类加载器的双亲委派模型和代码热部署
前言
最近看了《深入理解JVM》,发现它的内容确实在某些方面是很深入的,学习到了很多有趣的知识。但是限于自己的能力,有些地方看着也不是很理解,掌握的知识层次还是不够,可能还是要多动手实践、多看书了解相关的概念。今天看了类加载器相关的知识,因为它提到了代码的热更新(热部署),以前学习jsp的时候经常使用,所以就感觉很好奇,想来探究一下它的实现过程。所以就萌生了一个想法,结合自己学习过的知识,使用类加载器的知识来尝试写了一个简单的demo——关于代码的热部署。
这里需要读者先了解:
1.类加载器的概念
2.类加载器的双亲委派模型
注: 因为我就是为了理解双亲委派机制才来写这个博客的,所以关于上面的概念,可以自行去参考网上的资料,CSDN上也有一些博客对于理解它们很有帮助。
个人理解,仅供参考:
我们平时写的代码指的是源代码,它是文本文件,无法直接被机器识别,必须经过编译。Java源文件被编译之后,会产生同名的类文件(字节码文件)。而类加载器的作用就是将类文件(字节码文件)加载到内存中去,所谓加载,就是将类文件所组成的二进制数据,读取入内存中去。就我个人理解来看,本质上就是一个IO操作,把文件读入内存中去。然后会有特殊的类去处理这个字节码文件,这里我们先不管它如何处理,因为我也不清楚,哈哈。
类加载器的双亲委派模型实验
类加载器的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,没一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中
,只有当父类加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需要的类)时,子加载器才会尝试自己去加载。 使用双亲委派
模型来组织来加载器之间的关系,有一个显而易见的好处就是Java类随着它的类加载器一起具备了一种带有优先级的层次关系。
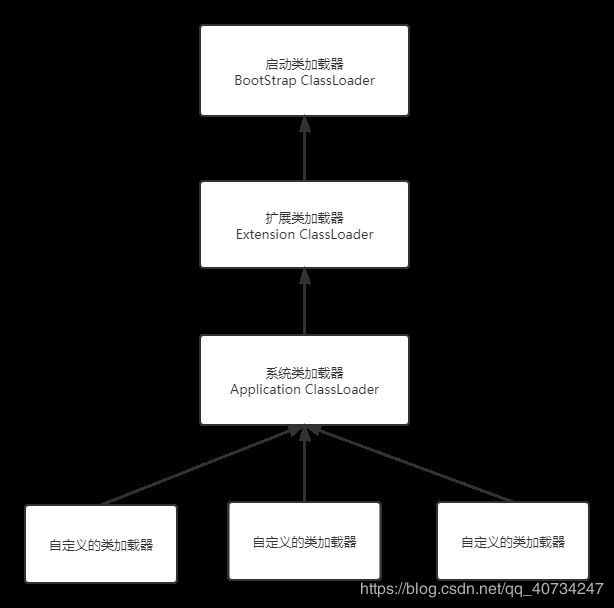
如果没有优先级关系的话,java.lang.Object 类可以被任何类加载器加载(包括用户自定义的),但是不同的类加载器会有一个自己的命名空间,也就是说不同类加载器加载同一个类文件所产生的Class对象是不同的。这是一个非常有意思的问题,它会产生一些混乱的情况,读者可以使用自定义两个类加载器,使用它们来加载同一个类,就可以看出来了。
实验代码
为了验证类加载器的双亲委派模型,提供如下的代码,做一个小的实验。
package dragon.classloader;
import java.io.File;
import java.net.URL;
import java.net.URLClassLoader;
public class Test {
public static void main(String[] args) throws Exception {
// 这里这个url的路径是错误的,因为字节码文件,即Class文件是在项目的 bin 目录下的,
// 我这里指定的是 src 目录,即源文件目录,当时这段代码是执行是没有问题。
// 因为这个错误的 url 根本没有被用到,具体原因你往下看就会明白了,这里我就不修改了,
// 作为要给错误示例给大家看看。
URL[] urls = new URL[] {new URL("file", null,
System.getProperty("user.dir") + File.separator + "src" +
File.separator + "dragon" + File.separator + "classloader")};
Class<?> clazz1 = null, clazz2 = null;
// 使用classLoader1加载Cat类
try (URLClassLoader classLoader1 = new URLClassLoader(urls)) {
System.out.println(urls[0].toString());
clazz1 = classLoader1.loadClass("dragon.classloader.Cat");
}
// 使用classLoader2加载Cat类
try (URLClassLoader classLoader2 = new URLClassLoader(urls)) {
clazz2 = classLoader2.loadClass("dragon.classloader.Cat");
}
// 同一个类被加载多次,其实只是加载了一次,这里就是双亲委派机制的作用
// 所以,为了达到热部署的目的,即修改了代码之后,再次加载,需要卸载当前已经加载的类,
// 必须通过自定义的类加载器来实现这个目的。
System.out.println("clazz1 == clazz2: " + (clazz1 == clazz2));
}
}

这里使用的是URLClassLoader,它是遵循双亲委派机制的,所以Clazz1 == Clazz2为true。这里我使用它去加载在当前工程的 classpath 下面的类,所以第一个类加载器对象去尝试加载,而加载的顺序是从启动类加载器–>扩展类加载器–>应用类加载器,最终是使用应用类加载器来加载的,但是它确实是从上到下走了双亲委派的流程。至于为何两个类加载器获取的Class对象是相同的,是因为同一个类只会被类加载器加载一次,所以第二次加载会直接返回已经加载过的类。
原因
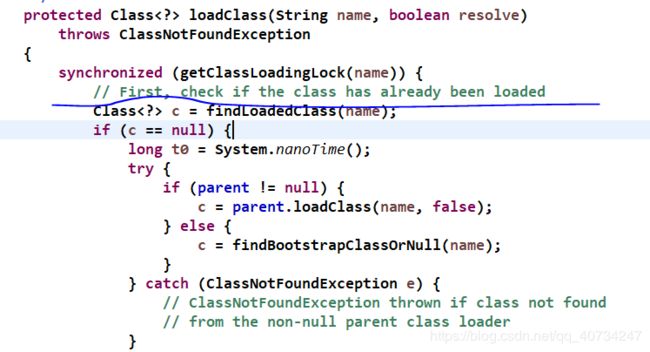
我们直接去查看loadClass的源码,可以发现如下注释:First, check if the class has alreday been loaded.
翻译为中文大致意思是:首先,检查是否这个类已经被加载过。
如果已经被加载过,它会直接返回 c 对象的。
破坏类加载器的双亲委派模型
自定义一个类加载器
package dragon.classloader;
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class DragonClassLoader extends ClassLoader {
private String url; //需要加载的字节码文件的位置,绝对路径。
public DragonClassLoader(String url) {
this.url = url;
}
/**
* 自定义类加载器推荐重写此方法,比较安全,
* 重写 defineClass,对使用者能力要求较高。
*
* 重写 findClass,以我个人的理解来说,就是根据 name,找到class文件的位置,
* 然后读取该文件的数据,将其作为参数传入 defineClass 即可。
* 当然了,还是需要自己动手,才能理解吧。
* */
@Override
public Class<?> findClass(String name) {
name = name.replace('.', File.separatorChar);
String filepath = this.url + name + ".class";
System.out.println(filepath);
//将该字节码文件读入内存中,这里我使用下面这个流来处理
ByteArrayOutputStream output = new ByteArrayOutputStream();
//开始读取文件
try (InputStream input = new BufferedInputStream(new FileInputStream(filepath))) {
int len = 0;
byte[] b = new byte[1024];
while ((len = input.read(b)) != -1) {
output.write(b, 0, len);
}
} catch (Exception e) {
e.printStackTrace();
}
//将字节流转成字节数组
byte[] data = output.toByteArray();
return this.defineClass(null, data, 0, data.length);
}
}
破坏双亲委派模型测试代码
package dragon.classloader;
public class Test {
public static void main(String[] args) throws ClassNotFoundException {
DragonClassLoader classLoader1 = null, classLoader2 = null;
String url = System.getProperty("user.dir");
System.out.println(url);
classLoader1 = new DragonClassLoader(url);
classLoader2 = new DragonClassLoader(url);
Class<?> clazz1 = classLoader1.loadClass("dragon.classloader.Cat");
Class<?> clazz2 = classLoader2.loadClass("dragon.classloader.Cat");
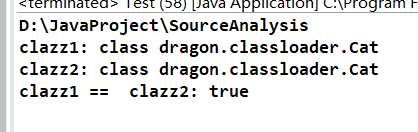
System.out.println("clazz1: " + clazz1);
System.out.println("clazz2: " + clazz2);
System.out.println("clazz1 == clazz2: " + (clazz1 == clazz2));
}
}
说明:
这里的结果还是true,说明我这个实验是失败的。但是为什么呢?我们把目光向前移动,看到双亲委派模型的那幅图片,可以看出自定义的类加载器的关系是平行的,但是我这里只是一个自定义类加载器,所以我应该再去自定义一个类加载器来加载,这样它们才会为false吗?也不是,因为我当前加载得这个类它是在classpath下面的,而classpath下面的类是由系统类加载器,即 Application Class Loader 来加载的。所以,我还是在双亲委派模型的机制下,加载了我自己写的类,也就是没有破坏双亲委派模型。
下面让我们来证明一下,上面的解释是正确的吧,证明的方式很简单,只是两句打印语句而已!
对上面的代码修改如下 :
public static void main(String[] args) throws ClassNotFoundException {
DragonClassLoader classLoader1 = null, classLoader2 = null;
//这里这个url路径其实是不对的,当时代码没有问题,你继续往下看就会懂的。
//我也就不改了,作为一个错误示例给大家看看。
String url = System.getProperty("user.dir");
System.out.println(url);
classLoader1 = new DragonClassLoader(url);
classLoader2 = new DragonClassLoader(url);
Class<?> clazz1 = classLoader1.loadClass("dragon.classloader.Cat");
Class<?> clazz2 = classLoader2.loadClass("dragon.classloader.Cat");
System.out.println("clazz1: " + clazz1);
System.out.println("clazz2: " + clazz2);
System.out.println("clazz1 == clazz2: " + (clazz1 == clazz2));
System.out.println(clazz1.getClassLoader());
System.out.println(clazz2.getClassLoader());
}
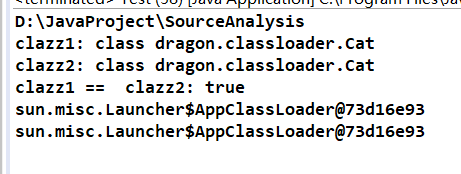
如上,可以看出,即使是自定义的类加载器加载的也是使用了双亲委派模型的。但是按照上面那幅图来看,它应该是使用 DragonClassLoader 来加载呀?这是为什么呢?其实上面也说了,是和classpath有关。
原因详细:
类加载器的双亲委派模型中,每个类加载器是有一个加载范围的。
启动类加载器加载的是:
存放在
扩展类加载器加载的是:
应用类加载器加载的是:
用户类路径(ClassPath)上所指定的类库。
那么怎么知道用户类路径是什么呢?
通过如下代码可快速知道:System.out.println(System.getProperty("java.class.path"));
结果为:
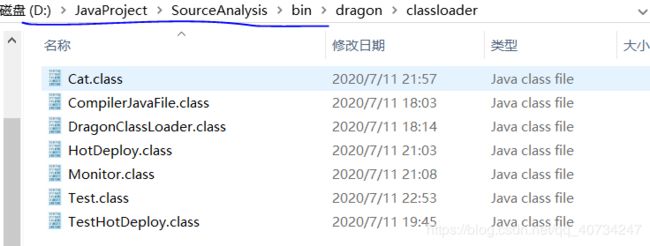
D:\JavaProject\SourceAnalysis\bin;C:\Program Files\Java\jdk1.8.0_241\bin
如下图所示,可以看到我的 Cat.class 字节码文件。
解决办法
知道了为什么,那么解决办法其实也很简单。我们首先要来看一下,类加载器的加载模型是双亲委派模型,那么它是如何实现的呢?答案就是类加载器的 loadClass 方法。
它的具体作用是:先检查是否已经被加载过,若没有加载则调用父类加载器的 loadClass() 方法,若父类加载器为空则默认使用启动类加载器作为父加载器。如果父类加载失败,则在抛出 ClassNotFoundException 异常后,再调用自己的 findClass() 方法进行加载。
所以,我们的自定义的类加载器其实是没有起作用的,因为我们是重写了 findClass() 方法,但是它根本就没有执行到!
所以现在解决办法就有了 ,而且有两种方式:
1.我们不走双亲委派模型,也就是说不调用类加载器的 loadClass() 方法,直接调用 findClass() 方法,这样就可以轻松破坏双亲委派模型了。
2.我们继续调用 loadClass,但是我们把需要加载的类不放在当前 classpath 下面,那么应用类加载器也会加载失败,它失败之后就会调用我们自己重写的 findClass() 方法进行加载类。
有效的破坏双亲委派模型实验代码
上面第一种是违背了双亲委派模型了,第二种则是保持双亲委派模型。但是效果是一样的,因为只要通过我们自己的 findClass() 方法,那么就可以达到破坏双亲委派模型的目的了。这里我采用第一种方式。
public static void main(String[] args) throws ClassNotFoundException {
DragonClassLoader classLoader1 = null, classLoader2 = null;
// 注意,因为我前面使用自定义类加载器加载类,但是它其实是使用了应用类加载器加载,
// 没有使用我自己重写的方法(因为我加载的是classpath下面的路径)
// 其实我写的 findClass 方法是有点问题,我应该指定一个全路径的,而 Cat.class
// 是在当前工程的 bin 目录下面的,所以这里需要加上一个 "/bin/"
String url = System.getProperty("user.dir") + "/bin/";
System.out.println(url);
classLoader1 = new DragonClassLoader(url);
classLoader2 = new DragonClassLoader(url);
Class<?> clazz1 = classLoader1.findClass("dragon.classloader.Cat");
Class<?> clazz2 = classLoader2.findClass("dragon.classloader.Cat");
System.out.println("clazz1: " + clazz1);
System.out.println("clazz2: " + clazz2);
System.out.println("clazz1 == clazz2: " + (clazz1 == clazz2));
System.out.println(clazz1.getClassLoader());
System.out.println(clazz2.getClassLoader());
}
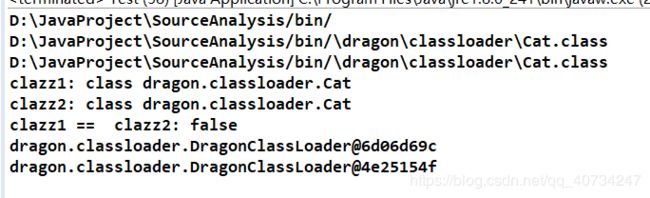
好了,目的已经达成了,可以看出来确实是使用了自定义的类加载器去加载了该类。即使它是在classpath 路径下面的。我还是成功打破了双亲委派模型。第二种方式,感兴趣的可以自己去尝试一下。
代码热部署
通过前面的示例表明,如果遵循双亲委派模型,那么一个类只会被加载一次,以后的加载会直接返回已经加载过的类。而代码的热更新需要将修改后的类,再次加载如内存,也就是重复加载类。所以,这里就需要打破双亲委派模型了。关于如何打破,上面已经介绍了一些简单的思路,代码虽然很简单,当时原理还是正确的。
检查源文件修改
对于代码的热更新我的理解是如果发现了源文件被修改了,那么就重新进行对该源文件进行编译,然后重新加载编译后的字节码文件。这样就可以实现了代码的热更新。 所以,现在的问题就转为如何检测源文件被修改?对此我的思路是:启动一个线程,每隔一段时间,检测该源文件是否修改了。具体方法是:首先记录该源文件的最后修改实践,然后间隔一定时间,检测它的最后修改时间是否发生变化,如果发生变化,那么就认为该文件已经被修改了。
Monitor 类
package dragon.classloader;
import java.io.File;
import java.io.IOException;
import java.nio.charset.Charset;
import javax.tools.JavaCompiler;
import javax.tools.JavaFileObject;
import javax.tools.StandardJavaFileManager;
import javax.tools.ToolProvider;
import javax.tools.JavaCompiler.CompilationTask;
public class Monitor implements Runnable {
// flag 为 true 表示需要重新加载(源文件已经编译了),false 表示不需要重新加载
public static boolean flag = false;
private static long time = 0L;
private static int SLEEP_TIME = 5*1000;
private String filepath;
public Monitor(String filepath) {
this.filepath = filepath;
}
@Override
public void run() {
while (true) {
File file = new File(filepath);
//如果当前时间为0L,说明文件是第一次加载,不为0L,则需要判断文件是否被加载过。
if (time != 0L) {
long lastTime = file.lastModified();
if (time != lastTime) {
time = lastTime; //更新当前文件得最后修改时间
//文件已经被修改,重新编译源文件
if (compileJavaFile(filepath)) {
System.out.println("编译成功!");
} else {
System.out.println("编译失败!");
}
flag = true;
System.out.println("Animal类文件已经修改,重新加载。");
} else {
System.out.println("Animal类文件未修改,不需要重新加载。" + Monitor.flag);
}
} else {
//记录文件的最后修改时间
time = file.lastModified();
//第一次编译源文件
if (compileJavaFile(filepath)) {
System.out.println("编译成功!");
} else {
System.out.println("编译失败!");
}
flag = true;
System.out.println("第一次加载Animal类文件。");
}
try {
//每隔一段时间检测一次
Thread.sleep(SLEEP_TIME);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private static boolean compileJavaFile(String filepath) {
// 获取系统提供的编译器
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
try (StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, Charset.forName("UTF-8"))) {
Iterable<? extends JavaFileObject> units = fileManager.getJavaFileObjects(filepath);
// 编译任务
CompilationTask task = compiler.getTask(null, null, null, null, null, units);
// 开始编译
return task.call();
} catch (IOException e) {
e.printStackTrace();
}
return false;
}
}
说明:
- 这里主要的思路都在 run 方法中了,我加了注释,读者应该可以理解它的作用,如果发现了问题,可以在评论中指出来。
- 关于下面这个 compileJavaFile 方法,它的作用是编译指定的Java源文件。关于这部分的代码,我以前见过,当时今天是第一次使用,我也是参考了别人的思路。
大家可以去参考这个人的博客:
java_基础——用代码编译.java文件+加载class文件
或者如果你感觉这个方法有点难以理解(实际上我也是的,哈哈!)。那你可以去使用调用 Javac 程序来编译代码,那个会比较简单一些。
重新加载字节码文件
这里我的思路是同样启动一个线程,然后它会检测 Monitor.flag 是否为 true (如果为true表明文件已经被修改,并且被重新编译了。)然后它就会重新加载该字节码文件,并将 Monitor.flag 设置为 false。然后再执行上述步骤,这样就实现了,代码的热部署(热更新)。
package dragon.classloader;
import java.lang.reflect.Constructor;
import java.lang.reflect.Method;
import dragon.obj.DragonClassLoader;
public class HotDeploy implements Runnable {
@Override
public void run() {
reloadClass();
}
private static void reloadClass() {
while (true) {
if (Monitor.flag) {
//加载完以后,将其置为 false
Monitor.flag = false;
// Java源文件存放的位置
DragonClassLoader classLoader = new DragonClassLoader("D:\\DragonFile\\testCode\\");
try {
Class<?> clazz = classLoader.loadClass("dragon.Animal");
Constructor<?> con = clazz.getConstructor(String.class, int.class);
Object obj = con.newInstance("tomcat", 1);
// 这里调用 obj 的一个方法
Method method = clazz.getMethod("say", new Class<?>[] {});
String msg = (String) method.invoke(obj, new Object[] {});
System.out.println("调用getDescription方法,执行结果为:" + msg);
} catch (Exception e) {
e.printStackTrace();
}
} else {
// 暂时没有修改源文件,不需要重新加载,让线程休息一会
// 如果不休息的话,会导致线程执行过快,也就是说 monitor线程竞争,导致monitor无法执行,
//或者很难执行。所以要及时让出CPU的执行权。
// try {
// //每隔一段时间检测一次
// Thread.sleep(SLEEP_TIME);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
// 或者使用下面这句,让出线程执行权
Thread.yield();
}
}
}
}
这里会使用一个 Animal 类,它同样很简单,注意它得包名和存放的路径结构。

package dragon;
public class Animal {
private String name;
private int age;
public Animal(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String say() {
return "我是小王" + name + ", 今年"+ age +"岁。";
}
}
热部署(热更新)实验代码
package dragon.classloader;
public class TestHotDeploy {
public static void main(String[] args) {
String filepath = "D:\\DragonFile\\testCode\\dragon\\Animal.java";
Monitor monitor = new Monitor(filepath);
Thread t1 = new Thread(monitor);
t1.start(); //启动线程开始监视文件的修改
HotDeploy hotDeploy = new HotDeploy();
Thread t2 = new Thread(hotDeploy);
t2.start(); //启动线程开始加载类
}
}
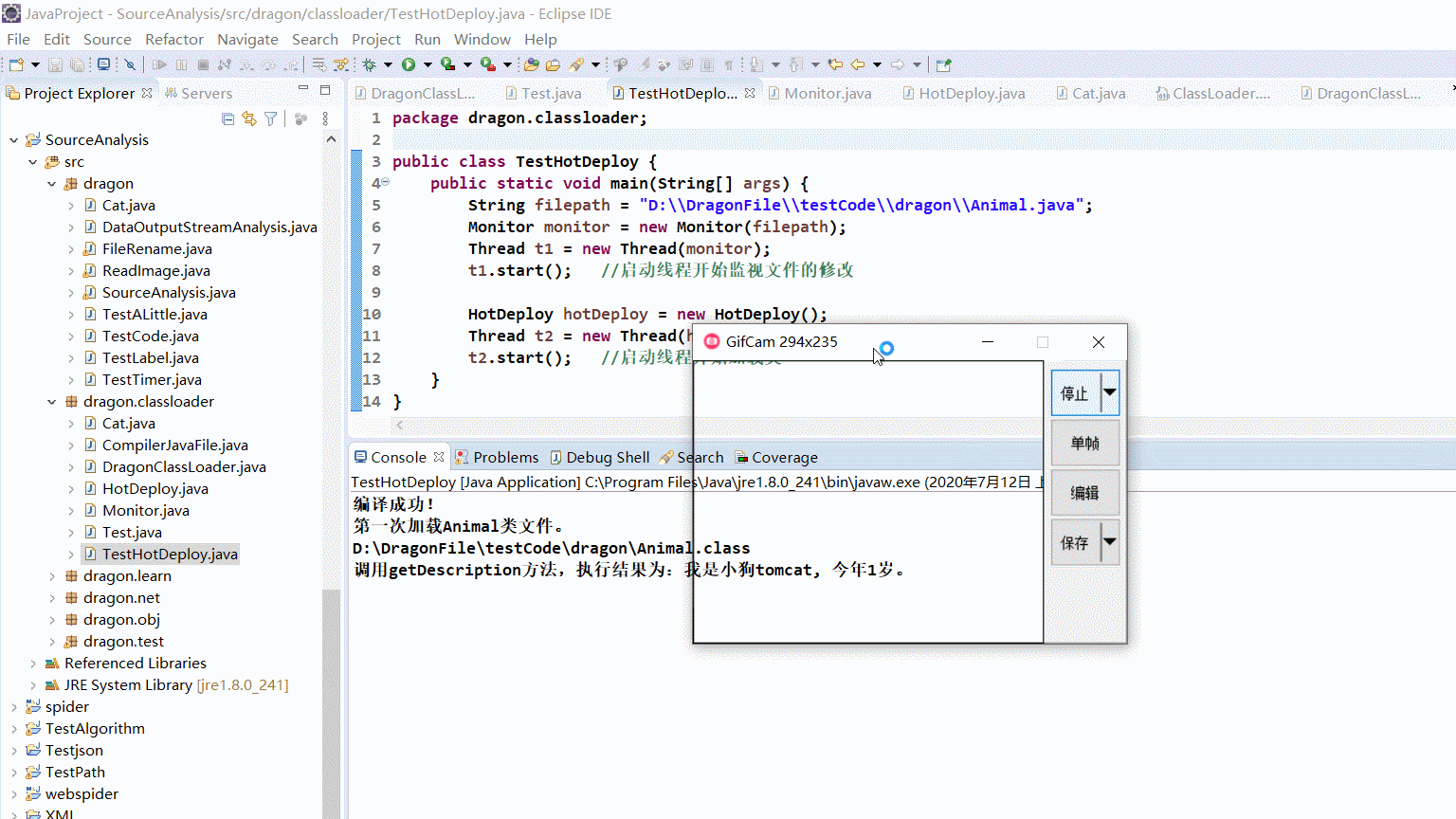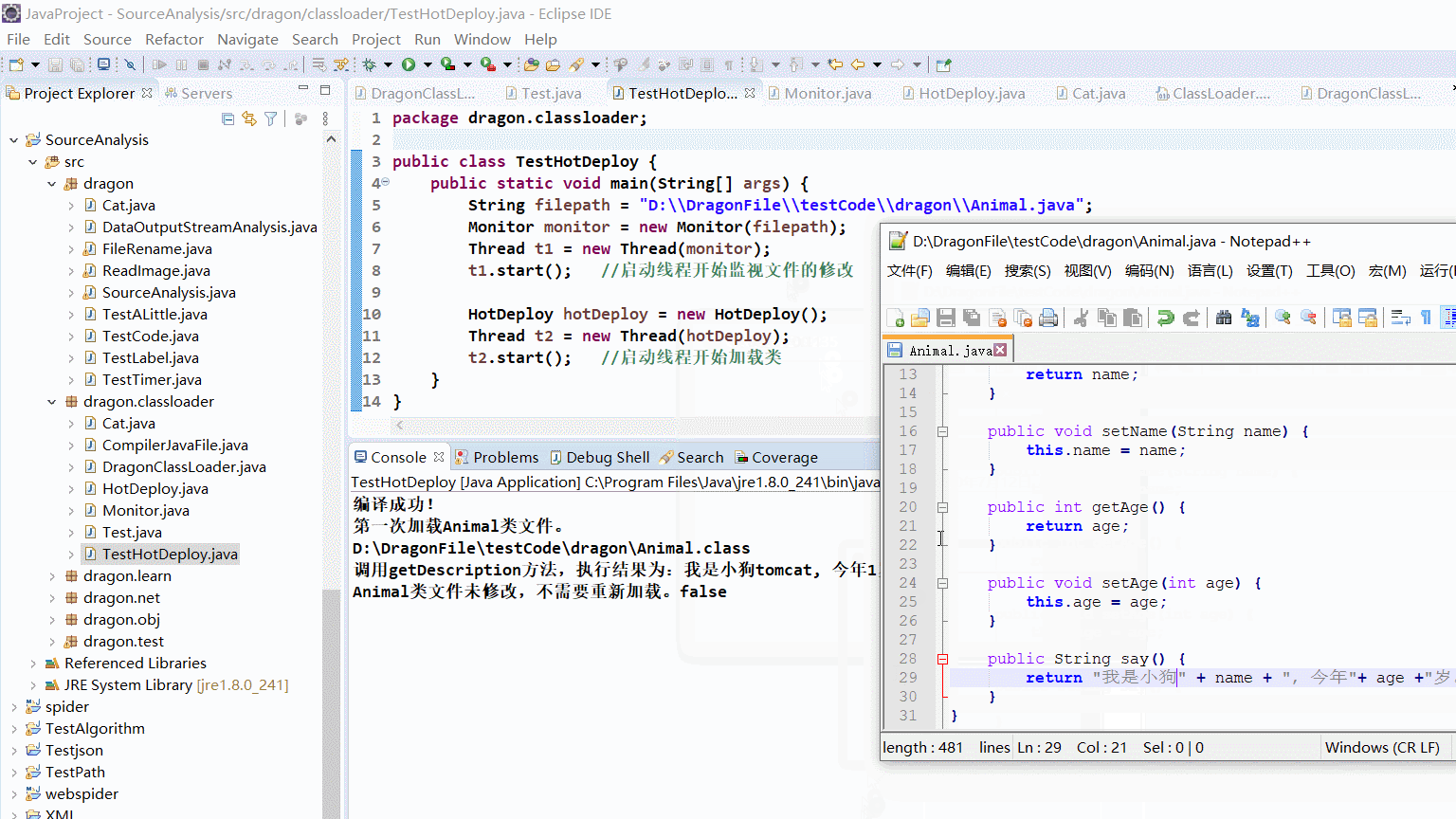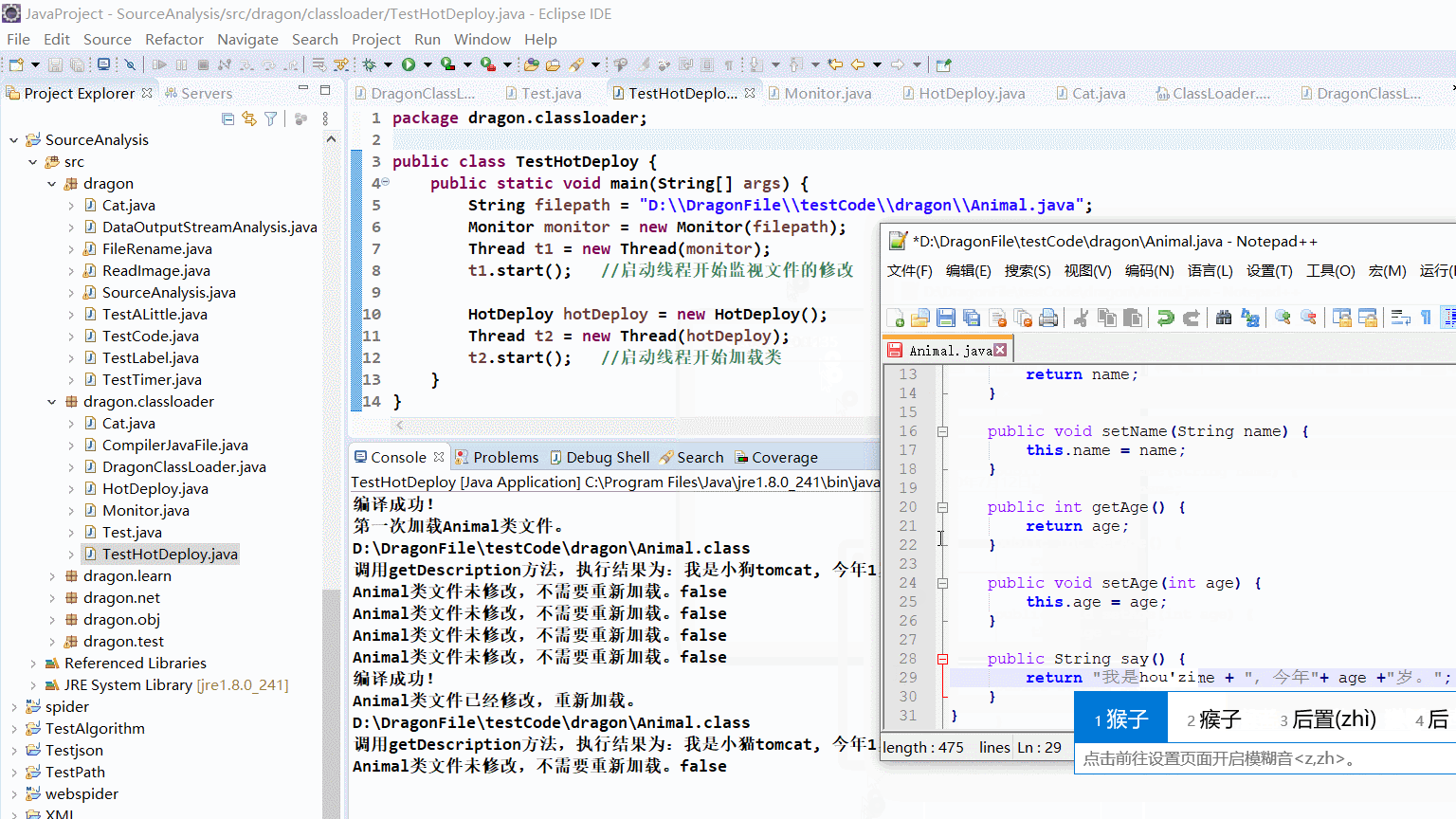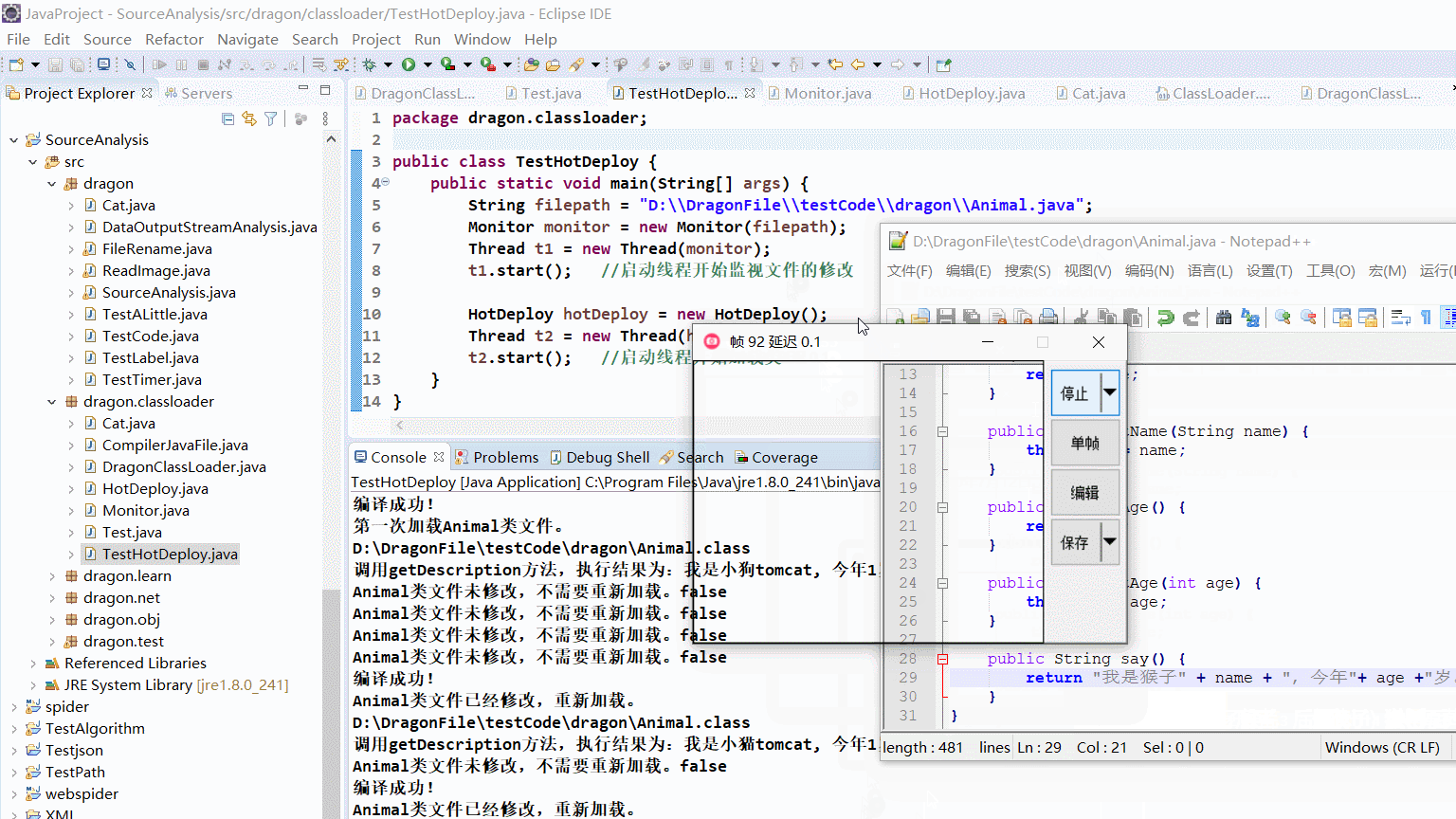
演示效果图
这里我修改了检测间隔时间为两秒钟。
总结
这篇博客,基本上是把我最近所学的知识给总结了一遍,再配上几个示例的代码,算是更加深入的理解了类加载的相关知识。当时这也不是全部,还有很多东西是值得去探索的。例如,我重复加载一个类,那么原来加载进去的类,它会去哪里呢?我了解到有一个概念叫做类的卸载。但是《深入理解JVM》中似乎没有找到(因为我是跳着看的,可能没有发现吧。)我猜测前面的类会被卸载掉,但是我现在还不是很清楚。这个问题就留待以后解决吧。
好了,基本上该说的都已经说完了。写这篇博客,确实费了我很大的功夫。一开始的理解还是有问题,知道我写到了后面我才发现。写代码的时候,有些问题,可能不是很容易发现,当时通过将它表述出来,就比较容易发现逻辑上的漏洞了。例如上面的 src 和 bin 文件夹都搞糊涂了,哈哈!不过还好,及时发现了。关于剩下的我没发现的问题,如果各位发现了,可以在评论区指出来。