信息摘要算法之一:MD5算法解析及实现
MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法),主流编程语言普遍已有MD5实现。
1、MD5算法简介
MD5在90年代初由MIT的计算机科学实验室和RSA Data Security Inc发明,经MD2、MD3和MD4发展而来。
MD5将任意长度的“字节串”变换成一个128bit的大整数,并且它是一个不可逆的字符串变换算法,换句话说就是,即使你看到源程序和算法描述,也无法将一个MD5的值变换回原始的字符串,从数学原理上说,是因为原始的字符串有无穷多个。
MD5的典型应用是对一段信息串 (Message)产生所谓的指纹 (fingerprint),以防止被“篡改”。比方说,你将一段话写在一个文本文件中,并对这个文本文件产生一个MD5的值并记录在案,然后你可以传播这个文件给别人,别人如果修改了文件中的任何内容,你对这个文件重新计算MD5时就会发现。如果再有一个第三方的认证机构,用MD5还可以防止文件作者的“抵赖”,这就是所谓的数字签名应用。
MD5还广泛用于加密和解密技术上,在很多操作系统中,用户的密码是以MD5值(或类似的其它算法)的方式保存的,用户Login的时候,系统是把用户输入的密码计算成MD5值,然后再去和系统中保存的MD5值进行比较,而系统并不“知道”用户的密码是什么。
2、MD5算法分析
前面我们提到了MD5算法的主要应用领域,那么究竟MD5算法具体是什么样的呢?接下来我们就对其原理进行一些说明。
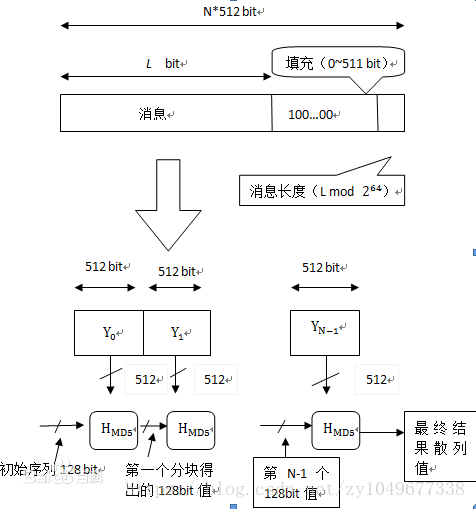
算法整体流程图
(1)待加密信息处理
显而易见,我们要对一个字符串进行MD5计算,那么肯定要从这个字符串的处理入手。我们知道一个字符的长度是一个字节,即8位(bit)的长度。MD5对待加密的字符串的处理是将一个字符串分割成每512位为一个分组,形如N*512+R,这里的R是余下的位数。这个R分为几种情况:
R=0时,需要补位,单补上一个512位的分组,因为还要加入最后64个位的字符串长度。
R<448时,则需要补位到448位,后面添加64位的字符串长度。
R>448时,除了补满这一分组外,还要再补上一个512位的分组后面添加64位的字符串长度。
补位的形式是先填充一个1,再接无数个0,直到补足512位。
NOTE:对消息进行数据填充,使消息的长度对512取模得448,设消息长度为X,即满足X mod 512=448。根据此公式得出需要填充的数据长度。
填充方法:在消息后面进行填充,填充第一位为1,其余为0。
(2)MD5的链接变量及基本操作
MD5有四个32位的被称作链接变量的整数参数,这是个参数我们定义为A、B、C、D其取值为:A=0x01234567,B=0x89abcdef,C=0xfedcba98,D=0x76543210。但考虑到内存数据存储大小端的问题我们将其赋值为:A=0x67452301,B=0xefcdab89,C=0x98badcfe,D=0x10325476。
同时MD5算法规定了四个非线性操作函数(&是与,|是或,~是非,^是异或):
F(X,Y,Z) =(X&Y)|((~X)&Z)
G(X,Y,Z) =(X&Z)|(Y&(~Z))
H(X,Y,Z) =X^Y^Z
I(X,Y,Z)=Y^(X|(~Z))
这些函数是这样设计的:如果X、Y和Z的对应位是独立和均匀的,那么结果的每一位也应是独立和均匀的。
利用上面的四种操作,生成四个重要的计算函数。首先我们声明四个中间变量a,b,c,d,赋值:a = A, b = B, c = C, d = D。然后定义这四个计算函数为:
FF(a, b, c, d, M[j], s, ti)表示 a = b + ((a + F(b, c, d) + Mj + ti) <<< s)
GG(a, b, c, d, M[j], s, ti)表示 a = b + ((a + G(b, c, d) + Mj + ti) <<< s)
HH(a, b, c, d, M[j], s, ti)表示 a = b + ((a + H(b, c, d) + Mj + ti) <<< s)
II(a, b, c, d, M[j], s, ti)表示 a = b + ((a + I(b, c, d) + Mj + ti) <<< s)
其中M[j]表示消息的第j个子分组(从0到15),<<表示循环左移s,常数ti是4294967296*abs(sin(i))的整数部分,i取值从1到64,单位是弧度。
(3)循环计算
定义好上述的四个计算函数后,就可以实现MD5的真正循环计算了。这个循环的循环次数为512位分组的个数。每次循环执行64不计算,上述4个函数每个16次,具体如下:
//第一轮循环计算
FF(a,b,c,d,M[0],7,0xd76aa478);
FF(d,a,b,c,M[1],12,0xe8c7b756);
FF(c,d,a,b,M[2],17,0x242070db);
FF(b,c,d,a,M[3],22,0xc1bdceee);
FF(a,b,c,d,M[4],7,0xf57c0faf);
FF(d,a,b,c,M[5],12,0x4787c62a);
FF(c,d,a,b,M[6],17,0xa8304613);
FF(b,c,d,a,M[7],22,0xfd469501) ;
FF(a,b,c,d,M[8],7,0x698098d8) ;
FF(d,a,b,c,M[9],12,0x8b44f7af) ;
FF(c,d,a,b,M[10],17,0xffff5bb1) ;
FF(b,c,d,a,M[11],22,0x895cd7be) ;
FF(a,b,c,d,M[12],7,0x6b901122) ;
FF(d,a,b,c,M[13],12,0xfd987193) ;
FF(c,d,a,b,M[14],17,0xa679438e) ;
FF(b,c,d,a,M[15],22,0x49b40821);
//第二轮循环计算
GG(a,b,c,d,M[1],5,0xf61e2562);
GG(d,a,b,c,M[6],9,0xc040b340);
GG(c,d,a,b,M[11],14,0x265e5a51);
GG(b,c,d,a,M[0],20,0xe9b6c7aa) ;
GG(a,b,c,d,M[5],5,0xd62f105d) ;
GG(d,a,b,c,M[10],9,0x02441453) ;
GG(c,d,a,b,M[15],14,0xd8a1e681);
GG(b,c,d,a,M[4],20,0xe7d3fbc8) ;
GG(a,b,c,d,M[9],5,0x21e1cde6) ;
GG(d,a,b,c,M[14],9,0xc33707d6) ;
GG(c,d,a,b,M[3],14,0xf4d50d87) ;
GG(b,c,d,a,M[8],20,0x455a14ed);
GG(a,b,c,d,M[13],5,0xa9e3e905);
GG(d,a,b,c,M[2],9,0xfcefa3f8) ;
GG(c,d,a,b,M[7],14,0x676f02d9) ;
GG(b,c,d,a,M[12],20,0x8d2a4c8a);
//第三轮循环计算
HH(a,b,c,d,M[5],4,0xfffa3942);
HH(d,a,b,c,M[8],11,0x8771f681);
HH(c,d,a,b,M[11],16,0x6d9d6122);
HH(b,c,d,a,M[14],23,0xfde5380c) ;
HH(a,b,c,d,M[1],4,0xa4beea44) ;
HH(d,a,b,c,M[4],11,0x4bdecfa9) ;
HH(c,d,a,b,M[7],16,0xf6bb4b60) ;
HH(b,c,d,a,M[10],23,0xbebfbc70);
HH(a,b,c,d,M[13],4,0x289b7ec6);
HH(d,a,b,c,M[0],11,0xeaa127fa);
HH(c,d,a,b,M[3],16,0xd4ef3085);
HH(b,c,d,a,M[6],23,0x04881d05);
HH(a,b,c,d,M[9],4,0xd9d4d039);
HH(d,a,b,c,M[12],11,0xe6db99e5);
HH(c,d,a,b,M[15],16,0x1fa27cf8) ;
HH(b,c,d,a,M[2],23,0xc4ac5665);
//第四轮循环计算
II(a,b,c,d,M[0],6,0xf4292244) ;
II(d,a,b,c,M[7],10,0x432aff97) ;
II(c,d,a,b,M[14],15,0xab9423a7);
II(b,c,d,a,M[5],21,0xfc93a039) ;
II(a,b,c,d,M[12],6,0x655b59c3) ;
II(d,a,b,c,M[3],10,0x8f0ccc92) ;
II(c,d,a,b,M[10],15,0xffeff47d);
II(b,c,d,a,M[1],21,0x85845dd1) ;
II(a,b,c,d,M[8],6,0x6fa87e4f) ;
II(d,a,b,c,M[15],10,0xfe2ce6e0);
II(c,d,a,b,M[6],15,0xa3014314) ;
II(b,c,d,a,M[13],21,0x4e0811a1);
II(a,b,c,d,M[4],6,0xf7537e82) ;
II(d,a,b,c,M[11],10,0xbd3af235);
II(c,d,a,b,M[2],15,0x2ad7d2bb);
II(b,c,d,a,M[9],21,0xeb86d391);
(4)结果输出
处理完所有的512位的分组后,得到一组新的A,B,C,D的值,将这些值按ABCD的顺序级联,就得到了想要的MD5散列值。当然,输出依然要考虑内存存储的大小端问题。
3、MD5算法实现
(1)方法1:来自百度百科
#include>2]|=(str[i])<<((i%4)*8);//一个整数存储四个字节,i>>2表示i/4 一个unsigned int对应4个字节,保存4个字符信息
}
strByte[str.length()>>2]|=0x80<<(((str.length()%4))*8);//尾部添加1 一个unsigned int保存4个字符信息,所以用128左移
/*
*添加原长度,长度指位的长度,所以要乘8,然后是小端序,所以放在倒数第二个,这里长度只用了32位
*/
strByte[num*16-2]=str.length()*8;
return strByte;
}
string changeHex(int a)
{
int b;
string str1;
string str="";
for(int i=0;i<4;i++)
{
str1="";
b=((a>>i*8)%(1<<8))&0xff; //逆序处理每个字节
for (int j = 0; j < 2; j++)
{
str1.insert(0,1,str16[b%16]);
b=b/16;
}
str+=str1;
}
return str;
}
string getMD5(string source)
{
atemp=A; //初始化
btemp=B;
ctemp=C;
dtemp=D;
unsigned int *strByte=add(source);
for(unsigned int i=0;i16;i++)
{
unsigned int num[16];
for(unsigned int j=0;j<16;j++)
num[j]=strByte[i*16+j];
mainLoop(num);
}
return changeHex(atemp).append(changeHex(btemp)).append(changeHex(ctemp)).append(changeHex(dtemp));
}
unsigned int main()
{
string ss;
// cin>>ss;
string s=getMD5("abc");
cout<return 0;
} (2)方法2:来自https://www.cnblogs.com/hjgods/p/3998570.html
#MD5.h
#ifndef MD5H
#define MD5H
#include #MD5.cpp
#include "MD5.h"
/*4组计算函数*/
inline unsigned int F(unsigned int X, unsigned int Y, unsigned int Z)
{
return (X & Y) | ((~X) & Z);
}
inline unsigned int G(unsigned int X, unsigned int Y, unsigned int Z)
{
return (X & Z) | (Y & (~Z));
}
inline unsigned int H(unsigned int X, unsigned int Y, unsigned int Z)
{
return X ^ Y ^ Z;
}
inline unsigned int I(unsigned int X, unsigned int Y, unsigned int Z)
{
return Y ^ (X | (~Z));
}
/*4组计算函数结束*/
/*32位数循环左移实现函数*/
void ROL(unsigned int &s, unsigned short cx)
{
if (cx > 32)cx %= 32;
s = (s << cx) | (s >> (32 - cx));
return;
}
/*B\L互转,接收UINT类型*/
void ltob(unsigned int &i)
{
unsigned int tmp = i;//保存副本
byte *psour = (byte*)&tmp, *pdes = (byte*)&i;
pdes += 3;//调整指针,准备左右调转
for (short i = 3; i >= 0; --i)
{
CopyMemory(pdes - i, psour + i, 1);
}
return;
}
/*
MD5循环计算函数,label=第几轮循环(1<=label<=4),lGroup数组=4个种子副本,M=数据(16组32位数指针)
种子数组排列方式: --A--D--C--B--,即 lGroup[0]=A; lGroup[1]=D; lGroup[2]=C; lGroup[3]=B;
*/
void AccLoop(unsigned short label, unsigned int *lGroup, void *M)
{
unsigned int *i1, *i2, *i3, *i4, TAcc, tmpi = 0; //定义:4个指针; T表累加器; 局部变量
typedef unsigned int(*clac)(unsigned int X, unsigned int Y, unsigned int Z); //定义函数类型
const unsigned int rolarray[4][4] = {
{ 7, 12, 17, 22 },
{ 5, 9, 14, 20 },
{ 4, 11, 16, 23 },
{ 6, 10, 15, 21 }
};//循环左移-位数表
const unsigned short mN[4][16] = {
{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 },
{ 1, 6, 11, 0, 5, 10, 15, 4, 9, 14, 3, 8, 13, 2, 7, 12 },
{ 5, 8, 11, 14, 1, 4, 7, 10, 13, 0, 3, 6, 9, 12, 15, 2 },
{ 0, 7, 14, 5, 12, 3, 10, 1, 8, 15, 6, 13, 4, 11, 2, 9 }
};//数据坐标表
const unsigned int *pM = static_cast<unsigned int*>(M);//转换类型为32位的Uint
TAcc = ((label - 1) * 16) + 1; //根据第几轮循环初始化T表累加器
clac clacArr[4] = { F, G, H, I }; //定义并初始化计算函数指针数组
/*一轮循环开始(16组->16次)*/
for (short i = 0; i < 16; ++i)
{
/*进行指针自变换*/
i1 = lGroup + ((0 + i) % 4);
i2 = lGroup + ((3 + i) % 4);
i3 = lGroup + ((2 + i) % 4);
i4 = lGroup + ((1 + i) % 4);
/*第一步计算开始: A+F(B,C,D)+M[i]+T[i+1] 注:第一步中直接计算T表*/
tmpi = (*i1 + clacArr[label - 1](*i2, *i3, *i4) + pM[(mN[label - 1][i])] + (unsigned int)(0x100000000UL * abs(sin((double)(TAcc + i)))));
ROL(tmpi, rolarray[label - 1][i % 4]);//第二步:循环左移
*i1 = *i2 + tmpi;//第三步:相加并赋值到种子
}
return;
}
/*接口函数,并执行数据填充*/
unsigned int* MD5(const char* mStr)
{
unsigned int mLen = strlen(mStr); //计算字符串长度
if (mLen < 0) return 0;
unsigned int FillSize = 448 - ((mLen * 8) % 512); //计算需填充的bit数
unsigned int FSbyte = FillSize / 8; //以字节表示的填充数
unsigned int BuffLen = mLen + 8 + FSbyte; //缓冲区长度或者说填充后的长度
unsigned char *md5Buff = new unsigned char[BuffLen]; //分配缓冲区
CopyMemory(md5Buff, mStr, mLen); //复制字符串到缓冲区
/*数据填充开始*/
md5Buff[mLen] = 0x80; //第一个bit填充1
ZeroMemory(&md5Buff[mLen + 1], FSbyte - 1); //其它bit填充0,另一可用函数为FillMemory
unsigned long long lenBit = mLen * 8ULL; //计算字符串长度,准备填充
CopyMemory(&md5Buff[mLen + FSbyte], &lenBit, 8); //填充长度
/*数据填充结束*/
/*运算开始*/
unsigned int LoopNumber = BuffLen / 64; //以16个字为一分组,计算分组数量
unsigned int A = 0x67452301, B = 0x0EFCDAB89, C = 0x98BADCFE, D = 0x10325476;//初始4个种子,小端类型
unsigned int *lGroup = new unsigned int[4]{ A, D, C, B}; //种子副本数组,并作为返回值返回
for (unsigned int Bcount = 0; Bcount < LoopNumber; ++Bcount) //分组大循环开始
{
/*进入4次计算的小循环*/
for (unsigned short Lcount = 0; Lcount < 4;)
{
AccLoop(++Lcount, lGroup, &md5Buff[Bcount * 64]);
}
/*数据相加作为下一轮的种子或者最终输出*/
A = (lGroup[0] += A);
B = (lGroup[3] += B);
C = (lGroup[2] += C);
D = (lGroup[1] += D);
}
/*转换内存中的布局后才能正常显示*/
ltob(lGroup[0]);
ltob(lGroup[1]);
ltob(lGroup[2]);
ltob(lGroup[3]);
delete[] md5Buff; //清除内存并返回
return lGroup;
}#main.cpp
#include