq);
}
return fence_is_signaled(sync_file->fence) ? POLLIN : 0;
}
能看到epoll中熟悉的身影,poll_wait方法。不过这里设计和epoll不一样。因为epoll自己调用了注册在监听中的文件描述的poll方法,所以就能够自己设置poll_table的回调函数,我们来看看poll系统调用中poll_table的初始化:
文件:/fs/select.c
void poll_initwait(struct poll_wqueues *pwq)
{
init_poll_funcptr(&pwq->pt, __pollwait);
pwq->polling_task = current;
pwq->triggered = 0;
pwq->error = 0;
pwq->table = NULL;
pwq->inline_index = 0;
}
init_poll_funcptr这个方法就是epoll中,如果注册到epoll的监听并调用了poll_wait会调用的关键的回调函数。
static void __pollwait(struct file *filp, wait_queue_head_t *wait_address,
poll_table *p)
{
struct poll_wqueues *pwq = container_of(p, struct poll_wqueues, pt);
struct poll_table_entry *entry = poll_get_entry(pwq);
if (!entry)
return;
entry->filp = get_file(filp);
entry->wait_address = wait_address;
entry->key = p->_key;
init_waitqueue_func_entry(&entry->wait, pollwake);
entry->wait.private = pwq;
add_wait_queue(wait_address, &entry->wait);
}
能看到在系统调用中,将会通过add_wait_queue添加到poll中的等待队列。当注册到poll系统调用的sync_file执行完poll_wait后,将会进入到poll的循环中,直到fence有信号唤醒对其中的等待队列。
我们回到sync_file_poll方法中,当把等待队列注册到poll后,将会检测是否打开了POLL_ENABLE的标志位,一般是打开的,此时就会进入到fence_add_callback,为fence注册监听,添加到sync_timeline活跃链表中,如果注册成功会先调用wake_up_all唤起所有的fence,最后进行fence_is_signaled,校验是否有需要进行唤醒的fence。
fence_add_callback fence注册唤醒回调
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/fence.c
int fence_add_callback(struct fence *fence, struct fence_cb *cb,
fence_func_t func)
{
unsigned long flags;
int ret = 0;
bool was_set;
if (WARN_ON(!fence || !func))
return -EINVAL;
if (test_bit(FENCE_FLAG_SIGNALED_BIT, &fence->flags)) {
INIT_LIST_HEAD(&cb->node);
return -ENOENT;
}
spin_lock_irqsave(fence->lock, flags);
was_set = test_and_set_bit(FENCE_FLAG_ENABLE_SIGNAL_BIT, &fence->flags);
if (test_bit(FENCE_FLAG_SIGNALED_BIT, &fence->flags))
ret = -ENOENT;
else if (!was_set) {
trace_fence_enable_signal(fence);
if (!fence->ops->enable_signaling(fence)) {
fence_signal_locked(fence);
ret = -ENOENT;
}
}
if (!ret) {
cb->func = func;
list_add_tail(&cb->node, &fence->cb_list);
} else
INIT_LIST_HEAD(&cb->node);
spin_unlock_irqrestore(fence->lock, flags);
return ret;
}
能看到,实际上fence结构体中有flag标志在控制整个流程。
- 1.如果flags是FENCE_FLAG_SIGNALED_BIT,则说明fence已经唤醒,没必要继续下去。
- 2.如果FENCE_FLAG_SIGNALED_BIT,如果是从不允许唤醒到运行唤醒,则进行fence enable_signaling操作的校验,校验失败说明添加active_list失败;并调用fence_signal_locked进行唤醒。
- 3.最后为fence添加一个调用fence_signal_locked后回调方法指针,fence_check_cb_func。
fence enable_signaling
fence中enable_signaling的操作指针就是上面方法结构体的timeline_fence_enable_signaling。
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/sw_sync.c
static bool timeline_fence_enable_signaling(struct fence *fence)
{
struct sync_pt *pt = fence_to_sync_pt(fence);
struct sync_timeline *parent = fence_parent(fence);
if (timeline_fence_signaled(fence))
return false;
list_add_tail(&pt->active_list, &parent->active_list_head);
return true;
}
static bool timeline_fence_signaled(struct fence *fence)
{
struct sync_timeline *parent = fence_parent(fence);
return (fence->seqno > parent->value) ? false : true;
}
此时做了一件事情,判断sync_timeline此时的同步时间点和fence预计唤醒的同步时间点进行比较,发现fence的同步时间点大于sync_timeline当前同步时间点,不做任何事情,直接在添加回调步骤fence_signal_locked进行唤醒。否则说明还没到fence需要唤醒的时间点,就会把fence对应的sync_pt添加到sync_timeline的active_list。
fence的唤醒机制
经过上述的阻塞原理理解后,我们在对fence唤醒原理进行解析。在本文中,通过sync_wait进行阻塞后,唤醒的时机暂时只看到了三个:
- 1.当hwc执行完渲染屏幕操作之前
- 2.当hwc执行完渲染屏幕操作之后。
- 3.添加到sync_wait进行阻塞,也会首先进行校验,可能会进行唤醒。
先来看当fence需要唤醒时候,fence_is_signaled 唤醒校验机制
fence_is_signaled
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/include/linux/fence.h
static inline bool
fence_is_signaled(struct fence *fence)
{
if (test_bit(FENCE_FLAG_SIGNALED_BIT, &fence->flags))
return true;
if (fence->ops->signaled && fence->ops->signaled(fence)) {
fence_signal(fence);
return true;
}
return false;
}
- 1.校验的时候,判断到FENCE_FLAG_SIGNALED_BIT标志位,就直接返回true。
- 2.否则就调用fence的signaled进行判断,调用fence_signal,唤醒fence,能唤醒就返回true,唤醒失败则会返回false。
最后都会汇总到fence_signal中进行唤醒。timeline_fence_signaled则是比较记录在fence中的预计时间点和当前的sync_timeline时间点
fence_signal 唤醒fence
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/fence.c
int fence_signal(struct fence *fence)
{
unsigned long flags;
if (!fence)
return -EINVAL;
if (!ktime_to_ns(fence->timestamp)) {
fence->timestamp = ktime_get();
smp_mb__before_atomic();
}
if (test_and_set_bit(FENCE_FLAG_SIGNALED_BIT, &fence->flags))
return -EINVAL;
trace_fence_signaled(fence);
if (test_bit(FENCE_FLAG_ENABLE_SIGNAL_BIT, &fence->flags)) {
struct fence_cb *cur, *tmp;
spin_lock_irqsave(fence->lock, flags);
list_for_each_entry_safe(cur, tmp, &fence->cb_list, node) {
list_del_init(&cur->node);
cur->func(fence, cur);
}
spin_unlock_irqrestore(fence->lock, flags);
}
return 0;
}
实际上很简单,就是调用fence中注册在回调队列的回调函数fence_check_cb_func。
static void fence_check_cb_func(struct fence *f, struct fence_cb *cb)
{
struct sync_file *sync_file;
sync_file = container_of(cb, struct sync_file, cb);
wake_up_all(&sync_file->wq);
}
最后调用wake_up_all唤醒fence对应的等待队列。
小结
用一幅图总结整个fence在内核中的设计:
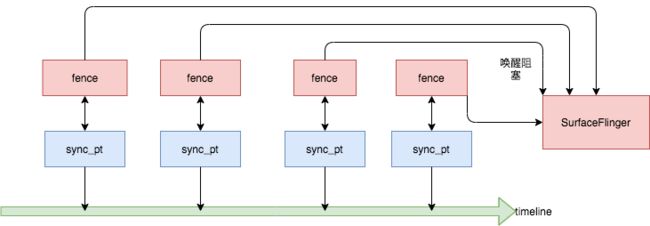
至此fence的阻塞唤醒原理已经明白了。但是仅仅如此,我们只需要一个fence就好,只需要等待在屏幕渲染之前,以及屏幕渲染之后即可,无论有多少线程来了,我们都可以进行poll的阻塞,等到drm渲染屏幕结束。这样能够处理解耦合,为什么需要嵌入到SF的图元合成渲染流程中呢?
实际上这里面还因为有Client的绘制类型,也就是OpenGL es的绘制。因为OpenGL es实际上是以一条条命令输送给GPU进行计算,是一个异步的过程;除非使用glFlush把命令一口气推给GPU完成,但是会造成阻塞,使得CPU利用率低。
因此,fence还会对OpenGL es的绘制在在关键的步骤进行等待,防止后面出现异常。
首先来看看OpenGL es是如何接洽fence的。我们看看SF中管理OpenGL es操作的RenderEngine类。
bool RenderEngine::waitFence(base::unique_fd fenceFd) {
if (!GLExtensions::getInstance().hasNativeFenceSync() ||
!GLExtensions::getInstance().hasWaitSync()) {
return false;
}
EGLint attribs[] = {EGL_SYNC_NATIVE_FENCE_FD_ANDROID, fenceFd, EGL_NONE};
EGLSyncKHR sync = eglCreateSyncKHR(mEGLDisplay, EGL_SYNC_NATIVE_FENCE_ANDROID, attribs);
if (sync == EGL_NO_SYNC_KHR) {
return false;
}
// fenceFd is now owned by EGLSync
(void)fenceFd.release();
eglWaitSyncKHR(mEGLDisplay, sync, 0);
EGLint error = eglGetError();
eglDestroySyncKHR(mEGLDisplay, sync);
if (error != EGL_SUCCESS) {
return false;
}
return true;
}
大致操作如下三个操作:
- 1.eglCreateSyncKHR 传入sync_file的句柄在OpenGL es中创建sync。
- 2.eglWaitSyncKHR 进行fence的等待。
- 3.eglDestroySyncKHR 销毁OpenGL es中的fence对象。
老规矩,我们虽然没有各大厂商的源码,但是可以看软件模拟的OpenGL es的机制来一窥究竟。由于libaegl的sync是直接同步的,就算是如其他如模拟器的我们看不到更近一步实现。
不过倒是可以从入口推导一二,在OpenGL es中eglCreateSyncKHR方法实际上是在OpenGL es中创建一个对应的fence的同步栅对象,eglWaitSyncKHR通过管道发送到OpenGL es中进行阻塞等待,直到OpenGL es的操作完成后,将会解开阻塞执行eglDestroySyncKHR方法释放OpenGL es中对应fence的同步栅对象。
Fence 在SF图元合成中状态的流转
明白了fence的基本原理,我们可以进一步的探索整个SF的中fence在其中处于什么角色。
首先,我们必须清楚一点。从启动到屏幕的第一帧的渲染,fence是不会有任何效果的。因为此时fence还没有经过hwc_set给fence进行赋值。但是到了第二帧开始,已经存在的Layer已经经过了hwc_set的赋值,存在Layer的releaseFence中。
我们来看看在SF中核心的4个流程:
-
- dequeueBuffer GraphicBuffer的出队
-
- queueBuffer GraphicBuffer的入队
-
- updateTexImage GraphicBuffer 消费
-
- GraphicBuffer的释放
Fence 在 dequeueBuffer 参与的角色
我们先来看看Surface中的lock方法,这个方法是onDraw方法之前,ViewRootImpl绘制之前进行调用。这个方法会调用IGraphicBufferProducer的dequeue方法。
我们只关注其核心的方法:
文件:/frameworks/native/libs/gui/Surface.cpp
status_t Surface::lock(
ANativeWindow_Buffer* outBuffer, ARect* inOutDirtyBounds)
{
...
ANativeWindowBuffer* out;
int fenceFd = -1;
status_t err = dequeueBuffer(&out, &fenceFd);
...
void* vaddr;
status_t res = backBuffer->lockAsync(
GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN,
newDirtyRegion.bounds(), &vaddr, fenceFd);
...
if (res != 0) {
err = INVALID_OPERATION;
} else {
mLockedBuffer = backBuffer;
outBuffer->width = backBuffer->width;
outBuffer->height = backBuffer->height;
outBuffer->stride = backBuffer->stride;
outBuffer->format = backBuffer->format;
outBuffer->bits = vaddr;
}
}
return err;
}
fence参与的步骤有2个:
- 1.BufferQueueProducer 的dequeueBuffer
-
- GraphicBufferMapper的lockAsync 进行本进程对ion同一段page进行映射的时候,也会进行fence的等待。
BufferQueueProducer dequeueBuffer
文件:/frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
ATRACE_CALL();
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
mConsumerName = mCore->mConsumerName;
...
eglDisplay = mSlots[found].mEglDisplay;
eglFence = mSlots[found].mEglFence;
// Don't return a fence in shared buffer mode, except for the first
// frame.
*outFence = (mCore->mSharedBufferMode &&
mCore->mSharedBufferSlot == found) ?
Fence::NO_FENCE : mSlots[found].mFence;
...
} // Autolock scope
...
if (eglFence != EGL_NO_SYNC_KHR) {
EGLint result = eglClientWaitSyncKHR(eglDisplay, eglFence, 0,
1000000000);
// If something goes wrong, log the error, but return the buffer without
// synchronizing access to it. It's too late at this point to abort the
// dequeue operation.
if (result == EGL_FALSE) {
BQ_LOGE("dequeueBuffer: error %#x waiting for fence",
eglGetError());
} else if (result == EGL_TIMEOUT_EXPIRED_KHR) {
BQ_LOGE("dequeueBuffer: timeout waiting for fence");
}
eglDestroySyncKHR(eglDisplay, eglFence);
}
...
return returnFlags;
}
在dequeue这个进行的时候,会判断OpenGL es对应的eglFence是否有效,有效,则说明上一帧的OpenGL es中有部分工作还没有完成,就进行eglClientWaitSyncKHRfence的等待,直到OpenGL es中的唤醒,最后销毁。
GraphicBufferMapper的lockAsync
这个方法实际上是对GraphicBuffer句柄对应在ion驱动中page页进行一次映射。
我们直接看对应Hal层源码:
文件:/hardware/interfaces/graphics/mapper/2.0/utils/passthrough/include/mapper-passthrough/2.0/Gralloc0Hal.h
Error lock(const native_handle_t* bufferHandle, uint64_t cpuUsage,
const IMapper::Rect& accessRegion, base::unique_fd fenceFd,
void** outData) override {
int result;
void* data = nullptr;
if (mMinor >= 3 && mModule->lockAsync) {
result = mModule->lockAsync(mModule, bufferHandle, cpuUsage, accessRegion.left,
accessRegion.top, accessRegion.width, accessRegion.height,
&data, fenceFd.release());
} else {
waitFenceFd(fenceFd, "Gralloc0Hal::lock");
result =
mModule->lock(mModule, bufferHandle, cpuUsage, accessRegion.left, accessRegion.top,
accessRegion.width, accessRegion.height, &data);
}
if (result) {
return Error::BAD_VALUE;
}
*outData = data;
return Error::NONE;
}
static void waitFenceFd(const base::unique_fd& fenceFd, const char* logname) {
if (fenceFd < 0) {
return;
}
const int warningTimeout = 3500;
const int error = sync_wait(fenceFd, warningTimeout);
if (error < 0 && errno == ETIME) {
sync_wait(fenceFd, -1);
}
}
我们能看到这里分为高低两个版本,低版本只支持同步的处理,因此首先判断fenceFd大于等于说明fd有效,就存在对应的sync_file结构体。此时会进行sync_file的等待,直到上一帧处理完,fence才会被唤醒,允许Surface对ion内存进行映射修改。
而高版本支持异步处理,则不需要进行等待
记住dequeueBuffer步骤中,此时是上一帧正在绘制,赋值在Layer中的releaseFence中。也就是Fence处于release状态。
Fence 在queueBuffer中参与的角色
文件:/frameworks/native/libs/gui/Surface.cpp
当映射好,通过了onDraw对Canvas绘制后,将会调用unlockAndPost发送。
status_t Surface::unlockAndPost()
{
if (mLockedBuffer == 0) {
return INVALID_OPERATION;
}
int fd = -1;
status_t err = mLockedBuffer->unlockAsync(&fd);
err = queueBuffer(mLockedBuffer.get(), fd);
mPostedBuffer = mLockedBuffer;
mLockedBuffer = 0;
return err;
}
这里分为两个步骤:
- 1.unlockAsync GraphicBufferMapper如果是高版本则解开fence的同步,接着会调用对应gralloc的unlock方法,解开当前进程对应ion内存的映射,释放虚拟内存。
- 2.queueBuffer SF的queueBuffer,进入mQueueItem中准备被消费
GraphicBufferMapper unlock
Error unlock(const native_handle_t* bufferHandle, base::unique_fd* outFenceFd) override {
int result;
int fenceFd = -1;
if (mMinor >= 3 && mModule->unlockAsync) {
result = mModule->unlockAsync(mModule, bufferHandle, &fenceFd);
} else {
result = mModule->unlock(mModule, bufferHandle);
}
outFenceFd->reset(fenceFd);
return result ? Error::BAD_VALUE : Error::NONE;
}
这个过程中,如果对应的高版本gralloc模块支持异步处理,则会在unlock进行fence的等待唤醒,否则直接解开映射。
这个过程实际上是把整个过程推后到queueBuffer发送之前。
BufferQueueProducer queueBuffer
文件:/frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
int64_t requestedPresentTimestamp;
bool isAutoTimestamp;
android_dataspace dataSpace;
Rect crop(Rect::EMPTY_RECT);
int scalingMode;
uint32_t transform;
uint32_t stickyTransform;
sp acquireFence;
bool getFrameTimestamps = false;
....
item.mFrameNumber = currentFrameNumber;
item.mSlot = slot;
item.mFence = acquireFence;
item.mFenceTime = acquireFenceTime;
item.mIsDroppable = mCore->mAsyncMode ||
mCore->mDequeueBufferCannotBlock ||
(mCore->mSharedBufferMode && mCore->mSharedBufferSlot == slot);
item.mSurfaceDamage = surfaceDamage;
item.mQueuedBuffer = true;
...
VALIDATE_CONSISTENCY();
...
int connectedApi;
sp lastQueuedFence;
{ // scope for the lock
...
lastQueuedFence = std::move(mLastQueueBufferFence);
mLastQueueBufferFence = std::move(acquireFence);
mLastQueuedCrop = item.mCrop;
mLastQueuedTransform = item.mTransform;
++mCurrentCallbackTicket;
mCallbackCondition.broadcast();
}
// Wait without lock held
if (connectedApi == NATIVE_WINDOW_API_EGL) {
// Waiting here allows for two full buffers to be queued but not a
// third. In the event that frames take varying time, this makes a
// small trade-off in favor of latency rather than throughput.
lastQueuedFence->waitForever("Throttling EGL Production");
}
...
return NO_ERROR;
}
在这个过程,我们能够注意到,此时fence的名字已经改成了acquireFence。此时就代表了Fence已经更改成acquire状态。同时记录当前的fence为mLastQueueBufferFence。
当下一个绘制的GraphicBuffer进来之后,如果是通过OpenGL es的swapBuffer触发的queueBuffer操作,则会进行lastQueuedFence的waitForever进行阻塞。
这里面的内在逻辑是什么呢?如果通读我之前写文章,其实发现OpenGL es在eglswapBuffer会进行queueBuffer以及Surface每一次通过unlockAndPost之后会把Canvas中的数据通过queueBuffer进行GraphicBuffer的队列压入。
提示,通过OpenGL es 入队的api都是NATIVE_WINDOW_API_EGL,而通过Canvas的绘制好后unlockAndPost的操作对应的api是NATIVE_WINDOW_API_CPU。
这样就会造成一个问题,两个不同的对象在不断的开始生产各自图元进行入队。当我们已经把一个通过Skia绘制好的GraphicBuffer传入了hwc_set并初始化好fence后,OpenGL es绘制的图元到来会检测上一帧还没绘制就会等到上一帧绘制好后才能继续。
因此,这里意味着OpenGL es生产的图元和一次性和CPU生产的图元一起运到后续的步骤进行合成。
其实这就是为了处理OpenGL es绘制和CPU绘制每一帧花费的时间不同,一般的OpenGL es都是借助GPU进行绘制,因此会快上很多。后面有提到,Android希望每一帧都卡在16.6ms左右也就是60fps中,如果GPU太快,而CPU太慢就会出现因为GPU太快导致SF刷新的频率过高,从而使得性能消耗过大。
如下图:
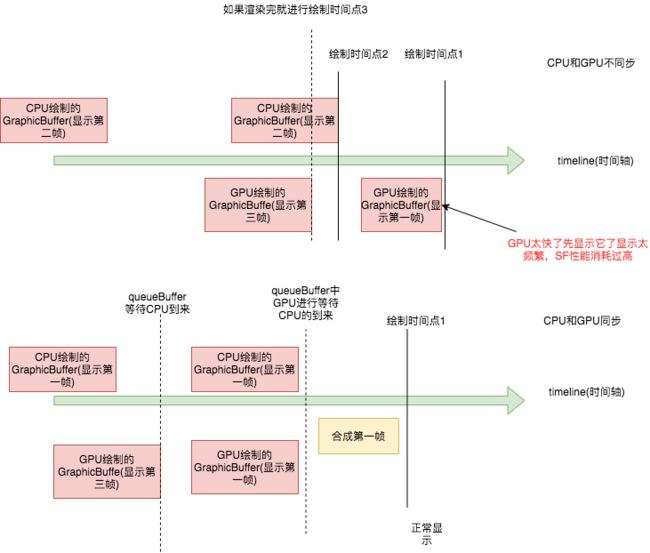
这就是源码注解中,为什么Google经过权衡之后,偏向选择牺牲SF的吞吐量从而降低刷新频率的原因。
Fence 在 updateTexImage 参与的角色
在acquireBuffer过程中实际上就是选定需要跳多少帧之后需要显示的GraphicBuffer,实际上Fence真正起作用的是它的调用者updateTexImage。
文件:/frameworks/native/services/surfaceflinger/BufferLayerConsumer.cpp
status_t BufferLayerConsumer::updateTexImage(BufferRejecter* rejecter, const DispSync& dispSync,
bool* autoRefresh, bool* queuedBuffer,
uint64_t maxFrameNumber) {
Mutex::Autolock lock(mMutex);
...
// Release the previous buffer.
err = updateAndReleaseLocked(item, &mPendingRelease);
if (err != NO_ERROR) {
return err;
}
if (!SyncFeatures::getInstance().useNativeFenceSync()) {
err = bindTextureImageLocked();
}
return err;
}
在这个过程中,fence参与了两件事情:
- 1.updateAndReleaseLocked 释放前一帧的GraphicBuffer,如果打开了useNativeFenceSync标志位则会合并OpenGL es和SF的fence。
- 2.如果关闭了useNativeFenceSync标志位,bindTextureImageLocked等待OpenGL es在这个过程中完成消费需要的OpenGL es的命令。
updateAndReleaseLocked fence在释放GraphicBuffer的角色
此时已经从多个线程通过Handler转化到主线程中执行的步骤,因此到这一步需要释放上一帧的GraphicBuffer时候,需要把当前要释放的GraphicBuffer对应的fence阻塞起来,避免在dequeueBuffer的时候拿出来使用。主要对应其GraphicBufferMapper的lockAsync的方法。
status_t BufferLayerConsumer::updateAndReleaseLocked(const BufferItem& item,
PendingRelease* pendingRelease) {
status_t err = NO_ERROR;
int slot = item.mSlot;
// Do whatever sync ops we need to do before releasing the old slot.
if (slot != mCurrentTexture) {
err = syncForReleaseLocked();
...
}
sp nextTextureImage = mImages[slot];
// release old buffer
if (mCurrentTexture != BufferQueue::INVALID_BUFFER_SLOT) {
if (pendingRelease == nullptr) {
status_t status =
releaseBufferLocked(mCurrentTexture, mCurrentTextureImage->graphicBuffer());
if (status < NO_ERROR) {
BLC_LOGE("updateAndRelease: failed to release buffer: %s (%d)", strerror(-status),
status);
err = status;
// keep going, with error raised [?]
}
} else {
pendingRelease->currentTexture = mCurrentTexture;
pendingRelease->graphicBuffer = mCurrentTextureImage->graphicBuffer();
pendingRelease->isPending = true;
}
}
// Update the BufferLayerConsumer state.
...
return err;
}
这里面会判断不是当前绘制的GraphicBuffer不是上一次对应的索引,则会释放上一次索引对应的GraphicBuffer。如果是同一个索引,就要判断到mCurrentTexture已经有数据,则会添加到pendingRelease等到合成完毕后再释放,pendingRelease为空直接释放上一帧的内容。
fence 在图元绑定和释放处理的逻辑
其中的如果slot不是一致的,会调用:
- 1.syncForReleaseLocked 合并同步当前图元对应的fence
- 2.releaseBufferLocked 释放图元
syncForReleaseLocked同步当前图元对应的fence逻辑
status_t BufferLayerConsumer::syncForReleaseLocked() {
BLC_LOGV("syncForReleaseLocked");
if (mCurrentTexture != BufferQueue::INVALID_BUFFER_SLOT) {
if (SyncFeatures::getInstance().useNativeFenceSync()) {
base::unique_fd fenceFd = mRE.flush();
if (fenceFd == -1) {
return UNKNOWN_ERROR;
}
sp fence(new Fence(std::move(fenceFd)));
status_t err = addReleaseFenceLocked(mCurrentTexture,
mCurrentTextureImage->graphicBuffer(), fence);
if (err != OK) {
return err;
}
}
}
return OK;
}
如果发现SF打开了OpenGL es的同步开关,此时会从RenderEngine中拿到对应OpenGL es中的fence同步栅,赋值给当前Fence对象,通过addReleaseFenceLocked把CPU和GPU的同步栅合并起来。
文件:/frameworks/native/libs/gui/ConsumerBase.cpp
status_t ConsumerBase::addReleaseFenceLocked(int slot,
const sp graphicBuffer, const sp& fence) {
...
auto currentStatus = mSlots[slot].mFence->getStatus();
...
auto incomingStatus = fence->getStatus();
...
if (currentStatus == incomingStatus) {
char fenceName[32] = {};
sp mergedFence = Fence::merge(
fenceName, mSlots[slot].mFence, fence);
if (!mergedFence.get()) {
mSlots[slot].mFence = fence;
return BAD_VALUE;
}
mSlots[slot].mFence = mergedFence;
} else if (incomingStatus == Fence::Status::Unsignaled) {
mSlots[slot].mFence = fence;
}
return OK;
}
文件:/frameworks/native/include/ui/Fence.h
inline Status getStatus() {
switch (wait(0)) {
case NO_ERROR:
return Status::Signaled;
case -ETIME:
return Status::Unsignaled;
default:
return Status::Invalid;
}
}
结合这两段代码,我们实际上能知道,这过程先通过wait方法,但是传入超时时间为0。换句话说通过不等待的poll阻塞方式,直接通过fence_is_signaled获取当前fence对应的状态。
此时发现从OpenGL es内部的fence和当前CPU对应的fence是一致的,就能合并两个fence。不是同一个对象,判断到GPU中的fence还没解开说明还有工作需要做,那就说明后面就不能只能释放。就把mSlots索引对应GraphicBuffer的Fence切换成GPU,在后面进行等待。
我们看看fence中merge做了什么?我们直接看内核中做的工作:
文件:https://github.com/yjy239/android_kernel_4.19/blob/a12d1ce91b8cccb239991af90daf46311b7ba975/drivers/dma-buf/sync_file.c
static struct sync_file *sync_file_merge(const char *name, struct sync_file *a,
struct sync_file *b)
{
struct sync_file *sync_file;
struct fence **fences, **nfences, **a_fences, **b_fences;
int i, i_a, i_b, num_fences, a_num_fences, b_num_fences;
sync_file = sync_file_alloc();
if (!sync_file)
return NULL;
a_fences = get_fences(a, &a_num_fences);
b_fences = get_fences(b, &b_num_fences);
if (a_num_fences > INT_MAX - b_num_fences)
return NULL;
num_fences = a_num_fences + b_num_fences;
fences = kcalloc(num_fences, sizeof(*fences), GFP_KERNEL);
if (!fences)
goto err;
for (i = i_a = i_b = 0; i_a < a_num_fences && i_b < b_num_fences; ) {
struct fence *pt_a = a_fences[i_a];
struct fence *pt_b = b_fences[i_b];
if (pt_a->context < pt_b->context) {
add_fence(fences, &i, pt_a);
i_a++;
} else if (pt_a->context > pt_b->context) {
add_fence(fences, &i, pt_b);
i_b++;
} else {
if (pt_a->seqno - pt_b->seqno <= INT_MAX)
add_fence(fences, &i, pt_a);
else
add_fence(fences, &i, pt_b);
i_a++;
i_b++;
}
}
for (; i_a < a_num_fences; i_a++)
add_fence(fences, &i, a_fences[i_a]);
for (; i_b < b_num_fences; i_b++)
add_fence(fences, &i, b_fences[i_b]);
if (i == 0)
fences[i++] = fence_get(a_fences[0]);
if (num_fences > i) {
nfences = krealloc(fences, i * sizeof(*fences),
GFP_KERNEL);
if (!nfences)
goto err;
fences = nfences;
}
if (sync_file_set_fence(sync_file, fences, i) < 0) {
kfree(fences);
goto err;
}
strlcpy(sync_file->name, name, sizeof(sync_file->name));
return sync_file;
err:
fput(sync_file->file);
return NULL;
}
- 1.get_fences 获取sync_file中的对象。此时可能是单一时间点的fence,也可能含有多个时间点的fence_array.
- 2.不管是哪一种,由于fence的序列是基于同一个sync_timeline为基准不断的单调递增的。因此可以简单通过同步点的大小,找出每一个fence此时对应的时间点顺序。把没有达到释放时间的fence全部合并起来,变成一个fence_array。
这个唤醒逻辑如下:
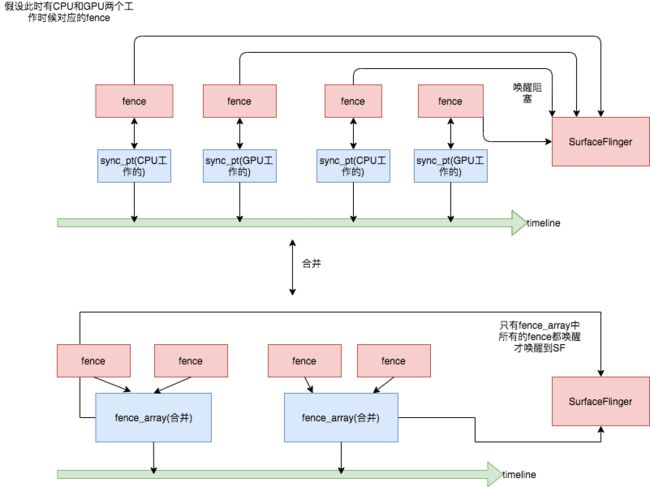
当进行了OpenGL es和CPU的fencemerge之后,我们可以看updateTexImage中bindTextureImageLocked的逻辑。
bindTextureImageLocked 中fence进行分开或者合并管理
bindTextureImageLocked的使用时机有两处:
- 1.第一处是在消费图元的时候,如果SF打开了对了OpenGL es的sync同步信号的等待,就会进行在updateTexImage直接执行。
- 2.第二处在BufferLayer的onDraw方法中直接调用。
为什么这2种处理会出现差异呢?useNativeFenceSync这个标志位实际上是处理OpenGL es对应的fence同步栅是否是兼容Android的EGL_ANDROID_native_fence_sync。
兼容那么Android将会在syncForReleaseLocked提前合并OpenGL es中的fence作为同步的标准之一,提前绑定一个RE::Image到SF中。
但是如果不兼容,那就必须分开同步管理,也就是在onDraw中进行等待OpenGL es中合成好,才能继续下一步,其中的核心就是最后的doFenceWaitLocked方法。
status_t BufferLayerConsumer::doFenceWaitLocked() const {
if (!mRE.isCurrent()) {
return INVALID_OPERATION;
}
if (mCurrentFence->isValid()) {
if (SyncFeatures::getInstance().useWaitSync()) {
base::unique_fd fenceFd(mCurrentFence->dup());
if (fenceFd == -1) {
return -errno;
}
if (!mRE.waitFence(std::move(fenceFd))) {
return UNKNOWN_ERROR;
}
} else {
status_t err = mCurrentFence->waitForever("BufferLayerConsumer::doFenceWaitLocked");
if (err != NO_ERROR) {
return err;
}
}
}
return NO_ERROR;
}
这里有两个判断:
- 1.如果OpenGL es支持fence同步栅,则会通过RenderEngine自己进行等待处理。
- 2.如果OpenGL es支持Android的fence同步栅,此时已经合并了,直接对着合并后的fence进行等待即可。
releaseBufferLocked 释放图元中fence参与的角色
releaseBufferLocked 执行的时机有2处:
- 1.updateAndReleaseLocked 如果没有pendingReleaseFence,则直接释放上一帧的GraphicBuffer
- 2.当SF的合成完成后,进行postComposition收尾工作,会遍历mLayersWithQueuedFrames(可视的Layer)调用releasePendingBuffer方法,该方法判断mPendingRelease的isPending是否为true。一般都为true,因为每一次绘制完都会调用releasePendingBuffer生成一个PendingRelease对象,告诉updateAndRelease需要延迟销毁。
bool BufferLayerConsumer::releasePendingBuffer() {
if (!mPendingRelease.isPending) {
return false;
}
Mutex::Autolock lock(mMutex);
status_t result =
releaseBufferLocked(mPendingRelease.currentTexture, mPendingRelease.graphicBuffer);
if (result < NO_ERROR) {
...
}
mPendingRelease = PendingRelease();
return true;
}
为什么需要一个延时销毁呢?主要是因为在SF中的GraphicBuffer有一种模式是共享模式,这种模式同样需要进行阻塞,不同的是,SF会不断的复用当前这个GraphicBuffer交给应用程序进行渲染。
正因为这种特殊原因,需要每一次绘制完后进行才判断,而不是粗暴的直接在选取完需要绘制下一帧之前直接释放掉。
有点偏题了,接下来看看释放的核心方法:
文件:/frameworks/native/libs/gui/BufferQueueConsumer.cpp
status_t BufferQueueConsumer::releaseBuffer(int slot, uint64_t frameNumber,
const sp& releaseFence, EGLDisplay eglDisplay,
EGLSyncKHR eglFence) {
ATRACE_CALL();
ATRACE_BUFFER_INDEX(slot);
if (slot < 0 || slot >= BufferQueueDefs::NUM_BUFFER_SLOTS ||
releaseFence == NULL) {
return BAD_VALUE;
}
sp listener;
{ // Autolock scope
Mutex::Autolock lock(mCore->mMutex);
if (frameNumber != mSlots[slot].mFrameNumber &&
!mSlots[slot].mBufferState.isShared()) {
return STALE_BUFFER_SLOT;
}
if (!mSlots[slot].mBufferState.isAcquired()) {
return BAD_VALUE;
}
mSlots[slot].mEglDisplay = eglDisplay;
mSlots[slot].mEglFence = eglFence;
mSlots[slot].mFence = releaseFence;
mSlots[slot].mBufferState.release();
if (!mCore->mSharedBufferMode && mSlots[slot].mBufferState.isFree()) {
mSlots[slot].mBufferState.mShared = false;
}
if (!mSlots[slot].mBufferState.isShared()) {
mCore->mActiveBuffers.erase(slot);
mCore->mFreeBuffers.push_back(slot);
}
listener = mCore->mConnectedProducerListener;
mCore->mDequeueCondition.broadcast();
VALIDATE_CONSISTENCY();
} // Autolock scope
if (listener != NULL) {
listener->onBufferReleased();
}
return NO_ERROR;
}
实际上很简单,这个方法先把当前fence名字改成releaseFence说明此时fence已经进入会release状态。接着保存当前的GraphicBuffer等,判断到如果不是共享状态,则会把对应的slot从mActiveBuffers放到mFreeBuffers中,等到下一次dequeue时候使用,最后唤醒同一个线程的dequeue的阻塞。
至此,整个SF中fence的状态的流转已经解析完全。
总结
fence本质上对应上内核中一个文件描述符sync_file,sync_file中有一个核心的fence结构体,用于预计释放的时间点。所有的fence都是以sync_timeline为基准进行递增的。
sync_timeline 作为内核记录已经渲染屏幕多少个时间点,每一次通过hwc_set都会递增一个时间点,并且会尝试的唤醒关联在sync_timeline中active_list中sync_pt的fence的阻塞。
当fence合并之后,将会调用fence_add_callback重新把fence_array中的时间点都加到对应的active_list中。不过这一次唤醒,就需要fence_array中所有的fence都唤醒了,才会唤醒阻塞。
能看到实际上这个过程其实有点像Java中的CyclicBarrier,不过比他灵活多了。关于图,我已经在上文已经画过了,接下来让我们重点关注fence在SurfaceFlinger中的状态流转。
先来看看GraphicBuffer中在SF的状态流转

接着再来看看fence在整个SF中各个流程中担当了什么角色:
dequeueBuffer GraphicBuffer的从SF出队到app进行绘制流程中
-
- 调用BufferQueueProducer的dequeue方法,获取在BufferQueueProducer中空闲的slot对应的GraphicBuffer,这个过程中,通过fence会等待OpenGL es在还没有完成的工作。
-
- 调用GraphicBufferMapper的lockAsync方法,对ion驱动中的内存地址进行一次内存映射,找到分配出来的图元绘制地址。这个过程如果是低版本或者不支持lockAsync,则会进行等待上一帧GraphicBuffer的fence阻塞,直到对应该GraphicBuffer完成了release操作,才可能完成Surface的lock操作。
queueBuffer GraphicBuffer在应用绘制好后进入SF进程
-
- 首先Surface在unlockAndPost中先对GraphicBuffer解开内存映射,如果是高版本的gralloc,则会进行阻塞,等到绘制的内容同步到gralloc中,才解开映射。
-
- 调用BufferQueueProducer的queueBuffer方法,把fence转化为acquire状态,GPU(OpenGL es)的完成这一帧的工作会等待CPU(Skia)的绘制工作,避免频率过快导致耗能过高。
GraphicBuffer 消费和合成图元
该方法会通过acquireBuffer决定跳多少帧,显示哪一帧的图元。之后会调用updateAndReleaseLocked方法,主要做了事情:
-
- syncForReleaseLocked判断是否需要合并OpenGL es是否支持Android的fence。支持则会把OpenGL es的fence和CPU的fence合并起来。如果合并了,则可以统一处理OpenGL es和CPU的fence的同步栅唤醒事件,提前执行bindTextureImageLocked方法,把图元交给OpenGL es中进一步处理,交给doFenceWaitLocked进行阻塞等待合并后的fence。
2.如果此时Client的绘制模式,当执行到了Layer的onDraw的方法时候,也会执行bindTextureImageLocked,不过,如果此时OpenGL es不支持Android的fence,调用doFenceWaitLocked此时是单独阻塞了OpenGL es中的fence。
3.无论谁都是doFenceWaitLocked进行阻塞,这个方法实际上是等待OpenGL es把GraphicBuffer绑定到OpenGL es操作的GPU中。只有同步了这个步骤了,之后无论HWC还是OpenGL es的绘制才能同步且正确。
当所有绘制完的,把已经释放过的fence会合并到retireFenceFd保存起来。
释放图元因为有Share模式的图元将会把事释放事件从updateAndReleaseLocked推迟到SF执行完合成步骤的postComposition开始释放。
GraphicBuffer的释放
做的事情很简单,就是一件事情。把GraphicBuffer对应的索引放入mFreeSlots集合中等待是dequeue使用,同时把fence只是名字上转化为release状态。
最后老规矩,我们用一幅图总结:
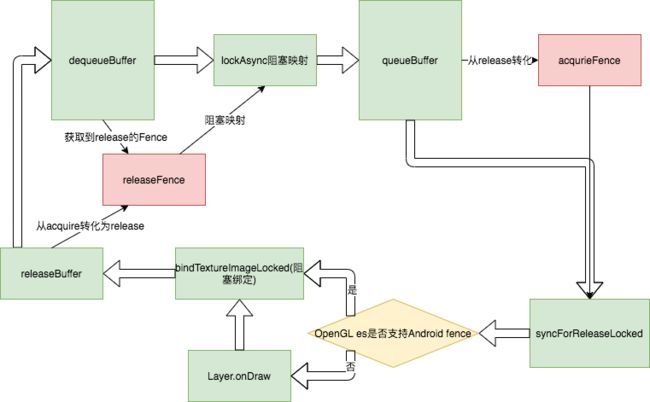
实际上,总结一句话,Fence的acquire状态其实是阻塞什么时候可以被消费,什么时候可以被渲染到屏幕;而Fence的release状态则是控制什么时候可以出队给应用进行绘制,什么时候可以被映射到内存。
同时也会依据OpenGL es是否兼容Android的fence而是否提前设置本地纹理。
后话
最后感谢这些大佬:
http://tangzm.com/blog/?p=167
https://blog.csdn.net/w401229755/article/details/39228535
研究fence的时候,其实花了很大的经历在阅读GPU中vblank的fence的机制。因为GPU中也有fence机制,它的核心思想是注册了GPU的irq中断用来唤醒fence。由于下意识的认为GPU中的同步栅和SurfaceFlinger的fence应该也是同步得到,在drm_hwcomposer花了大量的时间找了两者的联系。事实上两者的联系不大,导致做了大量的无用功。
drm_hwcomposer说到底设计上还是不足。使用了阻塞的方式进行drmModeAtomicCommit提交,白白浪费了drm的多线程和SF的多线程模型。仅仅只是完成提交渲染后才解开阻塞。其实阅读源码过程中,drm驱动对应不同的GPU的实现也会在实现自己的fence,可以通过OUT_FENCE_PTR的属性获取这个fence,从而做到更加流程的SurfaceFlinger流程。而实际上在msm8960这些不太新的驱动反而做到了fence同步了GPU自己fb驱动中的fence。
下一篇文章就是SF最后一篇文章,看看SurfaceFlinger是如何处理同步信号,如何把同步信号Vsync发送应用的。