1.Redis
1.1 特点
- 数据模型简单(键值对)
- 数据库性能较高
- 数据的弱一致性(比如一个数据在不断的增加,当他显示的是1的时候,真实的数据可能已经变成2了,当他显示是2的时候,真是的数据可能已经变成4了)
减弱了一致性换取了更好的性能
数据都是缓存在内存中,可以周期的把更新的数据写入磁盘或者追加到日志文件中(AOF)
1.2 优缺点
优点:
- 数据高并发读写
- 海量数据的高效率存储和访问
- 数据的可扩展性(可以添加节点)和高可用性(某个节点坏了也不怕)
缺点: - 弱一致性
- 无法做到太复杂的关系数据库模型
2. 安装
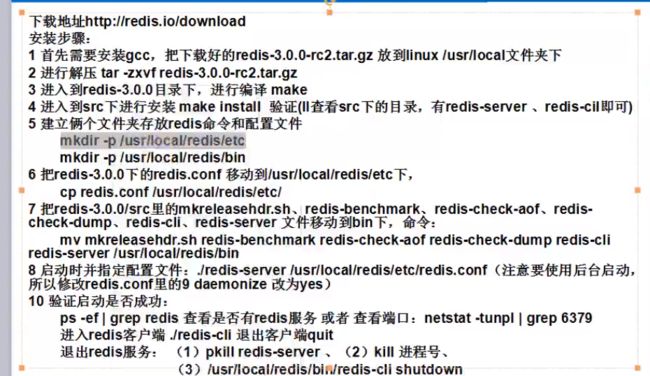
设置密码(没啥必要):redis.conf
requirepass ****
登录:redis-cli -a ****
3. 数据类型
展示所有key:keys *
清空所有key:flushdb
3.1 String
- set name zhangsan:给name赋值zhangsan,没有name,就新增name
- setnx name zhangsan:如果没有name这个key,就创建并赋值,有name就什么都不做
- setex color 10 red:给color赋值red,有效期10秒,之后为nil(表示空)
-
setrange email 10 ww:把email的值从第10位开始替换
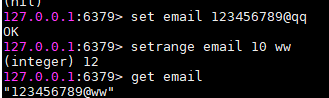 替换qq
替换qq - mset key1 value1 key2 value2。。。:同时设置多个
- getset email 111:先get email的值,然后设置email的值为111
-
incr key和decr key:对数值加1或者减1
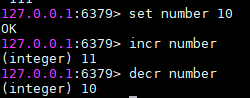 ++或者--
++或者-- - incrby key n和decrby key n:对数值加n或者减n。
-
append key xxx:追加字符串xxx
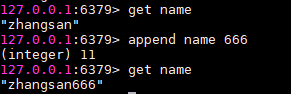 追加字符串
追加字符串 -
strlen key:获取value长度

3.2 hash
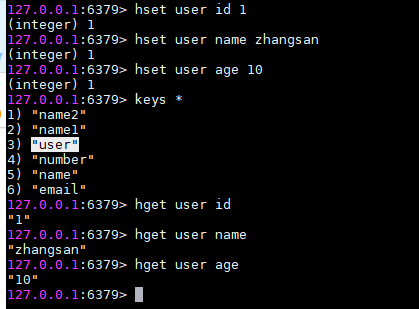
hmset,hmget批量存取

hsetnx:参考setnx
hincrby:参上
hdecrby:参上
hdel:删除hash的field
hkeys:列出hash的field
hlen:返回hash有多少个键
hvals:返回hash的所有value
hgetall:返回hash里面的所有key和value
3.3 list
- lpush:从头部加入,最先出来,全部元素都lpush的话,就相当于栈,先入后出
- rpush:从尾部加入,最后出来,全部元素都rpush的话,就相当于队列,先入先出
- lrange list名 0 -1:显示全部
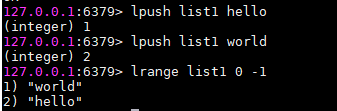

-
linsert list名 before "one" "three"
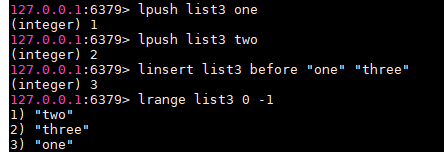 插入数据
插入数据
lset list名 0 “xx”:将第0个元素替换为xx
lrem list名 n “b”:删除list里面的n个“b”
ltrim list名 x y:保留list的第x位置到第y位置的值,其他的删除
lpop:从头部删除元素,并返回删除的元素
rpop:从尾部删除元素,并返回删除元素
- rpoplpush:把尾部的一个元素放到头
-lindex list名 n:返回n位置的元素
- llen list名:list的长度
3.4 set
string类型的无序集合(不允许有重复)
- smembers set1:查看set1的所有元素
- sadd set1 xxx:往set1添加xxx
- srem:删除元素
- spop:随机返回删除的key
- sdiff:返回两个集合的不同元素,哪个集合在前面就以哪个集合为标准
- sdiffstore set3 set1 set2:将set1和set2的不同元素(以set1为准),存储在set3里面
- sinter set1 set2:返回集合的交集
- sunion:取并集
- sunionstore set3 set1 set2:取并集,放到set3中
-
smove:将某个元素从一个集合剪切到另一个集合
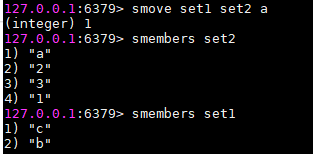 剪切
剪切 - scard:查看集合里元素个数
- sismember set1 a:判断a是不是set1的元素
- srandmember:随机返回一个元素
3.5 zset
有序的集合
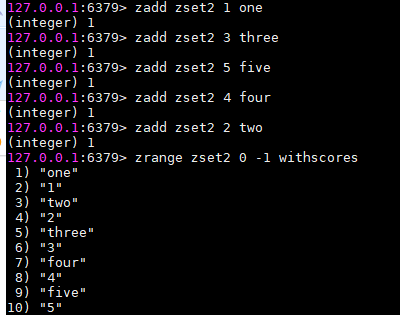
- zrange zset2 0 -1 withscores:查看zset2的所有元素(withscores把索引也显示出来,不加withscores,不显示索引)
- zadd zset2 2 two:在位置2添加元素two
- zrem zset2 one:删除zset2的one元素
- zincrby:自增,自减,参上
- zrangebyscore:找到指定区间范围的数据返回
- zremrangebyrank:删除1到1(只删除索引1)
- zremrangebyscore:删除指定的序号
4. 其他命令
exists key:是否存在key
-
expire设置某个key的过期时间,ttl查看剩余时间,时间结束之后,key就没有了
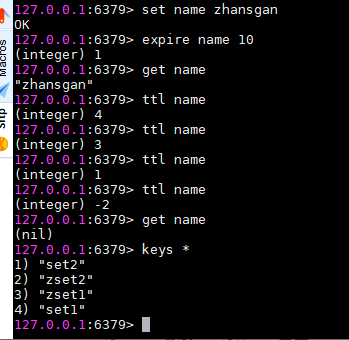 过期时间
过期时间 persist:取消过期时间,这个key就会一直存在了
select:选择数据库(0-15)
一共16个数据库,默认0move key 2:把key移动到第二个数据库中
randomkey:随机返回一个key
rename:重命名key
echo:打印
dbsize:查看数据库的key数量
info:查看数据库信息
config get:实时传储收到的请求(返回相关的配置信息)
config get *: 查看所有的配置信息(redis.conf)flushdb:清空当前数据库
flushall:清空所有数据库
5. 主从复制
配置,修改从机器的redis.conf配置文件
slaveof 192.168.60.134 6379
但是我配置了却没有作用,不知道为什么从机连不上主机,于是在一个机器上模拟运行多个redis
-
创建文件夹:
 创建主从文件夹
创建主从文件夹 - 复制redis.conf到三个文件夹并配置:
bind 192.168.60.137(本机ip)
设置port 6379,6380,6381
设置dir:比如6380:dir /usr/local/redis-zhucongfuzhi/cong-6380/
- 运行三个server实例(模拟三台机器)
../redis-3.0.1/bin/redis-server ./zhu-6379/redis.conf
../redis-3.0.1/bin/redis-cli -h 192.168.60.137 -p 6379
../redis-3.0.1/bin/redis-server ./cong-6380/redis.conf
../redis-3.0.1/bin/redis-cli -h 192.168.60.137 -p 6380
../redis-3.0.1/bin/redis-server ./cong-6381/redis.conf
../redis-3.0.1/bin/redis-cli -h 192.168.60.137 -p 6381
主机info:

从机info:
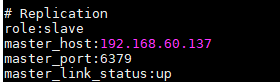
- 成功之后,从机将只能读不能写,主机写的东西会同步到从机
主机set 值,在主从机都可以拿到。
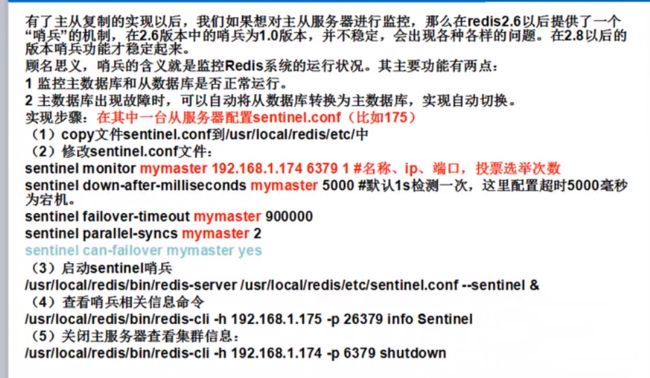
6.哨兵
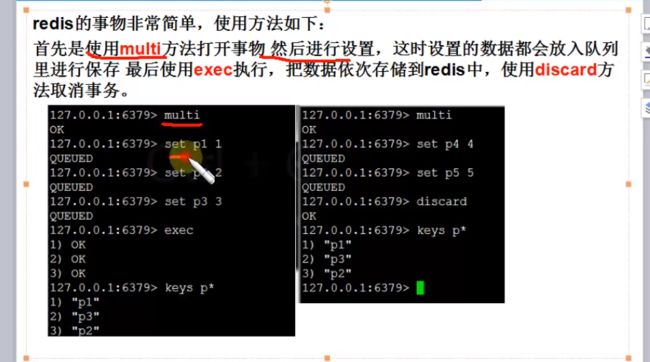
7. redis事务
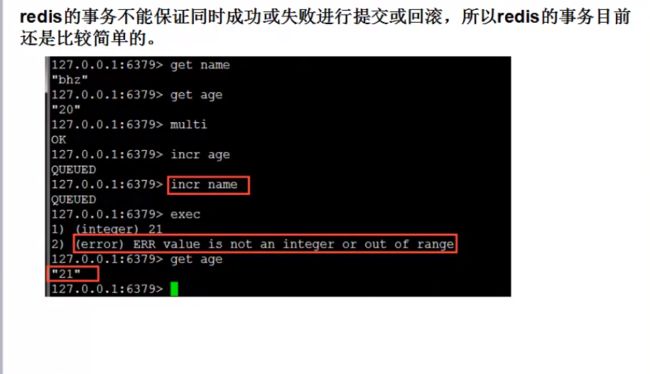
8.持久化机制
redis数据是保存在内存中的,持久化机制是指将内存中的数据保存在硬盘上
snapshotting(快照)
默认的方式,dump.rdb。隔一段时间写一次
在redis.conf文件设置超过n秒,或者超过m个key,则保存一次
比如:
save 900 1:900秒内超过一个key被修改,发起快照
save 300 10:300秒内超过10个key被修改,发起快照
快照有可能发生数据丢失-
append-only(aof)
日志文件:appendonly.aof
将数据库操作的记录在适当的时候保存在日志里面
开启aof:redis.conf文件:appendonly yes
适当的时候:- appendfsync always:有日志就写(常用)
- appendfsync everysec:每秒写一次磁盘
- appendfsync no:系统自己判断
开启aof,rdb就没有用了
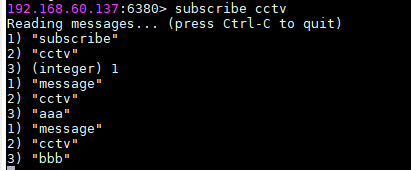
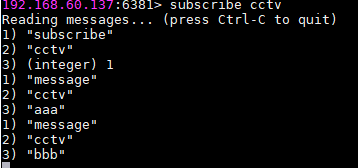
9.发布订阅
发布:publish cctv aaa
订阅:subscribe cctv
继续使用上面5使用的主从机:

10.java
package com.ithiema.jedis;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisTest {
//通过java程序访问redis数据库
@Test
//获得单一的jedis对象操作数据库
public void test1(){
//1、获得连接对象
Jedis jedis = new Jedis("192.168.186.131", 6379);
//2、获得数据
String username = jedis.get("username");
System.out.println(username);
//3、存储
jedis.set("addr", "北京");
System.out.println(jedis.get("addr"));
}
//通过jedis的pool获得jedis连接对象
@Test
public void test2(){
//0、创建池子的配置对象
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(30);//最大闲置个数
poolConfig.setMinIdle(10);//最小闲置个数
poolConfig.setMaxTotal(50);//最大连接数
//1、创建一个redis的连接池
JedisPool pool = new JedisPool(poolConfig, "192.168.186.131", 6379);
//2、从池子中获取redis的连接资源
Jedis jedis = pool.getResource();
//3、操作数据库
jedis.set("xxx","yyyy");
System.out.println(jedis.get("xxx"));
//4、关闭资源
jedis.close();
pool.close();
}
}
package com.ithiema.jedis;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisPoolUtils {
private static JedisPool pool = null;
static{
//加载配置文件
InputStream in = JedisPoolUtils.class.getClassLoader().getResourceAsStream("redis.properties");
Properties pro = new Properties();
try {
pro.load(in);
} catch (IOException e) {
e.printStackTrace();
}
//获得池子对象
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(Integer.parseInt(pro.get("redis.maxIdle").toString()));//最大闲置个数
poolConfig.setMinIdle(Integer.parseInt(pro.get("redis.minIdle").toString()));//最小闲置个数
poolConfig.setMaxTotal(Integer.parseInt(pro.get("redis.maxTotal").toString()));//最大连接数
pool = new JedisPool(poolConfig,pro.getProperty("redis.url") , Integer.parseInt(pro.get("redis.port").toString()));
}
//获得jedis资源的方法
public static Jedis getJedis(){
return pool.getResource();
}
public static void main(String[] args) {
Jedis jedis = getJedis();
System.out.println(jedis.get("xxx"));
}
}
存储和查询对象(带条件)
https://www.bilibili.com/video/av34488241/?p=15
11.集群搭建并使用
11.1 搭建
- 如果有多个机器
-
需要对每个机器配置
 配置redis.conf
配置redis.conf
2,4可以不用配,3不确定是否必须配,6最好和每个节点对应
安装ruby相关的东西(用来执行后面的redis-trib.rb脚本)
yum install ruby
yum install rubygems
yum install redis
ps:需要ruby2.2.2以上版本,如果自动安装的版本过低的话:https://www.cnblogs.com/PatrickLiu/p/8454579.html启动6个redis
开始搭建集群(redis-trib.rb在redis的src目录下)
./redis-trib.rb create --replicas 1 192.168.0.100:7001 192.168.0.100:7002 192.168.0.100:7003 192.168.0.100:7004 192.168.0.100:7005 192.168.0.100:7006
ps:replicas 1表示一个比值(主机/从机),这里是1的话,就表示一半一半,三个主机,三个从机。并且是按照命令的顺序来的,比如这里7001,7002,7003就是主机,7004,7005,7006是从机,并且7001是7004的从机,7002是7005的从机,7003是7006的从机
- 如果没有多个机器,可以用一台机器来模拟多个机器
创建一个文件夹redis-cluster
-
在redis-cluster文件夹下创建多个文件夹(7001,7002,7003,7004,7005,7006),主要是用来区分不同的机器
 文件夹
文件夹 -
配置每一个redis.conf
将redis.conf复制到7001-7006文件夹,并配置
配置redis.conf 启动6个redis
开始搭建集群(redis-trib.rb在redis的src目录下)
./redis-trib.rb create --replicas 1 192.168.0.100:7001 192.168.0.100:7002 192.168.0.100:7003 192.168.0.100:7004 192.168.0.100:7005 192.168.0.100:7006


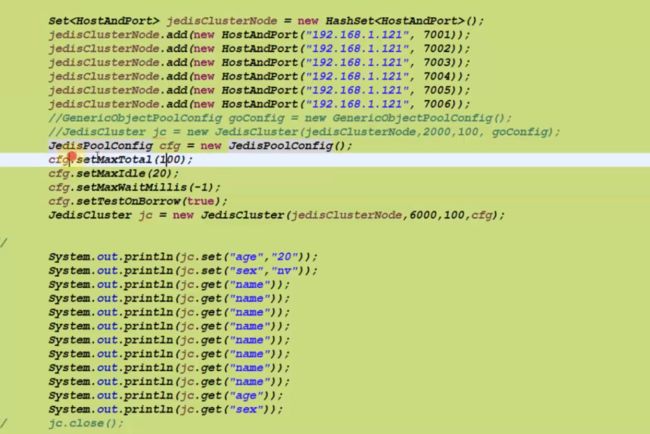
11.2 使用
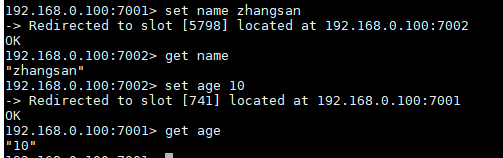
/usr/local/redis-3.0.1/bin/redis-cli -c -h 192.168 .0.100 -p 7001
进入客户端,-c:集群模式,-h:ip,-p:端口号
cluster nodes:查看节点

存取数据:
11.3 java使用