https://www.zhihu.com/question/22764869
9 个回答
默认排序

知乎用户
1459 人赞同了该回答
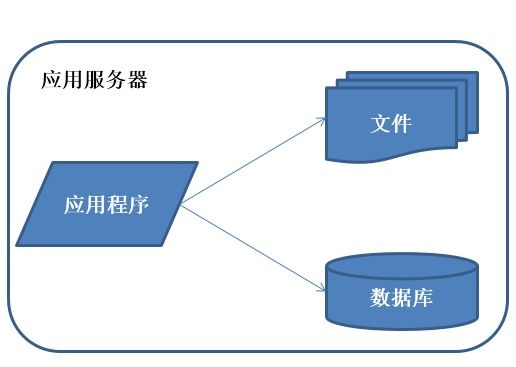





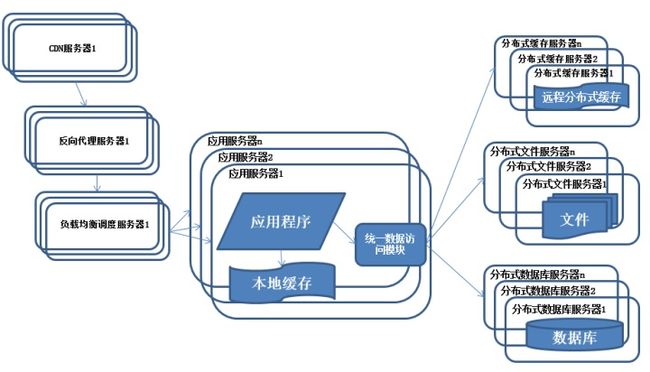





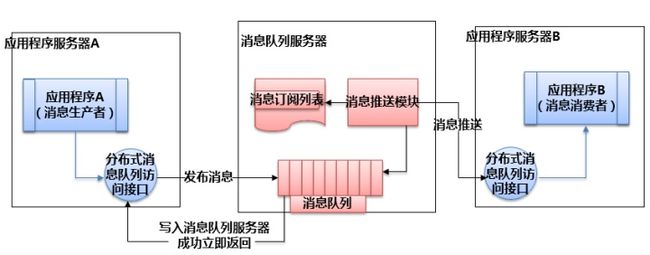
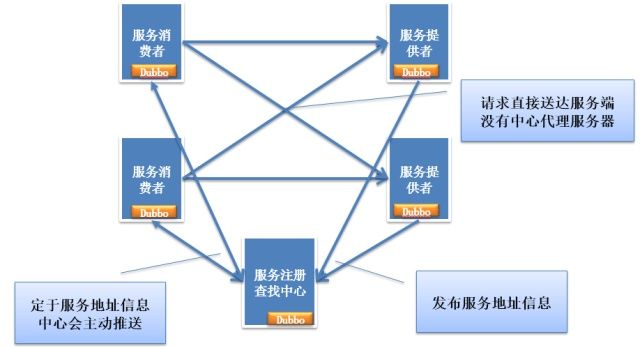










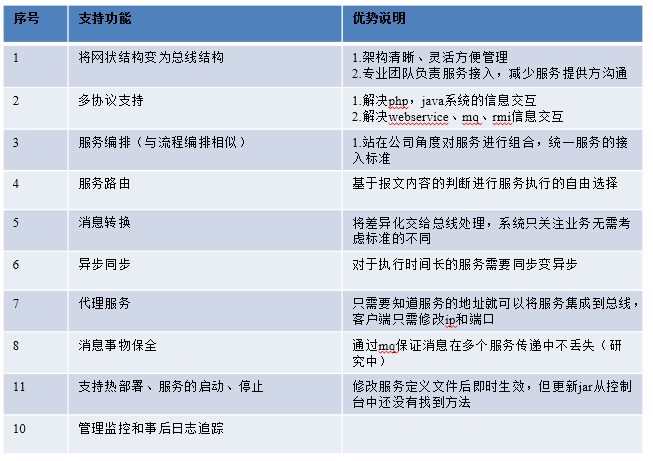

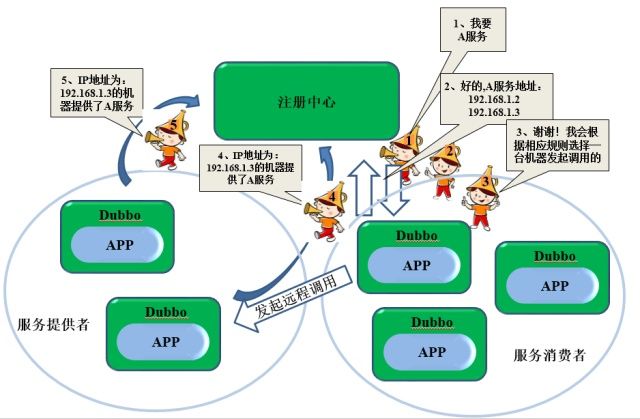
编辑于 2014-11-21
1.5K 50 条评论
收藏 感谢
收起
分享

用心阁
195 人赞同了该回答
编辑于 2015-10-28
195 10 条评论
收藏 感谢
收起
分享

林建入
250 人赞同了该回答
编辑于 2015-08-02
250 53 条评论
收藏 感谢
收起
分享

暗灭
2 人赞同了该回答
发布于 2016-11-20
2 1 条评论
收藏 感谢
分享
肖进
1 人赞同了该回答
编辑于 2017-06-16
1 添加评论
收藏 感谢
分享

大王
2 人赞同了该回答
发布于 2016-06-10
2 1 条评论
收藏 感谢
分享

mauersu
编辑于 2016-02-29
0 添加评论
收藏 感谢
分享

Java程序员
1 人赞同了该回答